当前位置:网站首页>[reading point paper] deeplobv3+ encoder decoder with Atlas separable revolution
[reading point paper] deeplobv3+ encoder decoder with Atlas separable revolution
2022-06-13 02:20:00 【Shameful child】
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Deep neural network uses spatial pyramid pool module or codec structure for semantic segmentation .
Space pyramid pool module
- Multi scale context information can be encoded by detecting incoming features through filter or pool operation at multiple rates and multiple effective fields of view
- Capture rich contextual information , By concentrating features on different resolutions
Codec structure
- Clearer target boundaries can be captured by gradually recovering spatial information
- pyramid network : High precision , But the amount of calculation is too large , So the running time is long .
- Codec network : A small amount of calculation , But the accuracy is relatively low .
DeepLabv3+
Expanded DeepLabv3, A simple and effective decoder module is added to refine the segmentation results , Especially along object boundaries .
Use DeepLabv3 As a powerful encoder module And a simple and effective decoder module .
In order to obtain context information on multiple scales ,DeepLabv3 Applied Multiple parallel at different rates atrous Convolution
The proposed model DeepLabv3 + Extend by adding a simple and effective decoder module DeepLabv3, To optimize segmentation results , Especially along object boundaries . We Further exploration Xception Model The depth separable convolution is applied to Atrous Spatial Pyramid Pooling And decoder module , This produces a faster and stronger encoder - Decoder network .
The proposed model DeepLabv3+ Contains Rich semantic information from encoder module , and Detailed object boundaries are recovered by a simple and efficient decoder module .
The encoder module allows us to pass application atrous Convolution can extract features at any resolution .

