当前位置:网站首页>Classic literature reading -- deformable Detr
Classic literature reading -- deformable Detr
2022-07-02 06:05:00 【Hermit_ Rabbit】
0. brief introduction
I haven't written a blog about deep learning for a long time . But I think DETR It's worth my time to introduce in detail .Deformable DETR As the most famous DETR One of the variants , Of course, the amount of code is also relatively large . Here we will analyze in detail from the paper to the code Deformable DETR The essence of . In the past two years, it has been from Attention To NAS Until then Transformer, The visual inspection industry is Transformer To a new height . and DETR As Transformer Methods that have attracted much attention in the past two years , It also attracts many people to change . One of the more famous is Deformable DETR.DETR It is proposed to remove artificial components in the target detection method , It can also maintain excellent performance . But because of Transformer The attention module can only process the image feature map in a limited way , Its convergence speed is relatively slow , The resolution of feature space is limited . To alleviate these problems , The author puts forward Deformable DETR, Its attention module will only focus on a small number of key sampling points around the target frame .Deformable DETR Be able to achieve more than DETR Better performance ( Especially on small objects ). stay COCO A large number of experiments on the benchmark have proved the effectiveness of this method .
1. Article contribution
At present, many artificial components are used in target detection , such as anchor Generate 、 Rule based training target allocation mechanism 、NMS After treatment, etc . and Carion And so forth DETR Come and go to remove artificial components , It is the first time to build a complete end-to-end target detector . Use a simple structure , take CNN and Transformer Encoder - Combined with decoder . however DETR There are also a few problems :(1) Need longer training time to converge . for example , stay COCO On the benchmark ,DETR need 500 individual epochs To converge , than Faster R-CNN slow 10-20 times .(2) DETR The performance of small target detection is relatively poor . Current target detectors usually use multiscale features , Small targets can be detected from high-resolution feature maps . And yes DETR Come on , High resolution feature map means high complexity . These problems can be summarized as Transformer Lack of components for processing image feature maps .Transformer Calculation of attention weight of encoder , Relative to the number of pixels, it is squared . therefore , To process high-resolution feature map , The amount of calculation is very high , Memory complexity is also very high . and Deformable DETR, Through the following methods DETR The rate of convergence , And reduce high complexity problems .
- It will deformable The best sparse space sampling method of convolution and Transformer The ability to model relationships . The author used ( Multiscale )deformable Attention module replacement Transformer Attention module , To process the feature map .
- Deformable DETR Opens the opportunity to explore end-to-end target detectors , Because it converges quickly , Memory consumption and computation are low .

2. Transformer
Talking about Deformable DETR Before , We need to know Transformer and DETR. In this section, we mainly pass self-attention To introduce Transformer The most important thing in Q、K、V Three parameters , Corresponding to the query vector (Query)、 Bond vector (Key)、 Value vector (Value).
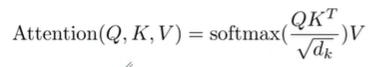
X 1 X_1 X1 And W Q W^Q WQ Multiply the weight matrix to get q 1 q_1 q1, It is related to this word Query vector . Finally, a query vector is created for each word of the input sequence q 1 q_1 q1、 A key vector k 1 k_1 k1 And a value vector v 1 v_1 v1.
The specific steps are: :
Generate three vectors QKV: For each input X i X_i Xi, adopt Word embedding is multiplied by three weight matrices to create three vectors : A query vector 、 A bond vector and a value vector .
Calculate the score : Enter... For each X i X_i Xi Calculation Self attention vector , Use other inputs X X X For the current X i X_i Xi Scoring , These scores determine the encoding X i X_i Xi How much attention is paid to the other parts of input .
Stable gradient : Divide the score by 8( The default value is ),8 Is the dimension of the bond vector used in this paper 64 The square root of , This will make the gradient more stable , Other values can also be used .
normalization : adopt softmax Deliver results , Its function is to make all X X X Normalization of scores , The scores are all positive and the sum is 1. This softmax The score determines the current position of each word pair (“Thinking”) The contribution of . obviously , Words already in this position will get the highest softmax fraction , But sometimes it helps to focus on another word that is related to the current word .
