当前位置:网站首页>After watching the video, AI model learned to play my world: cutting trees, making boxes, making stone picks, everything is good
After watching the video, AI model learned to play my world: cutting trees, making boxes, making stone picks, everything is good
2022-07-03 11:37:00 【3D vision workshop】
Author Chen Ping 、 Boat
Source: heart of machine
《 My world 》 in , Players are not necessarily human , Now? AI Can also play .
《 My world 》 It is the most famous open world game in the world . Children only need to watch ten minutes of teaching video , You can learn to find rare diamonds in the game , But this is AI Previously unreachable heights .
today OpenAI Our research team announced that they have developed a kind of game that can play 《 My world 》 The agent of , It uses 《 My world 》 A large number of unlabeled video data sets are used to train neural networks , Use only a small amount of tag data .
After fine tuning ,OpenAI The training model can also learn to make mining tools , Skilled human players in 20 You can finish this task in minutes (24000 operations ).OpenAI The model uses buttons and mouse movements to control the human-computer interface , This makes the model very general , This is a step towards the use of agents in general-purpose computers .

Address of thesis :https://cdn.openai.com/vpt/Paper.pdf
Let's see the effect first , The model built a crude wooden shelter :

Making stone picks

Search the village
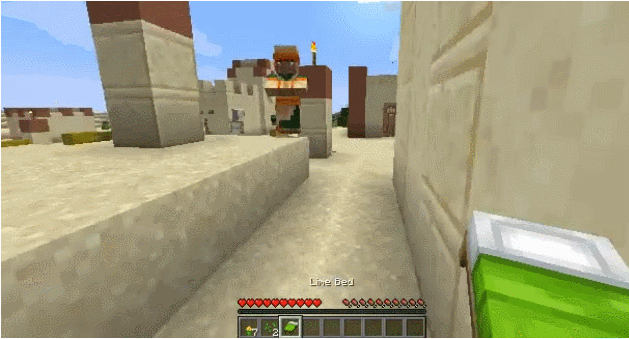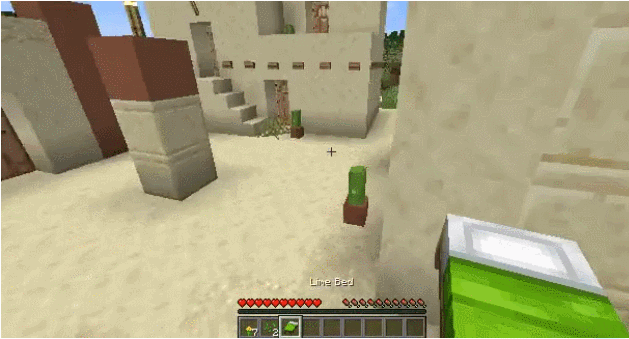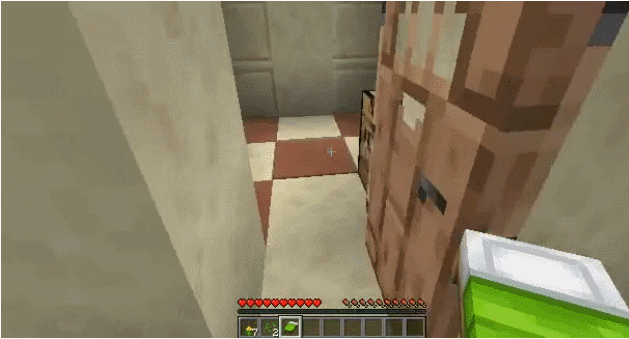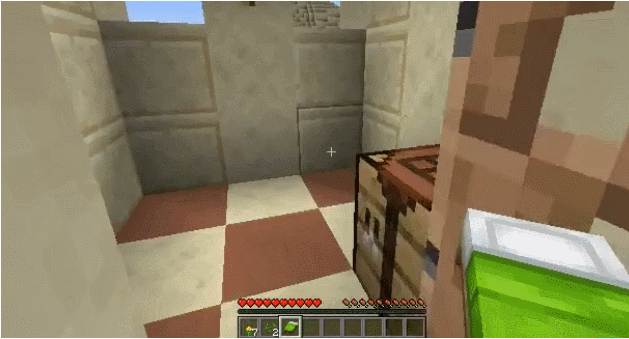
VPT Method
The Internet contains a large number of public videos for us to learn , For example, a gamer demonstrates how to play a game ,《 My world 》 Players build an intricate house . However, these videos only provide a record of what happened , Rather than the exact implementation , That is, the exact sequence of mouse movements and buttons is not specified .
Compared with OpenAI A large language model of , To build large-scale basic models in more general fields such as video games (foundation model), Lack of action labels poses new challenges .
To take advantage of the large amount of unlabeled video data available on the Internet , This study proposes a novel but simple semi supervised imitation learning method : Video pre training (VPT).
The study first collected a small data set from game vendors , It not only records the video of playing games , It also records the actions taken by players , That is, the movement of keys and mouse . Use the data , This study trains an inverse dynamic model (IDM), To predict the action taken at each step in the video . It is important to ,IDM You can use past and future information to guess every move . Compared with the behavior cloning task that only gives the past video frame prediction action , This task is much easier , Much less data is needed . The study then used trained IDM To tag larger online video datasets , And learn to act through behavioral cloning .
The following figure for VPT Method Overview :

