当前位置:网站首页>Multimodal deep multi modal sets
Multimodal deep multi modal sets
2022-07-25 23:16:00 【Programmers who only know git clone】
Preface
The paper :arxiv
Nowadays, many visual tasks will integrate and utilize the features of multiple modes , To train features with high robustness and strong representation ability , Previous methods mainly used features Concat as well as MLP Layer to mine and train the features of fusion representation . In this way, when more modes are added and used ,Concat The characteristic latitude of will be larger and larger .
contribution
- This paper provides a flexible structure to deal with the number of features and the number of modes for multi-modal fusion .
- This structure can facilitate us to analyze which mode contributes the most to the model when reasoning /
Method
Multimodal tasks can be understood as using more than one modal data in training tasks , The goal is to train to get a that can represent multiple modal information embedding, This feature will be used to complete downstream tasks, such as recall sequencing .
traditional method , Put the characteristics of each mode Concat get up , Expressed by the following formula :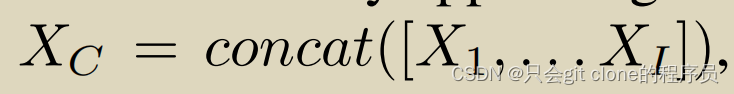
X1-I Corresponding I Characteristics of modes , In this case XC The dimension of I The dimensions of features and , And then MLP Layer can be used to complete the prediction of downstream tasks . This method has the following disadvantages :
- If a certain mode is missing , Space occupying features are needed to temporarily replace , For example, make up 0, But all 0 For some tasks, it may be a very unnatural feature that is artificially imposed on the training task .
- Then for sequence features , For example, the click behavior of user history , The frequency of occurrence is uncertain. If such a feature is used concat To deal with it, you need to Padding To the maximum length, this will cause a great waste of computation and add a lot of invalid features .
- in addition , Some modal features have lower dimensions , Like gender characteristics can be used 2 A vector of dimensions , For image features resnet50 Extraction is generally 2048 The characteristics of dimensions , In this way, there will be the problem of unbalanced latitude of modal characteristics , This may cause those high latitude features to mainly affect the performance of the model . Of course, this problem can be solved by analyzing the modal characteristics first encoder Handle to a certain dimension . The formula in the figure below indicates that I pass the civil examinations i Modes from Mi Latitude is encoded as D latitude .

