当前位置:网站首页>Analyze datahub, a new generation metadata platform of 4.7K star
Analyze datahub, a new generation metadata platform of 4.7K star
2022-07-01 03:08:00 【Big data sheep said】
With the advancement of digital transformation , Data governance has been put on the agenda by more and more companies . As a new generation of metadata management platform ,Datahub It has developed rapidly in the past year , It is likely to replace the old metadata management tools Atlas Trend . At home Datahub Very little information , Most companies want to use Datahub As its own metadata management platform , But there are too few references .
Through this document , You can get started quickly Datahub, Successful construction Datahub And get the metadata information of the database . It's from 0 To 1 The introduction document of , more Datahub Advanced features of , You can follow the subsequent article updates .
The text is : 10289 word 32 chart
Estimated reading time : 26 minute
Documents are divided into 6 Parts of , The hierarchy is shown in the figure below .

One 、 Data governance and metadata management
background
Why data governance ? There are many businesses , There's a lot of data , Business data iterates . Mobility , Incomplete documentation , The logic is not clear , It's hard to understand data intuitively , It's hard to maintain later .
In the research and development of big data , The raw data has a lot of databases , Data sheet .
And after data aggregation , There will be many dimension tables .
In recent years, the magnitude of data has increased madly , This brings a series of problems . As the data support for the AI team , The question we hear most is “ The correct data set ”, They need the right data for their analysis . We're starting to realize that , Although we built a highly scalable data store , Real time computing and so on , But our team is still wasting time looking for the right data set for analysis .
That is, we lack the management of data assets . in fact , Many companies have provided open source solutions to solve the above problems , This is the data discovery and metadata management tool .
Metadata management
In short , Metadata management is to organize data assets effectively . It uses metadata to help manage their data . It can also help data professionals collect 、 organization 、 Access and enrich metadata , To support data governance .
Thirty years ago , Data assets may be Oracle A table in the database . However , In modern enterprises , We have a dazzling array of different types of data assets . It could be a relational database or NoSQL Table in storage 、 Real time streaming data 、 AI Functions in the system 、 Indicators in the indicator platform , Dashboard in data visualization tool .
Modern metadata management should include all these types of data assets , And enable data workers to use these assets more efficiently to complete their work .
therefore , The functions of metadata management are as follows :
** Search and discovery :** Data sheet 、 Field 、 label 、 The use of information
** Access control :** Access control group 、 user 、 Strategy
** Data consanguinity :** Pipeline execution 、 Inquire about
** Compliance :** Data privacy / Classification of compliance note types
** Data management :** Data source configuration 、 Ingestion configuration 、 Keep configuration 、 Data purge policy
**AI Interpretability 、 Reproducibility :** Feature definition 、 Model definition 、 Training run execution 、 Problem statement
** Data manipulation :** Pipeline execution 、 Processed data partition 、 Data statistics
** Data quality :** Data quality rule definition 、 Rule execution results 、 Data statistics
Architecture and open source solutions
The following describes the architecture and implementation of metadata management , Different architectures correspond to different open source implementations .
The following figure describes the first generation metadata architecture . It is usually a classic monomer front end ( It could be a Flask Applications ), Connect to primary storage for queries ( Usually MySQL/Postgres), A search index used to provide search queries ( Usually Elasticsearch), And for the second 1.5 generation , Maybe once you reach the goal of relational database “ recursive query ” Limit , The processing lineage is used ( Usually Neo4j) Graph index of graph query .

Soon , The second generation architecture has emerged . The single application has been split into services located in front of the metadata storage database . The service provides a API, Allow metadata to be written to the system using the push mechanism .

The third generation architecture is an event based metadata management architecture , Customers can interact with the metadata database in different ways according to their needs .
Low latency lookup of metadata 、 The ability to perform full-text and ranking search on metadata attributes 、 Graphical query of metadata relationships and full scanning and analysis capabilities .

Datahub This is the architecture used .
The following figure is a simple and intuitive representation of today's metadata pattern :
( Including some non open source solutions )

