当前位置:网站首页>Scala学习总结
Scala学习总结
2022-08-02 14:05:00 【大学生爱编程】
1.Scala简单介绍
1、Scala是把函数式编程和面向对象编程思想结合的一门编程语言
2、大数据计算引擎spark是由Scala编写的(学习初衷)
3、Scalable Language :可扩展的语言
4、特点:
(1)多范式 面向对象 函数式编程
(2) 兼容Java 类库调用 互操作
(3)简洁 代码行短,自动类型推断,抽象控制
5、在函数式编程中,把函数传来传去
6、Java编程与Scala编程都会被先编译成class文件,然后放到jvm上运行,但Scala无法反编译(Scala在Java的基础上做了一次封装,类是兼容的概念相同的但是语法有差别)
2.Scala安装
下载Scala插件 引入三个依赖 加入Java和Scala的编译插件
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
Scala和Java的编译插件
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
3.Scala基础语法
1.基础
**var:**可变的 变量的引用可以再指向其他值
**val:**不可变的
**数组:**元素可以进行直接赋值修改,可以根据下标取值也可以直接分割打印,可以增强for循环打印
直接mkString()打印数组元素:
val ints:Array[Int]=Array(1,2,3,4,5)
println(ints.mkString("分隔符")) //得到的是一个字符串
增强for:
for(a:Int<-ints){
print(a+",")
}
scala中的异常默认直接抛出
2.读写文件
读文件 java的方式
Java中的缓冲流读取文件
val bufferedReader=new BufferedReader(new FileReader("文件路径"))
var line:String=bufferedReader.readLine()
while(line!=null){
println(line) (此处注意,(line=bufferedReader.readline())!=null是不可以的)
line=bufferedReader.readLine()
}
读文件 Scala的方式
//迭代器可以toList
val bufferedSource:BufferedSource=Source.fromFile("文件路径")
val lines:Interator[String]=bufferedSourcce.getLines()
for(line<-lines){
println(line)
}
bufferedReader.close()
写文件
val fileWriter=new FileWriter("文件路径")
fileWriter.write("java"+"\n"+"hadoop")
fileWriter.close()
3.函数(定义,调用,简写)
1.main方法的区别
public static void main(String[] args){....}
def main(args:Array[String]):Unit={....}
2.函数的定义与简写
1.可以定义在object中,直接用函数名即可调用
2.可以在方法或者函数内部进行定义函数
定义:
关键字 函数名(参数列表): 返回值类型 **注意Unit相当于void**
def add(x:Int,y:Int):Int={
return x+y
}
简写:
1.函数体最后一行作为返回值,return可以省略
def add1(x: Int): Int = {
x + x
}
2.函数体在同一行,{}可以省略
def add2(x: Int, y: Int): Int = x + y
3.返回值类型可以根据参数列表自动进行推断,可以省略
def add3(x: Int, y: Int) = x + y
4.参数列表为空,()可以不写,但是调用的时候也不可以写()
def pr(): Unit = println("scala")
3.函数的调用
1.使用object名称调用方法
println(obj名称.add(100,200))
println(add2(100,200))
2.函数的参数只有一个时,省略". ()"
val str="java,spark,hadoop"
val string1:Array[String]=str.split(",")
简写:val String1:Array[String]=str split ","
4.类
object是一个单例对象,类只有一个对象
(构造函数加了参数后就必须传参数才能创建对象)
class Student(这里写构造方法的参数id:String,name:String){ // {}内的是默认的构造方法
println("默认的构造方法")
//属性
在默认构造函数内部进行重载构造函数
def this(id:String,name:String,age:Int){
