当前位置:网站首页>P1223 排队接水/1319:【例6.1】排队接水
P1223 排队接水/1319:【例6.1】排队接水
2022-07-07 08:14:00 【暴揍键盘的程序猿】
P1223 排队接水/1319:【例6.1】排队接水
# 排队接水
## 题目描述
有 $n$ 个人在一个水龙头前排队接水,假如每个人接水的时间为 $T_i$,请编程找出这 $n$ 个人排队的一种顺序,使得 $n$ 个人的平均等待时间最小。
## 输入格式
第一行为一个整数 $n$。
第二行 $n$ 个整数,第 $i$ 个整数 $T_i$ 表示第 $i$ 个人的等待时间 $T_i$。
## 输出格式
输出文件有两行,第一行为一种平均时间最短的排队顺序;第二行为这种排列方案下的平均等待时间(输出结果精确到小数点后两位)。
## 样例 #1
### 样例输入 #1
```
10
56 12 1 99 1000 234 33 55 99 812
```
### 样例输出 #1
```
3 2 7 8 1 4 9 6 10 5
291.90
```
## 提示
$n \leq 1000,t_i \leq 10^6$,不保证 $t_i$ 不重复。
当 $t_i$ 重复时,按照输入顺序即可(sort 是可以的)
【俩81分代码】
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e3;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
void sort()
{
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
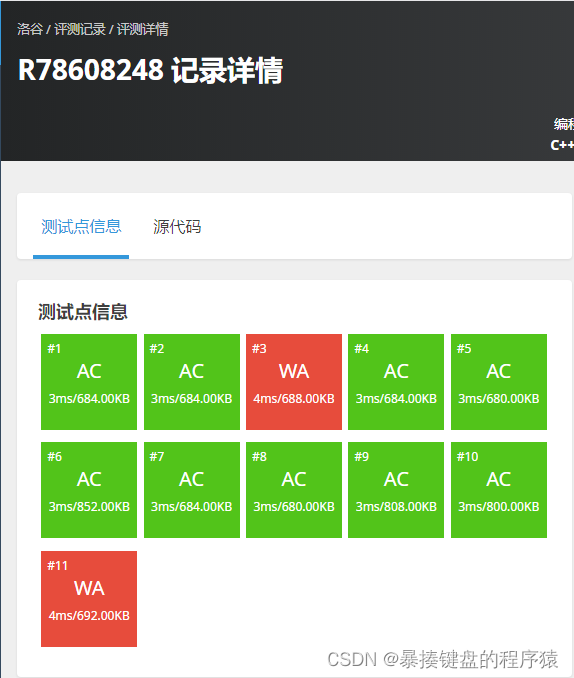
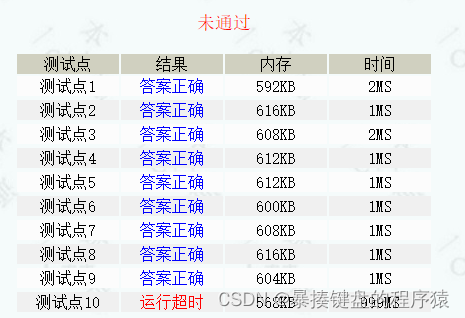
}数组开小了。
#include<stdio.h>
#include<iostream>
using namespace std;
#define int long long
const int N=1e3;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
void sort()
{
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
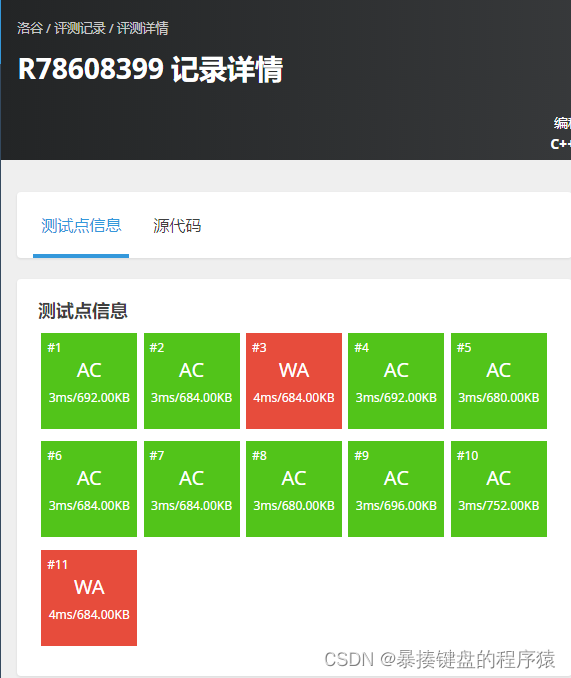
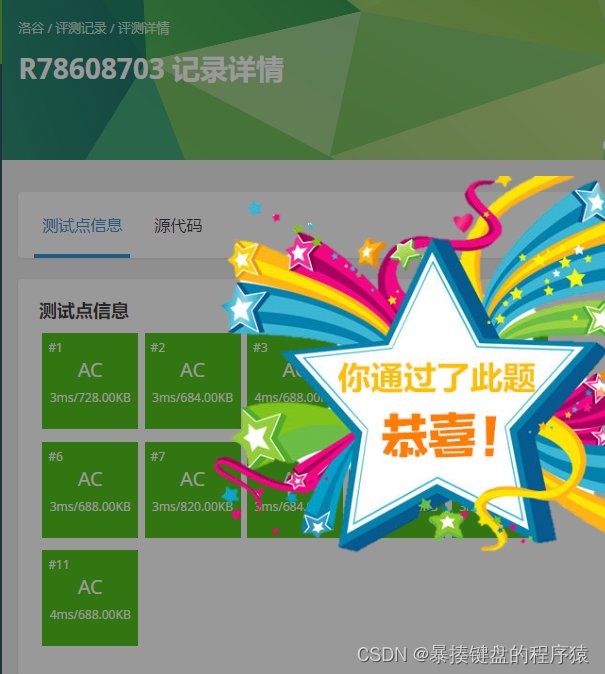
【AC代码】
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
void sort()
{
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
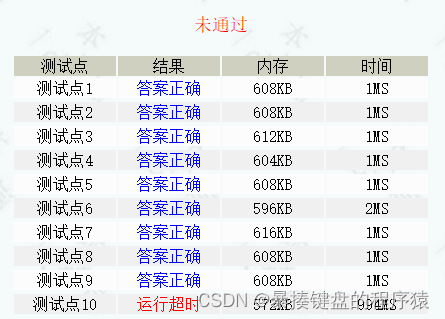
【一堆运行超时代码】
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
void sort()
{
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
void sort()
{
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
inline void sort()
{
for(register int i=1;i<=n;i++)
for(register int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(register int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(register int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(register int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
inline void sort()
{
for(register int i=1;i<=n;i++)
for(register int j=n;j>0;j--)
if(t[j]<t[j-1])swap(t[j],t[j-1]),swap(a[j],a[j-1]);
}
signed main()
{
n=fread();
for(register int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(register int i=1;i<=n;i++)cnt+=t[i]*(n-(i-1)),sum+=t[i];
for(register int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
inline void sort()
{
for(register int i=1;i<=n;i++)
