当前位置:网站首页>Paper reading [MM21 pre training for video understanding challenge:video captioning with pre training techniqu]
Paper reading [MM21 pre training for video understanding challenge:video captioning with pre training techniqu]
2022-07-07 05:34:00 【hei_ hei_ hei_】
MM21 Pre-training for Video Understanding Challenge:Video Captioning with Pretraining Technique
summary
- publish :ACMM 2021
- idea: Use X-Linear Attention, reference XLAN Right Multi-modality Feature To merge , Propose a multi-path XLAN The model can fuse multiple single-mode features , Get a better fused feature . In addition, in the video understanding pre training model competition, through data expansion technology and integration multi-path XLAN(early fuse) And fine tuning pretrained OPT(late fuse) Get first
Detailed design
1. Single-Modality Pretrained Feature Fusion
Multi-Modality Feature Extraction
Almost all modal features in the video are considered , Include :
(1)appearance feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):FixResNeXt-101 network pretrained on the ImageNet-1k dataset
(2)motion feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):irCSN-152 network pretrained on the Kinetics-400 dataset
(3)region feature( 50 f r a m e s ∗ 2048 d i m s 50 frames * 2048 dims 50frames∗2048dims):vinvl model pretrained on Visual Genome dataset
(4)audio feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):CNN14 network pretrained on the AudioSet datasetMulti-Modality Feature Fusion
The feeling is OPT+XLAN, Almost nothing has changed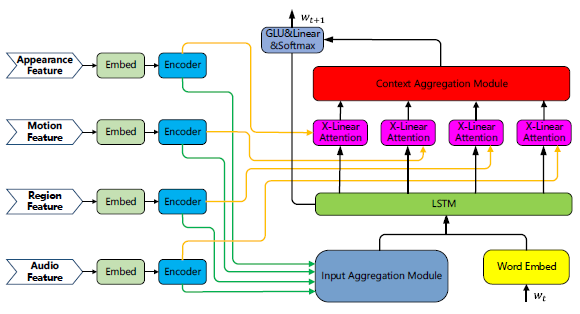
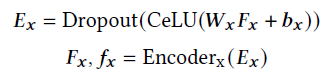
F x F_x Fx Represents the input feature , E x E_x Ex It mainly embeds various modal features into the same semantic hidden space , E n c o d e r x Encoder_x Encoderx yes XLAN encoder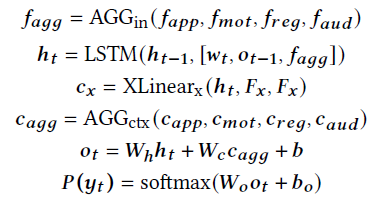
there A G G i n AGG_in AGGin and A G G c t x AGG_ctx AGGctx Indicates the aggregation method , There are several options :average pooling、concatenation、additional attention
2. Multi-Modality Pretrained Model Finetuning
Yes pretrained Omni-Perception Pre-Trainer model (OPT) Fine tuning .
- OPT
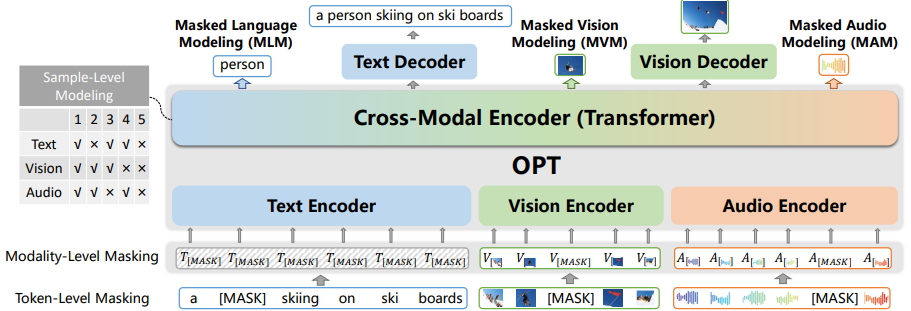
Use three... Respectively encoder To text 、 picture 、 The sound is encoded and the features are converted to the same latent space; And then use transformer Fuse the three features (inter- and intra interactions), Then access text decoder and visual decoder Generate text and pictures respectively . At the same time token-level、modality-level and sample-level To make the model have the ability of cross modal understanding and generation . The author uses MSR-VTT Fine tune the dataset .