//在重载构造函数第一行调用默认构造函数
this(id,name)
}
}
5.样例类 case class
Score object是Score class的伴生对象,但是没有什么关系,利用重名以及apply方法
apply:是object中一个特殊的方法,可以直接使用object的名称调用
1、可以省略new创建对象
底层创建一个伴生对象(对象名和类名同名),定义apply方法时在方法内部new了一个对象,apply方法可以用对象名直接调用,所以样例类可以省略new,因为在用对伴生对象名的时候自动调用了apply方法,所以自动new了对象
apply()直接用对象名调用
val score:Score1=Score("001",200) //右边调用apply方法,传参数,返回值为new Score1("001",200),Score1右重写的toString方法,打印名字默认调用重写方法
println(score)
object Score{
def apply(sid:String,sco:Int):Score1={
new Score1(sid,sco)
}
}
class Score1(sid:String,sco:Int){
override def toString:String=s"Score($sid,$sco)"
}
2、编译时动态增加新的方法属性,参数变属性,重载构造方法,toString方法,序列化,equal()
3、样例类的参数默认是val的,传参数创建对象后不可修改属性,参数列表加var即可
参数可以给默认值,在创建对象时可以不传参数
6.函数作为参数
String类型转化,直接点直接to xxx.toInt() xxx.toLong()
函数类型的表示:
String =>Int :(参数类型=>返回值类型)参数是String返回值是Int类型的函数
可变化的逻辑代码进行封装,比如我只关心String类型转化成Int类型,但具体怎么转我不关心
lamada表达式: 匿名函数 对参数函数进行简化
def fun(s:String=>Int):Unit={ //需要传进去一个参数为String返回值为Int的函数
val m=s("500")
print(m)
}
//使用lambda表达式作为函数的参数 没有函数名,f是作为引用不是函数名
val f=(s1:String)=>{s1.toInt} //函数体只有一行可以省略{}
fun(f)
-------------------------------------------
fun((s:String)=>{s.toInt})
//输入的参数类型可以自动推断
//参数只使用了一次可以使用"_"代替 fun(_.toInt)
函数作为参数的应用
无需循环,只需要指出循环时做什么事情
val array=Array(1,2,3,4,5,6)
def f(i:Int):Unit=println(i)
array.foreach(f) //lambda简写:array.foreach((i:Int)=>println(i))
//需要传一个参数为Int返回值为U(Unit)的函数
//foreach()可以将数组中的元素一个一个传给函数
-------------------------------------------------------------------
//println也是函数,Any是所有类型的父类,Int是Any的子类
def println(x:Any):Unit={Console.println(x)}
7.集合
1.在Scala中可以使用Java的集合
2.Java的集合在Scala中不能用增强for(本质是迭代器),他们的迭代器不同
遍历集合
val list=new Util.ArrayList[Int]()
list.add(1) list.add(2) list.add(3) list.add(4)
//可以使用下标获取某一值,也可以使用下标进行while循环
var i=0
while(i<list.size()){
println(list.get(i))
i+=i
}
8.Scala集合
有自己的迭代器
1.List: 有序 不唯一(可去重)
2.Set: 无序 唯一
3.Map: kv格式 key唯一
4.Tuple: 元组 固定长度
List集合简单方法
val list=List(1,2,3,4,5,6,7) //不可变的集合
println(list.head) //取头元素
println(list.last) //取尾元素
println(list.tail) //获取头元素外的所有元素(返回新的集合)
println(list.mkString(",")) //集合中元素拼接成一个字符串
println(list.reverse) //转置集合(返回的是新的集合)
println(list.take(3)) //取前三个元素
println(list.takeRight(3)) //取后三个元素
println(list.distinct) //去重
