当前位置:网站首页>Transfer Learning - Distant Domain Transfer Learning
Transfer Learning - Distant Domain Transfer Learning
2022-08-05 01:48:00 【orokok】
《Distant Domain Transfer Learning》学习
Thirty
文章目录
摘要
Different from existing transfer learning problems that assume a close relationship between source and target domains,In distributed time series classification problem,目标域可以与源域完全不同.
受人类认知过程的启发,Two seemingly unrelated concepts can be connected by progressively learning intermediate concepts,We propose a selective learning algorithm(SLA)来解决DDTL问题,where supervised autoencoders or supervised convolutional autoencoders are used as base models for processing different types of inputs.
直观地说,SLAAlgorithms gradually select useful unlabeled data from intermediate domains as bridges,To break the transfer between two distant domain knowledge of great distribution gap.Empirical studies on image classification problems demonstrate the effectiveness of the algorithm,在某些任务中,分类精度比“non-transfer”方法提高了17%.
一、介绍
An essential requirement for successful knowledge transfer is that the source and target domains should be closely related.This relationship can be a related instance、form of features or models,并通过KL散度或A-Distance测量.
tags for headers,We can build accurate learners,Because there is a lot of labeled data,but at the end,Due to scarcity of labeled data,Learners per label often do not perform satisfactorily.
在这种情况下,We can reuse the knowledge of the head by,Use transfer learning algorithms to build accurate classifiers for labels in the tail.When the label at the tail is related to the label at the head,This strategy usually works well.
DDTL问题至关重要,Because solving it can greatly expand the application scope of transfer learning,and help reuse as much previous knowledge as possible.
然而,这是一个困难的问题,Because the distribution gap between the source domain and the target domain is very large.
People act as bridges through one or more intermediate concepts,Transfer knowledge between two seemingly unrelated concepts.
沿着这条路线,There are some works that aim to solveDDTL问题.例如Tan(2015)Bring in annotated images,Build a knowledge transfer bridge between source domain text data and target domain image data,Xie(2016)Use some nighttime light intensity information as an intermediate bridge,By transferring knowledge from object classification tasks,Poverty prediction based on daytime satellite imagery.
These studies assume only one intermediate domain,All data in the intermediate domain is useful.
然而,在某些情况下,Far domains can only be associated through multiple intermediate domains.Just use a middle areas across long distance transfer knowledge is not enough to help.
此外,Given multiple intermediate domains,It is likely that only a subset of data from each intermediate domain is useful to the target domain,Therefore we need an automatic selection mechanism to determine the subset.
We use reconstruction error as a measure of distance between two domains.
即,If the model trained on the target domain,of some data points in the source domainData reconstruction error较小,Then we think that these data points in the source domain are helpful to the target domain.
在此基础上,我们提出了一种针对DDTL问题的选择性学习算法(SLA),The algorithm selects useful instances from both source and intermediate domains,Learn high-level representations of selected data,and train a classifier against the target domain.
SLAThe learning process is an iterative process,Optionally add new data points from intermediate domains,and delete the useless data in the source domain,Step-by-step modification of source-specific models,Shift to a target-specific model,直到满足某个停止条件
本文的贡献有三个方面.
- 首先,据我们所知,This is the first study using a hybrid intermediate domainDDTL问题的工作.
- 其次,我们提出了一种DDTL的SLA算法.
- 第三,We conduct extensive experiments on multiple real-world datasets,to prove the effectiveness of the proposed algorithm.
二、相关工作
Typical transfer learning algorithms include instance weighting methods(Dai et al. 2007),Feature Mapping Methods(Pan et al. 2011),model adaptation method(Aytar和Zisserman 2011).
然而,These methods cannot handleDDTL问题,because they assume that the source and target domains are conceptually close.
在TTL中,only one intermediate domain,Manually selected by the user,and use all the intermediate domain data.
与TTL不同的是,Our work automatically selects subsets from a mixture of multiple intermediate domains as bridges between source and target domains.