for(register int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(register int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(register int i=1;i<=n;i++)
{
cnt+=t[i]*(n-i+1),sum+=t[i];
printf("%d ",a[i]);
}
printf("\n%.2lf",(cnt-sum)/n);
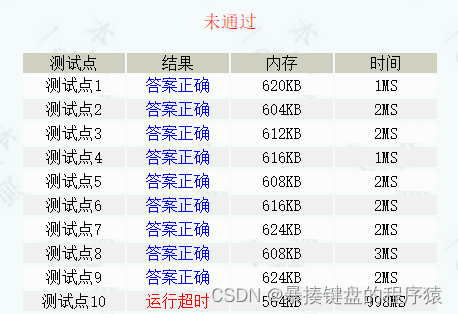
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#define ing long long
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
inline void sort()
{
for(register int i=1;i<=n;i++)
for(register int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
n=fread();
for(register int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(register int i=1;i<=n;i++)cnt+=t[i]*(n-i+1),sum+=t[i];
for(register int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
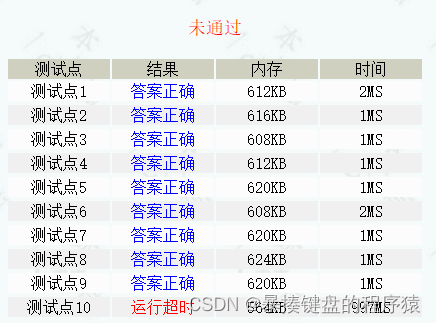
return 0;
}
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
#pragma GCC optimize(2)
#pragma GCC optimize(3)
#pragma GCC optimize("Ofast")
#pragma GCC optimize("inline")
#pragma GCC optimize("-fgcse")
#pragma GCC optimize("-fgcse-lm")
#pragma GCC optimize("-fipa-sra")
#pragma GCC optimize("-ftree-pre")
#pragma GCC optimize("-ftree-vrp")
#pragma GCC optimize("-fpeephole2")
#pragma GCC optimize("-ffast-math")
#pragma GCC optimize("-fsched-spec")
#pragma GCC optimize("unroll-loops")
#pragma GCC optimize("-falign-jumps")
#pragma GCC optimize("-falign-loops")
#pragma GCC optimize("-falign-labels")
#pragma GCC optimize("-fdevirtualize")
#pragma GCC optimize("-fcaller-saves")
#pragma GCC optimize("-fcrossjumping")
#pragma GCC optimize("-fthread-jumps")
#pragma GCC optimize("-funroll-loops")
#pragma GCC optimize("-fwhole-program")
#pragma GCC optimize("-freorder-blocks")
#pragma GCC optimize("-fschedule-insns")
#pragma GCC optimize("inline-functions")
#pragma GCC optimize("-ftree-tail-merge")
#pragma GCC optimize("-fschedule-insns2")
#pragma GCC optimize("-fstrict-aliasing")
#pragma GCC optimize("-fstrict-overflow")
#pragma GCC optimize("-falign-functions")
#pragma GCC optimize("-fcse-skip-blocks")
#pragma GCC optimize("-fcse-follow-jumps")
#pragma GCC optimize("-fsched-interblock")
#pragma GCC optimize("-fpartial-inlining")
#pragma GCC optimize("no-stack-protector")
#pragma GCC optimize("-freorder-functions")
#pragma GCC optimize("-findirect-inlining")
#pragma GCC optimize("-fhoist-adjacent-loads")
