当前位置:网站首页>Station B, Master Liu Er - back propagation
Station B, Master Liu Er - back propagation
2022-07-06 05:41:00 【Ning Ranye】
Series articles :
B Stand up, Mr. Liu er - Linear regression and gradient descent
List of articles
Code
import matplotlib.pyplot as plt
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# w Is a tensor with gradient tracking set
w = torch.Tensor([1.0])
w.requires_grad = True
print("w=",w)
def forward(x):
return x*w
# Loss function of single data
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)*(y_pred-y)
# Learning rate
alpha = 0.001
epoch_list = []
w_list = []
loss_list = []
for epoch in range(100):
l = 0
loss_sum = 0
for (x ,y) in zip(x_data, y_data):
# l, loss_sum It's all tensors , Gradient free tracking
l = loss(x,y)
loss_sum += l.data
# My question : Back propagation 、 Gradient update is carried out epoch*len(x_data),
# Why not epoch Time .
l.backward()
w.data = w.data - alpha*w.grad.data
w.grad.data.zero_()
w_list.append(w.data)
epoch_list.append(epoch)
# To get the value on the tensor, you need to convert it to numpy
loss_list.append(loss_sum.data.numpy()[0])
plt.plot(epoch_list, loss_list)
plt.xlabel("epoch")
plt.ylabel("loss_sum")
plt.show()
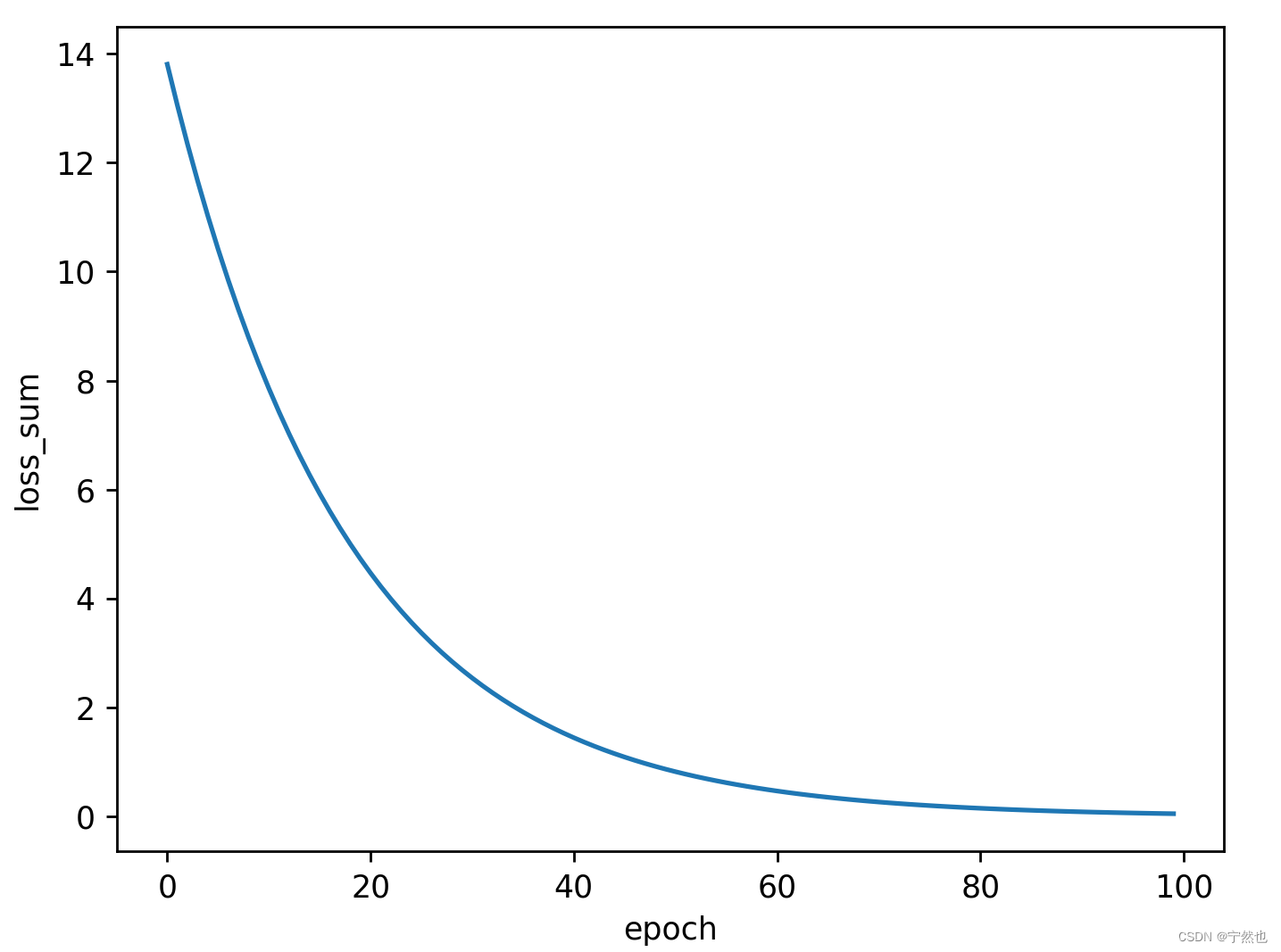
Back propagation 、 Gradient update lepoch Code for the next time
import matplotlib.pyplot as plt
