当前位置:网站首页>Lifeifei's team applied vit to the robot, increased the maximum speed of planning reasoning by 512 times, and also cued hekaiming's Mae
Lifeifei's team applied vit to the robot, increased the maximum speed of planning reasoning by 512 times, and also cued hekaiming's Mae
2022-06-26 16:04:00 【QbitAl】
Yang Jing From the Aofei temple
qubits | official account QbitAI
Human predictive power +ViT, What kind of chemical reaction will occur ?
It will make the robot's action planning ability fast and accurate .

This is the latest research of lifeifei's team ——MaskViT, adopt MVM, Mask visual modeling Yes Transformer pretraining , Thus the video prediction model is established .

Results show ,MaskViT Not only can it generate 256*256 video , It can also increase the reasoning speed of robot action planning to the highest 512 times .

Let's see what kind of research this is ?
Find inspiration from human beings
Research in the field of neuroscience shows that , Human cognition 、 Perception is supported by a predictive mechanism .
This predictive model of the world , It can be used to simulate 、 Evaluate and select different possible actions .
For humans , This process is fast and accurate .
If you can give robots a similar ability to predict . Then they can quickly plan in a complex dynamic environment 、 Perform various tasks .
such as , Predictive control through visual models , Maybe it's just a way , But it also puts forward higher requirements for calculating power and accuracy .
therefore , Lifeifei's team thought of many recent developments ViT framework , And hekaiming MAE Based on MVM,Masked Visual Modeling This self supervised pre training token .
But the details need to be operated , There are still many technical challenges .
One side , The complexity of the global attention mechanism is proportional to the square of the input sequence length , The cost of video processing is too high .
On the other hand , There is an inconsistency between video prediction task and autoregressive mask visual pre training . In the actual test , The model must predict the complete future frame sequence from scratch , This leads to poor video prediction quality .
Based on this background , Li Feifei's team proposed MaskViT—— Visual modeling by masking Transformer pretraining , Thus the video prediction model is established .

There are two design decisions .
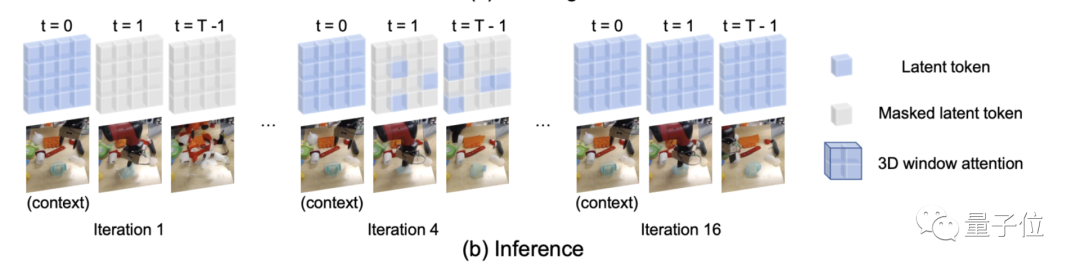
First , To improve memory and training efficiency , Two types of window attention are used : Spatial attention and spatiotemporal attention .
secondly , Masked during training token The proportion is variable .
In the reasoning stage , Video is generated through iterative refinement , The mask rate is gradually reduced according to the mask scheduling function .
experimental result
The research team worked on three different data sets , And four different indicators MaskViT.
Results show , Compared with the previous advanced methods ,MaskViT Both showed better performance , It can generate a resolution of 256 × 256 In the video .

still BAIR Ablation experiments were carried out .