#pragma GCC optimize("-frerun-cse-after-loop")
#pragma GCC optimize("inline-small-functions")
#pragma GCC optimize("-finline-small-functions")
#pragma GCC optimize("-ftree-switch-conversion")
#pragma GCC optimize("-foptimize-sibling-calls")
#pragma GCC optimize("-fexpensive-optimizations")
#pragma GCC optimize("-funsafe-loop-optimizations")
#pragma GCC optimize("inline-functions-called-once")
#pragma GCC optimize("-fdelete-null-pointer-checks")
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,a[N],t[N];
double cnt,sum;
inline void sort()
{
for(register int i=1;i<=n;i++)
for(register int j=i+1;j<=n;j++)
if(t[i]>t[j])swap(t[i],t[j]),swap(a[i],a[j]);
}
signed main()
{
std::ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
n=fread();
for(register int i=1;i<=n;i++)t[i]=fread(),a[i]=i;
sort();
for(register int i=1;i<=n;i++)cnt+=t[i]*(n-i+1),sum+=t[i];
for(register int i=1;i<=n;i++)printf("%d ",a[i]);
printf("\n%.2lf",(cnt-sum)/n);
return 0;
}
#include<algorithm>
#include<stdio.h>
#include<iostream>
using namespace std;
#define int long long
const int N=1e4;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n,sum,m;
double ans;
struct node
{
int x,y;
}t[N];
bool cmp(node n,node m)
{
return n.y<m.y;
}
signed main()
{
n=fread(),m=n-1;
for(int i=1;i<=n;i++)t[i].y=fread(),t[i].x=i;
sort(t+1,t+1+n,cmp);
for(int i=1;i<=n;i++)printf("%lld ",t[i].x);
for(int i=1;i<n;i++)sum+=t[i].y*m,m--;
ans=sum*1.0/n;
printf("\n%.2lf",ans);
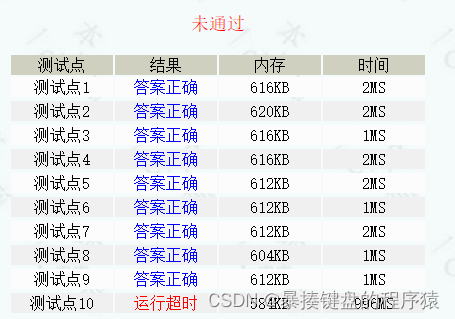
return 0;
}
【AC代码】
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
struct water
{
int time,id;
}a[1010];
bool cmp(struct water a,struct water b) {return a.time<b.time;}
int main()
{
int n;
double alltime=0;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i].time;
a[i].id=i;
}
sort(a+1,a+1+n,cmp);
for(int i=1;i<=n;i++)
{
cout<<a[i].id<<" ";
alltime=alltime+a[i-1].time*(n-i+1);
}
printf("\n%.2f",alltime/n);
return 0;
}抄的。
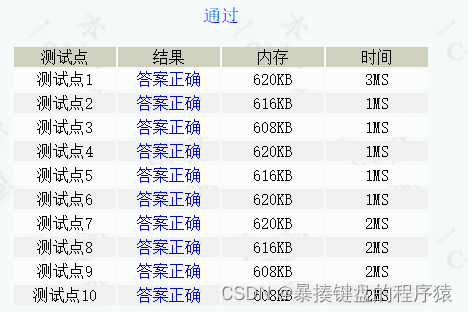
【听取T声亿片】
#include<algorithm>
#include<stdio.h>
#include<iostream>
using namespace std;
const int N=1e4;
inline int fread()
{
char ch=getchar();
int n=0,m=1;
while(ch<'0' or ch>'9')
{
if(ch=='-')m=-1;
ch=getchar();
}
while(ch>='0' and ch<='9')n=(n<<3)+(n<<1)+ch-48,ch=getchar();
return n*m;
}
int n;
double ans;
struct node
{
int x,y;