println(list.sum) //数字类型的集合进行求和
println(list.max) //取最大值,最小值
List集合复杂方法(高阶函数) 返回新的集合不会产生新的集合
val list=List(1,2,3,4,5,6,7)
list.foreach() //元素挨个传递给函数,没有返回值
var sum=0
list.foreach((i:Int)=>{sum+=i}) //list.foreach(println)
print(sum)
----------------------------------------------------------
list.map() //元素挨个传递给函数,返回值为新的集合,一行对一行
val list2:List[Int]=list.map((i:Int)=>{
if(i%2==0){
i*2 //{}可以省略
}else{
i+1
}
})
-------------------------------------------------------------
list.filter() //传一个判断条件,将符合条件的数据返回,输出类型为Boolean
val list3:List[Int]=list.filter((i:Int)=>i%2==1)
println(list3) //得到的集合的展示 list3[1,3,5,7]
------------------------------------------------------------
list.flatMap() //循环两次,将返回的集合拆开构建一个新的集合
val linesList=List("java,spark","datax,scala","hive,sqoop")
val wordsList:List[String]=linesList.flatMap((line:String)=>{
line.split(",")
wordsList.foreach(println)
})
------------------------------------------------------------
list.sortby() //返回需要排序的字段 默认升序
list.sortWith() //指定排序规则
val list:Lint[Int]=List(1,2,3,4,5,3,2,5,6,7,1)
val sortByList=lits.sortBy((i:Int)=>i) //默认是升序,-i表示是降序
println(sortWithList)
val sortByList:List[Int]=list.sortWith((x:Int,y:Int)=>{x>y})
------------------------------------------------------------
list.groupby() //指定一个分组的字段
val words=List("java","java","hadop","spark","java","hadoop","spark","java","hadoop")
val groupByList:Map[String,List[String]]=words.groupBy((word:String)=>word)
Set集合:无序,唯一 没有sort方法,其他方法基本一致
val set=Set(1,2,4,5,6,7,8)
println(set)
println(set.mkString("\t"))
set.foreach(println)
-----------------------------------------------------------
set集合的交并差运算
val s1=Set(1,2,3,4,6)
val s2=Set(3,4,5,6,7)
println(s1&s2) //交集 | 并集 s1&~s2 差集(前者减去交集)
-----------------------------------------------------------
list集合与set集合之间的相互转换
val list=List(1,2,2,3,4,5,6,5,3,5,6,)
val listtoset=list.toSet
println(listtoset)
println(listtoset.toList)
Immutable:不可变的
Mutable可变:listBuffer HashSet
val listBuffer=new ListBuffer[String]
listBuffer.+=("java") listBuffer.+=("hadoop") //增加元素
listBuffer-="java" //删除元素 省略的 . ()
listBuffer.remove(1) //利用下标删除元素,索引从0开始
listBuffer ++=List("spark","hadoop") //批量插入元素
listBuffer.update(1,"shujia") //利用下标更新元素(替换)