Other schemes can be used as the main direction of research , But not the focus of this article .
Two 、Datahub brief introduction
First , Alibaba cloud also has a product called DataHub Products , It's a streaming platform , Described in this article DataHub It's not about it .
Data governance is a hot topic recently talked about by big guys . Regardless of the national level , Or is the enterprise level paying more and more attention to this problem . Data governance should address data quality , Data management , Data assets , Data security and so on . The key to data governance is Metadata management , We need to know the context of the data , Only in this way can the data be comprehensively managed , monitor , Insight .
DataHub By LinkedIn Open source data team to provide a metadata search and discovery tool .
mention LinkedIn, I have to think of the famous Kafka,Kafka Namely LinkedIn Open source .LinkedIn Open source Kafka It directly affects the development of the whole real-time computing field , and LinkedIn Our data team has been exploring the issue of data governance , Constantly strive to expand its infrastructure , To meet the growing needs of the big data ecosystem . As the amount and richness of data increase , Data scientists and engineers need to discover available data assets , It is becoming more and more challenging to understand where they come from and take appropriate action based on their insights . To help growth while continuing to expand productivity and data innovation , Created a common metadata search and discovery tool DataHub.
There are several common metadata management systems in the market :
a) linkedin datahub: https://github.com/linkedin/datahub
b) apache atlas: https://github.com/apache/atlas
c) lyft amundsen https://github.com/lyft/amundsen
atlas We also introduced , Yes hive Very good support , But it is very difficult to deploy .amundsen It is also an emerging framework , Not yet release edition , It may develop in the future and needs to be observed slowly .
Sum up ,datahub It is a new star at present , Just now datahub There is little information about , In the future, we will continue to pay attention to and update datahub More information about .
at present datahub Of github The number of stars has reached 4.3k.

Datahub Official website
Datahub The official website describes it as Data ecosystems are diverse — too diverse. DataHub’s extensible metadata platform enables data discovery, data observability and federated governance that helps you tame this complexity.
The data ecology is diverse , and DataHub It provides an extensible metadata management platform , It can meet data discovery , Data can be observed and managed . This also greatly solves the problem of data complexity .

Datahub It provides rich data source support and blood relationship display .

When obtaining the data source , Just write a simple yml File can complete the metadata acquisition .

In terms of data source support ,Datahub Support druid,hive,kafka,mysql,oracle,postgres,redash,metabase,superset Equal data source , And support the adoption of airflow Blood relationship acquisition of data . It can be said that it has realized from Data source to BI Full link of the tool The data of blood connection .

3、 ... and 、Datahub Interface
adopt Datahub Let's have a brief look at Datahub Functions that can be satisfied .
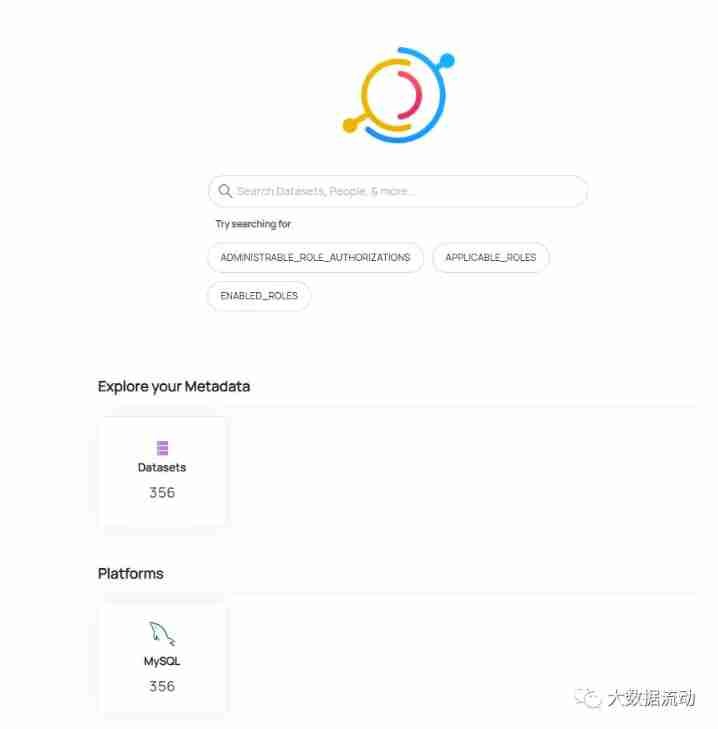
3.1 home page
First , Log in to Datahub After that, I entered Datahub home page , The home page provides Datahub The menu bar of , Search box and metadata information list . This is to allow you to quickly manage metadata .
Metadata information is based on data sets , instrument panel , Charts and other types are classified .

Further down is the platform information , This includes Hive,Kafka,Airflow And so on .

Here are some search statistics . Used to count the latest and most popular search results .
Include some label and glossary information .

3.2 Analysis page
The analysis page is the statistics of metadata information , Also for use datahub Statistics of user information .
It can be understood as a display page , This is very necessary to understand the overall situation .

Other functions are basically the control of users and permissions .

