当前位置:网站首页>论文阅读【Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention】
论文阅读【Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention】
2022-07-06 23:35:00 【hei_hei_hei_】
Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
概要
- 发表:ACMM 2021
- 代码:MMAC
- idea:本文提出了一种新的视频描述任务,以自我为中心的视觉描述(例如第一人称视角、第三人称视角),可以用于更近距离的视觉描述。同时,为了缓解设备等原因可能导致的运动模糊、遮挡等问题,使用传感器进行视觉描述的辅助工具。
在网络设计上,主要是两大模块:AMMT模块用于合并视觉特征 h v h_v hv和传感器特征 h s h_s hs得到合并的特征 h V + S h_{V+S} hV+S,然后将这三种特征( h v , h s , h V + S h_v, h_s, h_{V+S} hv,hs,hV+S)输入到DMA模块中对其进行选择性的注意力学习。然后输入GRU中进行word生成
详细设计
1. 特征提取
- 视觉特征 h V h_V hV:Vgg16
- 传感器特征 h S h_S hS:LSTM(时序)
2. Asymmetric Multi-modal Transformation(AMMT)
实质上是特征合并
出处:FiLM: Visual Reasoning with a General Conditioning Layer,知识点参考feature-wise linear modulation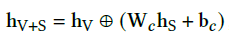
ps:初始化 W c = I , b c = 0 W_c=I, b_c=0 Wc=I,bc=0,即初始化为concate,随着训练的深入,学习二者的合并特征
注意这里输出的特征是三种特征:
(1) 视觉特征 h V h_V hV
(2)传感器特征 h S h_S hS
(3)合并的特征 h V + S h_{V+S} hV+S
- 一些使用不对称的解释
一方面缓解数据冗余可能带来的过拟合;另一方面,传感器数据中有时包含不需要的噪声,因此需要对它进行调节。
3. Dynamic Modal Attention (DMA)
对三种特征进行动态选择注意力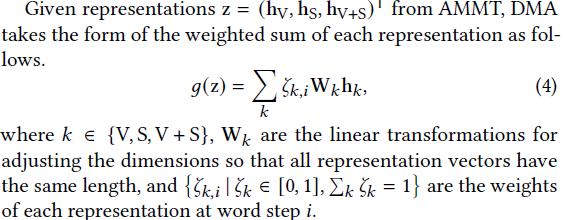
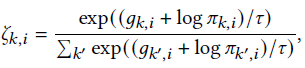

这里使用了Gumbel Softmax
ps:使用三种特征的原因:因为在许多情况下,只使用单一模态是可取的(例如,包含不需要的噪声的传感器数据)。
边栏推荐
- How does redis implement multiple zones?
- Summary of the mean value theorem of higher numbers
- Full link voltage test: the dispute between shadow database and shadow table
- 最长不下降子序列(LIS)(动态规划)
- Pytest testing framework -- data driven
- SQL injection cookie injection
- 背包问题(01背包,完全背包,动态规划)
- 【问道】编译原理
- 模拟线程通信
- y58.第三章 Kubernetes从入门到精通 -- 持续集成与部署(三一)
猜你喜欢
利用OPNET进行网络仿真时网络层协议(以QoS为例)的使用、配置及注意点
Use, configuration and points for attention of network layer protocol (taking QoS as an example) when using OPNET for network simulation
c语言神经网络基本代码大全及其含义
全链路压测:影子库与影子表之争
Torch optimizer small parsing

【js组件】自定义select

JHOK-ZBG2漏电继电器
![[JS component] date display.](/img/26/9bfc752c8c9a933a8e33b59e0488a2.jpg)
[JS component] date display.

ThinkPHP Association preload with

数字化如何影响工作流程自动化
随机推荐
数字化创新驱动指南
DFS,BFS以及图的遍历搜索
线程同步的两个方法
Mysql database learning (7) -- a brief introduction to pymysql
Under the trend of Micah, orebo and apple homekit, how does zhiting stand out?
做自媒体,有哪些免费下载视频剪辑素材的网站?
【QT】自定义控件-Loading
Where is NPDP product manager certification sacred?
PMP证书有没有必要续期?
项目经理如何凭借NPDP证书逆袭?看这里
[QT] custom control loading
MySQL数据库学习(7) -- pymysql简单介绍
Operand of null-aware operation ‘!‘ has type ‘SchedulerBinding‘ which excludes null.
高压漏电继电器BLD-20
在米家、欧瑞博、苹果HomeKit趋势下,智汀如何从中脱颖而出?
Is PMP really useful?
U++ metadata specifier learning notes
JHOK-ZBL1漏电继电器
一条 update 语句的生命经历
HarmonyOS第四次培训