experiment
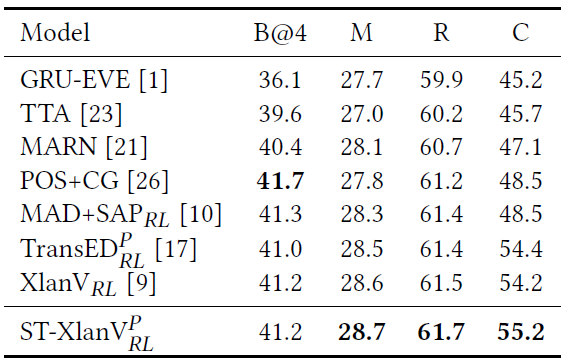
- Ablation Studies
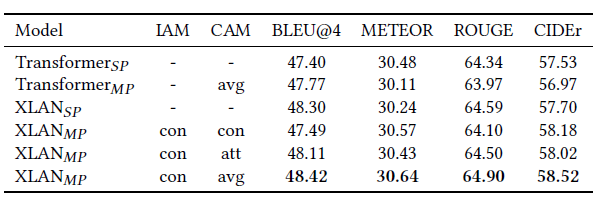
S P SP SP Direct transfer multi-modality features concate Then proceed reduce dimension To 1024 Then input encoder-decoder Of XLAN/Transformer modal in - Comparison to State-of-the-art
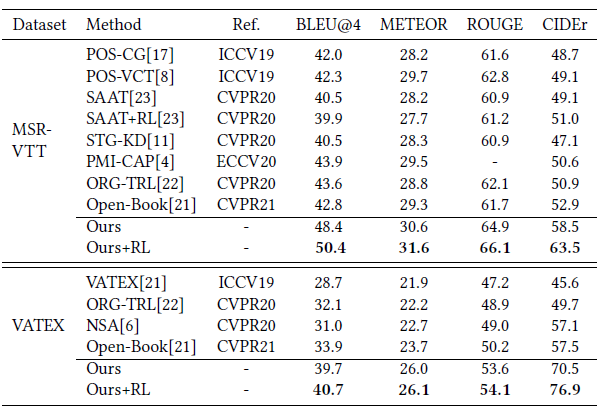
+ R L +RL +RL Indicates that it is used in fine-tuning reinforcement learning
边栏推荐
- K6el-100 leakage relay
- Annotation初体验
- Linkedblockingqueue source code analysis - initialization
- How does redis implement multiple zones?
- Mapbox Chinese map address
- Sorry, I've learned a lesson
- [optimal web page width and its implementation] [recommended collection "
- sql优化常用技巧及理解
- Torch optimizer small parsing
- Cve-2021-3156 vulnerability recurrence notes
猜你喜欢
Autowired注解用于List时的现象解析

张平安:加快云上数字创新,共建产业智慧生态
Lombok插件
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
K6EL-100漏电继电器
How does mapbox switch markup languages?
不同网段之间实现GDB远程调试功能
Leetcode 1189 maximum number of "balloons" [map] the leetcode road of heroding
![[JS component] custom select](/img/9d/f7f15ec21763c40b9bb6a053d90ee4.jpg)
[JS component] custom select

DOM node object + time node comprehensive case
随机推荐
人体传感器好不好用?怎么用?Aqara绿米、小米之间到底买哪个
Make web content editable
Two person game based on bevy game engine and FPGA
说一说MVCC多版本并发控制器?
高压漏电继电器BLD-20
淘宝店铺发布API接口(新),淘宝oAuth2.0店铺商品API接口,淘宝商品发布API接口,淘宝商品上架API接口,一整套发布上架店铺接口对接分享
Under the trend of Micah, orebo and apple homekit, how does zhiting stand out?
Leakage relay jd1-100
Simulate thread communication
The year of the tiger is coming. Come and make a wish. I heard that the wish will come true
JHOK-ZBG2漏电继电器
淘寶商品詳情頁API接口、淘寶商品列錶API接口,淘寶商品銷量API接口,淘寶APP詳情API接口,淘寶詳情API接口
As we media, what websites are there to download video clips for free?
How can professional people find background music materials when doing we media video clips?
Dbsync adds support for mongodb and ES
项目经理如何凭借NPDP证书逆袭?看这里
Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
导航栏根据路由变换颜色
How does redis implement multiple zones?
High voltage leakage relay bld-20