当前位置:网站首页>yolov5 improvement (1) Add attention focus mechanism
yolov5 improvement (1) Add attention focus mechanism
2022-08-02 14:19:00 【weixin_50862344】
(1) Self-attention mechanism
What I want to learn is the attention mechanism, but it seems to be running out of bounds at first, and I learned the self-attention mechanism.Not to mention, it's pretty good.
NTU Li Hongyi Self-Attention Mechanism
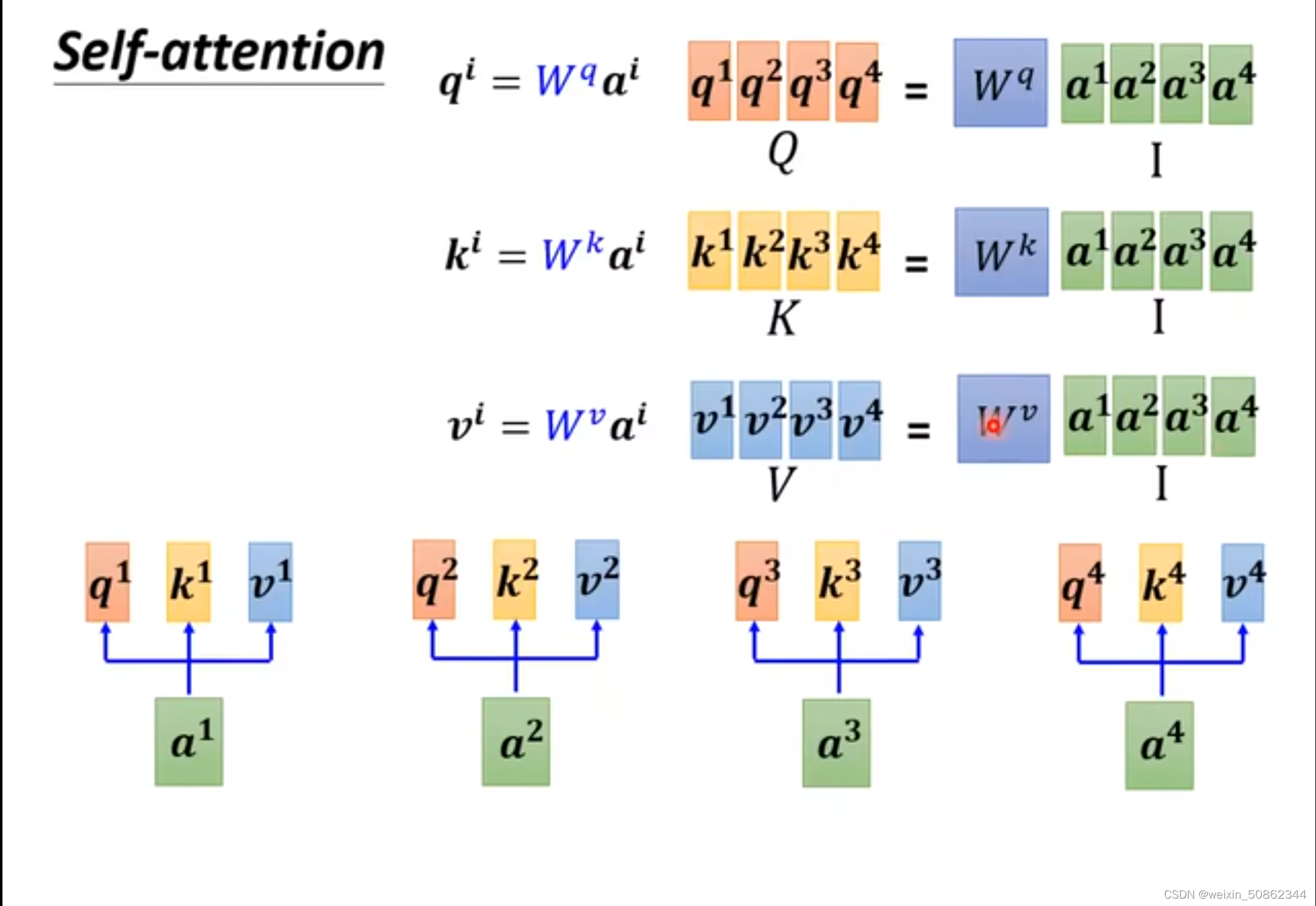
input: vector set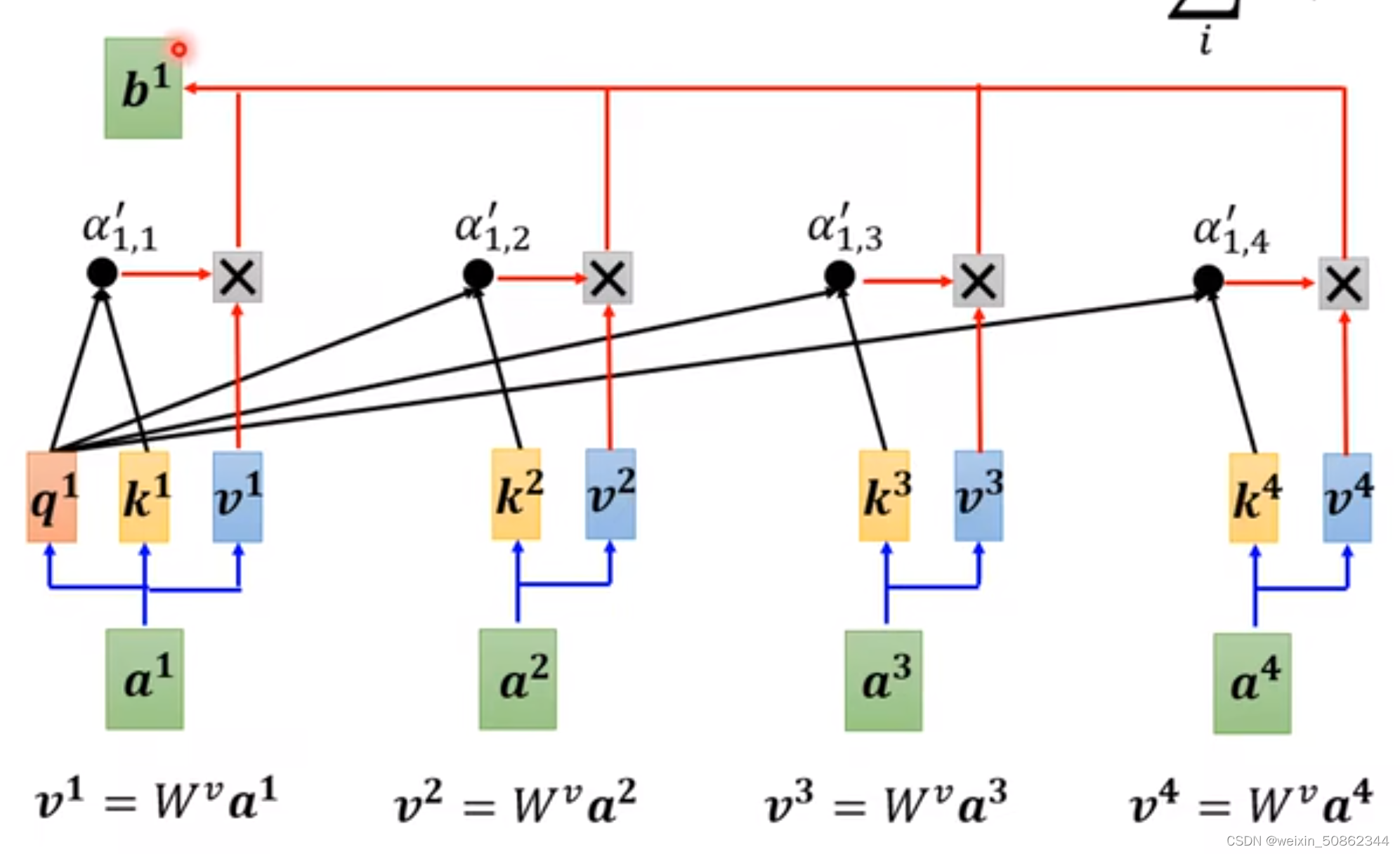
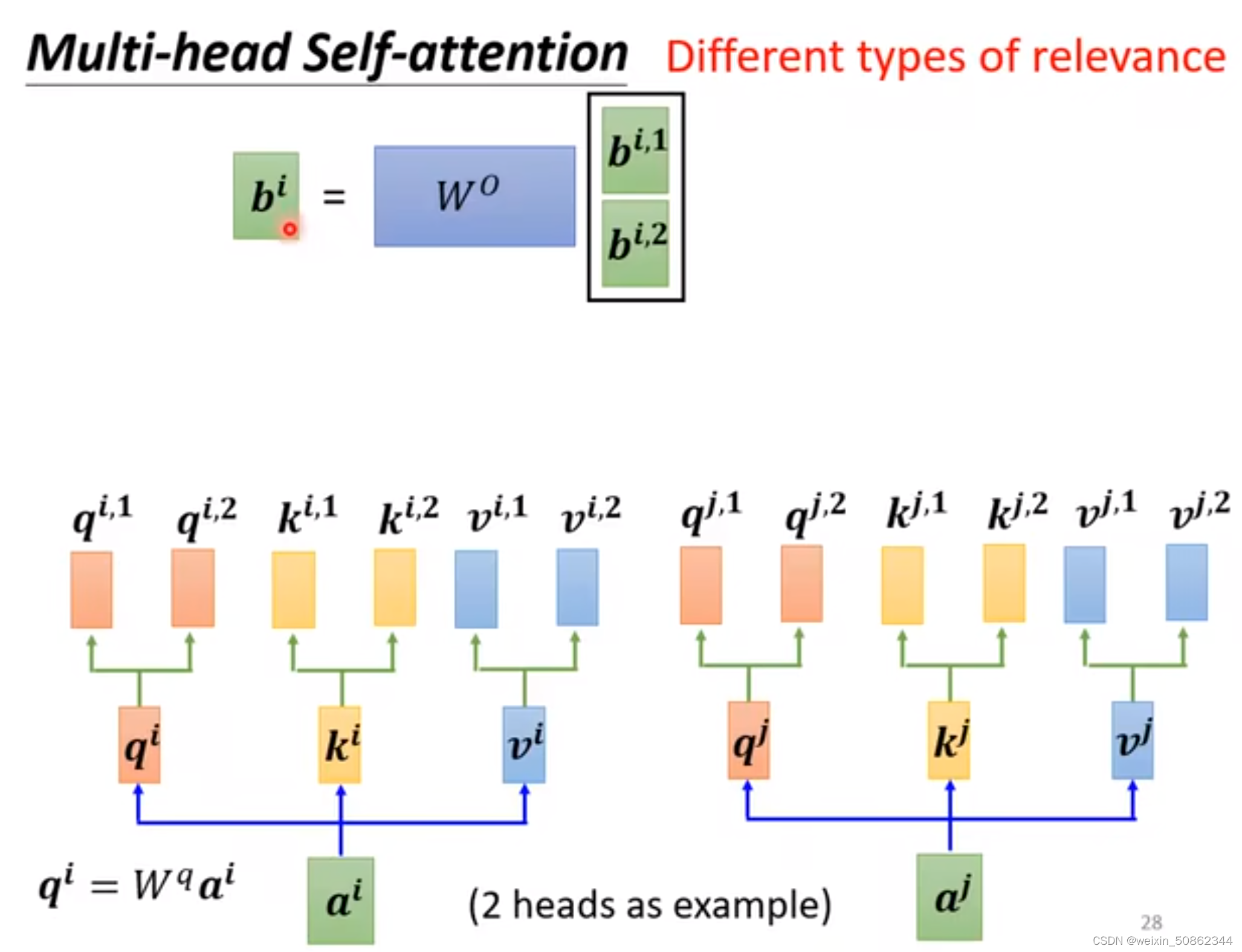
muti-head: may have different connections
Application in image: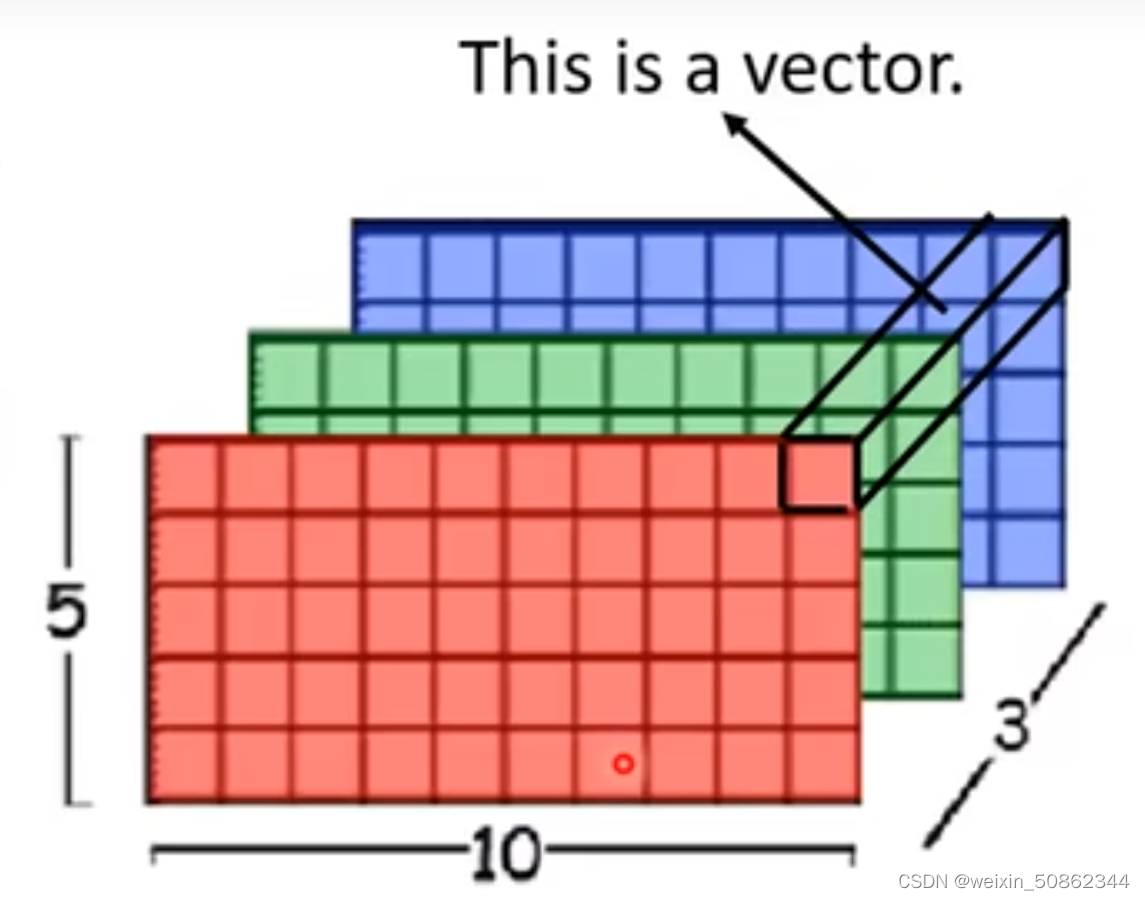