TLMSThere are two differences from our work.首先,TLMSAll source domains in have sufficient labeled data.其次,TLMSAll source domains in are close to the target domain.
STLThere are two differences from our work.首先,STLThere is no such thing as the source domain.其次,STLThe goal is to use all the unlabeled data from different domains to help the learning of the target domain,Whereas our work aims to identify useful subsets of instances from intermediate domains,to connect the source and target domains.
我们的工作与SSAThere are three differences.
- 首先,在SSA中,Both unlabeled data and labeled data come from the same domain,而在我们的工作中,Tagged data either comes from the source domain,either from the target domain,Unlabeled data from a mix of intermediate domains,The distribution of intermediate domains can be very different.
- 其次,SSALearn with all labeled and unlabeled data,While our work from the middle domain selectively choose some data without a label,and remove some labeled data from the source domain,to aid learning in the target domain.
- 第三,SSAno convolutional layers,Whereas our work uses convolutional filters when the input is a matrix or tensor.
三、问题定义
我们用 S = { ( x S 1 , y S 1 ) , ⋅ ⋅ ⋅ , ( x S n S , y S n S ) } S = \{(x^1_S, y^1_S),···,(x^{n_S}_S, y^{n_S}_S)\} S={(xS1,yS1),⋅⋅⋅,(xSnS,ySnS)}表示大小为 n S n_S nSsource domain tag data for,consider it sufficient to train an accurate classifier on the source domain,用 T = { ( x T 1 , y T 1 ) , ⋅ ⋅ ⋅ , ( x T n T , y T n T ) } T = \{(x^1_T, y^1_T),···,(x^{n_T}_T, y^{n_T}_T)\} T={(xT1,yT1),⋅⋅⋅,(xTnT,yTnT)}表示大小为 n T n_T nTtarget domain tag data for,consider it insufficient to learn an accurate classifier for the target domain.此外,我们用 I = { x I 1 , ⋅ ⋅ ⋅ , x I n I } I = \{x^1_I,···,x^{n_I}_I\} I={ xI1,⋅⋅⋅,xInI}A mixture of unlabeled data representing multiple intermediate domains,其中假设 n I n_I nI足够大.
在这项工作中,Domains correspond to concepts or classes of specific classification problems,例如从图像中识别人脸或飞机.在不丧失一般性的前提下,We assume that both the source and target domain classification problems are binary.All data points should be in the same feature space.设 p S ( x ) 、 p S ( y ∣ x ) 、 p S ( x , y ) p_S(x)、p_S(y|x)、p_S(x, y) pS(x)、pS(y∣x)、pS(x,y)are the marginal distributions of the source domain data, respectively、条件分布和联合分布, p T ( x ) 、 p T ( y ∣ x ) 、 p T ( x , y ) p_T (x)、p_T (y|x)、p_T (x, y) pT(x)、pT(y∣x)、pT(x,y)Parallel definition for the target domain, p I ( x ) p_I(x) pI(x)is the marginal distribution of the intermediate domain.在DDTL问题上,我们有
p T ( x ) ≠ p S ( x ) , p T ( x ) ≠ p I ( x ) , a n d p S ( y ∣ x ) ≠ p T ( y ∣ x ) p_T(x)\ne p_S(x),p_T(x)\ne p_I(x),and\quad p_S(y|x)\ne p_T(y|x) pT(x)=pS(x),pT(x)=pI(x),andpS(y∣x)=pT(y∣x)
DDTLThe purpose is to use the unlabeled data of the intermediate domain to build a bridge between the source and target domains that are otherwise far apart,and utilize bridges to transfer supervised knowledge from the source domain to the target domain,Train an accurate classifier for the target domain.
四、选择性学习算法
4.1自动编码器及其变体
An autoencoder is an unsupervised feedforward neural network,it has an input layer、一个或多个隐藏层和一个输出层.它通常包括两个过程:编码和解码.