Multiply each value vector by softmax fraction : Prepare for summing them later , To focus on semantic relevance , And weaken its irrelevance ( Multiply by a very small decimal ).
Sum the weighted vectors : meaning : Coding a X i X_i Xi when , Put all the others X X X It means ( Value vector ) Weighted sum , Its weight is through X i X_i Xi It means ( Bond vector ) And encoded X i X_i Xi Express ( Query vector ) Dot product and pass softmax obtain . That is, the output of the self attention layer at this position . Then I get the output from the attention layer at this position ( In our example, for the first word ).
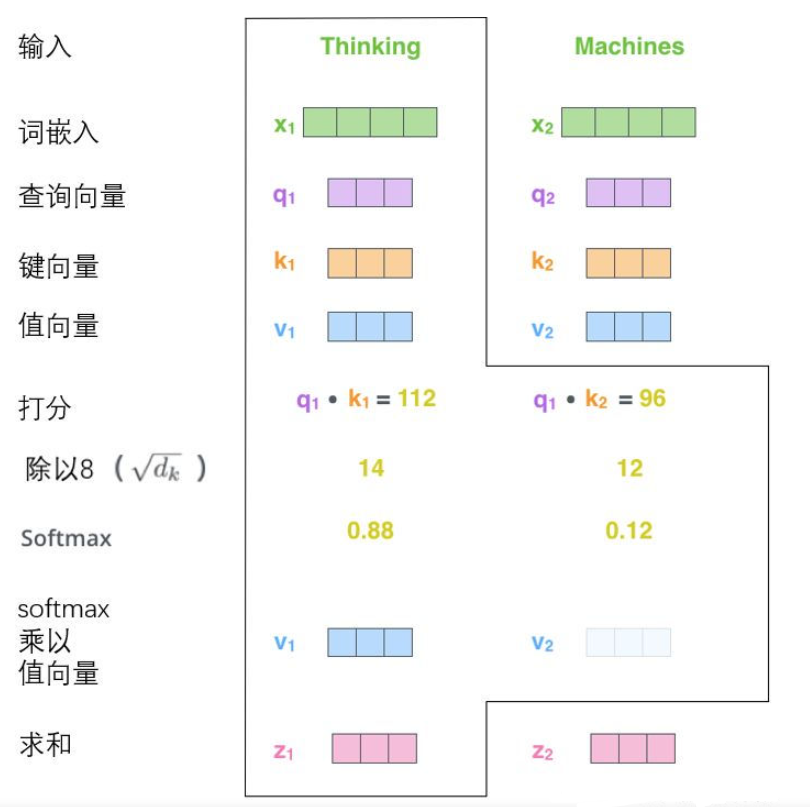
2.1 Introduce the tensor into the picture
We've seen the main parts of the model , Next, let's look at various vectors or tensors ( Translation notes : The concept of vector tensor is a generalization of the concept of vector tensor , It can be simply understood that a vector is a first-order tensor 、 A matrix is a second-order tensor .) How in different parts of the model , Convert input into output .
Like most NLP The application is the same , We first convert each input word into a word vector through the word embedding algorithm . Each word is embedded as 512 Dimension vector , We use these simple boxes to represent these vectors .
As already mentioned above , An encoder receives a list of vectors as input , Then, the vectors in the vector list are transferred to the self attention layer for processing , Then it is transferred to the feedforward neural network layer , Pass the output result to the next encoder .
Each word in the input sequence goes through a self coding process . then , They each pass forward propagation neural network —— Exactly the same network , And each vector passes through it separately .
2.2 What is a query vector 、 Key vector and value vector ?
They are abstract concepts that help to calculate and understand the mechanism of attention . Please continue to read the following , You will know what role each vector plays in the computational attention mechanism .
The second step in calculating self attention is to calculate the score . Suppose we are for the first word in this example “Thinking” Calculate the self attention vector , We need to take each word pair in the input sentence “Thinking” Scoring . These scores determine the encoding of words “Thinking” Pay more attention to the rest of the sentence .
