当前位置:网站首页>Petrv2: a unified framework for 3D perception of multi camera images
Petrv2: a unified framework for 3D perception of multi camera images
2022-07-01 17:15:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

Author Huang Yu
Source computer vision deep learning and automatic driving
arXiv Upload on 6 month 10 Day's paper “PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images“, It is the work of Sun Jian team of Kuangshi Technology ( It is also the project report of Dr. Sun before his death , Just as a souvenir ).

be based on PETR,PETRv2 The validity of time domain modeling is explored , It uses the time information of the previous frame to enhance 3D object detection . More specifically , take PETR Medium 3D Position insertion (3D PE) Extended to time domain modeling .3D PE Realize the time alignment of different frame target positions .
In order to improve the 3D PE Data adaptability , Further introduce feature guided position encoder . To support high quality BEV Division ,PETRv2 Add a set of divisions query, It provides a simple and effective solution . Each segment query Responsible for segmentation BEV A specific part of the map patch.
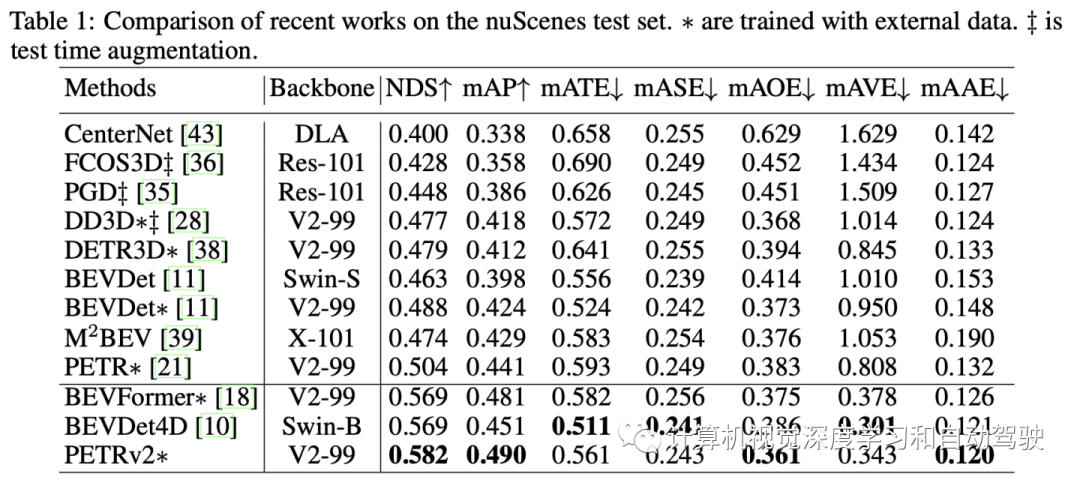
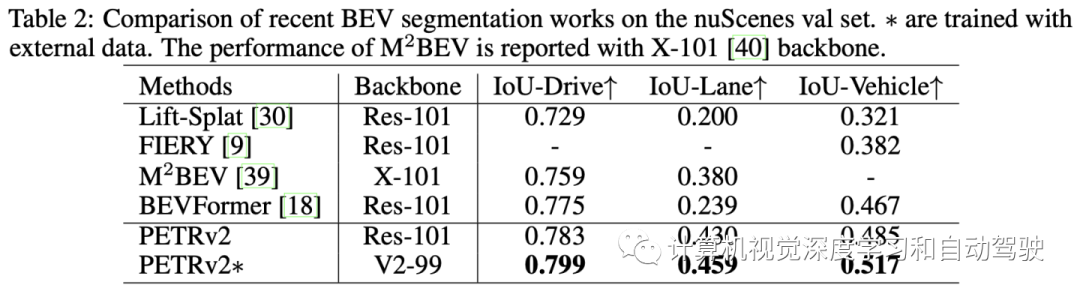
PETRv2 stay 3D Target detection and BEV Segmentation achieves the most advanced performance . Code is located https://github.com/megvii-research/PETR.