给定一个输入 x ∈ R q x\in \mathbb{R}^q x∈Rq,The autoencoder first passes the encoding function f e ( ⋅ ) f_e(·) fe(⋅)对其进行编码,Map it to a hidden said,Then pass the decode function f d ( ⋅ ) f_d(·) fd(⋅)对其进行解码,重构x.自动编码器的过程可以总结为
编码: h = f e ( x ) h=f_e(x) h=fe(x),解码: x ^ = f d ( h ) \hat x=f_d(h) x^=fd(h)
其中 x ^ \hat x x^是近似 x x x的重构输入.Encoding and decoding function pair f e ( ⋅ ) f_e(·) fe(⋅)和 f d ( ⋅ ) f_d(·) fd(⋅)The learning of is done by minimizing the reconstruction error of all training data,即 min f e , f d ∑ i = 1 n ∥ x ^ i − x i ∥ 2 2 \min_{f_e,f_d}\sum^n_{i=1}\|\hat x_i-x_i\|^2_2 minfe,fd∑i=1n∥x^i−xi∥22
After learning to encode and decode function pairs,输入 x x xthe output of the encoding function,即 h = f e ( x ) h=f_e(x) h=fe(x)被认为是 x x xA high-level and robust representation of.
注意,Autoencoder accepts a vector as input.when a matrix or tensor(比如图像)represents when the input instance is submitted to an autoencoder,Spatial information for this instance may be discarded.在这种情况下,More need for convolutional autoencoders,It is a variant of autoencoder,Capture the input by adding one or more convolutional layers,and one or more corresponding deconvolution layers to generate the output.
4.2通过重构误差进行实例选择
在实践中,Since the source and target domains are far apart,Perhaps only a subset of the source domain data is useful to the target domain.In the middle region the situation is similar.因此,为了从中间域中选择有用的实例,and remove irrelevant instances from the source domain for the target domain,We propose to learn a pair of encoding and decoding functions by minimizing the reconstruction error of selected instances in the source and intermediate domains and all instances in the target domain.The objective function expression to be minimized is:
J 1 ( f e , f d , v S , v T ) = 1 n S ∑ i = 1 n S v S i ∥ x ^ S i − x S i ∥ 2 2 + 1 n I ∑ i = 1 n I v I i ∥ x ^ I i − x I i ∥ 2 2 + 1 n T ∑ i = 1 n T ∥ x ^ T i − x T i ∥ 2 2 + R ( v S , v I ) (1) \begin{aligned} \mathcal{J}_{1}\left(f_{e}, f_{d}, \boldsymbol{v}_{S}, \boldsymbol{v}_{T}\right)=& \frac{1}{n_{S}} \sum_{i=1}^{n_{S}} v_{S}^{i}\left\|\hat{\boldsymbol{x}}_{S}^{i}-\boldsymbol{x}_{S}^{i}\right\|_{2}^{2}+\frac{1}{n_{I}} \sum_{i=1}^{n_{I}} v_{I}^{i}\left\|\hat{\boldsymbol{x}}_{I}^{i}-\boldsymbol{x}_{I}^{i}\right\|_{2}^{2} \\ &+\frac{1}{n_{T}} \sum_{i=1}^{n_{T}}\left\|\hat{\boldsymbol{x}}_{T}^{i}-\boldsymbol{x}_{T}^{i}\right\|_{2}^{2}+R\left(\boldsymbol{v}_{S}, \boldsymbol{v}_{I}\right) \end{aligned}\tag{1} J1(fe,fd,vS,vT)=nS1i=1∑nSvSi∥∥x^Si−xSi∥∥22+nI1i=1∑nIvIi∥∥x^Ii−xIi∥∥22+nT1i=1∑nT∥∥x^Ti−xTi∥∥22+R(vS,vI)(1)
其中 x ^ S i \hat{\boldsymbol{x}}_{S}^{i} x^Si, x ^ I i \hat{\boldsymbol{x}}_{I}^{i} x^Ii和 x ^ T i \hat{\boldsymbol{x}}_{T}^{i} x^Tiis based on an autoencoder x S i \boldsymbol{x}_{S}^{i} xSi, x I i \boldsymbol{x}_{I}^{i} xIi和 x T i \boldsymbol{x}_{T}^{i} xTi的重构,
v S = ( v S 1 , ⋅ ⋅ ⋅ , v S n S ) T , v I = ( v I 1 , ⋅ ⋅ ⋅ , v I n S ) T ,和 v S i , v I j ∈ { 0 , 1 } \boldsymbol{v}_{S} = (v^1_{S},···,v^{n_S}_{S})^T,\boldsymbol{v}_{I} = (v^1_{I},···,v^{n_S}_{I})^T,和v^i_S, v^j_ I\in\{0,1\} vS=(vS1,⋅⋅⋅,vSnS)T,vI=(vI1,⋅⋅⋅,vInS)T,和vSi,vIj∈{ 0,1}respectively in the source domain i i i个实例和中间域中第 j j jInstance selection metrics.