These scores are based on the words ( All the words in the sentence ) The bond vector of and “Thinking” Of the query vector phase dot product to calculate . So if we are dealing with the self attention of the word at the top , The first score is q1 and k1 The dot product , The second score is q1 and k2 The dot product .
Last , Because we're dealing with matrices , We can take steps 2 To step 6 Merge into a formula to calculate the output from the attention layer .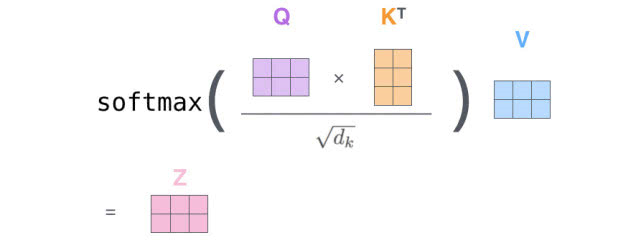
3. Multi-head Transformer
This section focuses on Transformer Of Multi-head attention . By adding a method called “ long position ” attention (“multi-headed” attention) The mechanism of , This paper further improves the self attention layer , The performance of attention layer is improved in two aspects :
Transformer in Self-Attention as well as Multi-Head Attention Detailed explanation

1. It extends the model Focus on different positions The ability of . In the example above , Although every code is z 1 z_1 z1 It is more or less reflected in , But it may Dominated by the actual word itself . If we translate a sentence , such as “The animal didn’t cross the street because it was too tired”, We'll want to know “it” Which word does it refer to , At this time, the model “ long position ” Attention mechanism will work .
2. It gives the attention level Multiple “ Represents a subspace ”(representation subspaces). Next we'll see , about “ long position ” Attention mechanism , We have Multiple queries / key / Value weight matrix set (Transformer Use eight attention heads , So for each encoder / The decoder has eight matrix sets ). Each of these sets is randomly initialized , After training , Each set is used to embed input words into ( Or from a lower encoder / Decoder vector ) Project into different representation subspaces .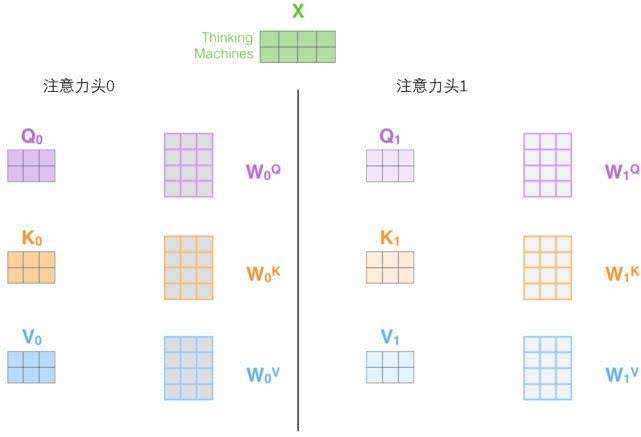
stay “ long position ” Under the attention mechanism , We keep separate queries for each header / key / Value weight matrix , So different queries are generated / key / Value matrix . Same as before , We take X multiply W Q 、 W K 、 W V W^Q、W^K、W^V WQ、WK、WV Matrix to generate queries / key / Value matrix . If we do the same self attention calculation as above , Only eight different weight matrix operations are needed , We'll get eight different Z matrix .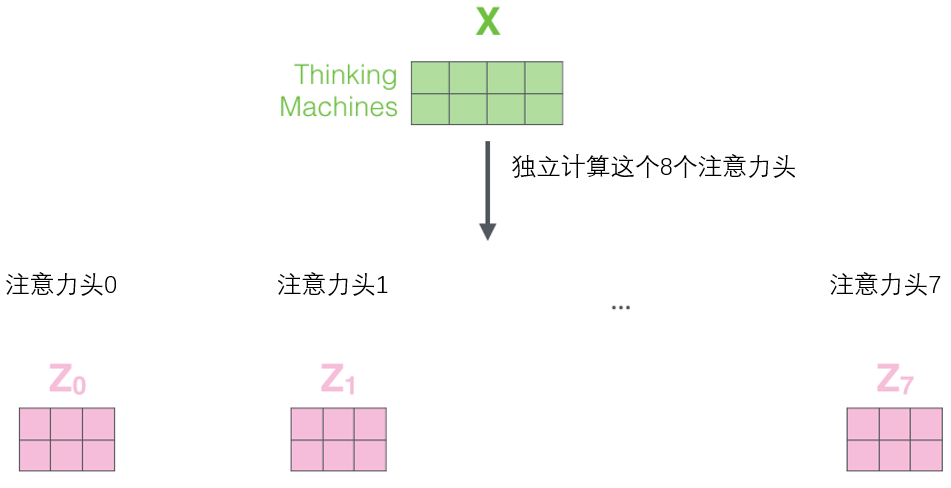
however , The feedforward layer does not need 8 Matrix , It only needs a matrix ( It consists of the representation vector of each word ). So we need to compress these eight matrices into one matrix , These matrices can be directly spliced together , Then use an additional weight matrix W O W^O WO Multiply them .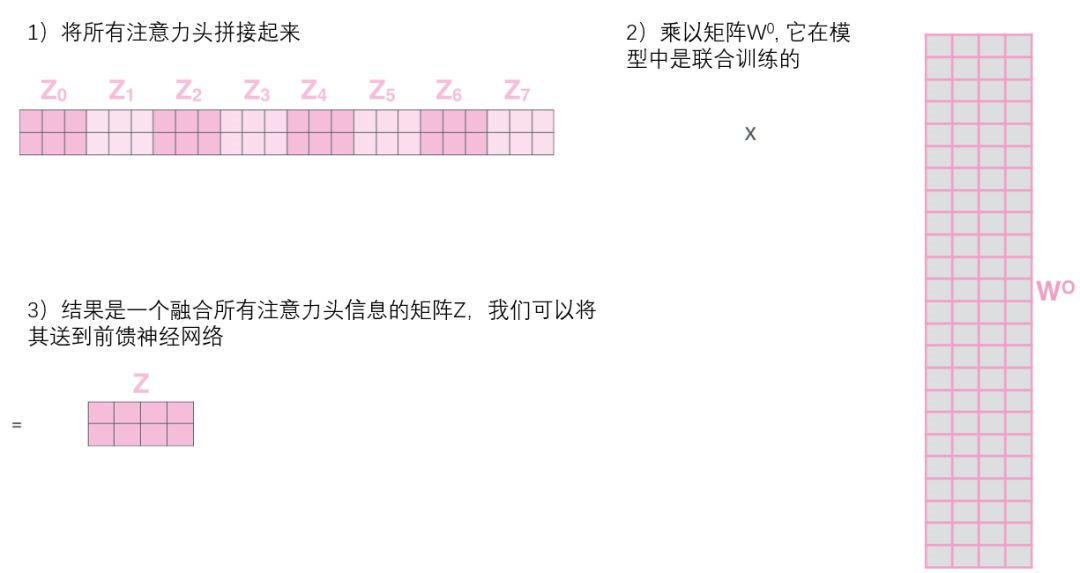
This is almost all the attention of bulls . There are really a lot of matrices , We try to put them in one picture , So you can see at a glance . This also shows that we can get the influence of the associated part on the position after multi head input .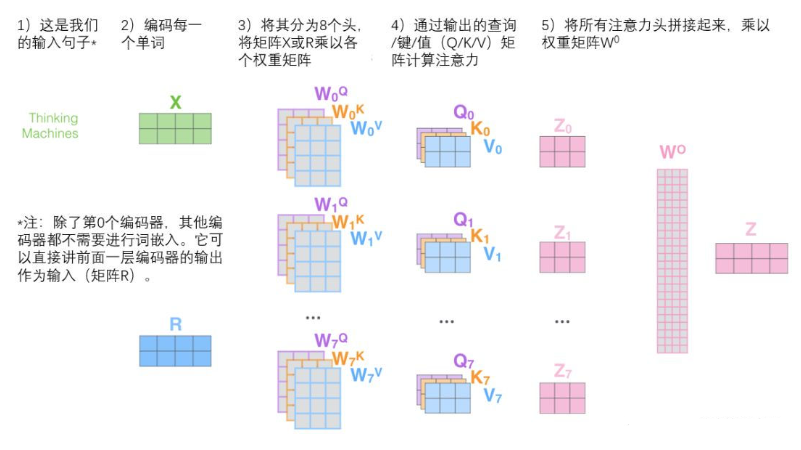
3.1 The sequence is represented by position coding
up to now , Our description of the model lacks a way to understand the order of input words .
