当前位置:网站首页>drf源码分析与全局捕获异常
drf源码分析与全局捕获异常
2022-08-02 14:01:00 【意大利面拌42号混凝土】
Python之drf源码分析与全局捕获异常
一、认证源码分析
views.py内认证类使用,与文件自定义认证类
# authentication.py
from rest_framework.authentication import BaseAuthentication
# 继承认证基类BaseAuthentication
class bookAuthentication(BaseAuthentication):
# 重写authenticate方法
def authenticate(self,request):
token = request.GET.get('token')
user_token = UserToken.objects.filter(token=token).first()
if user_token:
# 带的token是有效的
# user_token.user当前登录用户
return user_token.user, token
else:
raise AuthenticationFailed('token不合法或没有迭代token')
# views.py
from .serializers import Bookserializers
from .models import Book
from rest_framework.generics import ListCreateAPIView
from .authentication import bookAuthentication
class BookListCreateAPIView(ListCreateAPIView):
queryset = Book.objects.all()
serializer_class = Bookserializers
authentication_classes = [bookAuthentication,]
源码分析
#1 入口---》APIView的dispatch---》self.initial(request, *args, **kwargs)————》认证类的代码self.perform_authentication(request)
# 2 self.perform_authentication(request)
def perform_authentication(self, request):
request.user # 新的request对象的user方法
# 2 Request类的user方法
@property
def user(self):
if not hasattr(self, '_user'):
with wrap_attributeerrors():
self._authenticate() # 核心就是这句话,是Request的
return self._user
# 3 Request类的_authenticate(self)方法
def _authenticate(self):
for authenticator in self.authenticators: #self.authenticators是个列表,列表中放了一个个认证类的对象
try:
# self是request,所以我们的认证类的authenticate,有两个参数,self给了第二个参数
user_auth_tuple = authenticator.authenticate(self) # 执行认证类的authenticate方法
except exceptions.APIException:
self._not_authenticated()
raise
if user_auth_tuple is not None:
self._authenticator = authenticator
self.user, self.auth = user_auth_tuple #解压赋值,后续的requtst对象就有user属性了
return
self._not_authenticated()
# 4 Request类的self.authenticators属性
-是在Request初始化的时候,传入的
-Request类是在什么时候初始化的---》APIView的dispatch中的刚开始位置
-APIView的dispatch---》request = self.initialize_request(request, *args, **kwargs)
# 5 APIView的self.initialize_request方法
def initialize_request(self, request, *args, **kwargs):
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),# APIView
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
# 6 APIView的get_authenticators
def get_authenticators(self):
# 列表中放了一个个认证类的对象
return [auth() for auth in self.authentication_classes]
二、权限源码分析
#1 入口---》APIView的dispatch---》权限类的代码self.check_permissions(request)
#2 APIView的check_permissions(request)方法
def check_permissions(self, request):
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(
request,
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)
#3 APIView的self.get_permissions():
def get_permissions(self):
# 列表里放了一个个权限类的对象
return [permission() for permission in self.permission_classes]
# 4 权限认证失败,返回中文
-在权限类中配置message即可(给对象,类都可以)
三、频率源码分析
#1 入口---》APIView的dispatch---》频率类的代码self.check_throttles(request)
# 2 APIView的self.check_throttles(request)
def check_throttles(self, request):
throttle_durations = []
for throttle in self.get_throttles():# #列表,是一个个视图类中配置的频率类的对象
