当前位置:网站首页>Tensorflow常用函数
Tensorflow常用函数
2022-08-02 14:08:00 【伏月三十】
Tensorflow常用函数
| 函数名 | 含义 |
|---|---|
| tf.cast(张量名,dtype=数据类型) | 强制tensor转化为该数据类型 |
| tf.reduce_min(张量名) | 计算张量维度上元素的最小值 |
| tf.reduce_max(张量名) | 计算张量维度上元素的最大值 |
| axis | axis=0代表跨行计算,axis=1代表跨列计算 |
| tf.Variable(初始值) | 将变量表示为可训练 |
| tf.add(张量1,张量2) | 加 |
| tf.subtract(张量1,张量2) | 减 |
| tf.multiply(张量1,张量2) | 乘 |
| tf.divide(张量1,张量2) | 除 |
| tf.square(张量) | 计算某个张量的平方 |
| tf.pow(张量名,n) | 计算某个张量的n次方 |
| tf.sqrt(张量) | 计算某个张量的开方 |
| tf.matmul矩阵1,矩阵2) | 两个矩阵相乘 |
| tf.data.Dataset.from_tensor_slices(输入特征,标签) | 切分传入张量的第一维度,生成输入特征/标签对,构建数据集 |
| tf.GradientTape() | 与with结构使用,求张量的梯度 |
| enumerate(列表名) | 与for使用,遍历每个元素 |
| tf.one_hot(张待转换数据,depth=几分类) | 将待转换数据转换成one-hot形式的数据输出 |
| tf.nn.softmax(y) | 前向传播求出的y不可以直接用one-hot形式输出,需要转成符合概率分布的数 |
| w.assgin_sub(w要自减的内容) | 要先定义为可训练 |
| tf.argmax(张量名,axis=操作轴) | 返回张量沿指定维度最大值的索引 |
转换数据类型、求最大值最小值

print("----------强制类型转换、找出最大和最小---------")
x1=tf.constant([1.,2.,3.],dtype=tf.float64)
print(x1)
#强制类型转换
x2=tf.cast(x1,tf.int32)
print(x2)
#找出最大最小
print(tf.reduce_min(x2),tf.reduce_max(x2))
axis()

print("----------axis---------")
x=tf.constant([[1,2,3],[2,2,3]])
print(x)
print(tf.reduce_mean(x))
print(tf.reduce_sum(x,axis=1))
可训练的

数学运算—四则运算


print("---------对应元素的四则运算----------")
a=tf.ones([1,3])
b=tf.fill([1,3],3.)
print(a)
print(b)
print(tf.add(a,b))
print(tf.subtract(a,b))
print(tf.multiply(a,b))
print(tf.divide(b,a))
数学运算—平方、开方、次方

print("---------平方、次方、开方----------")
a=tf.fill([1,2],3.)
print(a)
print(tf.pow(a,3))
print(tf.square(a))
print(tf.sqrt(a))
数学运算—矩阵乘

print("---------两个矩阵相乘----------")
a=tf.ones([3,2])
b=tf.fill([2,3],3.)
print(tf.matmul(a,b))
生成输入、特征标签对