Four 、 The overall architecture
To learn well Datahub, You have to understand Datahub The overall structure of .
adopt Datahub The architecture diagram of can be clearly understood Datahub The structure of .

DataHub The architecture of has three main parts .
The front end is Datahub frontend As a front-end page display .
The rich front-end display makes Datahub It has the ability to support most functions . Its front end is based on React Framework development , For companies with secondary R & D plans , Pay attention to the matching of this technology stack .
Back end Datahub serving To provide back-end storage services .
Datahub The back-end development language of is Python, Storage is based on ES perhaps Neo4J.
and Datahub ingestion Is used to extract metadata information .
Datahub Provides the basis for API Active metadata pull , And based on Kafka The real-time metadata acquisition method . This is very flexible for metadata acquisition .
These three parts are also our main concerns in the deployment process , Let's deploy from scratch Datahub, And get metadata information of a database .
5、 ... and 、 Quick install deployment
Deploy datahub There are certain requirements for the system . This article is based on CentOS7 Installation .
Install it first docker,jq,docker-compose. At the same time, ensure the python Version is Python 3.6+.
5.1、 install docker,docker-compose,jq
Docker Is an open source application container engine , Allows developers to package their applications and dependencies into a portable container , Then post to any popular Linux or Windows On the machine with the operating system , You can also implement virtualization , Containers are completely sandboxed using the sandbox mechanism , There will be no interface between them .
Can pass yum Fast installation docker
yum -y install docker

Upon completion docker -v To view the version .
# docker -v
Docker version 1.13.1, build 7d71120/1.13.1
The following commands can be used to start and stop docker
systemctl start docker // start-up docker
systemctl stop docker // close docker
Then install Docker Compose
Docker Compose yes docker A command line tool provided , Used to define and run applications made up of multiple containers . Use compose, We can go through YAML File declaratively defines the services of the application , And by a single command to complete the application creation and start .
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
Modify the Execution Authority
sudo chmod +x /usr/local/bin/docker-compose
Establish a soft connection
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
View version , Verify the installation is successful .
docker-compose --version
docker-compose version 1.29.2, build 5becea4c
install jq
First installation EPEL Source , Enterprise Edition Linux Additional package ( hereinafter referred to as EPEL) It's a Fedora Special interest group , Used to create 、 Maintain and manage for enterprise edition Linux A set of high-quality additional software packages , Object oriented includes but is not limited to Red hat enterprise edition Linux (RHEL)、 CentOS、Scientific Linux (SL)、Oracle Linux (OL) .
EPEL Software packages are usually not compatible with enterprise edition Linux The software package in the official source conflicts , Or replace files with each other .EPEL Project and Fedora Almost the same , Contains a complete build system 、 Upgrade Manager 、 Image manager, etc .
install EPEL Source
yum install epel-release
installed EPEL After source , You can check it out jq Package exists :
yum list jq
install jq:
yum install jq
5.2、 install python3
Installation dependency
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
Download installation package
wget https://www.python.org/ftp/python/3.8.3/Python-3.8.3.tgz
tar -zxvf Python-3.8.3.tgz
Compilation and installation
mkdir /usr/local/python3
cd Python-3.8.3
./configure --prefix=/usr/local/python3
make && make install
Modify the system default python Point to
rm -rf /usr/bin/python
ln -s /usr/local/python3/bin/python3 /usr/bin/python
Modify the system default pip Point to
rm -rf /usr/bin/pip
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
verification
python -V
Repair yum
python3 It can lead to yum Can't be used normally
vi /usr/bin/yum
hold #! /usr/bin/python It is amended as follows #! /usr/bin/python2
vi /usr/libexec/urlgrabber-ext-down
hold #! /usr/bin/python It is amended as follows #! /usr/bin/python2
vi /usr/bin/yum-config-manager
#!/usr/bin/python Change it to #!/usr/bin/python2
No need to modify
5.3、 Installation and startup datahub
Upgrade first pip
python3 -m pip install --upgrade pip wheel setuptools
You need to see the following successful return .
Attempting uninstall: setuptools
Found existing installation: setuptools 57.4.0
Uninstalling setuptools-57.4.0:
Successfully uninstalled setuptools-57.4.0
Attempting uninstall: pip
Found existing installation: pip 21.2.3
Uninstalling pip-21.2.3:
Successfully uninstalled pip-21.2.3
Check environment
python3 -m pip uninstall datahub acryl-datahub || true # sanity check - ok if it fails
Receiving such a prompt indicates that there is no problem .
WARNING: Skipping datahub as it is not installed.
WARNING: Skipping acryl-datahub as it is not installed.
install datahub, This step takes a long time , Wait patiently .
python3 -m pip install --upgrade acryl-datahub
Receiving such a prompt indicates that the installation is successful .
Successfully installed PyYAML-6.0 acryl-datahub-0.8.20.0 avro-1.11.0 avro-gen3-0.7.1 backports.zoneinfo-0.2.1 certifi-2021.10.8 charset-normalizer-2.0.9 click-8.0.3 click-default-group-1.2.2 docker-5.0.3 entrypoints-0.3 expandvars-0.7.0 idna-3.3 mypy-extensions-0.4.3 progressbar2-3.55.0 pydantic-1.8.2 python-dateutil-2.8.2 python-utils-2.6.3 pytz-2021.3 pytz-deprecation-shim-0.1.0.post0 requests-2.26.0 stackprinter-0.2.5 tabulate-0.8.9 toml-0.10.2 typing-extensions-3.10.0.2 typing-inspect-0.7.1 tzdata-2021.5 tzlocal-4.1 urllib3-1.26.7 websocket-client-1.2.3
In the end, we see datahub Version of .
[[email protected] bin]# python3 -m datahub version
DataHub CLI version: 0.8.20.0
Python version: 3.8.3 (default, Aug 10 2021, 14:25:56)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]
Then start datahub
python3 -m datahub docker quickstart
It will go through a long download process , Wait patiently .