当值为1时,选择对应的实例,否则不选择.last item in target R ( v S , v I ) R\left(\boldsymbol{v}_{S}, \boldsymbol{v}_{I}\right) R(vS,vI)是对 v S \boldsymbol{v}_{S} vS和 v I \boldsymbol{v}_{I} vI的正则化项,通过设置 v S \boldsymbol{v}_{S} vS和 v I \boldsymbol{v}_{I} vIall values of is zero to avoid trivial solutions.本文将 R ( v S , v I ) R\left(\boldsymbol{v}_{S}, \boldsymbol{v}_{I}\right) R(vS,vI)定义为
R ( v S , v I ) = − λ S n S ∑ i = 1 n S v S i − λ I n I ∑ i = 1 n I v I i R\left(\boldsymbol{v}_{S}, \boldsymbol{v}_{I}\right)=-\frac{\lambda_S}{n_S}\sum^{n_S}_{i=1}v^i_S-\frac{\lambda_I}{n_I}\sum^{n_I}_{i=1}v^i_I R(vS,vI)=−nSλSi=1∑nSvSi−nIλIi=1∑nIvIi
Minimizing this term is equivalent to encouraging the selection of as many instances as possible from the source and intermediate domains.两个正则化参数 λ S \lambda_S λS和 λ I \lambda_I λIControls the importance of the regular term.请注意,More useful instance selected,More robust hidden representations can be learned by autoencoders.
4.3Incorporation of auxiliary information
By solving the minimization problem(1),可以通过 v S \boldsymbol{v}_{S} vS和 v T \boldsymbol{v}_{T} vTUseful instances for selecting target domains from source and intermediate domains,and pass the encoding function h = f e ( x ) h=f_e(x) h=fe(x)Simultaneously learn high-level hidden representations for data from different domains.
然而,The learning process is done in an unsupervised manner.因此,The learned hidden representation may not be relevant to the classification problem of the target domain.
This motivates us to incorporate auxiliary information when learning hidden representations for different domains.