Think of rgb on a pixel as a vector
Applications on the model include: ①self-attention GAN
②DETR
Comparison of CNN and Self-attention:
CNN only considers the receptive field, and Self-attention considers the overall situation.So think of cnn as a small (simplified) Self-attention
②Small data volume is superior to CNN, while large volume Self-attention will surpass CNN
Li Hongyi's statement for the reason is: Self-Attention is more elastic, CNN is less elastic
RNN&SA
①SA is parallelized, RNN cannot parallel words
②Data memory
(2) Attention mechanism
The next step is the attention mechanism (Attention)
First upload the information first
pytorch application:
First go to the information
In fact, it is on csdnThere are online courses but poor children really have no money to spend recently, but we can still learn according to his framework
1. Understand the attention mechanism
Attention is divided into four basic types according to the different dimensions of attention: channel attention, spatial attention, temporal attention and branch attention,And two combined attentions: channel-spatial attention and spatial-temporal attention.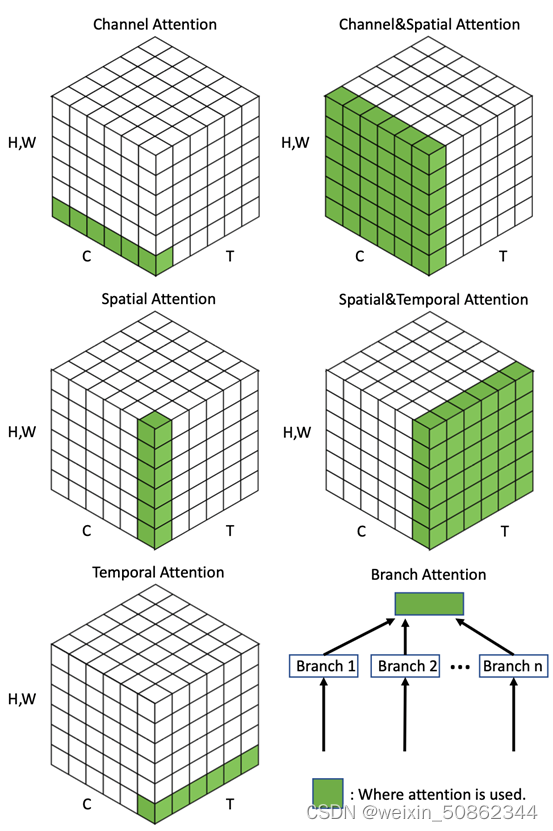
spatial: space
temporal: time
> Draw a 3D coordinate axis like this: 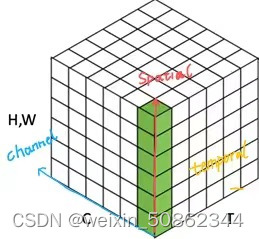
