当前位置:网站首页>A bold sounding and awesome operation - remake a Netflix
A bold sounding and awesome operation - remake a Netflix
2022-06-26 07:12:00 【Java enthusiast】
This is an article by Ankit Sirmorya Guest article written .Ankit Head of machine learning at Amazon / Senior machine learning Engineer , And led several machine learning projects in the Amazon ecosystem .Ankit Has been committed to applying machine learning to solve ambiguous business problems and improve the customer experience . for example , He created a platform , Using reinforcement learning technology to experiment with different hypotheses on Amazon Product Pages . at present , He was in Alexa In shopping organization , Develop solutions based on machine learning , Send personalized reorder tips to customers , To improve their experience .
Problem specification
Design one similar to Netflix Video streaming media platform , Content creators can upload their own video content , Let the audience play back through various devices . We should also be able to store video user statistics , Such as viewing times 、 Video viewing duration, etc .
Collect requirements
Within limits
The application should be able to support the following requirements :
- Content creators should be able to upload content at a specified time .
- Viewers can watch videos on various platforms ( TV 、 Move App etc. ).
- The user should be able to search the video according to the video title .
- The system shall also support subtitles of videos .
Beyond the range
- The mechanism of recommending personalized videos to different users .
- Charging and subscription mode for watching video .
Capacity planning
We need to develop an application , It should be able to support Netflix Traffic on that scale . We should also be able to handle popular online dramas ( Such as 《 House of CARDS 》、《 Fatal poison 》 etc. ) The traffic surge that often occurs when sequels are launched . Here are some figures related to capacity planning .
- Number of active users registered on the application = 1 Hundreds of millions of people .
- The average size of video content uploaded per minute = 2500 MB.
- Total combination of resolution and codec format to be supported = 10.
- The average number of videos users watch every day = 3.
Netflix It's made up of multiple microservices , among , The playback service responsible for responding to user playback queries will get the maximum traffic , therefore , It requires the maximum number of servers . We can calculate the number of servers required to process playback requests by the following formula :
S The playback = (# Number of playback requests per second * Delay time )/ For each server # Number of concurrent connections
Let's assume that the delay of playback service ( Time required to respond to user requests ) by 20 millisecond , Each server can support up to 10K The connection of . Besides , We need to be in 75% The application is extended in case of peak traffic when active users make playback requests . under these circumstances , We will need a total of 150 Servers (= 75M * 20ms/10K).
Number of videos viewed per second =(# Active users # Average video viewed per day )/ 86400 = 3472(100M 3/86400)
The size of the content stored every day = # Average video size uploaded per minute # Pairing combination of resolution and codec 24 60 = 36TB / God (= 2500MB 10 24 60)
Outline design
The system will mainly have two types of users : The content creator who uploaded the video content , And the audience watching the video . The whole system can be divided into the following parts :
- Content distribution network (CDN): It is responsible for storing content geographically closest to the user . This greatly enhances the user experience , Because it reduces the network and geographical distance that our video bits must go through in the playback process . It also greatly reduces the overall demand for upstream network capacity .
Interesting things :Open Connect yes Netflix Global customization CDN, Provide... To members around the world Netflix TV shows and movies . This is essentially a project made up of thousands of Open Connect Appliances(OCA) Composed network , Used to store encoded video / image file , And be responsible for transmitting the replayable bits to the client device .OCA It consists of optimized hardware and software , Deployed in ISP On the website , And customize , To provide the best customer experience .
- Control plane : This component will be responsible for uploading new content , These contents will eventually pass CDNS distribution . It will also be responsible for things like file storage 、 Fragmentation 、 Data storage and interpretation of relevant telemetry data about the playback experience . The main micro services in this component are listed as follows :
- CDN Health checker service : This microservice will be responsible for regular inspection CDN The health of the service , Understand the overall playback experience , And try to optimize it .
- Content uploader service : This micro service will consume the content provided by the content generator , And in CDN To distribute , To ensure health, robustness and the best playback experience . It will also be responsible for storing the metadata of video content in the data memory .
- data storage : Video metadata ( title 、 Description, etc. ) Is permanently stored in data storage . We will also persist the caption information in the best database .
- Data plane : This is the component that the end user interacts with when playing back video content . This component comes from different media streaming platforms ( TV 、 mobile phone 、 Tablet, etc ) Get request , And return... That can provide the requested file CDN The website of . It will consist of two main micro Services .
- Playback service : The microservice is responsible for determining the specific files required for the playback request service .
- Guidance services : This service determines the best CDN website , From there, you can get the requested playback