Rich semantic information is encoded into DeepLabv3 In the output of , Use atrous Convolution It is allowed to control the density of encoder features according to the budget of computing resources .
take The depth separable convolution is applied to ASPP Module and decoder module , So as to get faster 、 Stronger codec network .
atrous separable convolution
At present, there are mainly two kinds of separable convolution : Space separable convolution and Depth separates the convolution .
Spatially separable convolution has some obvious limitations , This means that it is not widely used in deep learning .
It is called spatially separable convolution , Because it mainly deals with the image and the space size of the kernel : Width and height .
Spatially separable convolution simply divides a kernel into two smaller kernels . The most common case is to 3x3 The kernel is divided into 3x1 and 1x3 kernel
> - We don't need to make one 9 Convolution of times multiplication , But do two 3 Times multiplication ( common 6 Time ) Convolution of , To achieve the same effectDepthwise Separable Convolutions
- The deep separable convolution is so named , Because it Not only the spatial dimension , And it involves the depth dimension ( The channel number )
- Depth can be divided into convolution or group convolution , This is a A powerful operation , It can reduce the calculation cost and the number of parameters , While maintaining similar performance .
- The deep separable convolution is applicable to the impossibility “ decompose ” A kernel for two smaller kernels .
- Deep separable convolution splits a kernel into two independent kernels , These kernels perform two convolutions : Convolution by depth (depthwise convolution) And point by point convolution (pointwise convolution).
- Depthwise Convolution
- Every 5x5x1 The kernel will iterate over the image 1 Channels ( Be careful :1 Channels , Not all channels ), Get every 25 Scalar product of pixel groups , So it gives 8x8x1 Images . Stacking these images together will create a 8x8x3 Image . - - Pointwise Convolution - Pointwise convolution is so named , Because it uses 1x1 Or iterate through the kernel at each point . The depth of the kernel is the number of channels the input image has . - take 1x1x3 Kernel in 8x8x3 Iterate over the image , In order to obtain 1 Zhang 8x8x1 Image . - 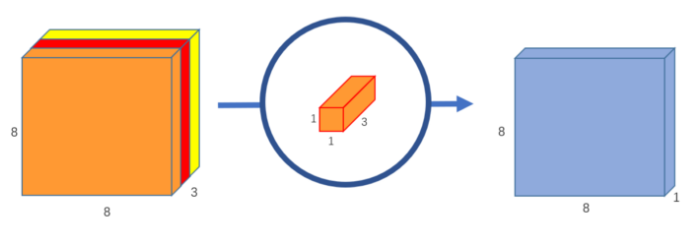- You can create 256 individual 1x1x3 kernel , Each kernel outputs 8x8x1 Images , To get the shape of 8x8x256 The final image of . - 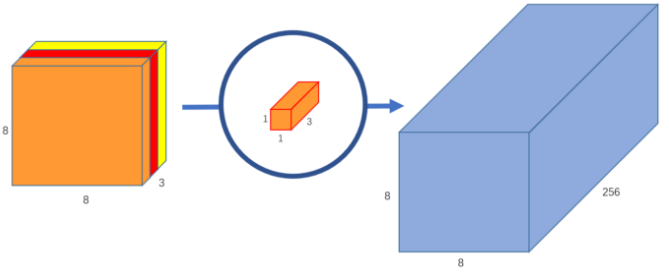If the original ordinary convolution is 12x12x3-(5x5x3x256)→8x8x256, We can explain this new convolution as 12x12x3-(5x5x1x3)->(1x1x3x256)-> 8x8x256.
https://zhuanlan.zhihu.com/p/197528715
3×3 The deep separable convolution decomposes the standard convolution into **(a) Deep convolution **( Apply a filter to each input channel ) and **(b) Pointwise convolution **( Combined with the output of cross channel depth convolution ). greatly It reduces the computational complexity .
Depth convolution performs spatial convolution for each input channel independently , Point convolution is used to combine the output of depth convolution .
The implementation process of the method in this paper
- So let's set up a Large encoding and decoding structure , among The coding structure is ASPP Instead of . The characteristic diagram of this part is connected through 1*1 After convolution with convolution kernel, the characteristic graph of a certain number of channels is obtained , after 4 Times of upsampling to get a set of characteristic graphs Features1.
- A set of low-level feature maps in the coding process ( And Features1 Same scale ) Pull it out , after 1*1 A set of characteristic graphs are obtained by adjusting the number of channels Features2. Here we use 1*1 Convolution kernel adjusts the number of channels because the number of channels is usually large when extracting low-level features (256), This leads to a large proportion of low-level features , It's not easy to train .
- take Features1 and Features2 Connect . after 3*3 Feature extraction using convolution kernel , Then go through 4 Times upsampling to get the image output with the same scale as the original image .
The goal of semantic segmentation is to Each pixel is assigned a semantic label
Encoder - Decoder network
Encoder
- This module can gradually reduce feature mapping and capture higher semantic information
- deeplabv3 As an encoder
- DeepLabv3 use atrous Convolution to extract the features of depth convolution neural network calculation with arbitrary resolution .
- DeepLabv3 Enhanced Atrous Space pyramid pool module , The module uses different rates of Atrous Convolution Detecting convolution features at multiple scales , There are also image level features
- Use primitive DeepLabv3 in logits Previous The last feature map is output as an encoder .
decoder
The decoder module can gradually recover the spatial information
- The encoder features are first characterized by 4 A multiple of times Bilinear up sampling , Then with from The corresponding low-order characteristic connection of the network backbone with the same spatial resolution .
- Apply another 1×1 The low-level function of convolution to reduce the number of channels , Because the corresponding low-level function usually contains a large number of channels, it may be more important than the rich encoder characteristics in our model and the difficulty of training .
- Apply a few 3×3 Convolution to refine features , Then a simple bilinear upsampling , The upper sampling multiple is 4.
- This paper shows how to use output stride= 16 The best compromise between speed and accuracy can be achieved .
- When the encoder module uses output stride= 8 when , Slightly improved performance , But the cost is additional computational complexity .

The encoder module passes Apply on multiple scales atrous Convolution Encode multi-scale context information , and The simple and effective decoder module refines the segmentation result along the target boundary .
Atrous Convolution
- It's a powerful tool , It allows us to explicitly control the resolution of the features calculated by the depth convolution neural network , And adjust the field of view of the filter , To capture multiscale information , Generalize the standard convolution operation .
Xception
take Xception The model is used to segment tasks , The depth separable convolution is applied to ASPP Module and decoder module , This produces a faster and stronger encoder - Decoder network .
MSRA The team modified Xception Model ( be called Aligned Xception),
In this paper MSRA The team modified Xception The model is being modified
- The portal stream network structure has not been modified , For fast computing and memory efficiency
- be-all Max The pool operation is replaced by the depth divisible convolution with span , This enables us to apply atrous The feature map with arbitrary resolution can be extracted by dividing convolution ( Another option is to atrous The algorithm is extended to Max Pool operation ).
- Additional batch normalization and ReLU Activate at each 3×3 Add... After deep convolution , Be similar to MobileNet Design