VPT Zero sample results
The study chose 《 My world 》 The proposed method is verified in this game , Because it (1) It is one of the most popular video games in the world , Have a lot of freely available video data , also (2) It's open , It can provide a variety of behaviors , Similar to real-world applications ( Such as computer use ). Compared with previous work in 《 My world 》 The simplified action space is different in ,OpenAI The use of the new model is more generally applicable 、 More difficult native human-computer interface : Mouse and keyboard use 20Hz Frame rate .
The behavioral cloning model of the study (VPT Basic model ) Use 70000 Hours of IDM Tag online videos for training , stay 《 My world 》 It has completed the task that reinforcement learning is almost impossible to achieve . The new model learned to cut trees and collect logs , Make logs into planks , Then make the wooden board into a box ; This behavior sequence is for 《 My world 》 Advanced players are about 50 Within seconds 1000 A series of game moves .
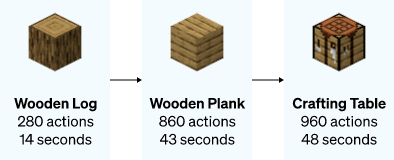
《 My world 》 The number of actions and time required for each step in the process of making boxes .

The process of making boxes with zero sample models .
Besides , The model can also perform other complex skills that humans often perform in games , For example, swimming 、 Hunting animals 、 Eat food and some 《 My world 》 Special skills .

swimming .

hunting .

Eat food .
Fine tune with behavior cloning
The underlying model is designed to have a wide range of behavioral characteristics , And complete various tasks . To integrate new knowledge or focus them on more specific tasks , The usual approach is based on smaller 、 More specific data sets fine tune the model .
that ,VPT How to fine tune the basic model to the downstream data set ?OpenAI Let human players in the latest version 《 My world 》 In play 10 minute , And build houses with basic materials .OpenAI Hopefully this will enhance the ability of the basic model to perform early game skills . It turns out that , The basic model has made great progress in reliably executing early game skills , And the fine-tuning model has also mastered new skills such as making stone tools .