Netflix HLD
In the diagram above , We showed an aerial view of the whole system , It should be able to meet the requirements of all ranges . The details of each component interaction are listed below :
- The content creator uploads the video content to the control plane .
- The video content is uploaded to CDN On ,CDN Geographically closer to end users .
- CDN Report status to the control plane , Such as health indicators 、 What files do they store 、 The best BGP Routing, etc. .
- Video metadata and related CDN The information is permanently stored in the data memory .
- The user on the client device proposed to play back a specific title ( TV shows or movies ) Request .
- The playback service determines the file required to play back a specific title .
- Guide the service to choose the best CDN, You can get the required files from there . It generates these CDN Of URL, And provide it to the client device .
- Client device request CDN Provide the required documents .
- CDN Provide the required files to the client device , And present it to users .
API Design
Video uploading
route :
POST /video-contents/v1/videosCopy code
The main body :
{
videoTitle : Title of the video
videoDescription : Description of the video
tags : Tags associated with the video
category : Category of the video, e.g. Movie, TV Show,
videoContent: Stream of video content to be uploaded
}
Copy code
Search video
route :
GET /video-contents/v1/search-query/Copy code
Query parameters :
{
user-location: location of the user performing search
}Copy code
Streaming video
route :
GET /video-contents/v1/videos/Copy code
Query parameters :
{
offset: Time in seconds from the beginning of the video
}Copy code
Data model
Within the scope of this problem , We need to persist the video metadata and its subtitles in the database . Video metadata can be stored in an aggregation oriented database , Considering that the values in the aggregate may be updated frequently , We can use MongoDB Such document based storage stores this information . The data model used to store metadata is shown in the following table .

We can use a time series database , Such as OpenTSDB, It is based on Cassandra above , To store subtitles . Below we show a fragment of a data model , It can be used to store video subtitles . In this model ( We call it media documentation ), We provide an event based representation , Each event occupies a time interval on the timeline .

Interesting things : In this speech , come from Netflix Of Rohit Puri When it comes to the Netflix Media database (Netflix Media Database,NMDB), It is based on the concept of media timeline with spatial attributes .NMDB Expect to be a highly scalable 、 Multi tenant media metadata system , It can provide near real-time queries , And can provide high read and write throughput . The structure of the media timeline data model is called “Media Document”.
Component design
Control plane
This component is mainly composed of three modules : Content uploader ,CDN Health checkers , And title indexer . Each of these modules will be microservices that perform specific tasks . We have covered the details of these modules in the following chapters .
Content uploader
When the content creator uploads content , The module is executed . It is responsible for the CDN Distribute content on , To provide the best customer experience .

Sequence diagram of content upload operation
The above figure describes the video content uploaded by the content creator ( TV shows or movies ) The sequence of operations performed when .
- The content creator uploads the original video content , It can be a TV show or a movie .
- Content_Storage_Service Divide the original video file into several pieces , And save these fragments in the file storage system .
- Video_Encoder Each segment is encoded with different codecs and resolutions .
- The encoded file segments are stored in the file store .
- Video_Distributor Read encoded file segments from the distributed file storage system .
- Video_Distributor stay CDN Distribute encoded file segments in .
- Video_Distributor The of the video CDN URL link persistence in data_storage in .
Video encoder
The working principle of the encoder is to divide the video file into smaller video segments . These video clips are encoded with all possible combinations of codecs and resolutions . In our case , We can plan to support four codecs (Cinepak、MPEG-2、H.264、VP8) And three different resolutions (240p、480p、720p). It means , Each video segment is encoded as 12 format (4 There are two kinds of codecs * 3 It's a kind of resolution ). These encoded video segments are distributed in CDN On ,CDN Your web address is saved in the data store . The playback API Responsible for the input parameters requested by the user ( Customer's equipment 、 Bandwidth, etc. ) Find the ideal CDN website .
Interesting things :Netflix Media processing platform for video coding (FFmpeg)、 Title Image generation 、 Media processing (Archer) wait . They developed a program called MezzFS Tools for , stay Netflix Memory time series database Atlas Data throughput collected in 、 Download efficiency 、 Indicators of resource use, etc . They use this data to develop and optimize , Such as replay and adaptive buffering .
CDN Health checkers
This module takes in CDN Health indicators , And persist it in the data store . When the user requests playback , These data are used by the data plane to obtain the best CDN website .

