当前位置:网站首页>【论文笔记】Dynamic Convolution: Attention over Convolution Kernels
【论文笔记】Dynamic Convolution: Attention over Convolution Kernels
2022-08-04 08:08:00 【m0_61899108】
Dynamic Convolution: Attention over Convolution Kernels,CVPR2020

参考博客:通过分组卷积的思想,巧妙的代码实现动态卷积(Dynamic Convolution) - 知乎
CVPR2020 oral-Dynamic Convolution动态卷积 - 知乎
摘要
相比高性能深度网络,轻量型网络因其低计算负载约束(深度与通道方面的约束)导致其存在性能降低,即比较有效的特征表达能力。为解决该问题,作者提出动态卷积:它可以提升模型表达能力而无需提升网络深度与宽度。
不同于常规卷积中的单一核,动态卷积根据输入动态的集成多个并行的卷积核为一个动态核,该动态核具有数据依赖性。多核集成不仅计算高效,而且具有更强的特征表达能力(因为这些核通过注意力机制以非线性形式进行融合)。
方法
动态卷积的目标在于:在网络性能与计算负载中寻求均衡。常规提升网络性能的方法(更宽、更深)往往会导致更高的计算消耗,因此对于高效网络并不友好。
作者提出的动态卷积不会提升网络深度与宽度,相反通过多卷积核融合提升模型表达能力。需要注意的是:所得卷积核与输入相关,即不同数据具有不同的卷积,这也就是动态卷积的由来。
创新点
在一个卷积层中用到了多个kernel,并且用attention机制去结合不同kernel的信息,因此就可以在计算消耗没有显著提升的情况下,提取到更加丰富的特征。
Dynamic Perceptron

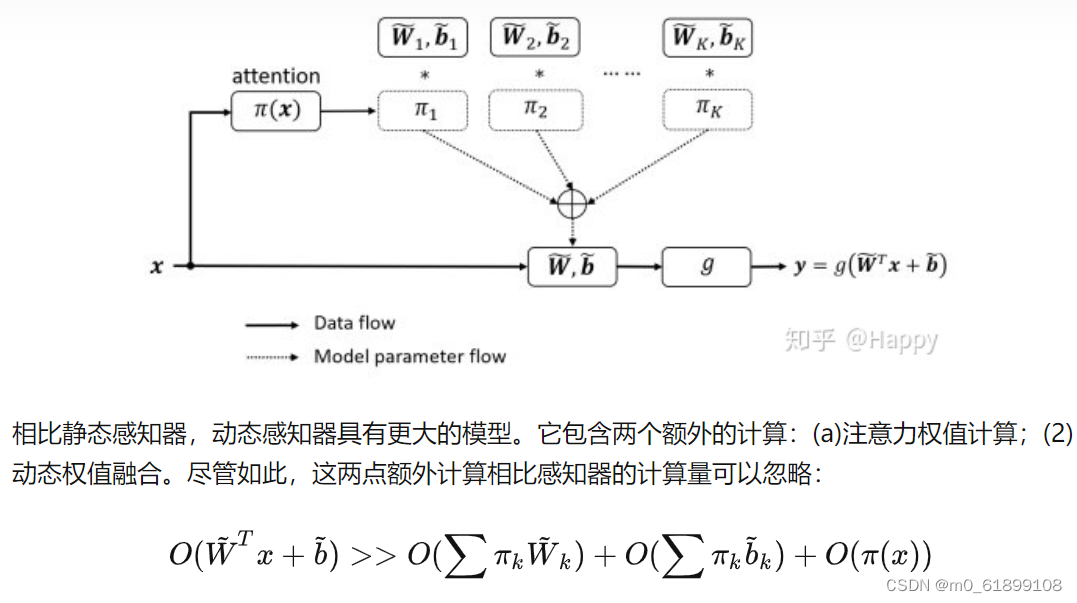
Dynamic Convolution
类似于动态感知器,动态卷积同样具有K个核。按照CNN中的经典设计,作者在动态卷积后接BatchNorm与ReLU。
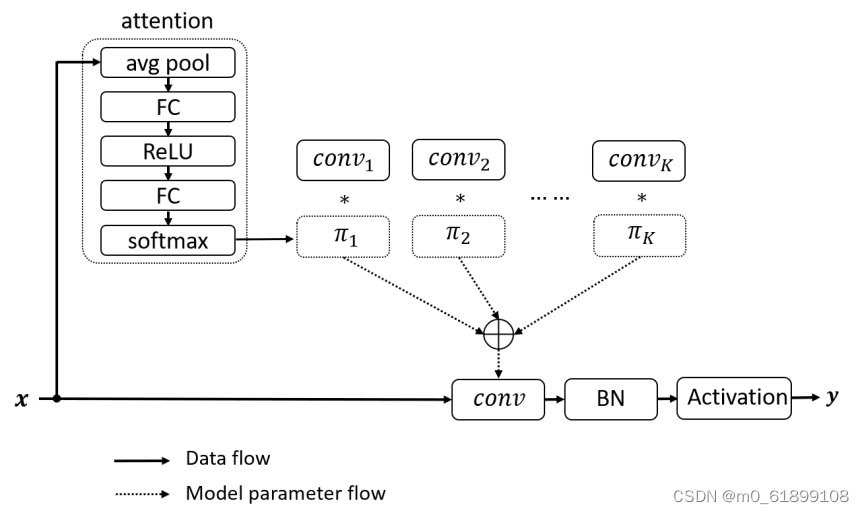
- 注意力:作者采用轻量型的
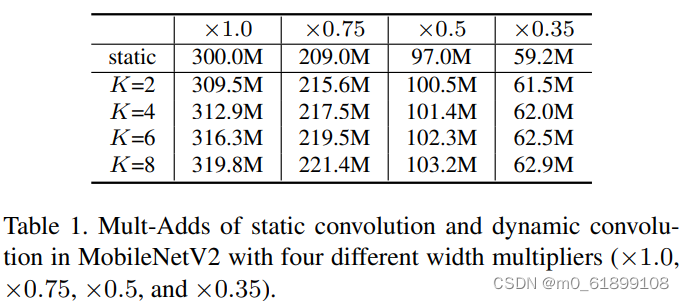
squeeze and excitation提取注意力权值πk(x),见上图。与SENet的不同之处在于:SENet为通道赋予注意力机制,而动态卷积为卷积核赋予注意力机制。 - 核集成:由于核比较小,故而核集成过程是计算高效的。下表给出了动态卷积与静态卷积的计算量对比。从中可以看到:计算量提升非常有限。
- 动态CNN:动态卷积可以轻易的嵌入替换现有网络架构的卷积,比如1x1卷积, 3x3卷积,组卷积以及深度卷积。与此同时,它与其他技术(如SE、ReLU6、Mish等)存在互补关系。
Training Strategy
训练深层动态卷积神经网络极具挑战,因其需要同时优化卷积核与注意力部分。因此,提出了两种见解来进行更有效的联合优化。