In recent years , Auto drive system based on multi camera images 3D Perception technology has received extensive attention . Multiple cameras 3D Target detection methods can be divided into based on BEV Based on DETR Methods . be based on BEV Methods ( for example ,BEVDet) adopt LSS Explicitly convert multi view features to aerial views (BEV) Express . And these are based on BEV The algorithm is different , be based on DETR The method will each 3D Goal modeling is goal query, And use Hungarian algorithm to realize end-to-end modeling .
PETR(“Petr: Position embedding transformation for multi-view 3d object detection“. arXiv 2203.05625, 2022) yes DETR A kind of , Its job is multi view 3D Position embedding transformation of target detection (PETR).PETR take 3D The position information of coordinates is encoded as image features , Generate 3D Location - The characteristics of awareness . The goal is query Perceptible 3D Location - Detect features and perform end-to-end target detection .
As shown in the figure PETR The architecture of the figure : Input the multi view image into the backbone ( Such as ResNet), Extract multiple views 2D Image features . stay 3D Coordinate generator , Camera screenshot shared by all views (frustum) Space is discretized into 3D grid . Using different camera parameters, the grid coordinates are transformed to 3D World space coordinates . And then 2D Image features and 3D Coordinates are injected into 3D Position encoder , Generate 3D Location - Aware of features .query Generator generated target query Through and with transformer In decoder 3D Location - Aware of feature interaction to update . Updated query Further used to predict 3D Borders and target classes .