Used for inspection CDN Sequence diagram of health indicators
In the diagram above , We show how to get CDN Health indicators and BGP The sequence of operations performed by routing statistics . The details of each step in the sequence diagram are listed below .
- cron The job triggered the responsible inspection CDN Health microservices (CDN_Health_Checker_Service).
- CDN_Health_Checker_Service Be responsible for checking CDN And collect health indicators and other information .
- CDN_Health_Checker_Service take CDN Information is stored in a data store , Then use... In the data plane , Depending on the availability of the file 、 Health status and proximity to the client's Network , Find the best way to provide files CDN.
Title indexer
This module is responsible for creating the index of video title , And update them in elastic search , Enable end users to discover content faster .

stay ElasticSearch Sequence diagram for storing index titles on
The details of the sequence of operations required to index video titles for searching video content are listed below .
- cron-job Trigger Title_Indexer_Service To index video titles .
- Title_Indexer_Service Get the newly uploaded content from the data store and apply business rules to create an index for the video title .
- Title_Indexer_Service Update with the index of the video title Elastic_Search, Make the title easy to search .
Data plane
This component will process the user's request in real time , It consists of two main workflows : Playback workflow and content discovery workflow .
Playback workflow
This workflow is responsible for coordinating operations when users make playback requests . It coordinates between different microservices , Such as authorized services ( Used to check user authorization and license )、 Guidance services ( Used to determine the best playback experience ) And playback experience Services ( Used to track events to measure playback experience ). Guide the service through according to the user's requirements , Such as user's equipment 、 Bandwidth, etc. , Find the best CDN website , Ensure the best customer experience . The coordination process will be conducted by Playback_Service Handle , As shown in the figure below .

Sequence diagram of playback service
The details of each step in the sequence diagram are listed below :
- The client places a request to play back the video , The request is directed to Playback_Service.
- The playback service calls the authorization service to verify the user's request .
- Playback service calls guidance service (Steering_Service) To select which can provide playback CDN website .
- CDN The URL is returned to the client ( mobile phone / TV ).
- The client from CDN Search for content .
- The client publishes the playback experience events to the playback service .
- Playback_Service By calling Playback_Experience_Service To track events to measure the playback experience .
Interesting things : just as Netflix The engineer Suudhan Rangarajan At this time speech Mentioned in ,gRPC be used as Netflix Communication framework between different microservices . And REST comparison , Its advantages include : Two-way flow 、 Minimal operational coupling and cross language and platform support .
Content discovery workflow
This workflow is triggered when the user searches for the video title , It consists of two micro Services . Content discovery service and content similarity service . When a user asks to search for a video title , The content discovery service is called . On the other hand , If the exact video title does not exist in our data store , The content similarity service will return a similar list of video titles .