实验

与condconv的比较:
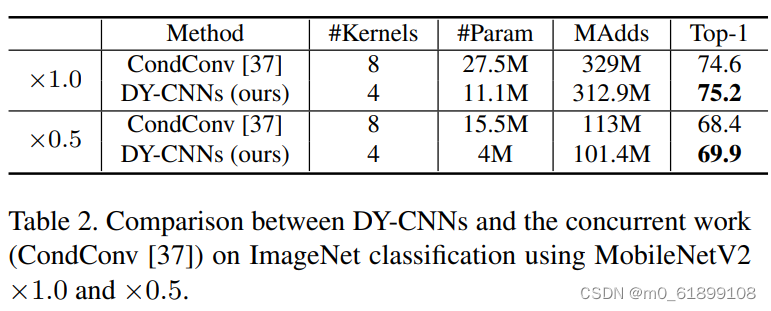
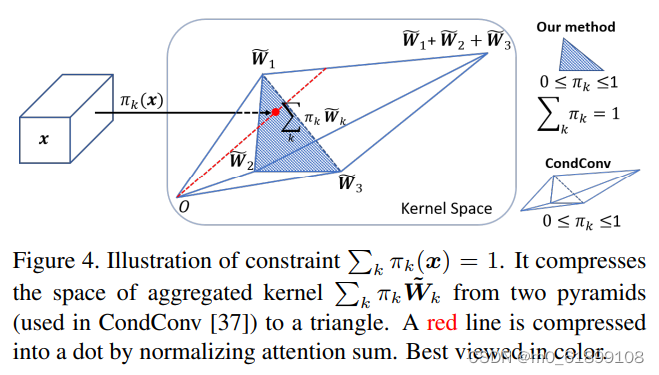
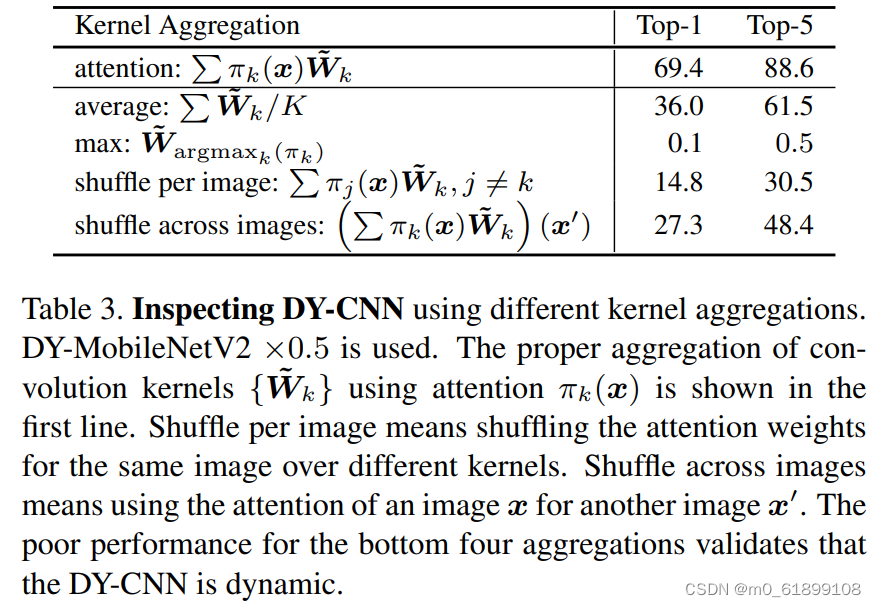
作者对动态卷积的期望属性为:(1)每层的动态卷积具有灵活性;(2)注意力机制 与输入 有关。对于第一个属性(如果不具有灵活性,那么不同的注意力会导致相似的性能,而实际上差异非常大),作者采用了不同的注意力进行验证,性能对比见下表。
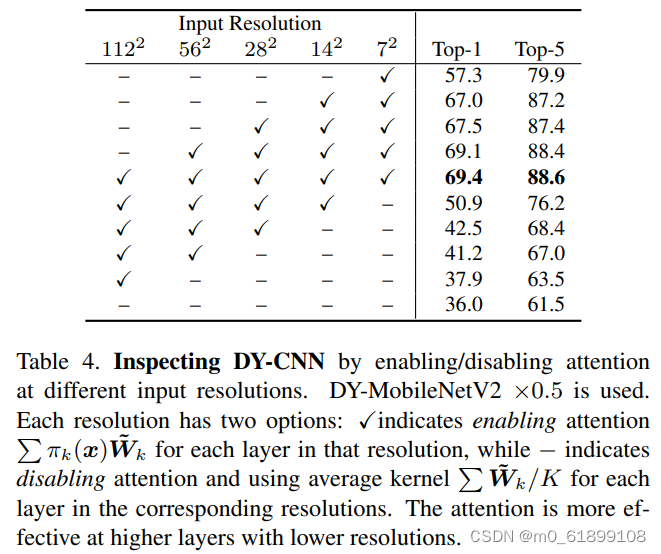
下表给出了注意力是如何跨层影响模型性能的:
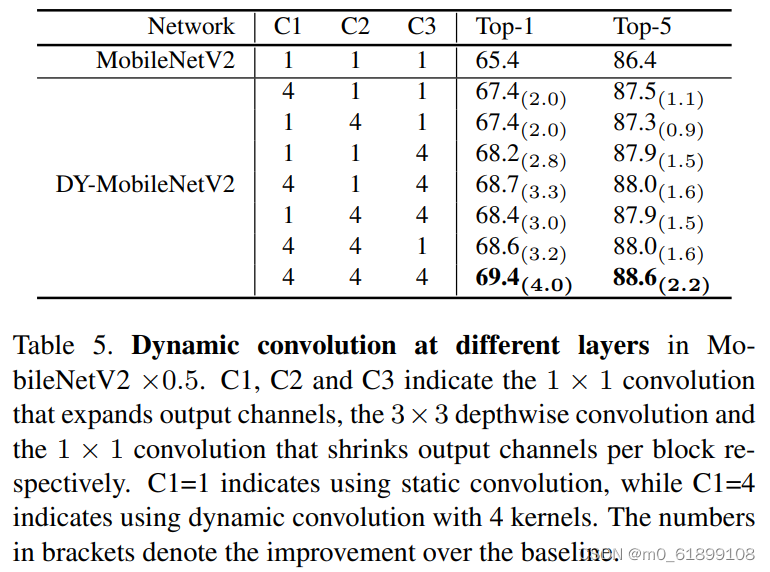
在不同层使用动态卷积的增益:
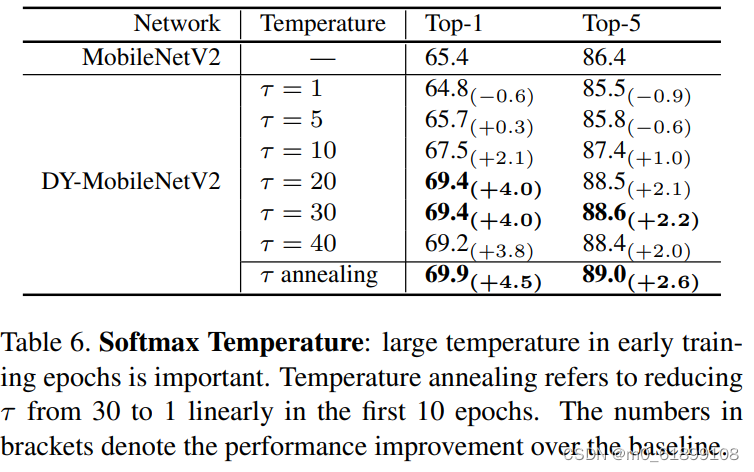
退火温度的影响:
是否使用se的比较:

代码实现
讲解
一句话描述下文内容:将batch size的大小视为分组卷积里面的组的大小进行动态卷积。如batch size=128,就转化成group=128,batch size=1的分组卷积。

推理的时候:红色框住的参数是固定的,黄色框住的参数是随着输入的数据不断变化的
对于卷积过程中生成的一个特征图x,先对特征图做几次运算,生成K个和为1的参数π_k,然后对K个卷积核参数进行线性求和,这样推理的时候卷积核是随着输入的变化而变化的。
下面是文章中 K 个卷积核求和的公式:
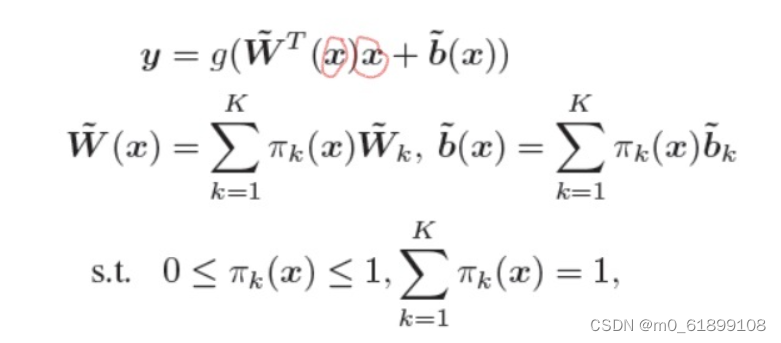
其中 x 是输入, y 是输出;可以看到 x 进行了两次运算,一次用于求注意力的参数(用于生成动态的卷积核),一次用于被卷积。先回顾一下Pytorch里面的卷积参数,然后描述一下可能会出现的问题,再讲解如何通过分组卷积去解决问题。
输入输出
从维度的视角回顾一下Pytorch里面的卷积的实现(输入维度、输出维度、正常卷积核参数维度、分组卷积维度、动态卷积维度、attention模块输出维度)。

可能出现的问题

分组卷积以及如何通过分组卷积实现 batch_size 大于1的动态卷积


pytorch代码
简易版本
# https://github.com/kaijieshi7/Dynamic-convolution-Pytorch
# 简易版本,未设置T
# attention代码的简易版本,输出的是[ batch_size , K ]大小的加权参数。 K 对应着要被求和的卷积核数量。
class attention2d(nn.Module):
def __init__(self, in_planes, K,):
super(attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_planes, K, 1,)