To start , Pay attention to the error reporting . If the network speed is not good , It needs to be executed several times .

If you can see the following display , Proof of successful installation .

visit ip:9002 Input datahub datahub Sign in

6、 ... and 、 Acquisition of metadata information
Log in to Datahub in the future , There will be a friendly welcome page . To prompt how to crawl metadata .

Metadata ingestion uses a plug-in architecture , You only need to install the required plug-ins .
There are many sources of intake
The plug-in name Installation command Provide function
mysql pip install 'acryl-datahub[mysql]' MySQL source
Two plug-ins are installed here :
Source :mysql
Remit :datahub-rest
pip install 'acryl-datahub[mysql]'

There are many packages installed , Get the following prompt to prove that the installation is successful .
Installing collected packages: zipp, traitlets, pyrsistent, importlib-resources, attrs, wcwidth, tornado, pyzmq, pyparsing, pycparser, ptyprocess, parso, nest-asyncio, jupyter-core, jsonschema, ipython-genutils, webencodings, pygments, prompt-toolkit, pickleshare, pexpect, packaging, nbformat, matplotlib-inline, MarkupSafe, jupyter-client, jedi, decorator, cffi, backcall, testpath, pandocfilters, nbclient, mistune, jupyterlab-pygments, jinja2, ipython, defusedxml, debugpy, bleach, argon2-cffi-bindings, terminado, Send2Trash, prometheus-client, nbconvert, ipykernel, argon2-cffi, numpy, notebook, widgetsnbextension, toolz, ruamel.yaml.clib, pandas, jupyterlab-widgets, jsonpointer, tqdm, termcolor, scipy, ruamel.yaml, jsonpatch, ipywidgets, importlib-metadata, altair, sqlalchemy, pymysql, greenlet, great-expectations
Successfully installed MarkupSafe-2.0.1 Send2Trash-1.8.0 altair-4.1.0 argon2-cffi-21.3.0 argon2-cffi-bindings-21.2.0 attrs-21.3.0 backcall-0.2.0 bleach-4.1.0 cffi-1.15.0 debugpy-1.5.1 decorator-5.1.0 defusedxml-0.7.1 great-expectations-0.13.49 greenlet-1.1.2 importlib-metadata-4.10.0 importlib-resources-5.4.0 ipykernel-6.6.0 ipython-7.30.1 ipython-genutils-0.2.0 ipywidgets-7.6.5 jedi-0.18.1 jinja2-3.0.3 jsonpatch-1.32 jsonpointer-2.2 jsonschema-4.3.2 jupyter-client-7.1.0 jupyter-core-4.9.1 jupyterlab-pygments-0.1.2 jupyterlab-widgets-1.0.2 matplotlib-inline-0.1.3 mistune-0.8.4 nbclient-0.5.9 nbconvert-6.3.0 nbformat-5.1.3 nest-asyncio-1.5.4 notebook-6.4.6 numpy-1.21.5 packaging-21.3 pandas-1.3.5 pandocfilters-1.5.0 parso-0.8.3 pexpect-4.8.0 pickleshare-0.7.5 prometheus-client-0.12.0 prompt-toolkit-3.0.24 ptyprocess-0.7.0 pycparser-2.21 pygments-2.10.0 pymysql-1.0.2 pyparsing-2.4.7 pyrsistent-0.18.0 pyzmq-22.3.0 ruamel.yaml-0.17.19 ruamel.yaml.clib-0.2.6 scipy-1.7.3 sqlalchemy-1.3.24 termcolor-1.1.0 terminado-0.12.1 testpath-0.5.0 toolz-0.11.2 tornado-6.1 tqdm-4.62.3 traitlets-5.1.1 wcwidth-0.2.5 webencodings-0.5.1 widgetsnbextension-3.5.2 zipp-3.6.0
Then check the installed plug-ins ,Datahub It is a plug-in installation method . You can check the data source acquisition plug-in Source, Transformation plug-in transformer, Get plug-ins Sink.
python3 -m datahub check plugins

