当前位置:网站首页>E-commerce data warehouse ODS layer-----log data loading
E-commerce data warehouse ODS layer-----log data loading
2022-08-03 21:34:00 【big data theory】
First generate the simulated log data and upload it to hdfs层
再将hdfsThe log data in the cut data is loaded intoODS层日志
一般企业在搭建数仓时,业务系统中会存在一定的历史数据,此处为模拟真实场景,需准备若干历史数据.假定数仓上线的日期为2020-06-14,具体说明如下.
1.用户行为日志
用户行为日志,一般是没有历史数据的,故日志只需要准备2020-06-14一天的数据.具体操作如下:
1)启动日志采集通道,包括Flume、Kafak等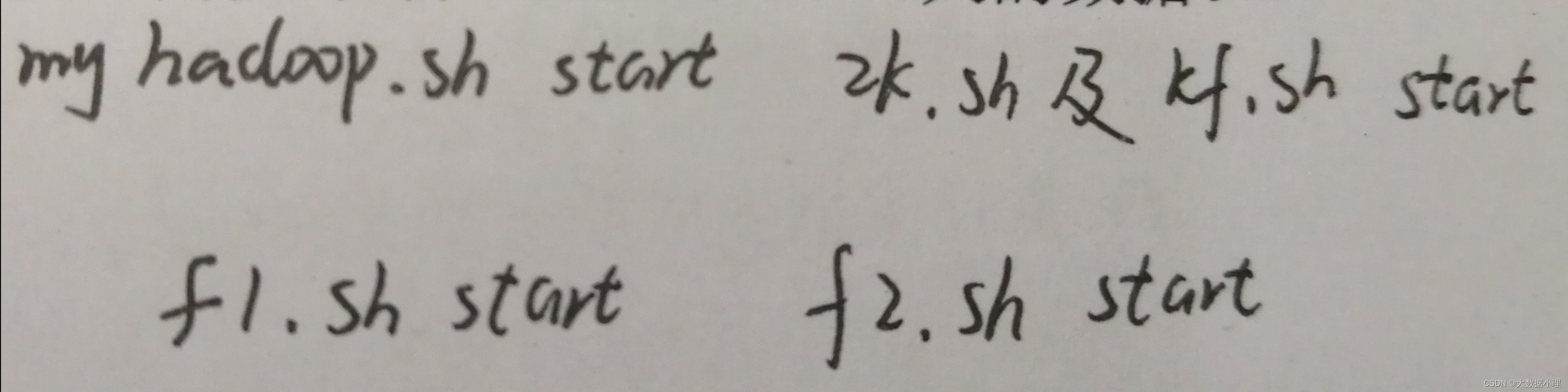
2)修改两个日志服务器(hadoop102、hadoop103)中的/opt/module/applog/application.yml配置文件,将mock.date参数改为2020-06-14.
3)执行日志生成脚本lg.sh.
4)观察HDFS是否出现相应文件.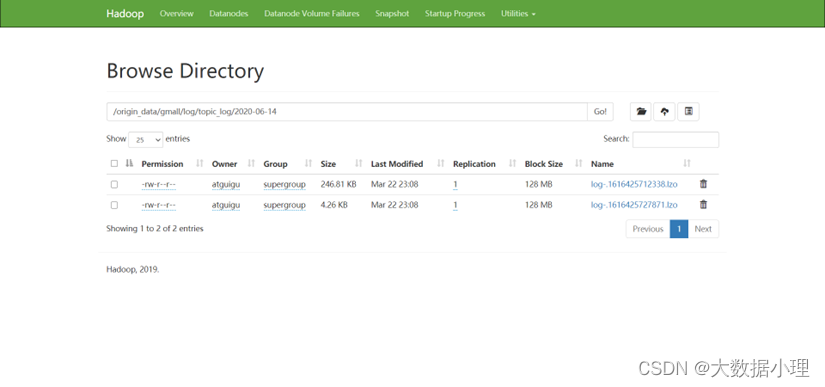
以下使用datagripData warehouse tools and script commands
create database gmall;
– ODS层
– ODS日志表
drop table if exists ods_log;
create external table ods_log(linestring)
partitioned by (dtstring) --按照时间创建分区
stored as inputformat ‘com.hadoop.mapred.DeprecatedLzoTextInputFormat’
–指定存储格式,读数据采用LzoTextInputFormat;
OUTPUTFORMAT ‘org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat’
LOCATION ‘/warehourse/gmall/ods/ods_log’ --指定数据在hdfs上的存储位置