self.fc2 = nn.Conv2d(K, K, 1,)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return F.softmax(x, 1)
class Dynamic_conv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, K=4,):
super(Dynamic_conv2d, self).__init__()
assert in_planes%groups==0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = attention2d(in_planes, K, )
self.weight = nn.Parameter(torch.Tensor(K, out_planes, in_planes//groups, kernel_size, kernel_size), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.Tensor(K, out_planes))
else:
self.bias = None
def forward(self, x):#将batch视作维度变量,进行组卷积,因为组卷积的权重是不同的,动态卷积的权重也是不同的
softmax_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width)# 变化成一个维度进行组卷积
weight = self.weight.view(self.K, -1)
# 动态卷积的权重的生成, 生成的是batch_size个卷积参数(每个参数不同)
aggregate_weight = torch.mm(softmax_attention, weight).view(-1, self.in_planes, self.kernel_size, self.kernel_size)
if self.bias is not None:
aggregate_bias = torch.mm(softmax_attention, self.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggregate_bias, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups*batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
return output完整版本
# https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/conv/DynamicConv.py
import torch
from torch import nn
from torch.nn import functional as F
class Attention(nn.Module):
def __init__(self,in_planes,ratio,K,temprature=30,init_weight=True):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.temprature=temprature
assert in_planes>ratio
hidden_planes=in_planes//ratio
self.net=nn.Sequential(
nn.Conv2d(in_planes,hidden_planes,kernel_size=1,bias=False),
nn.ReLU(),
nn.Conv2d(hidden_planes,K,kernel_size=1,bias=False)
)
if(init_weight):
self._initialize_weights()
def update_temprature(self):
if(self.temprature>1):
self.temprature-=1
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m ,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self,x):
att=self.avgpool(x) #bs,dim,1,1
att=self.net(att).view(x.shape[0],-1) #bs,K
return F.softmax(att/self.temprature,-1)
class DynamicConv(nn.Module):
def __init__(self,in_planes,out_planes,kernel_size,stride,padding=0,dilation=1,grounps=1,bias=True,K=4,temprature=30,ratio=4,init_weight=True):
super().__init__()
self.in_planes=in_planes
self.out_planes=out_planes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=grounps
self.bias=bias
self.K=K
self.init_weight=init_weight
self.attention=Attention(in_planes=in_planes,ratio=ratio,K=K,temprature=temprature,init_weight=init_weight)
self.weight=nn.Parameter(torch.randn(K,out_planes,in_planes//grounps,kernel_size,kernel_size),requires_grad=True)
if(bias):
self.bias=nn.Parameter(torch.randn(K,out_planes),requires_grad=True)
