当前位置:网站首页>What is the difference between self attention mechanism and fully connected graph convolution network (GCN)?
What is the difference between self attention mechanism and fully connected graph convolution network (GCN)?
2022-07-02 16:20:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery 
This article arranges self-knowledge questions and answers , For academic sharing only , The copyright belongs to the author . If there is any infringement , Please contact the background for deletion .
Point of view
author |Guohao Li
https://www.zhihu.com/question/366088445/answer/1023290162
Let's talk about our understanding .
The first conclusion is that most GCN and Self-attention All belong to Message Passing( The messaging ).GCN Medium Message Propagate from the neighbor node of the node ,Self-attention Of Message from Query Of Key-Value Spread .

Message Passing[4]
Let's see what is Message Passing. We know that in the implementation and design GCN It is often used Message Passing Framework [3], The idea is to transfer the characteristic information of the domain of each node to the node . Here is an example of a node i In the k layer GCN Convolution process :
1) Node i Every neighbor of j After functional transformation with the characteristics of this node, a Message( Corresponding public function \phi Operation inside );
2) Through a Permutation Invariant( Permutation invariance ) The function puts all of the nodes in the field Message Come together ( The corresponding function \square);
3) Then go through the function \gamma Make a functional change to the aggregated domain information and node characteristics , Get the node at k Features after convolution of layer graph X_i.
that Self-attention Whether it also falls in Message Passing Within the framework of ? So let's go back Self-attention How is it generally calculated [2], Here's an example Query i Passing through attention Calculation process :
1】Query i Characteristics of x_i Will be with everyone Key j Calculate a similarity based on the characteristics of e_ij;