2. Enter the attention module
If you encounter problems, please look at B-led lesson
The functions that this Xiaobai does not know, the example is better to understand
1) cat: splice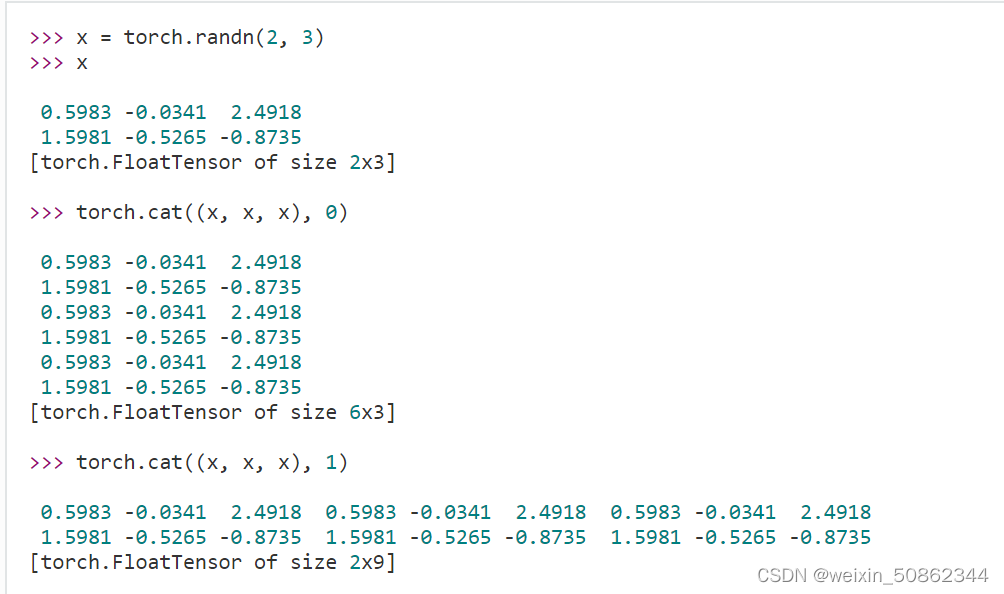
2) view: change the arrangement of cols and rows
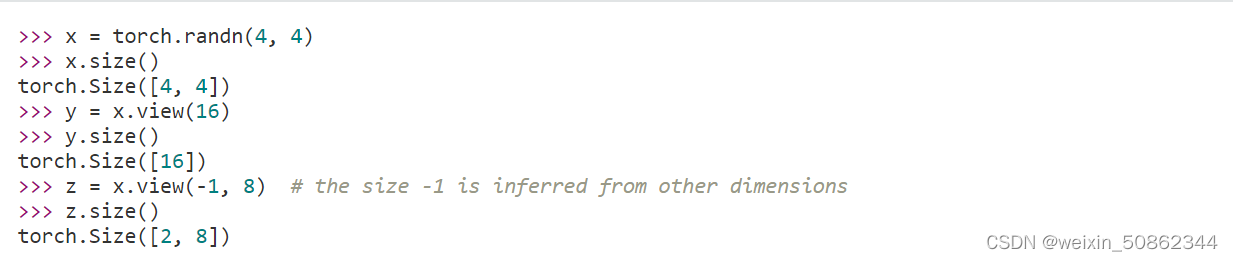
3) torch.mean channel average &torch.maxChannel max
torch.nn.AdaptiveAvgPool2d(output_size): Provides a 2-dimensional adaptive average pooling operation. For any input size input, the output size can be specified as H*Wp>
Compared with global average pooling, it can be understood that the slicing method is different!!!