if not throttle.allow_request(request, self):
throttle_durations.append(throttle.wait())
# 3 APIView的self.get_throttles()
def get_throttles(self):
return [throttle() for throttle in self.throttle_classes]
四、过滤源码分析
from rest_framework.generics import GenericAPIView,ListAPIView
from rest_framework.mixins import ListModelMixin
class Book(ListAPIView):
filter_backends = ['过滤类']
首先要明确一点,过滤查询是在所有数据中查询出符合条件的
所以视图层必须继承GenericAPIView和ListModelmixin。也就是ListAPIView
ListModelmixin里有list方法————>方法里有queryset = self.filter_queryset(self.get_queryset())这就是查询条进行过滤。self.get_queryset()取出所有数据,然后调用filter_queryset方法进行过滤
在视图类GenericAPIView中有filter_queryset:
def filter_queryset(self, queryset):
for backend in list(self.filter_backends): # 去视图层中找其filter_backends
找到其过滤类并加括号调用其下重写的filter_queryset方法
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
个人理解:
如果你使用rest_framework.filter中的SearchFilter进行过滤那么你的代码在视图层将是如下这种:
from rest_framework.filters import SearchFilter
from rest_framework.generics import GenericAPIView,ListAPIView
from rest_framework.mixins import ListModelMixin
class Book(ListAPIView):
filter_backends = [SearchFilter,]
在其GenericAPIView源码中:视图类GenericAPIView中的filter_queryset方法下的backend().filter_queryset(self.request, queryset, self)就变成了SearchFilter().filter_queryset(self.request, queryset, self)
而SearchFilter().filter_queryset(self.request, queryset, self),就会执行内部过滤SearchFilter()类的filter_queryset()方法。
如果是需要自定义过滤类就需要继承过滤基类BaseFilterBackend,重写BaseFilterBackend类下的filter_queryset()方法
内部源码的执行流程也是一样
五、分页源码分析
分页是在所有数据中进行分页,所以视图层必须继承GenericAPIView和ListModelmixin。也就是ListAPIView
from rest_framework.generics import GenericAPIView,ListAPIView
from rest_framework.mixins import ListModelMixin
class Book(ListAPIView):
pagination_class =['分页类']
ListModelmixin里有list方法————>方法里有:
page = self.paginate_queryset(queryset) # 执行分页
if page is not None:
serializer = self.get_serializer(page, many=True) # 序列化当前分页的数据
return self.get_paginated_response(serializer.data) # 返回上一页和下一页和总条数
在视图类GenericAPIView中有paginate_queryset:
if self.paginator is None: # self.paginator就是分页类的对象
return None
# 实现了分页功能,取出从前端地址中传入的,第几页,取多少条
# 在该方法中自动实现分页,返回当前页码的数据
return self.paginator.paginate_queryset(queryset, self.request, view=self)
在视图类GenericAPIView中有get_paginated_response:
# self.paginator就是分页类的对象
return self.paginator.get_paginated_response(data)
个人理解结合PageNumberPagination:
如果你使用rest_framework.pagination中PageNumberPagination来进行分页,你的代码在视图层将是如下这种:
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
from rest_framework.generics import GenericAPIView,ListAPIView
from rest_framework.mixins import ListModelMixin
class Book(ListAPIView):
pagination_class =[PageNumberPagination,]
在其GenericAPIView源码中self.paginate_queryset(queryset)就会变成paginate_queryset(self, queryset)下的
return PageNumberPagination.paginate_queryset(queryset, self.request, view=self)
而get_paginated_response下的self.paginator.get_paginated_response(data)会变成PageNumberPagination.paginate_queryset(queryset, self.request, view=self)
继承APIView实现分页
# 首先需要新建一个py文件写上一个继承PageNumberPagination的类,并修改里面的类属性如下:
papg.py