;
–数据装载语句:Load with a load script
–2020-06-14
//load data inpath ‘/origin_data/gmall/log/topic_log/2020-06-14’ into table ods_log partition(dt=‘2020-06-14’);
–为hiveCreate an index on the files in the table
// [bin]$ hadoop jar /opt/module/hadoop3.1.3/share/common/hadoop-lzo-0.4.20.jar
– com.hadoop.compression.lzo.DistributedLzoIIndexer /warehouse/gmall/ods/ods_log/dt=2020-06-14
// 即hadoop jar jar包位置 全类名 to create an indexlzo文件所在的路径
//创建脚本 vim hdfs_to_ods_log.sh 再 chmod 777 hdfs_ods_log.sh
/*
#!/bin/bash
定义变量方便修改
APP=gmall
hive=/opt/module/hive/bin/hive
如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n “$1” ] ;then
do_date=$1
else
do_date=date -d "-1 day" +%F
fi
echo ================== 日志日期为 d o d a t e = = = = = = = = = = = = = = = = = = s q l = " l o a d d a t a i n p a t h ′ / o r i g i n d a t a / do_date ================== sql=" load data inpath '/origin_data/ dodate==================sql="loaddatainpath′/origindata/APP/log/topic_log/$do_date’ into table A P P . o d s l o g p a r t i t i o n ( d t = ′ {APP}.ods_log partition(dt=' APP.odslogpartition(dt=′do_date’);
"