}t[N];
bool cmp(node n,node m)
{
return n.y<m.y;
}
signed main()
{
n=fread();
for(int i=1;i<=n;i++)t[i].y=fread(),t[i].x=i;
sort(t+1,t+1+n,cmp);
for(int i=1;i<=n;i++)
{
printf("%d ",t[i].x);
ans+=t[i-1].y*(n-i+1);
}
printf("\n%.2lf",ans/n);
return 0;
}妈的这题有毒老子不做了。
边栏推荐
- 【acwing】786. 第k个数
- Bit operation ==c language 2
- Review of the losers in the postgraduate entrance examination
- Wallys/IPQ6010 (IPQ6018 FAMILY) EMBEDDED BOARD WITH ON-BOARD WIFI DUAL BAND DUAL CONCURRENT
- Introduction to energy Router: Architecture and functions for energy Internet
- C#记录日志方法
- Download Text, pictures and ab packages used by unitywebrequest Foundation
- A small problem of bit field and symbol expansion
- @Transcation的配置,使用,原理注意事项:
- HAL库配置通用定时器TIM触发ADC采样,然后DMA搬运到内存空间。
猜你喜欢

一文讲解单片机、ARM、MUC、DSP、FPGA、嵌入式错综复杂的关系
Leetcode exercise - 113 Path sum II
反卷积通俗详细解析与nn.ConvTranspose2d重要参数解释
Use the fetch statement to obtain the repetition of the last row of cursor data
0x0fa23729 (vcruntime140d.dll) (in classes and objects - encapsulation.Exe) exception thrown (resolved)
Vs code specifies the extension installation location

Remote meter reading, switching on and off operation command
![[sword finger offer] 42 Stack push in and pop-up sequence](/img/f4/eb69981163683c5b36f17992a87b3e.png)
[sword finger offer] 42 Stack push in and pop-up sequence

Wallys/IPQ6010 (IPQ6018 FAMILY) EMBEDDED BOARD WITH ON-BOARD WIFI DUAL BAND DUAL CONCURRENT
PDF文档签名指南
随机推荐
Postman interface test III
Video based full link Intelligent Cloud? This article explains in detail what Alibaba cloud video cloud "intelligent media production" is
【acwing】789. 数的范围(二分基础)
Study summary of postgraduate entrance examination in October
Postman interface test IV
ES6中的函数进阶学习
A wave of open source notebooks is coming
AHB bus in stm32_ Apb2 bus_ Apb1 bus what are these
Pdf document signature Guide
Parameter sniffing (2/2)
【剑指Offer】42. 栈的压入、弹出序列
根据设备信息进行页面跳转至移动端页面或者PC端页面
Some test points about coupon test
Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
PDF文档签名指南
单片机(MCU)最强科普(万字总结,值得收藏)
Programming features of ISP, IAP, ICP, JTAG and SWD
Methods of adding centerlines and centerlines in SolidWorks drawings
Apprentissage avancé des fonctions en es6
Mongodb creates an implicit database as an exercise