This 3D The structure of the position encoder is shown in the figure : Multi view 2D Image features are input to 1×1 The convolution layer is used to reduce the dimension . Through multi-layer perception 3D Generated by coordinate generator 3D The coordinates are converted to 3D Position insertion .3D Position embedded shapes and 2D The image features are the same .3D The location is embedded in the same view 2D Image features together , Generate 3D Location - Aware of features . Last , take 3D Location - Perceive the flattening of features , Used as a transformer The input of the decoder .

For time domain modeling , The main problem is how to 3D Align the target position of different frames in space .BEVDet4D Transform the previous frame's BEV The feature is clearly aligned with the current frame . However ,PETR take 3D The location is implicitly encoded as 2D Image features , And cannot perform explicit feature conversion . because PETR It has been proved 3D PE stay 3D Perceived effectiveness , that 3D PE Whether it still applies to time alignment ?
stay PETR in , Through the camera parameters, the mesh points of the camera frustum space ( Share for different views ) Convert to 3D coordinate . And then 3D Coordinate input to simple multi-layer perception (MLP) Generate 3D PE. It is found in practice that , By simply adding 3D Align the coordinates with the current frame ,PETR It works well in time domain .
about BEV Segmented joint learning ,BEVFormer Provides a unified solution , take BEV Each point on the map is defined as a BEV query. therefore ,BEV query Can be used for 3D Target detection and BEV Division . However , When BEV The resolution of the map is relatively large ( such as 256×256) when ,BEV query The number of ( such as >60000) It tends to be very big . because transformer The decoder adopts a global attention mechanism , So this goal query The definition is obviously not suitable for PETR.
As shown in the figure ,PETRv2 The overall architecture of is based on PETR On the basis of , And through time domain modeling and BEV Split and expand :2D Image features are through 2D The trunk ( for example ResNet-50) Extracted from multi view images ,3D Coordinates are generated from the truncated cone space of the camera , Such as PETR equally . Considering self motion , Previous frame t-1 Of 3D The coordinates are first transformed into the current frame through attitude transformation t The coordinate system of . then , Set the adjacent frame's 2D The characteristics and 3D The coordinates are connected in series , And input to the feature guided position encoder (FPE). then , Use FPE by transformer The decoder generates key and value Components . Besides , From learnable 3D Anchors and fixed BEV spot , Initialize the detection respectively query(det query) And segmentation query(seg query), And feed it to transformer In decoder , Interact with multi view image features . Last , Will update the query Input the detection head and segmentation head respectively for final prediction .
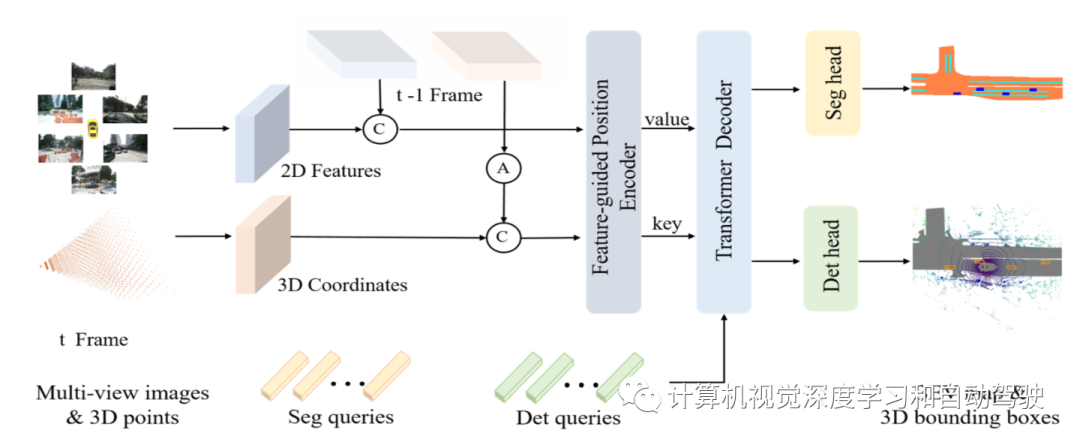
Time alignment is converting frames t-1 3D coordinates to frame t The coordinate system of . For clarity , First, mark some coordinate systems : Camera coordinates c(t), Lidar coordinates l(t), Vehicle coordinates e(t); Besides , The global coordinates are g. take T It is defined as the transformation matrix from the source coordinate system to the target coordinate system . use l(t) By default 3D Space to generate multi view cameras 3D Location - Aware of features . From i Projected by a camera 3D spot P-l-i(t) It can be expressed as :
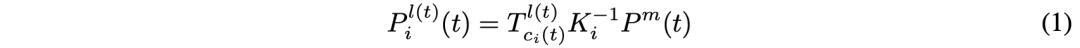
Given auxiliary frame t− 1, From frame t-1 To frame t alignment 3D Point coordinates :
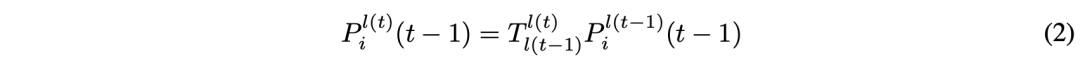
There is a global coordinate space as a frame t-1 And frames t The bridge between , Transformation T It is easy to calculate :