And then , The team also demonstrated the use of real robots MaskViT The effect of real-time planning .
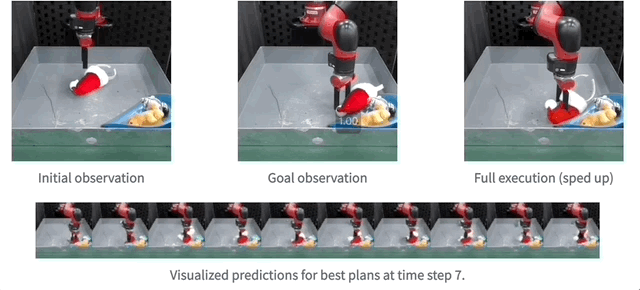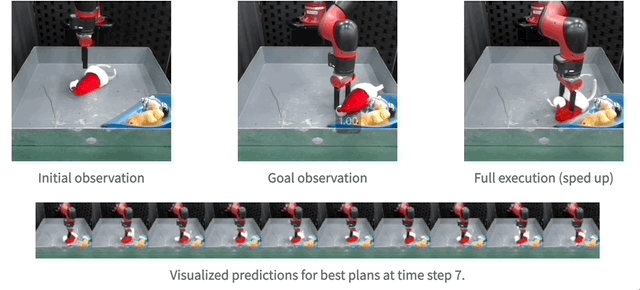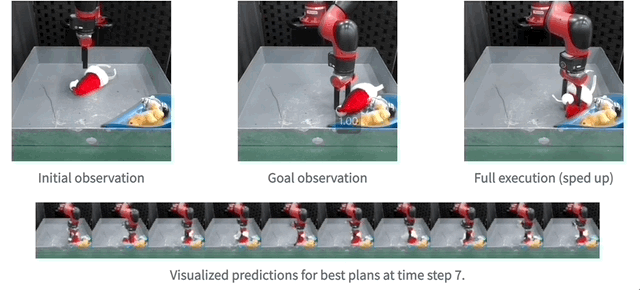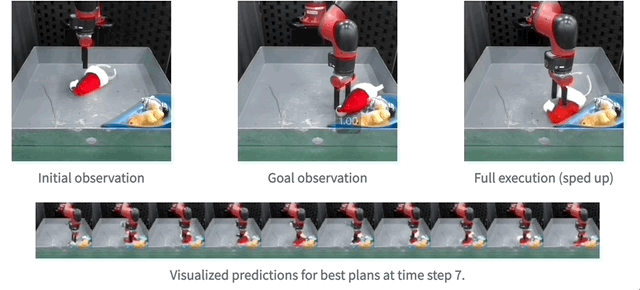
Reasoning speed can be increased up to 512 times .

The researchers say , This work shows that , With minimal domain knowledge , A general framework for visual modeling using masks , Give powerful prediction models like agents .
But at the same time , It also has some limitations .
For example, flicker artifacts may occur during quantization of each frame , Especially in RoboNet In this kind of video with static background .

And if we want to expand the scale of video prediction , Still challenging , Especially when there is a lot of camera movement .
future , They will explore how to integrate this video prediction method into more complex planning algorithms .
It is worth mentioning that , In this year 5 month , Hekaiming's team has proposed a video version MAE, And found that the best masking rate is as high as 90%.
Thesis link :
https://arxiv.org/abs/2206.11894
Project links :
https://maskedvit.github.io/
Hekaiming's thesis :
https://arxiv.org/abs/2205.09113
边栏推荐
- Selenium chrome disable JS disable pictures
- 【leetcode】701. Insert operation in binary search tree
- STEPN 新手入门及进阶
- 还存在过有键盘的kindle?
- 人人都当科学家之免Gas体验mint爱死机
- Auto Sharding Policy will apply Data Sharding policy as it failed to apply file Sharding Policy
- Practice of federal learning in Tencent micro vision advertising
- Simple use of tensor
- 7 自定义损失函数
- 如何辨别合约问题
猜你喜欢

5000 word analysis: the way of container security attack and defense in actual combat scenarios

9 Tensorboard的使用

How to configure and use the new single line lidar

Simple use of tensor

NFT 项目的开发、部署、上线的流程(1)

还存在过有键盘的kindle?

Beijing University and Tencent jointly build angel4.0, and the self-developed in-depth learning framework "River map" is integrated into the ecology

如何辨别合约问题

Ten thousand words! In depth analysis of the development trend of multi-party data collaborative application and privacy computing under the data security law

首例猪心移植细节全面披露:患者体内发现人类疱疹病毒,死后心脏重量翻倍,心肌细胞纤维化丨团队最新论文...
随机推荐
NFT transaction principle analysis (2)
NFT contract basic knowledge explanation
Super double efficiency! Pycharm ten tips
What is the process of switching C # read / write files from user mode to kernel mode?
Stepn novice introduction and advanced
5 model saving and loading
8 user defined evaluation function
Swiftui retrieves the missing list view animation
C. Inversion Graph
大话领域驱动设计——表示层及其他
【leetcode】331. 验证二叉树的前序序列化
01 backpack DP
TweenMax+SVG切换颜色动画场景
IntelliJ idea -- Method for formatting SQL files
svg canvas画布拖拽
svg环绕地球动画js特效
还存在过有键盘的kindle?
When a project with cmake is cross compiled to a link, an error cannot be found So dynamic library file
Svg animation around the earth JS special effects
若依打包如何分离jar包和资源文件?