具体来说,We propose to minimize the following function by,Incorporate auxiliary information into learning:
J 2 ( f c , f e , f d ) = 1 n S ∑ i = 1 n S v S i ℓ ( y S i , f c ( h S i ) ) + 1 n T ∑ i = 1 n T ℓ ( y T i , f c ( h T i ) ) + 1 n I ∑ i = 1 n I v I i g ( f c ( h I i ) ) (2) \begin{aligned} \mathcal{J}_{2}\left(f_{c}, f_{e}, f_{d}\right)=& \frac{1}{n_{S}} \sum_{i=1}^{n_{S}} v_{S}^{i} \ell\left(y_{S}^{i}, f_{c}\left(\boldsymbol{h}_{S}^{i}\right)\right)+\frac{1}{n_{T}} \sum_{i=1}^{n_{T}} \ell\left(y_{T}^{i}, f_{c}\left(\boldsymbol{h}_{T}^{i}\right)\right) \\ &+\frac{1}{n_{I}} \sum_{i=1}^{n_{I}} v_{I}^{i} g\left(f_{c}\left(\boldsymbol{h}_{I}^{i}\right)\right) \end{aligned}\tag{2} J2(fc,fe,fd)=nS1i=1∑nSvSiℓ(ySi,fc(hSi))+nT1i=1∑nTℓ(yTi,fc(hTi))+nI1i=1∑nIvIig(fc(hIi))(2)
式中 f c ( ⋅ ) f_c(·) fc(⋅)classification function for output classification probabilities, g ( ⋅ ) g(·) g(⋅)为 0 ≤ z ≤ 1 0\le z\le1 0≤z≤1时定义为 g ( z ) = − z l n z − ( 1 − z ) l n ( 1 − z ) g(z) =−z ln z−(1−z) ln(1−z) g(z)=−zlnz−(1−z)ln(1−z)的熵函数,Used to select instances with high prediction confidence in the intermediate domain.
4.4总体目标函数
Combine the two objectives in the equation.(1)和(2),我们得到DDTL的最终目标函数如下:
min Θ , v J = J 1 + J 2 , s . t . v S i , v T i ∈ { 0 , 1 } (3) \min_{\boldsymbol{\Theta,v}}\mathcal{J}=\mathcal{J}_{1}+\mathcal{J}_{2},\quad s.t.v^i_S,v^i_T\in\{0,1\}\tag{3} Θ,vminJ=J1+J2,s.t.vSi,vTi∈{ 0,1}(3)
其中 v = { v S , v T } \boldsymbol{v} =\{\boldsymbol{v_S}, \boldsymbol{v_T}\} v={ vS,vT},和 Θ \boldsymbol{\Theta} Θ表示函数 f c ( ⋅ ) , f e ( ⋅ ) 和 f d ( ⋅ ) f_c(·),f_e(·)和f_d(·) fc(⋅),fe(⋅)和fd(⋅)的所有参数
为了解决问题(3),We use block coordinate falloff(block coordinate decenent, BCD)方法,在每次迭代中,Each piece of the variables in the optimization in turn,同时保持其他变量不变.
在问题(3)中,There are two variable blocks: Θ \boldsymbol{\Theta} Θ和 v \boldsymbol{v} v.当 v \boldsymbol{v} vWhen the variable in is fixed,We can use backpropagation(BP)算法更新 Θ \boldsymbol{\Theta} Θ,This makes it easy to compute gradients.反过来,当 Θ \boldsymbol{\Theta} ΘWhen the variable in is fixed,我们可以得到 v \boldsymbol{v} vThe analytical solution is as follows:
v S i = { 1 i f l ( y s i , f c ( f e ( x S i ) ) ) + ∥ x ^ S i − x S i ∥ 2 2 < λ S 0 o t h e r w i s e (4) v^i_S=\begin{cases}1\quad if\mathcal{l}(y^i_s,f_c(f_e(\boldsymbol x^i_S)))+\left\|\hat{\boldsymbol{x}}_{S}^{i}-\boldsymbol{x}_{S}^{i}\right\|_{2}^{2}<\lambda_S\\0\quad otherwise\end{cases}\tag{4} vSi=⎩⎨⎧1ifl(ysi,fc(fe(xSi)))+∥∥x^Si−xSi∥∥22<λS0otherwise(4)
v I i = { 1 i f ∥ x ^ I i − x I i ∥ 2 2 + g ( f c ( f e ( x I i ) ) ) < λ I 0 o t h e r w i s e (5) v^i_I=\begin{cases}1\quad if\left\|\hat{\boldsymbol{x}}_{I}^{i}-\boldsymbol{x}_{I}^{i}\right\|_{2}^{2}+g(f_c(f_e(\boldsymbol x^i_I)))<\lambda_I\\0\quad otherwise\end{cases}\tag{5} vIi=⎩⎨⎧1if∥∥x^Ii−xIi∥∥22+g(fc(fe(xIi)))<λI0otherwise(5)
由式(4)可知,For data in the source domain,In the optimization process, only the reconstruction error is small、data with small training loss.同样,由式(5)可以发现,For the data in the middle area,Only choose the reconstruction error with small、Predict data with high confidence.