To solve this problem ,Transformer A vector is added for each input word embedding . These vectors follow the specific patterns learned by the model , This helps determine the position of each word , Or the distance between different words in the sequence . The intuition here is , Add position vectors to the word embedding so that they are used in the next operation , The distance between words that can better express .( This is in Vision Transfomer It's also very important )

In order for the model to understand the order of words , We added a position coding vector , The values of these vectors follow a specific pattern . If we assume that the dimension of word embedding is 4, The actual location code is as follows :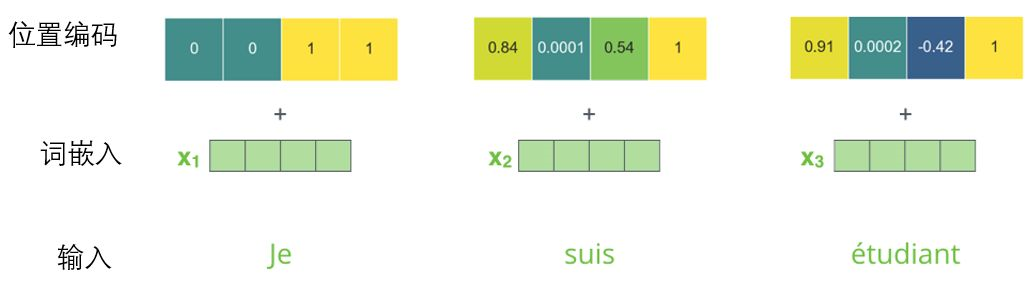
In the following illustration , Each line corresponds to the position code of a word vector , So the first line corresponds to the first word of the input sequence . Each row contains 512 It's worth , Each value is between 1 and -1 Between . We have color coded them , So the pattern is visible .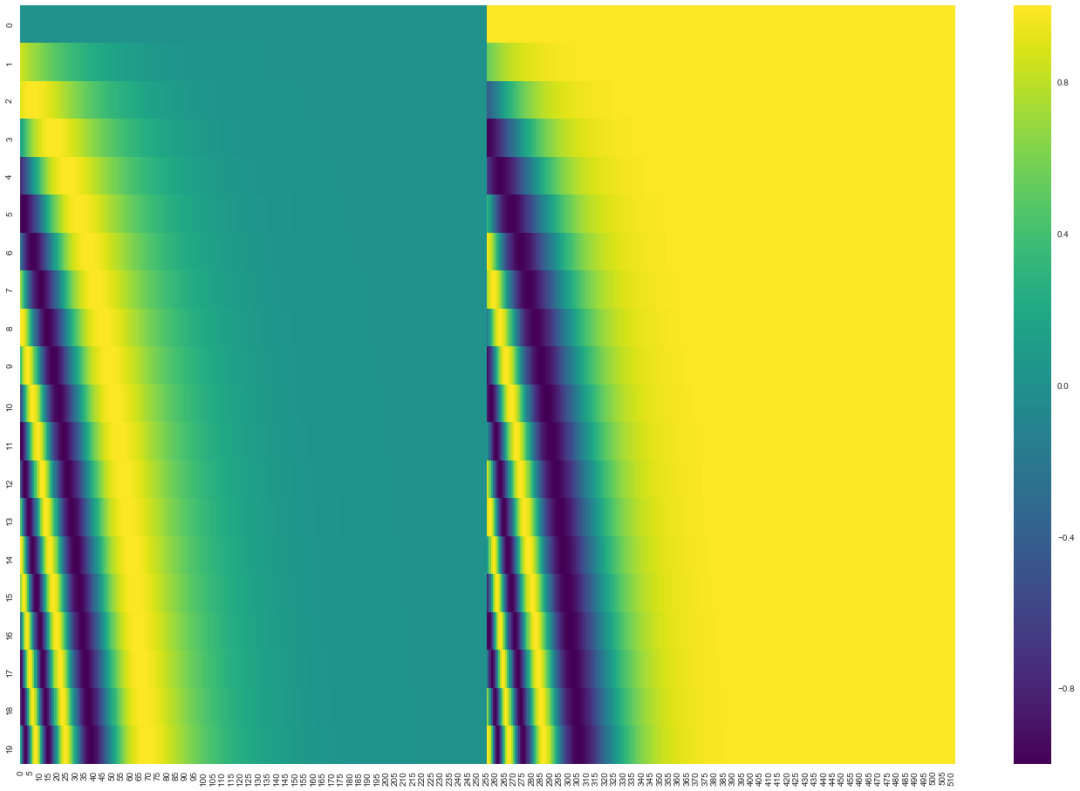
How to integrate location coding and word embedding , I've set it up here 20 word ( That's ok ) Location coding example of , The word embedding size is 512( Column ). You can see it split in two from the middle . This is because the value of the left half is determined by a function ( Use sine ) Generate , And the right half is made up of another function ( Use cosine ) Generate . Then put them together to get each position coding vector .