Sequence diagram of content query workflow
Below we list the details of each step involved in the content query workflow :
- The client searches for a video title .
- Content discovery services (Content Discovery Service,CDS) Inquire about Elastic Search, Check whether the title of the video exists in our database .
- If the video title can be found in elastic search , that CDS Get the details of the video from the data store .
- The details of the video will be returned to the client .
- If the title does not exist in our database ,CDS Query content similarity service (Content Similarity Service,CSS).
- CSS Return a list of similar video titles to CDS.
- CDS Get these video details similar to the video title from the data store .CDS Return similar video details to the customer .
Optimize
We can cache CDN Information to optimize the delay of playback workflow . This cache will be used by the boot service to pick CDN, Video content will be provided from there . We can further improve the performance of playback operations by asynchronizing the architecture . Let's play back api(getPlayData()) To further understand it , It needs customers (getCustomerInfo()) And device information (getDeviceInfo()) To deal with it (decisionPlayData()) A video playback request . Suppose these three operations (getCustomerInfo()、getDeviceInfo()、 and decidePlayData()) Depending on different microservices .
getPlayData() The synchronization implementation of the operation will be similar to the following code snippet . Such an architecture will include two types of thread pools : Request handler thread pool and client thread pool ( For every micro service ). For each playback request , From request - An execution thread of the response thread pool is blocked , until getPlayData() Call complete . whenever getPlayData() When called , A thread of execution ( From request - Processor thread pool ) Interact with the client thread pool of dependent microservices . It's blocked , Until the execution is complete . It applies to simple requests / Response model , Delay is not a problem , And the number of clients is limited .
PlayData getPlayData(String customerId, String titleId, String deviceId) {
CustomerInfo custInfo = getCustomerInfo(customerId);
DeviceInfo deviceInfo = getDeviceInfo(deviceId);
PlayData playData = decidePlayData(custInfo, deviceInfo, titleId);
return playData;
}Copy code
One way to extend the playback operation is to divide the operation into separate processes , These processes can be executed in parallel and reassembled . This can be achieved by using an asynchronous Architecture , The architecture consists of processing requests - Response and customer - Interactive event loops and worker threads . We show the asynchronous processing of playback request in the following picture .

The playback API Asynchronous architecture for
We show the adjusted code snippet below , To make effective use of asynchronous Architecture . For each playback request , The request handler event pool triggers a worker thread to set up the entire execution process . after , One of the worker threads obtains customer information from the relevant microservices , Another thread gets the device information . Once both worker threads return a response , A separate execution unit will bind the two responses together , And use it for decisionPlayData() call . In such a process , All contexts are passed as messages between independent threads . Asynchronous architecture not only helps to make effective use of available computing resources , It also reduces latency .
PlayData getPlayData(String customerId, String titleId, String deviceId) {
Zip(getCustomerInfo(customerId),
getDeviceInfo(deviceId),
(custInfo, deviceInfo) -> decidePlayData(custInfo, deviceInfo, titleId)
);
}Copy code
Solving bottlenecks
The use of microservices is accompanied by the efficient handling of fallbacks when invoking other services 、 Considerations for retry and timeout . We can use chaos Engineering (Chaos Engineering) To solve the bottleneck problem of using distributed system , Interestingly ,Chaos Engineering Is in Netflix The design of the . We can use things like Chaos Monkey Such a tool , Randomly terminate instances in production , To ensure that the service is resilient to instance failures .
We can test by using fault injection (Failure Injection Testing,FIT) The concept of chaos is introduced into the system . This can be done by I/O Introduce delays in the invocation or inject faults when invoking other services to achieve . after , We can implement the fallback strategy by returning the latest cached data from the failed service or using the fallback microservice . We can also use things like Hystrix Such a library to isolate access points between failed Services . If the error threshold is exceeded ,Hystrix Will act as a circuit breaker . We should also make sure that the retry timeout 、 Timeout and service invocation Hystrix Timeouts are synchronized .
Interesting things : stay Nora Jones(Netflix Chaos engineer ) In his speech , Discussed in detail Netflix The importance of flexibility testing and different strategies . She provides key points that engineers should keep in mind when designing microservices , To achieve flexibility , And ensure that the best design decisions are made on an ongoing basis .
Expand requirements
A common problem observed in streaming video is , Subtitles appear above the text in the video ( It's called the text overlay problem ). This problem is illustrated in the picture below . How can we extend the current solution and data model to detect this problem ?

