当前位置:网站首页>基于data.table的tidyverse?
基于data.table的tidyverse?
2022-08-03 20:31:00 【阿越1229】
获取更多R语言知识,请关注公众号:医学和生信笔记
“医学和生信笔记,专注R语言在临床医学中的使用,R语言数据分析和可视化。主要分享R语言做医学统计学、meta分析、网络药理学、临床预测模型、机器学习、生物信息学等。
tidyverse作为R语言数据分析中的瑞士军刀,非常好用,一个小小的缺点就是速度慢,data.table速度快,所以他们团队又开发了dtplyr,加快运行速度。
不过今天要介绍的是另一个,基于data.table的tidyverse:tidytable。
使用起来非常简单,只需要在原有函数后面加一个.即可!!!
下面是一个常见操作的简单的速度对比,可以看到速度提升了非常多~
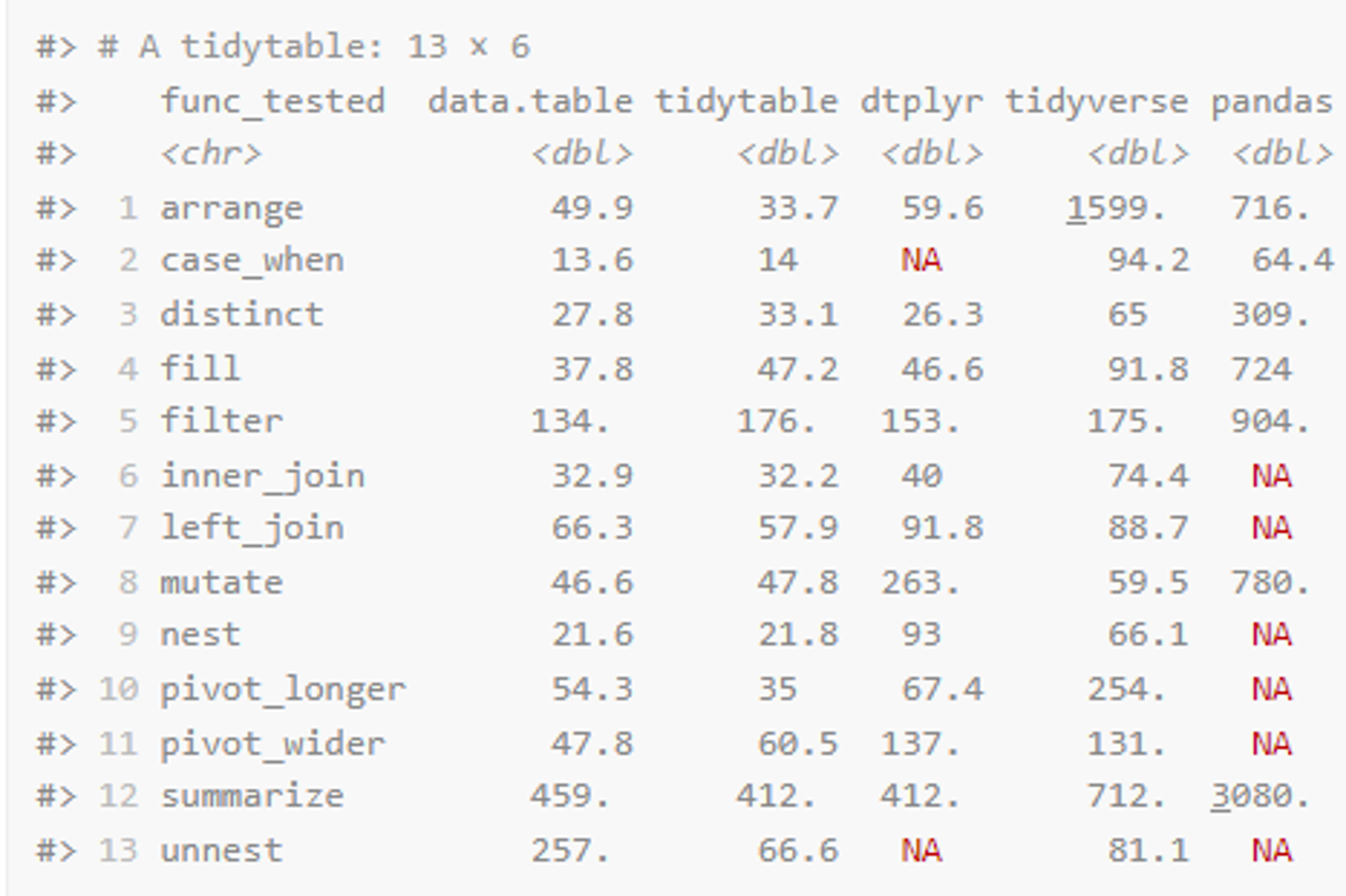
安装
# 经典2选1
install.packages("tidytable")
# install.packages("devtools")
devtools::install_github("markfairbanks/tidytable")
一般使用
只要在函数后面加一个.就可以了!!
library(tidytable)
## Warning: package 'tidytable' was built under R version 4.2.1
##
## Attaching package: 'tidytable'
## The following object is masked from 'package:stats':
##
## dt
df <- data.table(x = 1:3, y = 4:6, z = c("a", "a", "b"))
df %>%
select.(x, y, z) %>%
filter.(x < 4, y > 1) %>%
arrange.(x, y) %>%
mutate.(double_x = x * 2,
x_plus_y = x + y)
## # A tidytable: 3 × 5
## x y z double_x x_plus_y
## <int> <int> <chr> <dbl> <int>
## 1 1 4 a 2 5
## 2 2 5 a 4 7
## 3 3 6 b 6 9
分组汇总
和group_by()稍有不同,这里需要使用.by = 进行分组汇总。
df %>%
summarize.(avg_x = mean(x),
count = n(),
.by = z) # 分组汇总形式不同
## # A tidytable: 2 × 3
## z avg_x count
## <chr> <dbl> <int>
## 1 a 1.5 2
## 2 b 3 1
每次都要调用:
df <- data.table(x = c("a", "a", "a", "b", "b"))
df %>%
slice.(1:2, .by = x) %>% # .by
mutate.(group_row_num = row_number(), .by = x) # .by
## # A tidytable: 4 × 2
## x group_row_num
## <chr> <int>
## 1 a 1
## 2 a 2
## 3 b 1
## 4 b 2
支持tidyselect
常见的everything(), starts_with(), ends_with(), any_of(), where()等都是支持的。
df <- data.table(
a = 1:3,
b1 = 4:6,
b2 = 7:9,
c = c("a", "a", "b")
)
df %>%
select.(a, starts_with("b"))
## # A tidytable: 3 × 3
## a b1 b2
## <int> <int> <int>
## 1 1 4 7
## 2 2 5 8
## 3 3 6 9
df %>%
select.(-a, -starts_with("b"))
## # A tidytable: 3 × 1
## c
## <chr>
## 1 a
## 2 a
## 3 b
可以和.by连用:
df <- data.table(
a = 1:3,
b = c("a", "a", "b"),
c = c("a", "a", "b")
)
df %>%
summarize.(avg_a = mean(a),
.by = where(is.character))
## # A tidytable: 2 × 3
## b c avg_a
## <chr> <chr> <dbl>
## 1 a a 1.5
## 2 b b 3
支持data.table语法
借助dt()函数实现对data.table语法的支持。
df <- data.table(x = 1:3, y = 4:6, z = c("a", "a", "b"))
df %>%
dt(, .(x, y, z)) %>%
dt(x < 4 & y > 1) %>%
dt(order(x, y)) %>%
dt(, double_x := x * 2) %>%
dt(, .(avg_x = mean(x)), by = z)
## # A tidytable: 2 × 2
## z avg_x
## <chr> <dbl>
## 1 a 1.5
## 2 b 3
基本上tidyverse中和数据分析有关的函数都可以使用,详细支持的函数列表大家可以在这里[1]找到。
获取更多R语言知识,请关注公众号:医学和生信笔记
“医学和生信笔记,专注R语言在临床医学中的使用,R语言数据分析和可视化。主要分享R语言做医学统计学、meta分析、网络药理学、临床预测模型、机器学习、生物信息学等。
参考资料
tidytable支持的函数: https://markfairbanks.github.io/tidytable/reference/index.html
边栏推荐
猜你喜欢