PETR take 3D The coordinates are converted to 3D Position insertion (3D PE), Its generation can be expressed as :
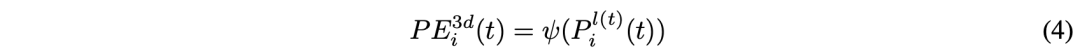
PETR Medium 3D PE Independent of the input image .3D PE Should be determined by the 2D Feature driven , Because image features can provide some information guidance ( For example, depth ). The author adopts a feature guided position encoder , Implicitly introduces a visual priori . This feature guides 3D The generation of location embedding can be expressed as :
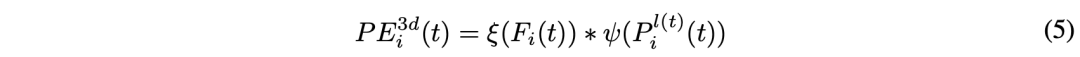
next , Jiang Jing 1×1 Convolution projection 2D Image features are fed back to a small MLP The Internet ξ and Sigmoid Function , Get attention weight .3D The coordinates are determined by another MLP The Internet ψ transformation , And multiply it by the weight of attention , Generate 3D PE.3D PE add to 2D features , obtain transformer Decoder key Components . Projective 2D Features are used as transformer Decoder value Components .
The following is PETR Equipped with seg query, Support high-quality BEV Division . high resolution BEV The map can be divided into a few patch. For the use of BEV Segmented seg query, Every seg query Correspond to a specific patch( for example ,BEV Top left of the map 16×16 Pixels ).
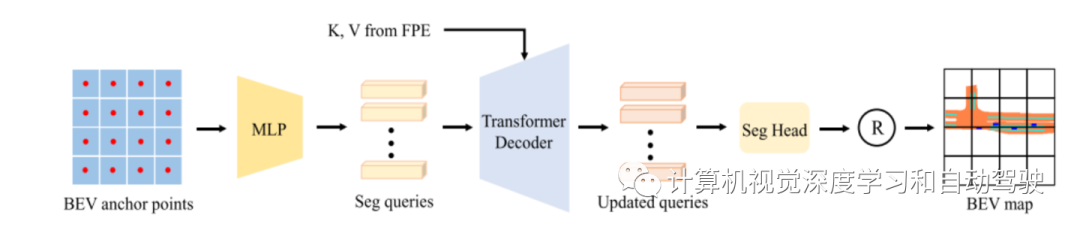
As shown in the figure above ,seg query Use BEV Initialize the fixed anchor in the space , Similar to in PETR Generate detection query(det query). then , Through a simple with two linear layers MLP Project these anchors onto seg query in . then ,seg query Input to transformer decoder , And interact with image features . about transformer decoder , Use the same framework as the detection task .
then , Will update the seg query Finally, input the split header ( A simple MLP The Internet , Followed by a Sigmoid layer ), To predict BEV The embedded . Every BEV Embedding is reshaped into a BEV patch( Shape is 16×16). all BEV patch Connected together in the spatial dimension , Produce segmentation results ( Shape is 256×256). For split branches , Prediction with weighted cross entropy loss BEV Map supervision training :
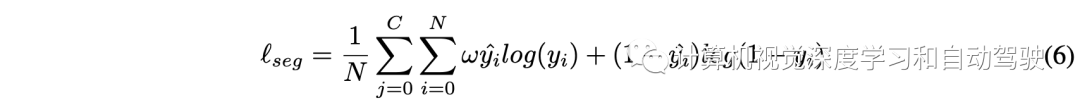
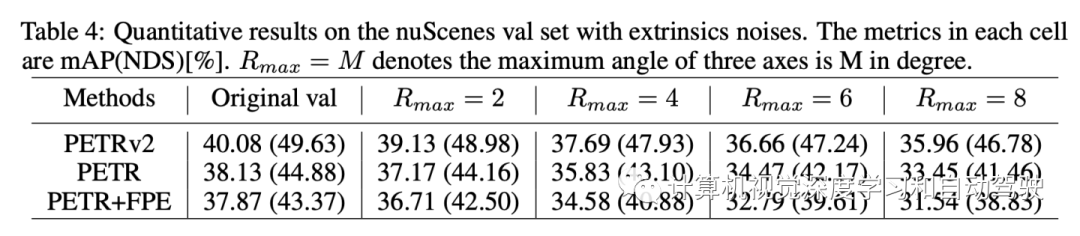
LSS It shows the performance in the case of external noise and camera falling off during the test . Again ,BEVFormer It is proved that the model change is robust to the external characteristics of the camera . In practice , There are various sensor errors and system deviations . Due to the high requirements for safety and reliability , It is important to verify the impact of these situations .
As shown in the figure , Focus on the following three common types of sensor errors :