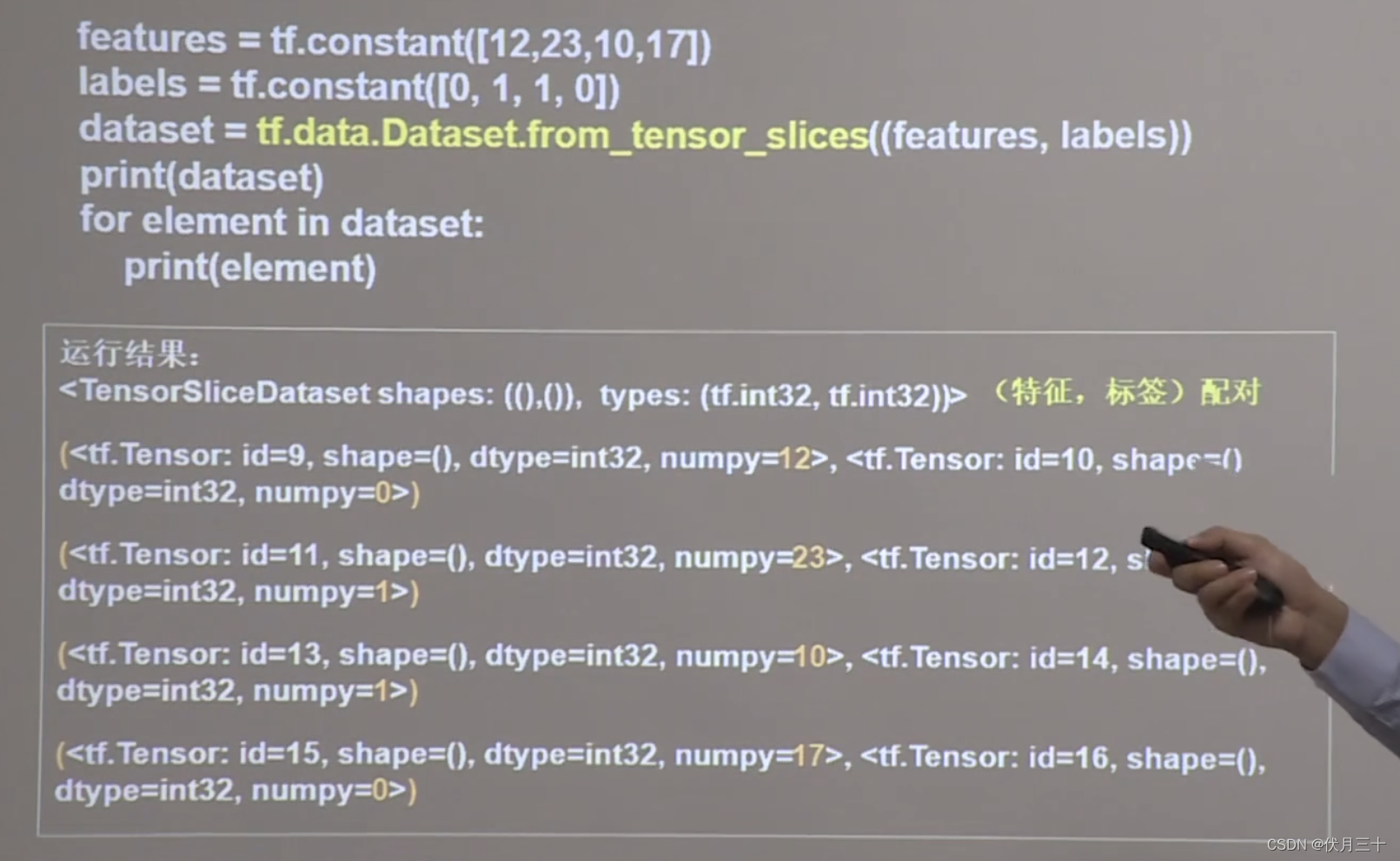
print("---------生成特征、标签对----------")
features=tf.constant([12,23,10,17])
lables=tf.constant([0,1,1,0])
dataset=tf.data.Dataset.from_tensor_slices((features,lables))
print(dataset)
for element in dataset:
print(element)
求导函数

print("---------with结构实现求导----------")
with tf.GradientTape() as tape:
w=tf.Variable(tf.constant(3.0))
loss=tf.pow(w,2)
gard=tape.gradient(loss,w)
print("grad:",gard)
遍历每个元素

print("---------遍历每个元素----------")
seq=['one','two','three']
#i接收索引,element接收元素
for i,element in enumerate(seq):
print(i,element)
独热码做标签


print("---------one_hot独热码----------")
#三分类问题
classes=3
lables=tf.constant([1,0,2])
output=tf.one_hot(lables,depth=classes)
print(output)
输出符合概率分布

对于分类问题,神经网络完成前向传播求出y(1.01,2.01,-0.66)
这些数字只有符合概率分布后,才可以和独热码的标签比较。
使用上面公式,输出符合概率分布,结果是:0.256,0.695,0.048,和为1。
0.256表示0类鸢尾的概率是25.6%…
使用softmax()实现概率分布的函数。
softmax()函数可以使n分类的n个输出y0,y1,直到yn-1符合概率分布,即将每个输出值变到0-1之间的概率值。概率的和为1。
print("---------tf.nn.softmax----------")
#前向传播的结果
y=tf.constant([1.01,2.01,-0.66])
y_pro=tf.nn.softmax(y)
print("After softmax,y_pro is:",y_pro)
自增、自减

print("---------自减----------")
#先定义成可训练的
w=tf.Variable(4)
#zijian1
w.assign_sub(1)
print(w)
返回张量沿指定维度最大值的索引

print("---------返回张量沿指定维度最大值的索引----------")
test=np.array([[1,2,3],[2,3,4],[5,4,3],[8,7,2]])
print(test)
print(tf.argmax(test,axis=0))
print(tf.argmax(test,axis=1))
边栏推荐
猜你喜欢





随机推荐
电商项目常见连续登录,消费,日期等问题
MySQL知识总结 (二) 存储引擎
拥抱Jetpack之印象篇
spark(standalone,yarn)
spark on yarn
什么是外生变量和内生变量
Flink实现Exactly Once
利用红外-可见光图像数据集OTCBVS打通图像融合、目标检测和目标跟踪
芝诺悖论的理解
Kubernetes架构和组件
什么是 Web 3.0:面向未来的去中心化互联网
LLVM系列第二十五章:简单统计一下LLVM源码行数
加强版Apktool堪称逆向神器
spark资源调度和任务调度
Enhanced Apktool reverse artifact
MySQL知识总结 (九) 用户与用户权限管理
checkPermissions Missing write access to /usr/local/lib
LLVM系列第十七章:控制流语句for
LLVM系列第二十章:写一个简单的Function Pass
PyTorch⑩---卷积神经网络_一个小的神经网络搭建