The sequence of items needed to make a stone pick
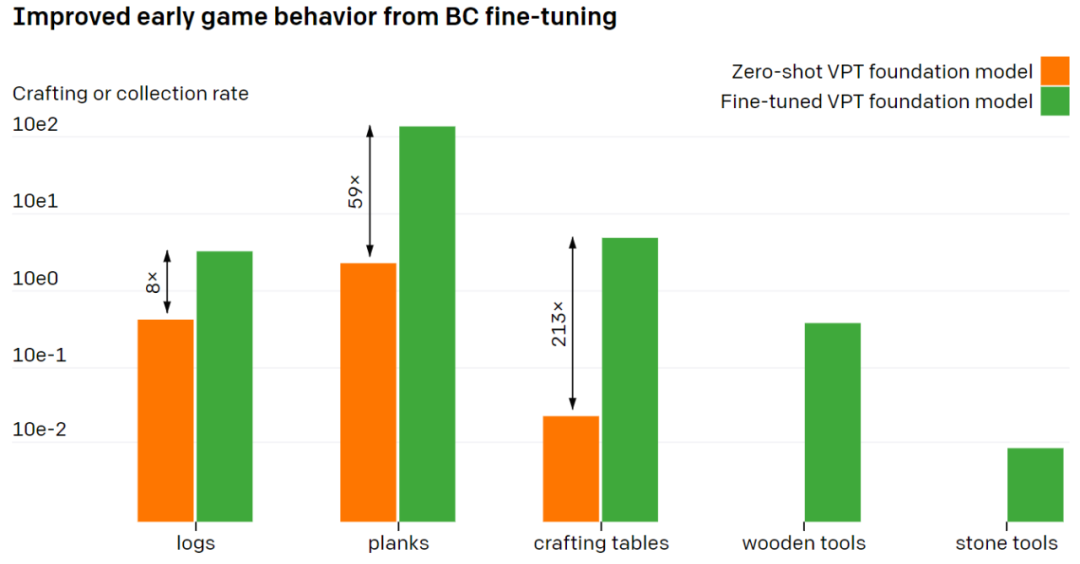
Data expansion
Perhaps the most important assumption in this study is , Use marked contractor Data training IDM( As VPT pipeline Part of ) Than directly from the same small contractor Dataset training BC The underlying model is much more effective . To test this hypothesis , Researchers continue to increase the amount of data to train the basic model , The scale of data volume ranges from 1 Hours increased to 70000 Hours . They divide the training into two parts , As shown by the dotted line in the figure below , The training data duration is in 2000 For the dividing line .
The influence of basic model training data on fine tuning : As you can see from the diagram , With the increase of basic model data , The ability to make models increases , Only under the largest data scale , We will see the emergence of stone tool making .
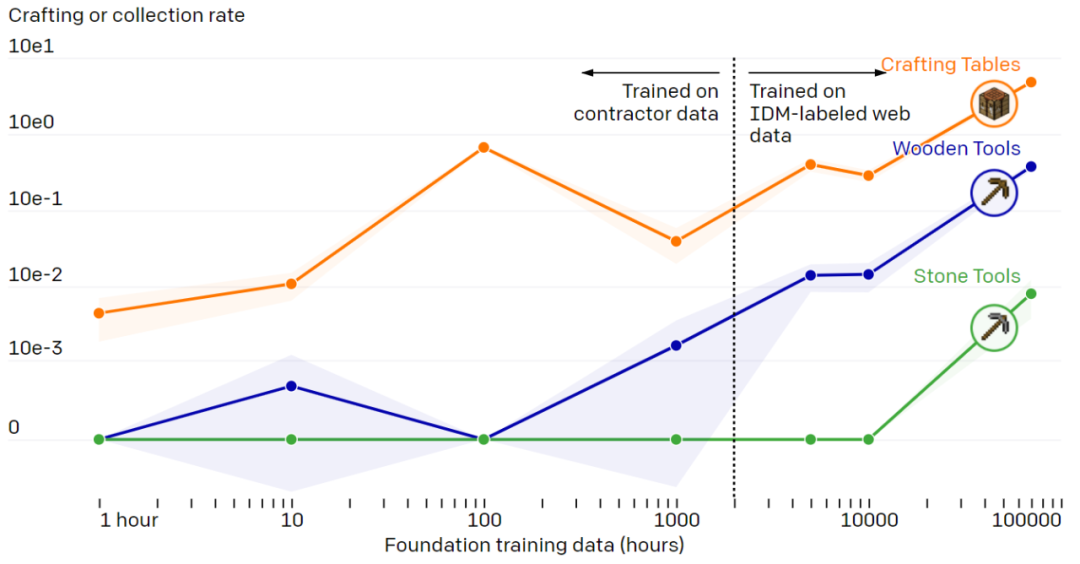
Fine tune through reinforcement learning
When the specified reward function is good enough , Reinforcement learning can be a powerful way to inspire higher , Even superhuman performance .VPT Models and RL Better collocation , Because mimicking human behavior may be more helpful than taking random actions . The study sets some model challenge tasks , Collect diamond pickaxe , This is 《 My world 》 Unprecedented ability in .
Making a diamond pickaxe requires a long series of complex subtasks . To make this task easy to handle , The research will reward each agent in the sequence .