亚马逊云科技 Build On 2022 - AIot 第二季物联网专场实验心得
RNA-ATTO 390|RNA-ATTO 425|RNA-ATTO 465|RNA-ATTO 488|RNA-ATTO 495|RNA-ATTO 520近红外荧光染料标记核糖核酸RNA
算法--交错字符串(Kotlin)
双线性插值公式推导及Matlab实现

收藏-即时通讯(IM)开源项目OpenIM-功能手册
 [email protected] 594/[email prote"/>
[email protected] 594/[email prote"/>RNA核糖核酸修饰Alexa 568/[email protected] 594/[email prote
简单又有效的基本折线图制作方法
Li Mu hands-on learning deep learning V2-BERT fine-tuning and code implementation
ThreadLocal详解

华为设备配置VRRP与BFD联动实现快速切换
随机推荐
云服务器如何安全使用本地的AD/LDAP?
在树莓派上搭建属于自己的网页(3)
调用EasyCVR接口时视频流请求出现404,并报错SSL Error,是什么原因?
直播小程序源码,UI自动化中获取登录验证码
ESP8266-Arduino编程实例-BH1750FVI环境光传感器驱动
亚马逊云科技 Build On 2022 - AIot 第二季物联网专场实验心得
简单又有效的基本折线图制作方法
不知道这4种缓存模式,敢说懂缓存吗?
NAACL 2022 | 具有元重加权的鲁棒自增强命名实体识别技术
(十六)51单片机——红外遥控
力扣59-螺旋矩阵 II——边界判断
ESP8266-Arduino编程实例-MCP4725数模转换器驱动
华为设备VRRP配置命令
leetcode 剑指 Offer 58 - II. 左旋转字符串
解决This application failed to start because no Qt platform plugin could be initialized的办法
PHP according to the longitude and latitude calculated distance two points
leetcode 268. Missing Numbers (XOR!!)
charles配置客户端请求全部不走缓存
使用 ReportLab 绘制 PDF
CheckBox列表项选中动画js特效