h i v e − e " hive -e " hive−e"sql"
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/ A P P / o d s / o d s l o g / d t = APP/ods/ods_log/dt= APP/ods/odslog/dt=do_date
*/
After executing the script, the files in the original path are gone,剪切到了ODSlayer in the log layer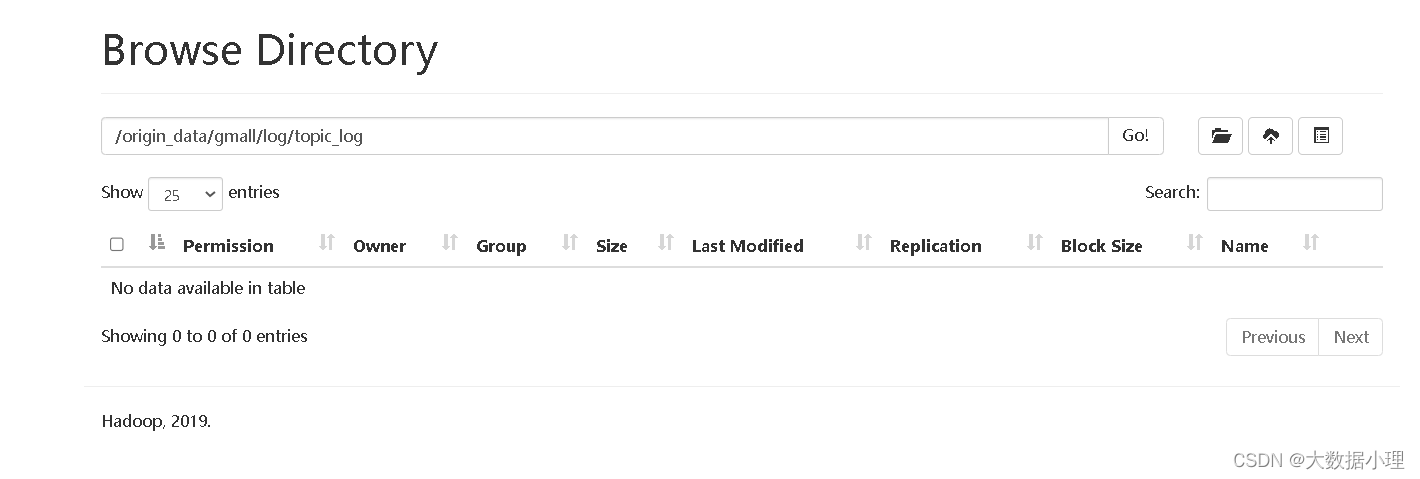
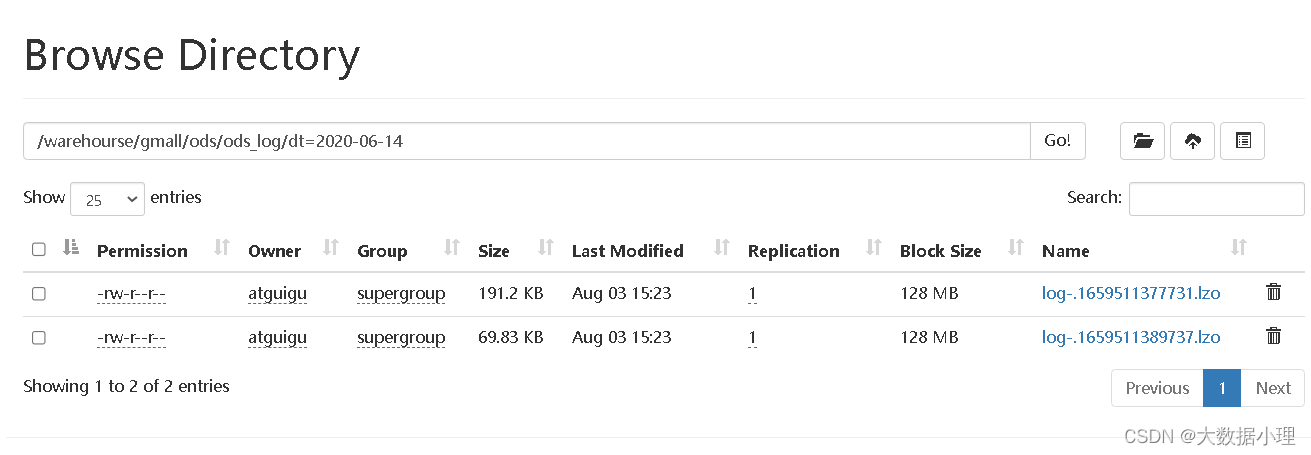
通过datagripYou can see that the data is loaded into the table
Double-click a table to view table data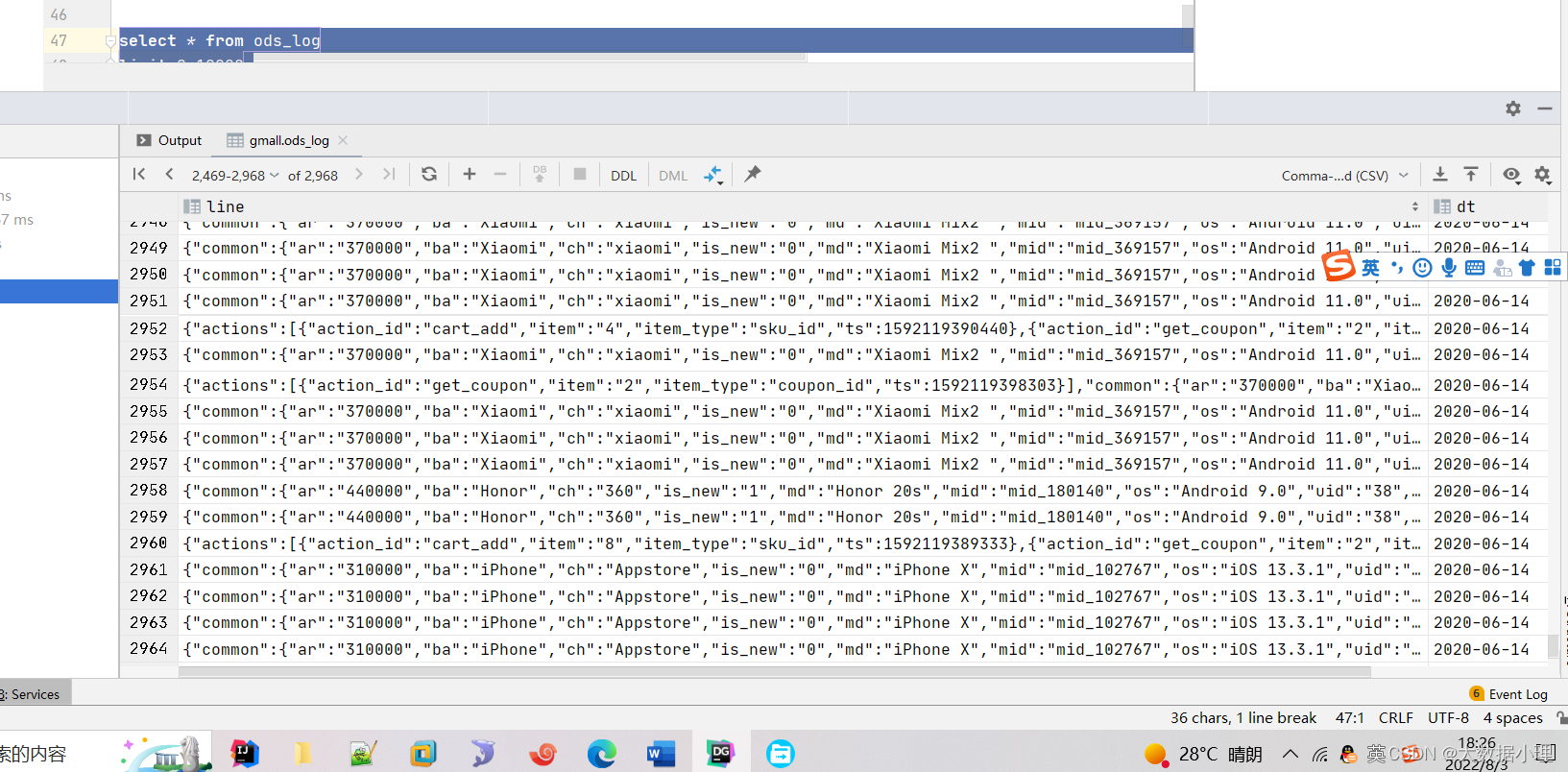
边栏推荐
- 卷起来!阿里高工携 18 位高级架构师耗时 57 天整合的 1658 页面试总结
- C. Array Elimination-- Codeforces Round #751 (Div. 2)
- 易基因:植物宏病毒组研究:植物病毒的进化与生态 | 顶刊综述
- 4. 模块化编程
- nxp官方uboot移植到野火开发板PRO(修改LCD部分和网络部分)
- XSS online shooting range---Warmups
- CAS:1620523-64-9_Azide-SS-biotin_生物素-二硫-叠氮
- LeetCode_位数统计_中等_400.第 N 位数字
- 1 秒完成授权,Authing 全新上线一键登录功能
- 开源一夏 |如何优化线上服务器
猜你喜欢
超级实用网站+公众号合集

安全基础8 ---XSS
Interesting opencv - record image binarization and similarity
2022年全国职业院校技能大赛网络安全 B模块 任务十windows操作系统渗透测试 国赛原题
![[kali-vulnerability exploitation] (3.2) Metasploit basics (on): basic knowledge](/img/49/117de5147a34e6a957f74880b4f597.png)