else:
self.bias=None
if(self.init_weight):
self._initialize_weights()
#TODO 初始化
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
def forward(self,x):
bs,in_planels,h,w=x.shape
softmax_att=self.attention(x) #bs,K
x=x.view(1,-1,h,w)
weight=self.weight.view(self.K,-1) #K,-1
aggregate_weight=torch.mm(softmax_att,weight).view(bs*self.out_planes,self.in_planes//self.groups,self.kernel_size,self.kernel_size) #bs*out_p,in_p,k,k
if(self.bias is not None):
bias=self.bias.view(self.K,-1) #K,out_p
aggregate_bias=torch.mm(softmax_att,bias).view(-1) #bs,out_p
output=F.conv2d(x,weight=aggregate_weight,bias=aggregate_bias,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
else:
output=F.conv2d(x,weight=aggregate_weight,bias=None,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
output=output.view(bs,self.out_planes,h,w)
return output
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)动态卷积论文合集
GitHub - kaijieshi7/awesome-dynamic-convolution: Dynamic convolution Paper collection.
Dynamic Filter Networks Jia X, De Brabandere B, Tuytelaars T, 2016
Dynamic deep neural networks: Optimizing accuracy-efficiency trade-offs by selective execution Liu L, Deng J. 2017
SkipNet: Learning Dynamic Routing in Convolutional Networks Wang X, Yu F, Dou Z Y, 2017
Condconv: Conditionally parameterized convolutions for efficient inference Yang B, Bender G, Le Q V, 2019