The original paper describes the formula of location coding ( The first 3.5 section ). You can get_timing_signal_1d() Function to see the code that generates the location code . This is not the only possible location coding method . However , Its advantages are It can be extended to unknown sequence length ( for example , When our trained model needs to translate sentences that are much longer than those in the training set , Or when more targets are detected ).
4. DETR
DETR Built on Transformer Encoder - Above the decoder , Combined with Hungarian losses , The loss is matched by two points for each ground-truth Borders assign unique prediction boxes . Li Mu's B Station account is also right DETR Have studied and talked about in detail .
DETR Intensive reading 【 Intensive reading 】
DEtection TRansformer, It greatly simplifies the framework of target detection , More intuitive . It regards the target detection task as an image to a set (image-to-set) The problem of , That is, given an image , The prediction result of the model is an unordered set containing all targets .
… Please refer to Ancient Moon House
边栏推荐
- php内的addChild()、addAttribute()函数
- Regular expression summary
- uni-app开发中遇到的问题(持续更新)
- 网络相关知识(硬件工程师)
- Use some common functions of hbuilderx
- 经典文献阅读之--Deformable DETR
- 借力 Google Cloud 基础设施和着陆区,构建企业级云原生卓越运营能力
- [C language] simple implementation of mine sweeping game
- Deep learning classification network -- vggnet
- memcached安装
猜你喜欢

如何使用MITMPROXy
File contains vulnerability (I)
Fundamentals of software testing

Shenji Bailian 3.54-dichotomy of dyeing judgment
TI毫米波雷达学习(一)

官方零基础入门 Jetpack Compose 的中文课程来啦!

Vite打包后的dist不能直接在浏览器打开吗

Compte à rebours de 3 jours pour l'inscription à l'accélérateur de démarrage Google Sea, Guide de démarrage collecté à l'avance!
在uni-app中引入uView

uni-app开发中遇到的问题(持续更新)
随机推荐
外部中断无法进入,删代码再还原就好......记录这个想不到的bug
Redis Key-Value数据库 【高级】
JS determines whether the mobile terminal or the PC terminal
I/o impressions from readers | prize collection winners list
Generics and generic constraints of typescript
Unity shader learning notes (3) URP rendering pipeline shaded PBR shader template (ASE optimized version)
c语言中的几个关键字
STC8H8K系列汇编和C51实战——数码管显示ADC、按键串口回复按键号与ADC数值
File contains vulnerability (I)
492.构造矩形
Can't the dist packaged by vite be opened directly in the browser
How vite is compatible with lower version browsers
DRM display framework as I understand it
STC8H8K系列汇编和C51实战——串口发送菜单界面选择不同功能
经典文献阅读之--Deformable DETR
Error creating bean with name 'instanceoperatorclientimpl' defined in URL when Nacos starts
php继承(extends)
Nacos 启动报错 Error creating bean with name ‘instanceOperatorClientImpl‘ defined in URL
Comment utiliser mitmproxy
在uni-app中引入uView