2】 obtain Query i With all the Key After the similarity of SoftMax obtain Attention coefficient( Attention coefficient )\alpha_ij;
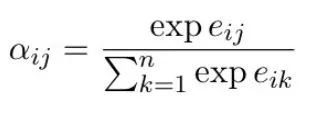
3】 adopt Attention coefficient weighting Value j To calculate the Query i The final output z_j.
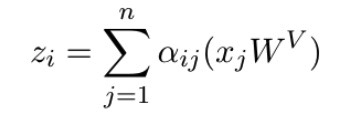
Okay , Then let's take a look at the corresponding relationship between them . The first conclusion is Self-attention In calculation 1】2】3】 It's corresponding to Message Passing Inside 1)2) Of .
If you use Message Passing To achieve Self-attention, Then we can do this one by one :
-1 Every Key-Value j It can be seen as Query i Neighbors of ;
-2 The calculation of similarity and attention coefficient and finally 3】 in Value j The operation multiplied by the attention coefficient can correspond to Message Passing The first step in the composition Message The process of ;
-3 Last Self-attention The sum operation of corresponds to Message Passing In the second step Permutation Invariant function , That is to say, the process of aggregating domain information here is through Query Yes Key-Value Come together .
So in other words ,Attention The process is to put every Query And all Key Connect to get a Complete Bipartite Graph( On the left is Query Dexter Key-Value), And then on this picture for all Query Nodes do Message Passing. Of course Query and Key-Value Same Self-attention In general Complete Graph Do on Message Passing 了 .
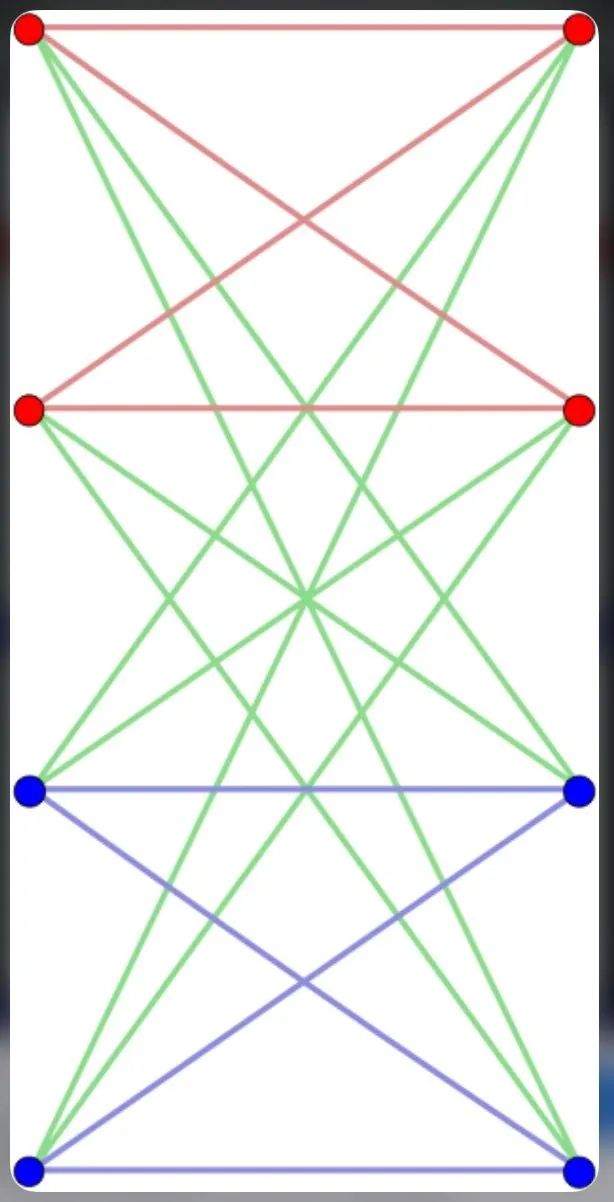
Complete Bipartite Graph
Seeing this, you may wonder why Self attention There's no more Message Passing In the third step, aggregate the information and node information through \gamma The process of function transformation . Yes , If you don't have this step, you may be in the learning process Query The original features of will be lost , In fact, this step is Attention is all your need[1] There are still some in it , Don't believe it. :
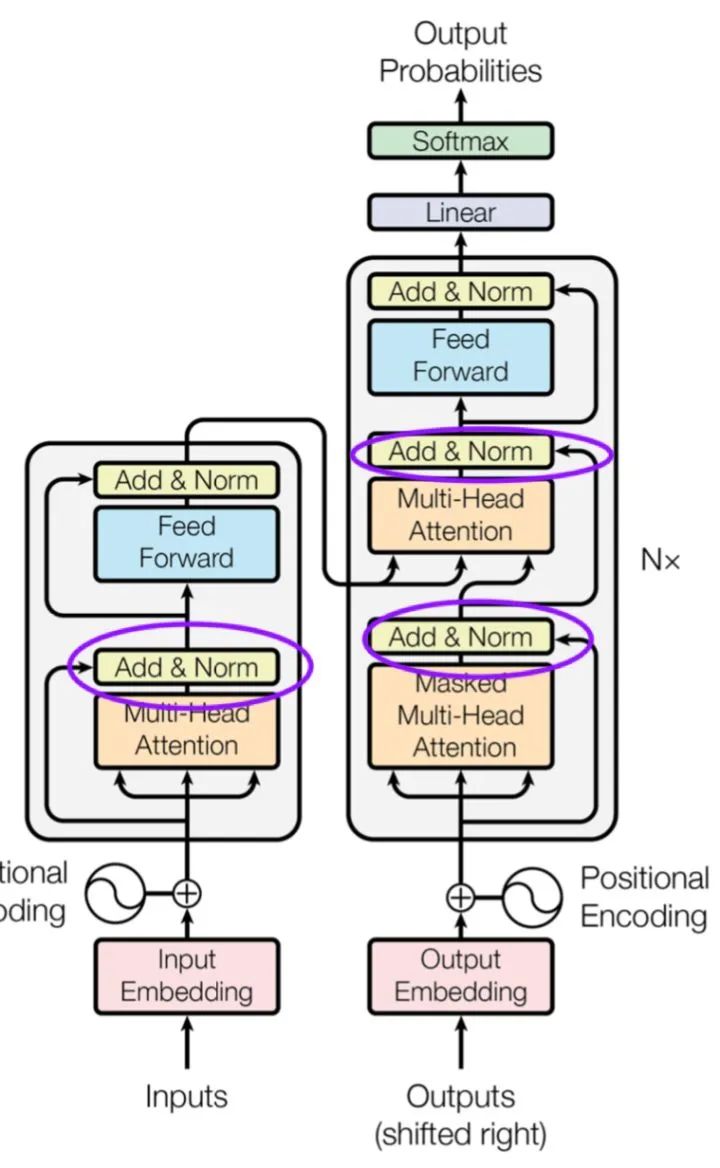
In every pass Self-Attention After that, there are basically Skip connection+MLP Of , This corresponds to Message Passing Inside \gamma Function, isn't it ?
So to put it bluntly GCN and Self-attention All fall on Message Passing( The messaging ) In frame .GCN Medium Message Propagate from the neighbor node of the node ,Self-attention Of Message from Query Of Key-Value Spread . If you weigh all Message Passing All functions are GCN Words , that Self-attention That is to say GCN effect Query and Key-Value What constitutes a Complete Garph A special case of . Just like Naiyan @Naiyan Wang The answer is the same .
so to speak NLP in GCN There should be great prospects , After all Self-attention It can be seen that it is GCN A kind of , Then there must be a ratio Self-attention More expressive and applicable GCN.
Thanks for the comments @ Ye Zihao's supplement ,DGL The team wrote a very detailed use Message Passing Realization Transformer A tutorial for . Students interested in specific implementation can read :DGL Transformer Tutorial.
Reference:
1. Attention is All You Need
2. Self-Attention with Relative Position Representations
3. Pytorch Geometric
4. DeepGCNs for Representation Learning on Graphs
Viewpoint two
author |Houye
https://www.zhihu.com/question/366088445/answer/1022692208
Let's talk about our understanding .
GAT Medium Attention Namely self-attention, The author has said in his paper