listBudder.insert(2,"shujia") //插入元素
------------------------------------------------------------
val hashSet=new mutable.HashSet[Int]() //指定包名
//无序的,没有索引,直接删值
hashSet +=1 hashSet +=3 hashSet +=4 //增加元素
hashSet -=1 //删除元素
tuple(元组:固定长度的集合) 下划线加下标获取数据,从1开始
存储多个相同或不同的值,长度和内容都不可变,最多能存22个元素
val tuple=Tuple5(1,2,3,4,5) //指定集合类型 以及元素个数
简写: val tuple=(1,2,3,4,5)
println(tuple._5) //元组名称._索引 快速得到元素,避免下标越界异常
map集合 kv键值形式的集合 (简写 ->函数)
val map:Map[String,Int]=Map(("001",23),("002",24),"003"->25)
val value1=map("001") //通过key取得value
println(value)
val value2=map.getOrElse("006",0) //key不存在就返回默认值(Int)
println(value2)
//给每个人的值加1 参数为二元组的类型,元组内部是String和Int
val addAge:Map[String,Int]=map.map((kv:(String,Int))=>{
val id=kv._1
val age=kv._2
(id,age+1) //每次返回一个新的二元组
}
addAge.foreach(println)
可变map集合 hashmap
val hashMap=new mutable.HashMap[String,String]()
hashMap.+=(("001","张三")) //插入元素 key重复时自动覆盖
hashMap.+=(("002","李四"))
hashMap += "003"->"王五" //省略. ()时换一下元素对形式
hashMap.remove("003") //根据键删除键值
hashMap.-=("002") //或者 hashMao -= "002"
4.解析json格式数据
添加依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.79</version>
</dependency>
[
{
"id":"001",
"name": "张三",
"age": 23
},{
"id": "002",
"name": "李四",
"age": 24
}
]
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
import scala.io.Source
object json {
def main(args: Array[String]): Unit = {
val lines: List[String] =Source.fromFile("D:\\mavenprojects\\maven_study\\scala_demo\\src\\data\\users.json").getLines().toList
// lines.foreach(println)
//读到的数据转字符串
val jsonStr:String=lines.mkString("\n")
// print(jsonStr)
//使用fastjson,将字符串转成json对象
val userArray: JSONArray =JSON.parseArray(jsonStr)
var index=0
while(index<userArray.size()){
//通过下标获取用户
val userObject: JSONObject =userArray.getJSONObject(index)
//通过列名获取列值
val id:String=userObject.getString("id")
val name:String=userObject.getString("name")
val age: Long=userObject.getLong("age")
index +=1
println(s"$id,$name,$age")
}
}
}
5.隐式转换(动态给对象增加新的方法)
import scala.collection.JavaConverters._
import scala.collection.JavaConversions._
asScala asJava
import java.util
object scalaToJava {
def main(args: Array[String]): Unit = {
/**
* java集合与scala互相转换
*/
//Java中的集合
val arrayList=new util.ArrayList[String]()