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# w Is a tensor with gradient tracking set
w = torch.Tensor([1.0])
w.requires_grad = True
print("w=",w)
def forward(x):
return x*w
# Loss function of single data
def loss(xs, ys):
# y_pred = forward(x)
# return (y_pred - y)*(y_pred-y)
loss_sum = 0
for(x, y) in zip(xs, ys):
y_pred = forward(x)
loss_sum += (y_pred-y)*(y_pred-y)
return loss_sum/len(xs)
# Learning rate
alpha = 0.001
epoch_list = []
w_list = []
loss_list = []
# Conduct epoch Sub gradient update 、 Loss function calculation
for epoch in range(100):
# Calculate the loss function of all data
l = loss(x_data, y_data)
l.backward()
# Gradient update
w.data = w.data - alpha * w.grad.data
w.grad.data.zero_()
w_list.append(w.data)
epoch_list.append(epoch)
loss_list.append(l.data.numpy()[0])
plt.plot(epoch_list, loss_list)
plt.xlabel("epoch")
plt.ylabel("loss_sum")
plt.show()
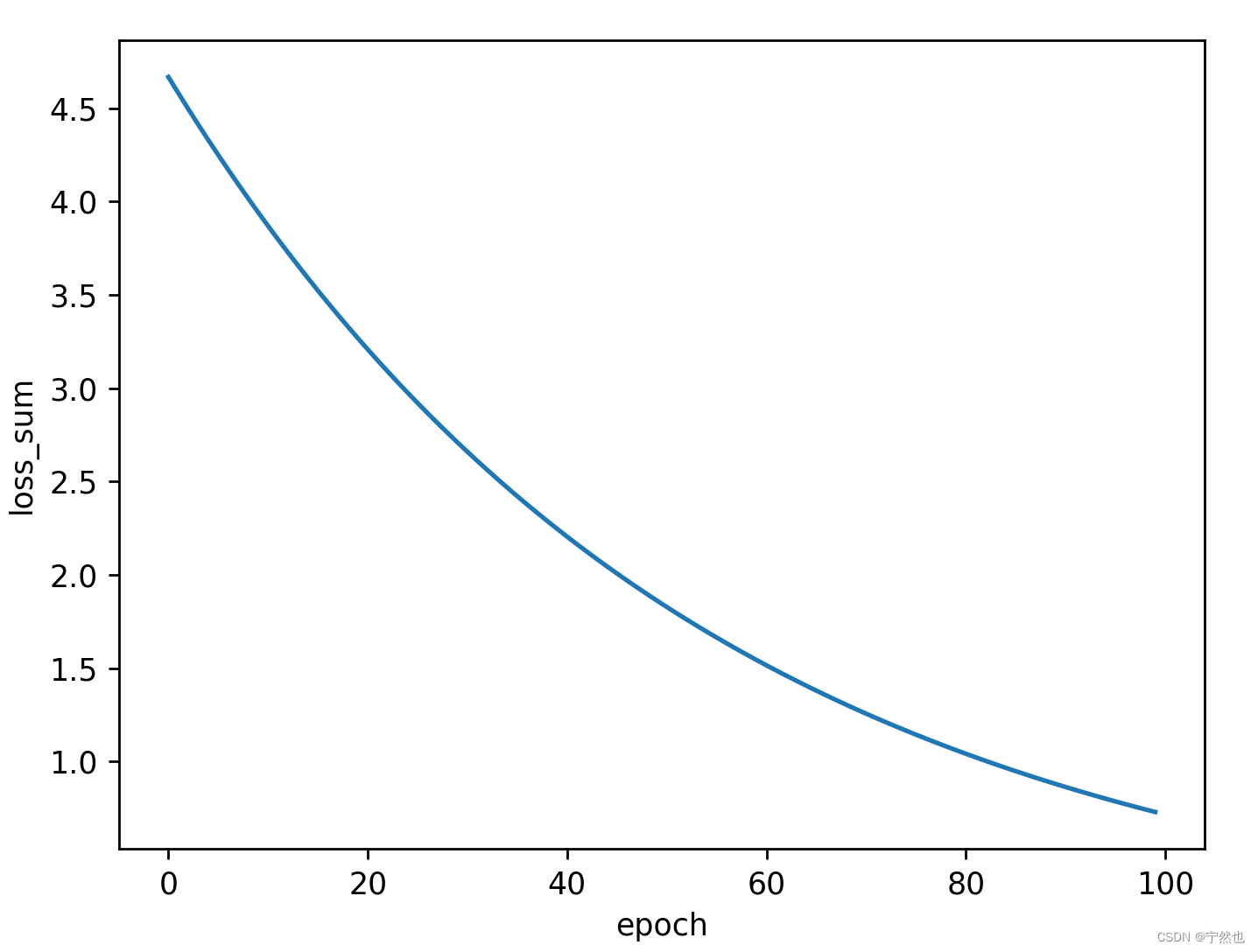
The pictures that come out in two ways are Loss reduction rate 、 The results are different .
At present, I also have questions , I don't know which kind is suitable .
B The station teacher wrote the first code
边栏推荐
- Huawei od computer test question 2
- [email protected]树莓派
- B站刘二大人-线性回归 Pytorch
- 【SQL server速成之路】——身份驗證及建立和管理用戶賬戶
- 改善Jpopup以实现动态控制disable
- UCF(暑期团队赛二)
- First acquaintance with CDN
- Vulhub vulnerability recurrence 67_ Supervisor
- C Advanced - data storage (Part 1)