- Finally, when there are many modes and the sequence length of a certain mode is variable , use concat as well as concat Technology will be very inflexible to deal with them .
Deepset, The paper is right deepset The fusion of sequence features is mainly studied in sum pool、max pool as well as min pool Other methods , I feel a little behind …attention is all you need… Now the mainstream method is still based on transformer To achieve , There is nothing to say about the experiment of the paper , Mainly introduce my own understanding .
The comparison of several structures is tested in business , And listened to some colleagues' technical sharing , I understand. deepset It should first fuse the sequence features and then fuse the overall modal features . The advantage of this is that it can save parameters and computation . Take an example of my experiment deepset structure :
f1-f5 Corresponding to five sequence features , after transformer The output shape of is unchanged , such as (bs, n, d) Input to transformer Output or (bs, n, d) At this time, the features have learned the relationship between sequences , Yes n Make a dimension of mean pool The characteristic of the corresponding mode can be obtained (bs, 1, d), Then the characteristics of each mode concat Get up and finally send to a fusion of all modes transformer After the module, we can get the global representation embdding 了 .
Compare another structure :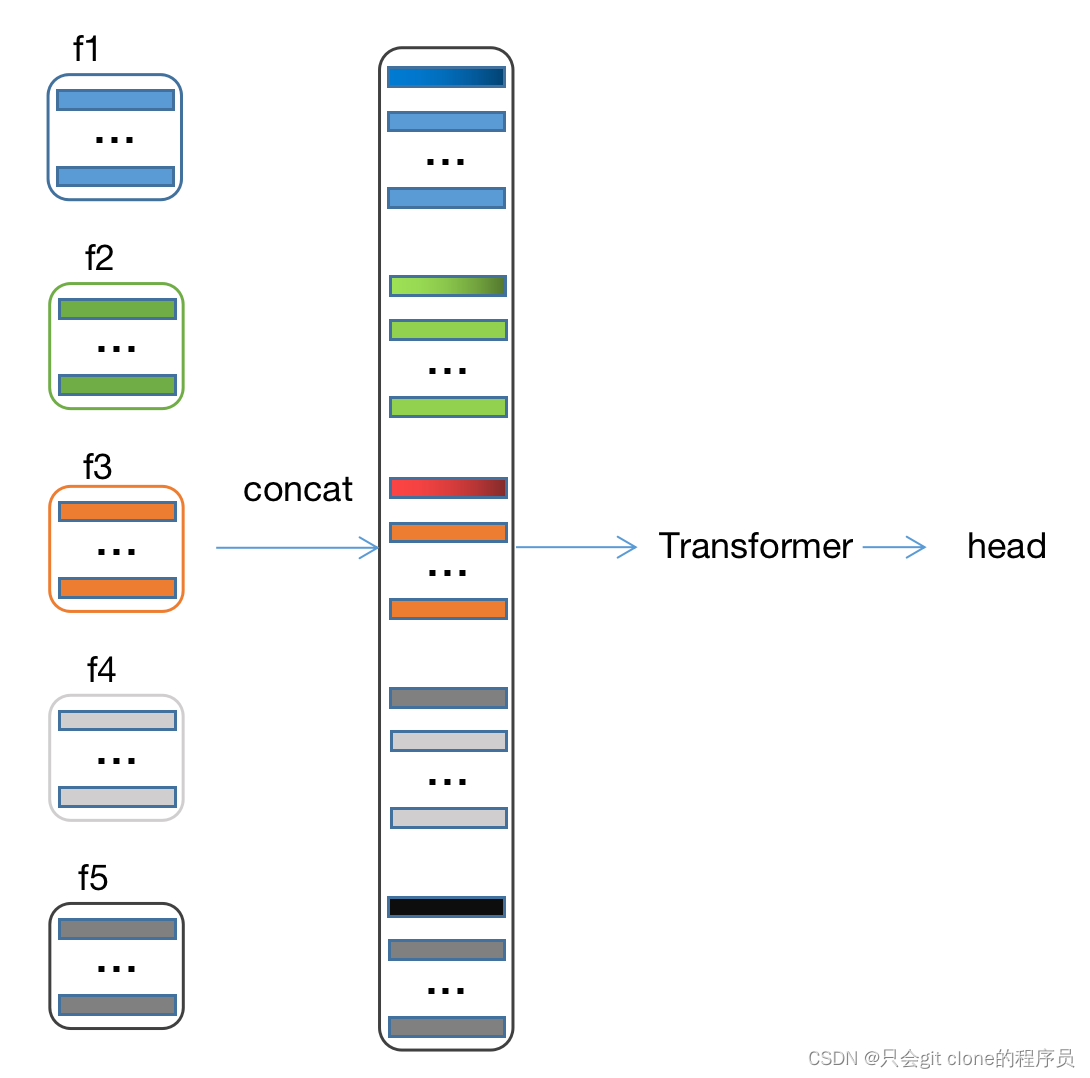
The conclusion of this method experiment is that the calculation of parameters is large and the effect of the model is slightly worse than deepset Formal model . Then you can see me in the picture concat Then I drew a gradient feature , Because if all the features are summarized first in this way, the information of which mode he inputs will be lost , Some methods add a modal code and a sequence code to each feature , Sequence coding is for some sequence dependent features, such as video image features . There are also some methods that will integrate the fusion features of this mode concat go in , Fusion features can be used maxpool perhaps sumpool To get , image ECCV MMT. The implementation of this structure is slightly cumbersome , It needs to add sequence position coding and modal coding , Then the parameter quantity is still large .
Other code
notice facebook Also open source some modal fusion code , be based on deepset Structural transformer Code :
https://github.com/facebookresearch/multimodal/blob/main/torchmultimodal/modules/fusions/deepset_fusion.py
边栏推荐
- How does Navicat modify the language (Chinese or English)?
- Hj9 extract non duplicate integers
- Firewall command simple operation
- Panzer_ Jack's personal blog founding day
- General paging function
- ETL tool (data synchronization) II
- Solve the problem phpstudy failed to import the database
- How to obtain the cash flow data of advertising services to help analyze the advertising effect?
- Check code generation
- Hj7 take approximate value
猜你喜欢

firewall 命令简单操作

Take root downward, grow upward, and explore the "root" power of Huawei cloud AI

Experience of machine learning with Google Lab

动态内存管理
Analysis of direction finding error of multi baseline interferometer system

OASYS system of code audit

Notification(状态栏通知)详解
Stack and stack class

Deploy flash based websites using Google cloud

IPFs of Internet Protocol
随机推荐
【接口性能优化】索引失效的原因以及如何进行SQL优化
WordPress controls the minimum and maximum number of words of article comments
Discuz atmosphere game style template / imitation lol hero League game DZ game template GBK
[PTA] 7-19 check face value (15 points)
Rental experience post
Deploy flash based websites using Google cloud
Longitude and latitude and its transformation with coordinate system
r语言绘图参数(R语言plot画图)
栈与Stack类
Enabling partners, how can Amazon cloud technology "get on the horse and get a ride"?
How to obtain the cash flow data of advertising services to help analyze the advertising effect?
新手哪个券商开户最好 开户最安全
Data broker understanding
CTS测试方法「建议收藏」
Several commonly used traversal methods
校验码生成
Hj7 take approximate value
向下扎根,向上生长,探寻华为云AI的“根”力量
Family relationship calculator wechat applet source code
The difference between MySQL clustered index and non clustered index