External noise : External noise is very common in reality , For example, camera shake caused by car collision or camera offset caused by external environmental forces . In these cases , The external information provided by the system is inaccurate , Perceived output will be affected .
Camera lost : When a camera fails or is blocked , The camera image will be lost . Multi view images provide panoramic visual information , But one of them may be missing in the real world . It is necessary to evaluate the importance of these images , In order to formulate sensor redundancy strategy in advance .
Camera delay : Due to the exposure time of the camera , Delay is also a challenge , Especially at night . Long exposure time causes the system to receive the image of the previous time , And bring significant output offset .
In order to simulate external noise and evaluate the effect , Choose to randomly apply the external parameter matrix of the camera 3D rotate . Ignore other noise patterns , Such as translation , To avoid multivariable interference . say concretely , Randomly select one from multiple camera heads to apply 3D rotate . take α、β、γ Expressed as along X、Y、Z The angle of the axis , Study several maximum amplitudes αmax、βmax、γmax Rotation setting of ∈{2, 4, 6, 8}, among αmax = 2 Express α from [−2,2] Uniform value . In the experiment , use Rmax = M Express αmax = βmax = γmax = M.
The experimental results are as follows :

When losing some perspective images nuScene Performance changes

This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- Research and investment strategy report of China's sodium sulfate industry (2022 Edition)
- China BMS battery management system Market Research Report (2022 Edition)
- 中国锦纶长丝缝纫线发展预测与投资方向研究报告(2022版)
- 求求你们,别再刷 Star 了!这跟“爱国”没关系!
- SQL question brushing 586 Customers with the most orders
- AI college entrance examination volunteer filling: the gods of Dachang fight, and candidates pay to watch
- 深度优先遍历和广度优先遍历[通俗易懂]
- Transition technology from IPv4 to IPv6
- Report on Market Research and investment prospects of ammonium dihydrogen phosphate industry in China (2022 Edition)
- 智能运维实战:银行业务流程及单笔交易追踪
猜你喜欢

(28) Shape matching based on contour features
重磅披露!上百个重要信息系统被入侵,主机成为重点攻击目标

Encryption and decryption of tinyurl in leetcode

SQL注入漏洞(Mysql与MSSQL特性)
Vulnhub range hacker_ Kid-v1.0.1
Roewe rx5's "a little more" product strategy

Alibaba cloud, Zhuoyi technology beach grabbing dialogue AI

C語言輸入/輸出流和文件操作

Gold, silver and four want to change jobs, so we should seize the time to make up

【PyG】文档总结以及项目经验(持续更新

随机推荐
Pytest learning notes (13) -allure of allure Description () and @allure title()
Computed property “xxx“ was assigned to but it has no setter.
There is a new breakthrough in quantum field: the duration of quantum state can exceed 5 seconds
Gaussdb (for MySQL):partial result cache, which accelerates the operator by caching intermediate results
深度优先遍历和广度优先遍历[通俗易懂]
中国乙腈市场预测与战略咨询研究报告(2022版)
[wrung Ba wrung Ba is 20] [essay] why should I learn this in college?
[live broadcast appointment] database obcp certification comprehensive upgrade open class
中国冰淇淋市场深度评估及发展趋势预测报告(2022版)
DNS
Babbitt | yuan universe daily must read: Naixue coin, Yuan universe paradise, virtual stock game Do you understand Naixue's tea's marketing campaign of "operation pull full"
【splishsplash】关于如何在GUI和json上接收/显示用户参数、MVC模式和GenParam
Integer array merge [JS]
[C language supplement] judge which day tomorrow is (tomorrow's date)
Introduction to software engineering - Chapter 6 - detailed design
RadHat搭建内网YUM源服务器
机器学习11-聚类,孤立点判别
中国PBAT树脂市场预测及战略研究报告(2022版)
开发那些事儿:EasyCVR集群设备管理页面功能展示优化
[mathematical modeling] [matlab] implementation of two-dimensional rectangular packing code