arrayList.add("java")
arrayList.add("spark")
/**
* 导入隐式转换(动态给对象增加scala中的方法)得到迭代器再toList
*/
import scala.collection.JavaConverters._
import scala.collection.JavaConversions._
val scalaList:List[String] =arrayList.asScala.toList
println(scalaList)
/**
* Scala集合转Java集合
*/
val list=List(1,2,3,4,5,6)
val javaList: util.List[Int] =list.asJava
println(javaList)
}
}
6.模式匹配(功能强大)
只有一个能匹配成功,所以下划线可以用来兜底
1.基本数据类型
val i=100
i match {
case 10=>{println("i的值为10")}
case 100=>{println("i的值为100")}
case _=>{println("其他")}
}
2.匹配字符串
val str:String="java"
str match {
case "java" =>
println("java")
case "spark" =>
println("spark")
case _ => println("其它")
}
3.匹配元组(取元组中的元素)
val t: (String, Int, String) = ("张三", 23, "001")
t match {
case (name: String, age: Int, id: String) =>
println(s"$name\t$age\t$id")
//println(s"$name")
}
//替代下划线 相当于对应得定义三个变量,再取值
val (name: String, age: Int, id: String) = t
println(s"$name\t$age\t$id")
元组时一个括号,只能手动构建之,而数组还可以通过其他函数切分等得到
4.匹配数组
val array: Array[Any] = Array("001", "李四")
array match {
case Array(id: String, name: String, age: Int) =>
println(s"$id\t$name\4$age")
case Array(id: String, name: String) =>
println(s"$id\t$name")
}
5.匹配类型
val obj: Any = 10
obj match {
case i: Int =>
println(s"obj是一个Int类型:$i")
case s: String =>
println(s"obj是一个String类型:$s")
case d: Double =>
println(s"obj是一个Double类型:$d")
case _ =>
println(s"其它类型:$obj")
}
6.模式匹配的返回值
val i1:Int=100
val t:String=i1%2 match{
case 1=>"奇数"
case 0=>"偶数"
}
println(t)
7.模式匹配在map中的应用 在一定情况下避免报错
val map=Map("001"->"张三","002"->"李四")
println(map.getOrElse("002","默认值")) //如果key没有匹配到就返回默认值
val value1:Option[String]=map.get("005") //在这种情况下会报错
println(value1)
//Option[String]:有值的时候是value1返回的是Some(值),value1.get得到值,没有值返回None
val value2:String=map.get("003") match{
case Some(v)=>v
case None=>"默认值"
}
println(value2)
8.模式匹配结合函数使用 (集合元素为一个大的String)
val lines: List[String] =Source.fromFile("D:\\mavenprojects\\maven_study\\scala_demo\\src\\data\\students.txt").getLines().toList
val map1: List[Array[String]] =lines.map(line=>line.split(",")) //集合元素为字符串数组
//匹配取出数据,直接从数组中取出需要的元素组成元组
val map2: List[(String, String, String, String)] =map1.map{
case Array(id:String,name:String,age:String,gender:String,clazz:String)=>
(id,name,gender,clazz)