There are two aspects to the intuitive explanation of this learning strategy:
- 用一个固定的 Θ \boldsymbol{\Theta} Θ更新 v \boldsymbol{v} v时,in the source domain“无用”的数据删除,Select those intermediate data that can connect the source and target domains for training;
- 在 v \boldsymbol{v} vFixed case update Θ \boldsymbol{\Theta} Θ时,model is only selected“有用”training on data samples.
解决问题(3)The overall algorithm is summarized in Algorithm1中.
问题(3)The corresponding deep learning architecture is shown in the figure2所示.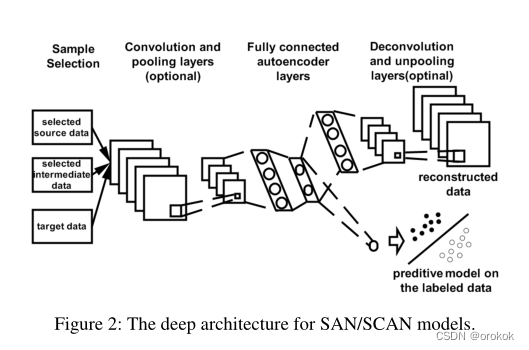
从图2中,We notice that in addition to the instance selection component v \boldsymbol{v} v之外,图2The remaining architectures in can be regarded as a general autoencoder or a convolutional autoencoder, respectively, by incorporating side information.
在续集中,我们将 f e ( ⋅ ) f_e(·) fe(⋅)和 f d ( ⋅ ) f_d(·) fd(⋅)使用antoencoder的架构(In addition to instance selection components)称为SAN (Supervised AutoeNcoder),将卷积antoencoder用作SCAN (Supervised convolutional AutoeNcoder).
五、实验
在本节中,We propose three aspectsSLAAlgorithms were empirically studied
- 首先,When the source and target domains are far apart,验证了算法的有效性.
- 其次,We visualize selected intermediate data,to understand how the algorithm works.
- 第三,我们通过将SLAThe generated intermediate instance learning order is compared with other human-designed orders to evaluate the importance of the intermediate instance learning order.
5.1基线方法
Using the three-class approach as a baseline
- 监督式学习
在这一类中,We selected two supervised learning algorithms,SVM和卷积神经网络(CNN)作为基线.
对于SVM,We use a linear kernel function.对于CNN,We implemented a nuclear size is 3 × 3 3 \times 3 3×3A network of two convolution layer,where each convolutional layer is followed by a kernel of size 2 × 2 2 \times 2 2×2的max pooling层、A fully connected layer and a logistic regression layer. - 转移学习
在这一类中,We selected five transfer learning algorithms,including adaptive support vector machines(ASVM) (Aytar和Zisserman 2011),geodetic core(GFK) (Gong等人2012),Landmark (LAN) (Gong, Grauman和Sha 2013),深度迁移学习(DTL) (Y osinski等人2014)and transfer transfer learning(TTL) (Tan等人2015). - 自学(STL)
We apply autoencoders or convolutional autoencoders on all intermediate domain data to learn a general feature representation,The classifier is then trained with the new feature representation using all source and target domain labeled data
in these baselines,CNNCan receive tensors as input,DTL和STLCan receive both vectors and tensors as input,while other models can only receive vectors as input.SCANThe convolutional autoencoder component used inCNNModels have the same network structure,The difference is that the fully connected layer connects the twounpoolinglayer and two deconvolution layers to reconstruct the input.For all deep learning based models,We use all training data for pre-training.
5.2数据集
实验使用的数据集包括Caltech-256 (Griffin, Holub和Perona 2007)And animal attribute(AwA).