An example of text superposition problem
We can extend our existing media document solutions ( For video subtitles ) To store video media information . then , We can run text detection and caption location algorithms in video on media document data storage , And persist the result as a separate index . after , These indexes will be queried by the text detection application in the text , To identify any overlaps , This will detect a text problem in the text .

text-on-text Detection application process of
边栏推荐
- When asked during the interview, can redis master-slave copy not answer? These 13 pictures let you understand thoroughly
- 【特征提取】基于稀疏PCA实现目标识别信息特征选择附matlab源码
- The performance of iron and steel enterprises was expected to be good in January this year. Since February, the prices of products of iron and steel enterprises have increased significantly. A mighty
- Excel中Unicode如何转换为汉字
- Porphyrin based polyimide ppbpis (ppbpi-pa, ppbpi-pepa and ppbpi-pena); Crosslinked porphyrin based polyimide (ppbpi-pa-cr, ppbpi-pepa-cr, ppbpi-pena-cr) reagent
- MySQL
- Porphyrin based polyimide (ppbpis); Synthesis of crosslinked porphyrin based polyimides (ppbpi CRS) porphyrin products supplied by Qiyue biology
- 基于sanic的服务使用celery完成动态修改定时任务
- 同花顺究竟如何开户,网上开户是否安全么?
- 高德地图使用自定义地图无效问题
猜你喜欢

少年,你可知 Kotlin 协程最初的样子?

Quickly find five channels for high-quality objects, quickly collect and avoid detours

MySQL basic usage 01
![[image enhancement] image defogging based on artificial multiple exposure fusion amef with matlab code](/img/4e/3317b2b99fc8da4d8af190f402e696.png)
[image enhancement] image defogging based on artificial multiple exposure fusion amef with matlab code
![[feature extraction] feature selection of target recognition information based on sparse PCA with Matlab source code](/img/79/053e185f96aab293fde54578c75276.png)
[feature extraction] feature selection of target recognition information based on sparse PCA with Matlab source code