}
map2.foreach(println)
}
7.隐式转换 implicit(方法,类,变量)
可利用之进行封装但是可读性差
1.方法的参数类型转换成返回值类型
显示转换:直接调用方法进行转换
val s="100"
vla i:Int=s.toInt
//定义一个隐式转换的方法,与名称无关,同一个作用域中只能出现一个同样类型同样返回值的隐式转换
//隐式地将参数类型转换成返回值类型,具体逻辑还是根据函数体
implicit def strToInt(s:String):Int={Integer.parseInt(s)}
implicit def doubleToInt(s:Double):Int={s.toInt}
fun("200")
fun(3.14) //结果为9
例如:String类型是没法直接toInt的,经过一次隐式转换成为了StringLike就可以调toInt了
2.隐式地将类的构造函数的参数类型转换成类的参数类型
给字符串动态地增加了新的方法
类的 构造函数的参数
implicit class Read(path:String){ //定义一个隐式转换类
def read():List[String]={ //构造函数的参数类型转成类的类型
Source.fromFile(path).getLines().toList
}
}
val scores:List[String]="data/score.txt".read()
3.隐式转换变量会对隐式转换的参数自动补齐(类型要对应上)
def add(x: Int)(implicit y: Int): Int = {
x + y
}
val i: Int = add(100)(200)
println(i)
//定义一个隐式转换变量
implicit val a: Int = 1000
//调用方法时,会自动使用当前作用域同类型的隐式转换变量填补上发方法的隐式转换参数
val j: Int = add(200)
println(j)
边栏推荐
- Web Design (Beginners) [easy to understand]
- 2022最新交规记忆重点
- Flask framework in-depth
- verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十一章)
- 使用云GPU+pycharm训练模型实现后台跑程序、自动保存训练结果、服务器自动关机
- Unit 11 Serializers
- Verilog Learning Series
- The specific operation process of cloud GPU (Hengyuan cloud) training
- MongoDB Compass 安装与使用
- 宏定义问题记录day2
猜你喜欢

Using the cloud GPU + pycharm training model to realize automatic background run programs, save training results, the server automatically power off
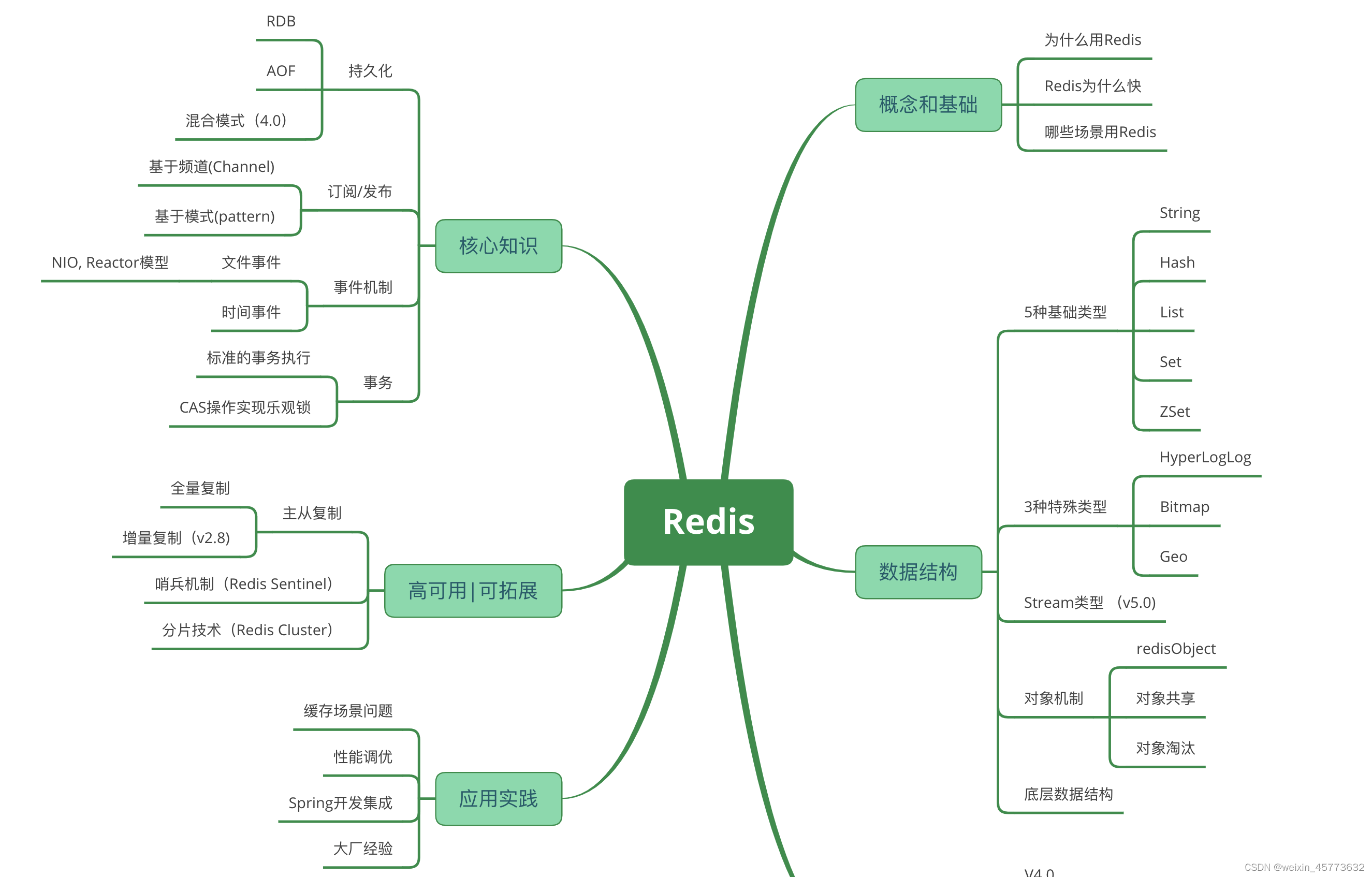
redis入门-1-redis概念和基础
宝塔面板搭建小说CMS管理系统源码实测 - ThinkPHP6.0
Redis-01-Nosql概述

MongoDB Compass 安装与使用
Unit 10 Continuous Tuning
C语言——一级指针初识
C语言日记 1“Hello world“

安装使用——百家CMS微商城说明文档(2)

ABP,kendo后台接口,新增,查询
随机推荐
MySQL知识总结 (三) 索引
Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed to apply plugin [id ‘c
Creating seven NiuYun Flask project complete and let cloud
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十四章)
redis delay queue
华为防火墙IPS
华为防火墙
Flask framework in-depth two
window10 lower semi-automatic labeling
Linux: CentOS 7 install MySQL5.7
原码、补码、反码
[ROS] (04) Detailed explanation of package.xml
VS Code远程开发及免密配置
PostgreSQL 性能谜题
MySQL知识总结 (八) InnoDB的MVCC实现机制
标签加id 和 加号 两个文本框 和一个var 赋值
MySQL知识总结 (九) 用户与用户权限管理
芝诺悖论的理解
jwt (json web token)
MySQL知识总结 (十一) MySql 日志,数据备份,数据恢复