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
猜你喜欢

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
![[Jiudu OJ 07] folding basket](/img/a7/e394f32cf7f02468988addad67674b.jpg)
[Jiudu OJ 07] folding basket
B站刘二大人-反向传播
Redis消息队列

SequoiaDB湖仓一体分布式数据库2022.6月刊
Notes, continuation, escape and other symbols

26file filter anonymous inner class and lambda optimization

What impact will frequent job hopping have on your career?
[SQL Server Express Way] - authentification et création et gestion de comptes utilisateurs
实践分享:如何安全快速地从 Centos迁移到openEuler
![[SQL Server Express Way] - authentification et création et gestion de comptes utilisateurs](/img/42/c1def031ec126a793195ebc881081e)
随机推荐
04. 项目博客之日志
2022 half year summary
C Advanced - data storage (Part 1)
Vulhub vulnerability recurrence 72_ uWSGI
Vulhub vulnerability recurrence 71_ Unomi
05. Security of blog project
Safe mode on Windows
剑指 Offer II 039. 直方图最大矩形面积
嵌入式面试题(四、常见算法)
注释、接续、转义等符号
毕业设计游戏商城
04. Project blog log
Jushan database appears again in the gold fair to jointly build a new era of digital economy
【SQL server速成之路】——身份验证及建立和管理用户账户
Figure database ongdb release v-1.0.3
How to get list length
【云原生】3.1 Kubernetes平台安装KubeSpher
26file filter anonymous inner class and lambda optimization
[QNX Hypervisor 2.2用户手册]6.3.3 使用共享内存(shmem)虚拟设备
How to download GB files from Google cloud hard disk