Caltech-256数据集包含256个对象类别的30607张图像,The number of instances for each class starts from80到827不等.
AwA数据集包含50animal category30475张图像,The number of samples for each class starts from92到1168不等.
5.3性能比较
在实验中,for each target domain,我们随机抽取6labeled instances for training,and use the rest of the instances to test.
Repeat for each configuration10次.
The comparison results of the average accuracy are shown in Fig.3所示.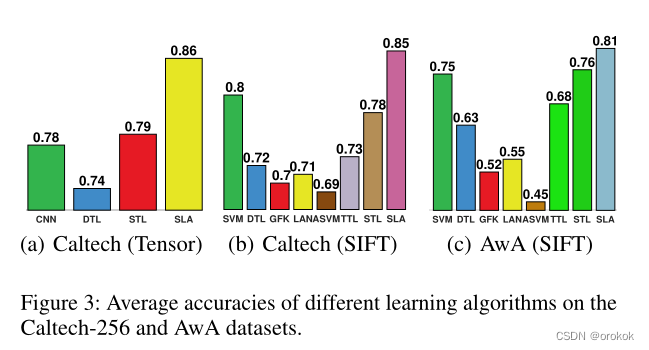
我们提出的SLAmethod achieves the best performance with all settings.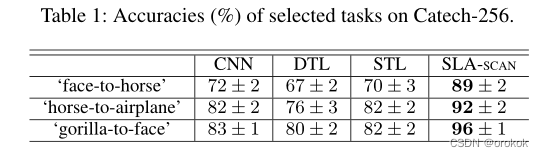
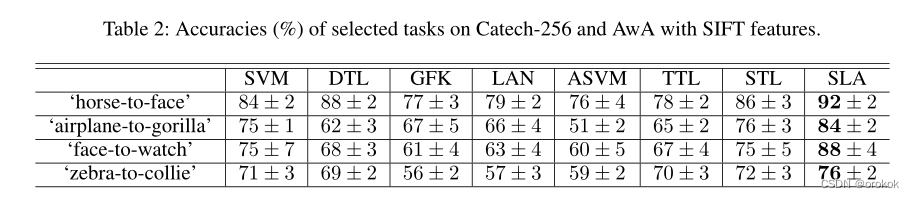
在表1和表2中,We also report the mean accuracy and standard deviation of different methods on some selected tasks.在这些任务中,我们可以看到SLA-SCAN在精度上比CNN提高了10%以上,有时甚至达到17%.对于SLA-SAN,其精度比SVM提高了约10%.
5.4详细结果
To understand how data in the intermediate domain helps connect the source and target domains,如图4所示,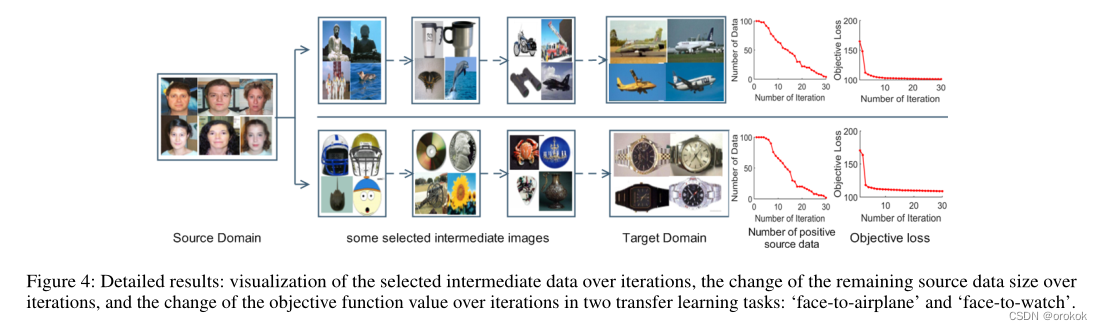
我们表明,As iterative learning proceeds,The number of positive samples in the source domain is reduced,问题(3)The objective function value is also reduced.