Crosslinked metalloporphyrin based polyimide ppbpi-h) PPBP Mn; PBP-Fe; PPBPI-Fe-CR; Ppbpi Mn CR product - supplied by Qiyue
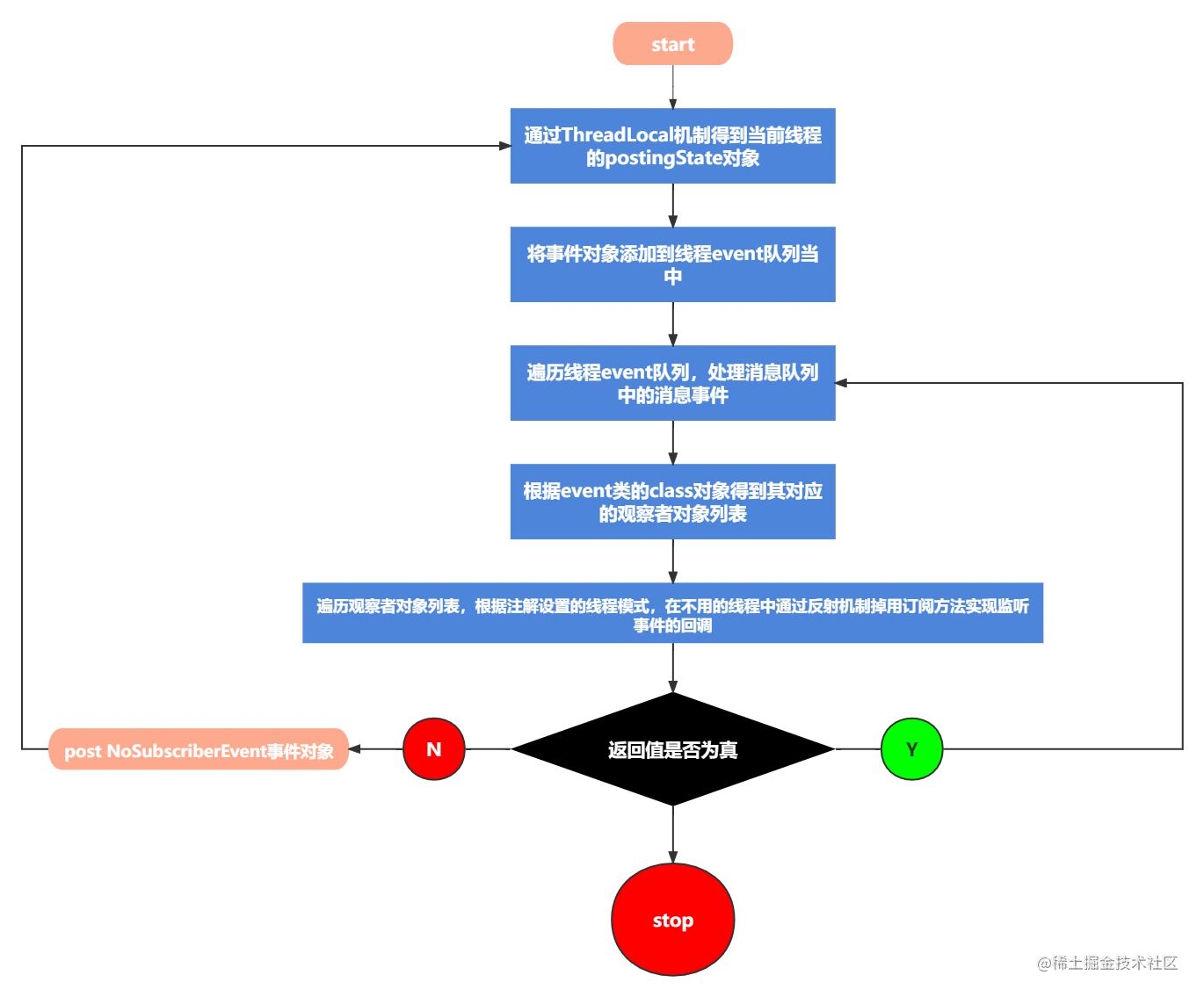
This paper analyzes the use method and implementation principle of eventbus event bus

高德地图使用自定义地图无效问题

Cocoscreator plays spine animation
![Meso tetra (4-bromophenyl) porphyrin (tbpp); 5,10,15,20-tetra (4-methoxy-3-sulfonylphenyl) porphyrin [t (4-mop) ps4] supplied by Qiyue](/img/83/ddbf296ac83f006f31cfd0bbbabe5e.jpg)
Meso tetra (4-bromophenyl) porphyrin (tbpp); 5,10,15,20-tetra (4-methoxy-3-sulfonylphenyl) porphyrin [t (4-mop) ps4] supplied by Qiyue
随机推荐
Procedure macros in rust
NumPy学习挑战第五关-创建数组
[image fusion] multimodal medical image fusion based on coupled feature learning with matlab code
Network IO, disk IO
Market development status analysis and investment risk outlook report of China's battery industry 2022-2027
ZRaQnHYDAe
php array_merge详解
When asked during the interview, can redis master-slave copy not answer? These 13 pictures let you understand thoroughly
报错问题Parameter index out of range(0 < 1) (1 > number of parameters,which is 0
The difference between insert ignore and insert into
Item2 installation configuration and environment failure solution
js模块化
C implementation adds a progress bar display effect to the specified column of the GridView table in devaxpress - code implementation method
5,10,15,20-tetraphenylporphyrin (TPP) and metal complexes fetpp/mntpp/cutpp/zntpp/nitpp/cotpp/pttpp/pdtpp/cdtpp supplied by Qiyue
Redis系列——redis启动,客户端day1-2
一文深入底层分析Redis对象结构
unity之EasyAR使用
炒股怎么选择证券公司?手机开户安全么?
Golang源码包集合
3,3 '- di (3,4-dicarboxyphenoxy) -4,4' - diphenylethynylbiphenyldianhydride (bpebpda) / porphyrin 2dcofs (H2P COF, ZNP COF and cup COF) supplied by Qiyue