[kali-vulnerability exploitation] (3.2) Metasploit basics (on): basic knowledge
《富爸爸,穷爸爸》思维导图和学习笔记
![[kali-vulnerability scanning] (2.1) Nessus lifts IP restrictions, scans quickly without results, and plugins are deleted (middle)](/img/93/0b78b6a930380aeecfbbb156df7498.png)
[kali-vulnerability scanning] (2.1) Nessus lifts IP restrictions, scans quickly without results, and plugins are deleted (middle)

用 setTimeout 来实现 setInterval
shell编程基础

服务器安装redis
随机推荐
软件测试人员必备的60个测试工具清单,建议收藏一波~
线程池的高级应用技巧核心解读
从0到1看支付
从开发到软件测试:除了扎实的测试基础,还有哪些必须掌握 ?
【kali-漏洞扫描】(2.1)Nessus解除IP限制、扫描快无结果、插件plugins被删除(中)
小朋友学C语言(1):Hello World
FVCOM三维水动力、水交换、溢油物质扩散及输运数值模拟丨FVCOM模型流域、海洋水环境数值模拟方法
What is the role and difference between buildscript and allprojects?
XSS practice - cycle and two cycle problem at a time
AI首席架构师13-AICA-智能文档分析技术在行业场景中的应用
6. XML
XSS线上靶场---prompt
Engineering Effectiveness Governance for Agile Delivery
A. Color the Picture- Codeforces Round #810 (Div. 1)
idea2021.1.3版本如何启动多个客户端程序
火了十几年的零信任,为啥还不能落地
ES、Kibana 8.0安装
跨端开发技术储备记录
6. XML
CAS:122567-66-2_DSPE-生物素_DSPE-Biotin