so Mysql Plug ins and Rest The interface plug-in has been installed , The following configuration is from MySQL Get metadata usage Rest Interface stores data DataHub.
vim mysql_to_datahub_rest.yml
# A sample recipe that pulls metadata from MySQL and puts it into DataHub
# using the Rest API.
source:
type: mysql
config:
username: root
password: 123456
database: cnarea20200630
transformers:
- type: "fully-qualified-class-name-of-transformer"
config:
some_property: "some.value"
sink:
type: "datahub-rest"
config:
server: "http://ip:8080"
# datahub ingest -c mysql_to_datahub_rest.yml
Then there is the long data acquisition process .

Get the following prompt , Prove success .
{datahub.cli.ingest_cli:83} - Finished metadata ingestion

Sink (datahub-rest) report:
{'records_written': 356,
'warnings': [],
'failures': [],
'downstream_start_time': datetime.datetime(2021, 12, 28, 21, 8, 37, 402989),
'downstream_end_time': datetime.datetime(2021, 12, 28, 21, 13, 10, 757687),
'downstream_total_latency_in_seconds': 273.354698}
Pipeline finished with warnings
Refresh here datahub page ,mysql Metadata information of has been successfully obtained .
Enter the table to view the metadata , Table field information .
The metadata analysis page has been shown in detail before .

So far we're done Datahub from 0 To 1 Build , In the whole process, in addition to simple installation and configuration , There is basically no code development work . however datahub There are more functions , For example, the acquisition of data kinship , Perform conversion operations in the process of metadata acquisition . There will also be tutorials to update these features in future articles .
To be continued ~
边栏推荐
- Introduction and basic knowledge of machine learning
- Elk elegant management server log
- POI exports excel and displays hierarchically according to parent-child nodes
- An article explaining the publisher subscriber model and the observer model
- [applet project development -- Jingdong Mall] classified navigation area of uni app
- Xception learning notes
- [applet project development -- Jingdong Mall] user defined search component of uni app (Part 1)
- The 'mental (tiring) process' of building kubernetes/kubesphere environment with kubekey
- Dell server restart Idrac method
- Restcloud ETL practice data row column conversion
猜你喜欢

Introduction and installation of Solr

Introduction and basic knowledge of machine learning

Huawei operator level router configuration example | BGP VPLS and LDP VPLS interworking example

lavaweb【初识后续问题的解决】

安装VCenter6.7【VCSA6.7(vCenter Server Appliance 6.7) 】

最新接口自动化面试题

PCB defect detection based on OpenCV and image subtraction

Redis高效点赞与取消功能
![[applet project development -- JD mall] uni app commodity classification page (first)](/img/6c/5b92fc1f18d58e0fdf6f1896188fcd.png)
[applet project development -- JD mall] uni app commodity classification page (first)
How the network is connected: Chapter 2 (Part 2) packet receiving and sending operations between IP and Ethernet
随机推荐
【小程序项目开发-- 京东商城】uni-app之分类导航区域
最好用的信任关系自动化脚本(shell)
几行事务代码,让我赔了16万
C#实现图的深度优先遍历--非递归代码
Chapitre 03 Bar _ Gestion des utilisateurs et des droits
Huawei operator level router configuration example | BGP VPLS and LDP VPLS interworking example
php批量excel转word
Redis tutorial
Stop saying that you can't solve the "cross domain" problem
[applet project development -- JD mall] uni app commodity classification page (Part 2)
xxl-job使用指南
Here comes the share creators budding talent training program!
Catch 222222
Summary of problems encountered in debugging positioning and navigation
【EXSI】主机间传输文件
Servlet [first introduction]
Poj-3486-computers[dynamic planning]
[machine learning] vectorized computing -- a must on the way of machine learning
Restcloud ETL WebService data synchronization to local
MCU firmware packaging Script Software