The attention mechanism is a plug-and-play module that can theoretically be placed behind any feature layer.
Since placing on thebackbone will make the pretrained weights of the network unavailable, apply the attention mechanism to enhancing the feature extraction network
How come someone even wrote the actual combat?Still so well written?yolov5 adds an attention-focusing mechanismdownloaded.
If there is any problem in actual use, I will add it!!I feel that the b guide has already said it very well
1. If you add an independent attention mechanism layer, it may affect the number of subsequent layers (the number of layers of the feature map layer received from the backbone will change)
2. Generally not added to the backbone extraction network to avoid affecting the pre-training weights
边栏推荐
猜你喜欢




随机推荐
MySQL数据库语法格式
[ROS] The software package of the industrial computer does not compile
第十一单元 序列化器
音频处理:浮点型数据流转PCM文件
deal!It's July 30th!
What is the difference between web testing and app testing?
window10下半自动标注
第六单元 初识ORM
配置zabbix自动发现和自动注册。
STM32(F407)—— 堆栈
paddleocr window10初体验
Interview | with questions to learn, Apache DolphinScheduler Wang Fuzheng
如何解决mysql服务无法启动1069
idea社区版下载安装教程_安装天然气管道的流程
瑞吉外卖笔记——第10讲Swagger
php开源的客服系统_在线客服源码php
第十三单元 混入视图基类
第三单元 视图层
此次519暴跌的几点感触 2021-05-21
文件加密软件有哪些?保障你的文件安全