- Added layers ( And MSRA The changes are the same , except Entry flow Changes )
- be-all max pooling All operations are carried stride Is replaced by the depth separable convolution
- Every 3×3 Add additional batch normalization sum after deep convolution ReLU, Be similar to MobileNet.
The experiment of this paper uses ImageNet-1k In the process of the training ResNet-101, Plus improved aligned Xception adopt atrous Convolution to extract dense feature graph . Our implementation is based on TensorFlow Above .
The model proposed in this paper is end-to-end training , There is no need to pre train each component . The proposed decoder module contains batch normalization parameters .
Simple bilinear upsampling can be seen as a naive decoder design
In the decoder module , This paper considers three different design options
Use 1×1 Convolution is used to reduce the channel of low-order feature mapping of encoder module
- Experiments show that : Reduce the channel of low-level feature mapping of encoder module to 48 or 32, Performance will be better . So we use [1×1,48] Channel reduction .

Use 3×3 Convolution for clearer segmentation results
- Experiments show that : take Conv2 feature map( Before you stride ) And DeepLabv3 feature map After connection , Use two 3×3 Convolution sum 256 Filters are more efficient than simply using one or three convolutions .

Which encoder lower order feature should be used .
- A very simple but effective decoder module is used : Through two [3×3,256] Operation to refine DeepLabv3 Characteristic diagram and channel reduction Conv2 Connection of characteristic diagram .
ResNet-101 as Network Backbone VS Xception as Network Backbone
Respectively embedded Resnet101 And Xception A comparative experiment was carried out , The experimental results show that Xception The result is better .
- Xceoption There are the following changes :
- The number of layers has deepened
- All maximum pooling has been replaced with 3x3 with stride 2 Of separable convolution
- At every 3x3 depthwise separable convolution Added after BN and ReLU
- Xceoption There are the following changes :
Improvement along Object Boundaries
PASCAL VOC 2012 Test set results and best performing models
The proposed model “DeepLabv3+” Using encoders - Decoder structure , among DeepLabv3 Used to encode rich context information , A simple and effective decoder module is used to recover the object boundary .
The anomaly model and atrous Separable convolution , Make the model faster and stronger .
https://arxiv.org/pdf/1802.02611.pdf



eepLabv3+” Using encoders - Decoder structure , among DeepLabv3 Used to encode rich context information , A simple and effective decoder module is used to recover the object boundary .
The anomaly model and atrous Separable convolution , Make the model faster and stronger .
https://arxiv.org/pdf/1802.02611.pdf
边栏推荐
- [unity] problems encountered in packaging webgl project and their solutions
- Looking at Qianxin's "wild prospect" of network security from the 2021 annual performance report
- [keras] train py
- Easydl related documents and codes
- Detailed explanation of C language conditional compilation
- 华为设备配置私网IP路由FRR
- Share three stories about CMDB
- [keras] generator for 3D u-net source code analysis py
- SWD debugging mode of stm32
- Basic exercises of test questions letter graphics ※
猜你喜欢
Armv8-m (Cortex-M) TrustZone summary and introduction

Basic principle of bilateral filtering

regular expression

Application circuit and understanding of BAT54C as power supply protection

华为设备配置私网IP路由FRR

Paper reading - joint beat and downbeat tracking with recurrent neural networks

传感器:SHT30温湿度传感器检测环境温湿度实验(底部附代码)

Parameter measurement method of brushless motor

In addition to the full screen without holes under the screen, the Red Devils 7 series also has these black technologies

Hstack, vstack and dstack in numpy
随机推荐
【 unity】 Problems Encountered in Packaging webgl Project and their resolution Records
Share three stories about CMDB
[programming idea] communication interface of data transmission and decoupling design of communication protocol
Easydl related documents and codes
【LeetCode-SQL】1532. Last three orders
Basic exercises of test questions Fibonacci series
The fastest empty string comparison method C code
GMM Gaussian mixture model
C language complex type description
16 embedded C language interview questions (Classic)
Huawei equipment is configured with CE dual attribution
[51nod.3210] binary Statistics (bit operation)
Area of basic exercise circle ※
[unity] problems encountered in packaging webgl project and their solutions
Leetcode daily question - 890 Find and replace mode
[pytorch]fixmatch code explanation - data loading
Solution of depth learning for 3D anisotropic images
Mac下搭建MySQL环境
记录:如何解决MultipartFile类的transferTo()上传图片报“系统找不到指定的路径“问题【亲测有效】
1000 fans ~