Let's talk about personal understanding :
GNN, Include GCN, It is a neural network model that aggregates neighbor information to update node representation . The picture below is taken from GraphSAGE, It's a good description of the polymerization process . Here we only focus on the figure 2: Red dots u It is our final point of concern ,3 A blue dot {v1,v2,v3} Is the first-order neighbor of the red dot . Each update is represented by a red node ,GNN Will collect 3 Blue dot information and aggregate it , Then the representation of the red node is updated by neural network . Here the neural network can be a mean-pooling, It is also an average of neighbors , Now v1,v2,v3 The weight of all is 1/3.
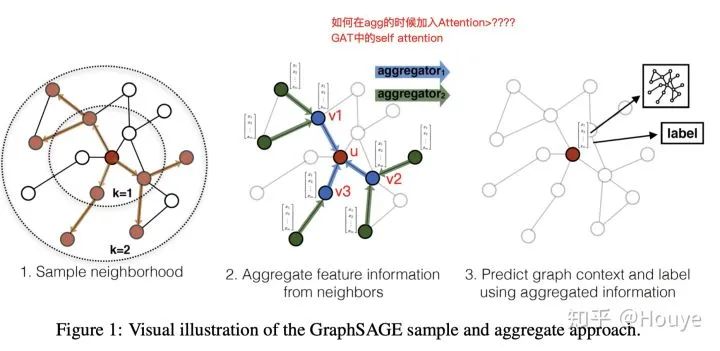
Then there's a problem here ,3 All the blue dots are neighbors , Intuitive thinking , Different neighbors have different importance for red dots . that , stay GNN When aggregating neighbors, can we consider the importance of neighbors to weight aggregation ( such as ,0.8v1+0.19v2+0.01v3)? Manual weighting is definitely not practical . Although weighted feel better , But it can also be done without weighting GNN Of , On some datasets , The effect of unweighted is even better .
I feel in the field of deep learning ,“ weighting =attention”. We can design one here attention Mechanism to realize the weighting of neighbors . The weight here can be understood as the weight of edges , It is for a pair of nodes ( such as u and v1).
Then why is it self-attention, because GNN When we gather, we will treat ourselves as neighbors . in other words , Above picture u The neighbor set of is actually {u,v1,v2,v3}. It's natural , Neighbor information can only be regarded as supplementary information , The information of the node itself is the most important .
Now the problem turns into : Given {u,v1,v2,v3} As input , How to integrate u Better express ? This is very much like NLP Inside self-attention 了 , See the picture below ( Quoted from Chuantuo scholar :Attention Detailed explanation of mechanism ( Two )——Self-Attention And Transformer)

So to conclude :GCN and self-attention even to the extent that attention There is no necessary connection . Weighting neighbors to learn better node representation is an option .
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- mysql 计算经纬度范围内的数据
- Rock PI Development Notes (II): start with rock PI 4B plus (based on Ruixing micro rk3399) board and make system operation
- 总结|机器视觉中三大坐标系及其相互关系
- 微信v3native支付设置的结束时间处理办法
- PyC file decompile
- End time processing method of wechat v3native payment settings
- 仙人掌之歌——投石问路(3)
- Compress words (kmp/ string hash, double hash)
- Flink real-time data warehouse (IX): incremental synchronization of data in MySQL
- day4
猜你喜欢

Aujourd'hui dans l'histoire: Alipay lance le paiement par code à barres; La naissance du père du système de partage du temps; La première publicité télévisée au monde...

Dimension table and fact table in data warehouse

Bone conduction non ear Bluetooth headset brand, bone conduction Bluetooth headset brand recommendation

Huawei ECS installs mysqlb for mysqld service failed because the control process exited with error code. See “sys
Pandora IOT development board learning (RT thread) - Experiment 2 RGB LED experiment (learning notes)

Idea public method extraction shortcut key

Rock PI Development Notes (II): start with rock PI 4B plus (based on Ruixing micro rk3399) board and make system operation

HMS core machine learning service helps zaful users to shop conveniently
![[Yu Yue education] reference materials of sensing and intelligent control technology of Nanjing University of Technology](/img/5c/5f835c286548907f3f09ecb66b2068.jpg)
[Yu Yue education] reference materials of sensing and intelligent control technology of Nanjing University of Technology

Recalling the college entrance examination and becoming a programmer, do you regret it?
随机推荐
Boot 连接 Impala数据库
虚假的暑假
day4
Maui learning road (III) -- in depth discussion of winui3
Seal Library - installation and introduction
外企高管、连续创业者、瑜伽和滑雪高手,持续迭代重构的程序人生
构建多架构镜像的最佳实践
What is Amazon keyword index? The consequences of not indexing are serious
In memory of becoming the first dayu200 tripartite demo contributor
Introduction to database system Chapter 1 short answer questions - how was the final exam?
Leetcode --- longest public prefix
Crawl the information of national colleges and universities in 1 minute and make it into a large screen for visualization!
After the win10 system is upgraded for a period of time, the memory occupation is too high
Kubernetes family container housekeeper pod online Q & A?
一文读懂AGV的关键技术——激光SLAM与视觉SLAM的区别
End time processing method of wechat v3native payment settings
Idea jar package conflict troubleshooting
纪念成为首个 DAYU200 三方 demo 贡献者
Figure database | Nepal graph v3.1.0 performance report
The median salary of TSMC's global employees is about 460000, and the CEO is about 8.99 million; Apple raised the price of iPhone in Japan; VIM 9.0 releases | geek headlines