RL fine-tuning VPT Model making diamond pickaxe
The study found that , From random initialization ( standard RL Method ) Trained RL The strategy received little reward . In sharp contrast to it is ,VPT Fine tuning of the model can not only ( It's in 10 Minutes of 《 My world 》 There is 2.5% Will do so ), And its success rate in collecting all items to obtain diamond picks has even reached the level of human beings . This is the first time that human beings have demonstrated that computer agents can 《 My world 》 To make diamond tools , And the average human needs 20 More minutes (24000 operations ).
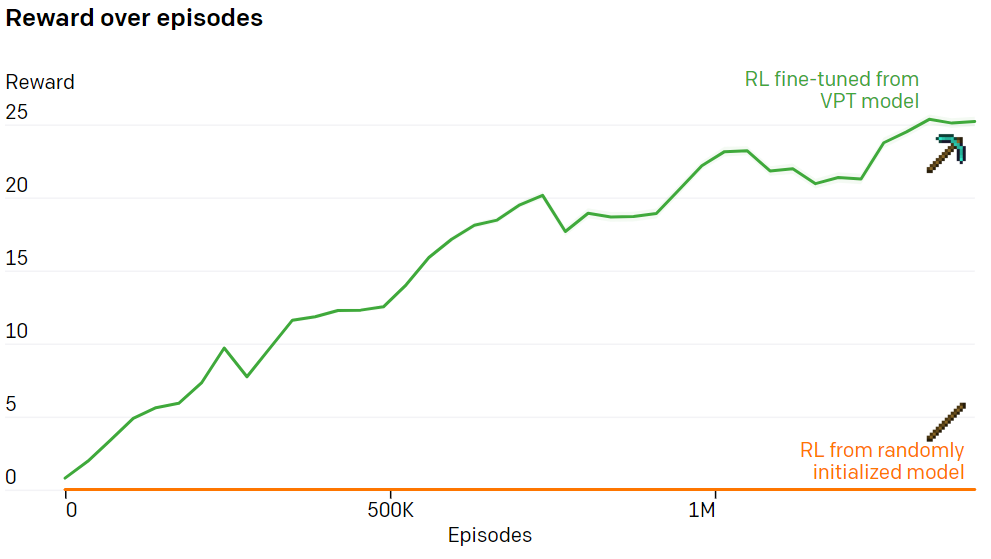
VPT It paves the way for agents to learn by watching a large number of videos on the Internet . Compared with the generated video modeling or comparison methods that only produce the representation a priori ,VPT It provides the possibility of directly learning large-scale behavior a priori in more fields , Not just language . Although the study is only in 《 My world 》 Experiment in , But the game is open , And native human-computer interface ( Mouse and keyboard ) Very versatile , So this research will also bring benefits to other fields , For example, computer use .
Besides , The study also opened up data 、《 My world 》 The environment required 、 The model code 、 Model weight , They hope that these open sources will help in the future VPT The study of .
Link to the original text :
https://openai.com/blog/vpt/
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- [OBS] configFile in ini format of OBS
- Solve undefined reference to`__ aeabi_ Uidivmod 'and undefined reference to`__ aeabi_ Uidiv 'error
- 2022年中南大学夏令营面试经验
- Reading notes: heart like Bodhi, Cao Dewang
- Some common terms
- P3250 [HNOI2016] 网络 + [NECPC2022] F.Tree Path 树剖+线段树维护堆
- 多维度监控:智能监控的数据基础
- R language uses data The table package performs data aggregation statistics, calculates window statistics, calculates the median of sliding groups, and merges the generated statistical data into the o
- Balance between picture performance of unity mobile game performance optimization spectrum and GPU pressure
- 导师对帮助研究生顺利完成学业提出了20条劝告:第一,不要有度假休息的打算.....
猜你喜欢

Qt+VTK+OCCT读取IGES/STEP模型

Kibana~Kibana的安装和配置
软考中级软件设计师该怎么备考

Analysis of EPS electric steering system
2022 东北四省赛 VP记录/补题

How to get started embedded future development direction of embedded

基于turtlebot3实现SLAM建图及自主导航仿真

Unique in the industry! Fada electronic contract is on the list of 36 krypton hard core technology enterprises

基于I2C协议的驱动开发
Use typora to draw flow chart, sequence diagram, sequence diagram, Gantt chart, etc. for detailed explanation
随机推荐
动态规划(区间dp)
Kubernetes 三打探针及探针方式
Cadence background color setting
Balance between picture performance of unity mobile game performance optimization spectrum and GPU pressure
VPP three-layer network interconnection configuration
银泰百货点燃城市“夜经济”
如何将数字字符串转换为整数
GCC compilation process and dynamic link library and static link library
STL教程10-容器共性和使用场景
Software testing weekly (issue 78): the more confident you are about the future, the more patient you are about the present.
[vtk] source code interpretation of vtkpolydatatoimagestencil
R language uses grid of gridextra package The array function combines multiple visual images of the lattice package horizontally, and the ncol parameter defines the number of columns of the combined g
Arctangent entropy: the latest SCI paper in July 2022
C language AES encryption and decryption
JGG专刊征稿:时空组学
Driver development based on I2C protocol
高精度室内定位技术,在智慧工厂安全管理的应用
[OBS] configFile in ini format of OBS
After setting up ADG, instance 2 cannot start ora-29760: instance_ number parameter not specified
C语言 AES加解密