Pay Less Attention with Lightweight and Dynamic Convolutions Wu F, Fan A, Baevski A, 2019
Dynamic convolution: Attention over convolution kernels Chen Y, Dai X, Liu M, 2020
WeightNet: Revisiting the Design Space of Weight Networks Ma N, Zhang X, Huang J, 2020
DyNet: Dynamic Convolution for Accelerating Convolutional Neural Networks Zhang Y, Zhang J, Wang Q, 2020
Unified Dynamic Convolutional Network for Super-Resolution with Variational Degradations Xu Y S, Tseng S Y R, Tseng Y, 2020
Context Modulated Dynamic Networks for Actor and Action Video Segmentation with Language QueriesWang H, Deng C, Ma F, et al, 2020
边栏推荐
猜你喜欢


随机推荐
js - the first letter that appears twice
redis分布式锁的实现
金仓数据库KingbaseES客户端编程接口指南-JDBC(10. JDBC 读写分离最佳实践)
电脑系统数据丢失了是什么原因?找回方法有哪些?
中职网络安全竞赛B模块新题
GBase 8c中怎么查询数据库配置参数,例如datestyle。使用什么函数或者语法呢?
Typora_Markdown_图片标题(题注)
New Questions in Module B of Secondary Vocational Network Security Competition
经典递归回溯问题之——解数独(LeetCode 37)
智汇华云 | 华云软件定义网络 DCI介绍
使用单调栈解决接雨水问题——LeetCode 42 接雨水+单调栈说明
线程和进程之间的区别
推荐几种可以直接翻译PDF英文文献的方法
安装GBase 8c数据库的时候,报错显示“Resource:gbase8c already in use”,这怎么处理呢?
25.时间序列预测实战
YOLOv5应用轻量级通用上采样算子CARAFE
IDEA引入类报错:“The file size (2.59 MB) exceeds the configured limit (2.56MB)
一天搞定JDBC01:连接数据库并执行sql语句
LeetCode 97. 交错字符串
分布式计算实验2 线程池