5.5Comparison of different learning sequences
如图4所示,SLAAlgorithms can learn a sequence of useful intermediate data,and add it to the learning process.In order to compare the different orders of the intermediate data added to the learning,We hand-designed three sorting strategies.
- 在第一种策略中,我们用Random表示,Randomly divide the data in the middle region into ten subsets.在每次迭代中,We add a subset to the learning process.
- 在第二种策略中,我们用Category表示,我们先用SLAAlgorithm to get an order,Then utilize the additional category information of the intermediate data,Add intermediate data to the learning process on a class-by-class basis.
因此,The order of categories is that they are inSLAThe order of the first occurrence in the order learned by the algorithm. - 第三种策略,用Reverse表示,Similar to the second strategy,It's just that the order of the added categories is reversed.在实验中,The removal method of source domain data andSLAThe original learning process of the algorithm is the same.
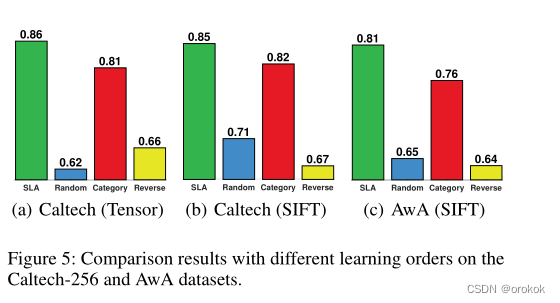
从图5所示的结果中,我们可以看到,The three manually designed strategies obtained far lower accuracy thanSLA.此外,在三种策略中,“Category”的性能最好,This is because the resulting order is close toSLA.
六、总结
本文研究了一种新的DDTL问题,The source domain and the target domain are far apart,但可以通过一些中间域连接.为了解决DDTL问题,我们提出了SLA算法,Stepwise selection of unlabeled data from intermediate domains to connect two distant domains.Experiments on two benchmark image datasets show that,SLACapable of reaching state-of-the-art performance in terms of accuracy.
as a future development direction,We will extend the proposed algorithm to deal with multiple source domain.
Reference
Distant Domain Transfer Learning
边栏推荐
- Binary tree [full solution] (C language)
- 汇编语言之源程序
- tcp中的三次握手与四次挥手
- 工具类总结
- 【七夕如何根据情侣倾听的音乐进行薅羊毛】背景音乐是否会影响情侣对酒的选择
- Method Overriding and Object Class
- Lattice PCIe 学习 1
- [How to smash wool according to the music the couple listens to during the Qixi Festival] Does the background music affect the couple's choice of wine?
- 动态规划/背包问题总结/小结——01背包、完全背包
- Exploding the circle of friends, Alibaba produced billion-level concurrent design quick notes are too fragrant
猜你喜欢


![[GYCTF2020]EasyThinking](/img/40/973411c69d1e4766d22f6a4a7c7c01.png)


随机推荐
The difference between a process in user mode and kernel mode [exclusive analysis]
活动推荐 | 快手StreamLake品牌发布会,8月10日一起见证!
GCC:编译时库路径和运行时库路径
深度学习训练前快速批量修改数据集中的图片名
Kubernetes 网络入门
Introduction to JVM class loading
习题:选择结构(一)
SAP ERP和ORACLE ERP的区别是哪些?
进程在用户态和内核态的区别[独家解析]
行业现状?互联网公司为什么宁愿花20k招人,也不愿涨薪留住老员工~
How DHCP works
ExcelPatternTool: Excel表格-数据库互导工具
MBps与Mbps区别
新唐NUC980使用记录:在用户应用中使用GPIO
Object.defineProperty实时监听数据变化并更新页面
Exploding the circle of friends, Alibaba produced billion-level concurrent design quick notes are too fragrant
C语言基础知识 -- 指针
PCIe Core Configuration
“配置”是把双刃剑,带你了解各种配置方法
配置类总结