from rest_framework.pagination import PageNumberPagination
class bookPageNumberPagination(PageNumberPagination):
page_size = 5
page_query_param = 'page'
page_size_query_param = 'size'
max_page_size = 10
# 在views视图类中书写代码:
from rest_framework.virews import APIView
from .papg import bookPageNumberPagination
from .models import Book
from .serializers import BookserializersModelserializer
from rest_framework.response import Response
class book(APIView):
def get(self,request):
# 获取出所有数据
all_book_queryset = Book.objcets.all()
# 实例化得到分页类的对象
page = bookPageNumberPagination()
# 调用其分页类所继承类PageNumberPagination中的paginate_queryset方法,并把所有数据传进方法里
res= page.paginate_queryset(all_book_queryset,request,self)
# 序列化分页类中的数据
serializer = BookserializersModelserializer(res, many=True)
# 将data返回出去
return Response(serializer.data)/page.get_paginated_response(serializer.data)
六、自定义全局捕获异常
from rest_framework.views import exception_handler
from rest_framework.response import Response
# 自定义异常处理
def common_exceptions_handler(exc, context):
response_exceptions = exception_handler(exc,context)
user_id = context.get('request').user.id
if not user_id:
user_id = '用户未登录'
# 精准定位异常,以后方便写入日志
errors_detail = '视图类:%s出错了,访问者的ip为:%s,访问者的id为:%s,错误原因为:%s'%(
str(context.get('view')),
context.get('request').META.get('REMOTE_ADDR'),
user_id,
str(exc)
)
print(errors_detail)
dic = {
'code':999,'msg':''}
# 如果response_exceptions有值说明异常在exceptions_handler中的Http404、PermissionDenied、exceptions.APIException,异常中
if response_exceptions:
dic['msg'] = response_exceptions.data
return Response(dic)
# 没有值说明是其他异常
dic['msg'] = '服务器异常'
return Response(dic)
""" 注意: 自定义异常必须继承APIView及其子类,因为exception_handler()方法就是APIView下的 """
全局配置
REST_FRAMEWORK = {
# 自定义异常的路径
'EXCEPTION_HANDLER':'appo1.lib.execption.common_exceptions_handler',
}
七、coreapi自动生成接口文档
# 前后的分离
-前端一批人
-根本不知道你写了什么接口,请求参数什么样,响应数据什么样
-使用什么编码都不知道
-后端一批人
-我们写了很多接口
# 需要写接口文档(不同公司有规范)
-1 公司有接口文档平台,后端在平台上录入接口
-2 使用第三方接口文档平台,后端写了在平台录入
-Yapi:开源
-3 使用md,word文档写,写完传到git上
-4 自动生成接口文档(swagger,coreapi)
-swagger自动导入,导入到Yapi中
# coreapi
-pip3 install coreapi
-在路由中配置
from rest_framework.documentation import include_docs_urls
path('docs/', include_docs_urls(title='路飞项目接口文档平台'))
-在配置文件中配置
REST_FRAMEWORK = {
'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema',
}
-访问地址http://127.0.0.1:8000/docs(只要路由中有的,都能看到)
边栏推荐
- 网络安全第五次作业
- Flutter 实现光影变换的立体旋转效果
- RKMPP库快速上手--(一)RKMPP功能及使用详解
- 不精确微分/不完全微分(Inexact differential/Imperfect differential)
- EasyExcel 的使用
- 【Tensorflow】AttributeError: '_TfDeviceCaptureOp' object has no attribute '_set_device_from_string'
- Mysql's case the when you how to use
- els strip collision deformation judgment
- Audio processing: floating point data stream to PCM file
- deal!It's July 30th!
猜你喜欢

The most complete ever!A collection of 47 common terms of "digital transformation", read it in seconds~

Some impressions of the 519 plummet 2021-05-21

Diodes and their applications
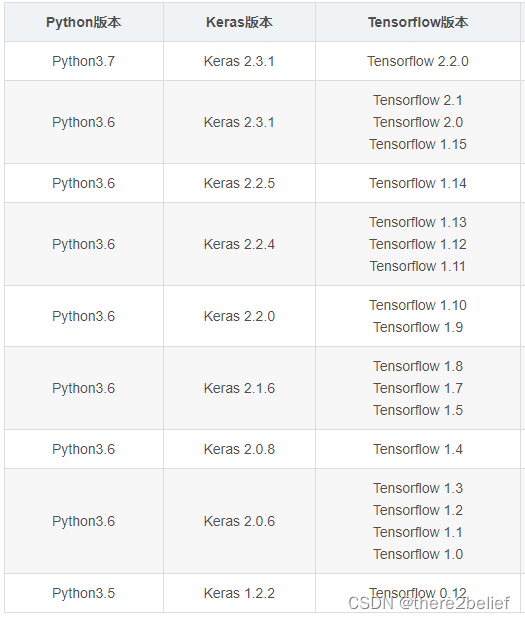
【Tensorflow】AttributeError: ‘_TfDeviceCaptureOp‘ object has no attribute ‘_set_device_from_string‘

微信小程序-最近动态滚动实现
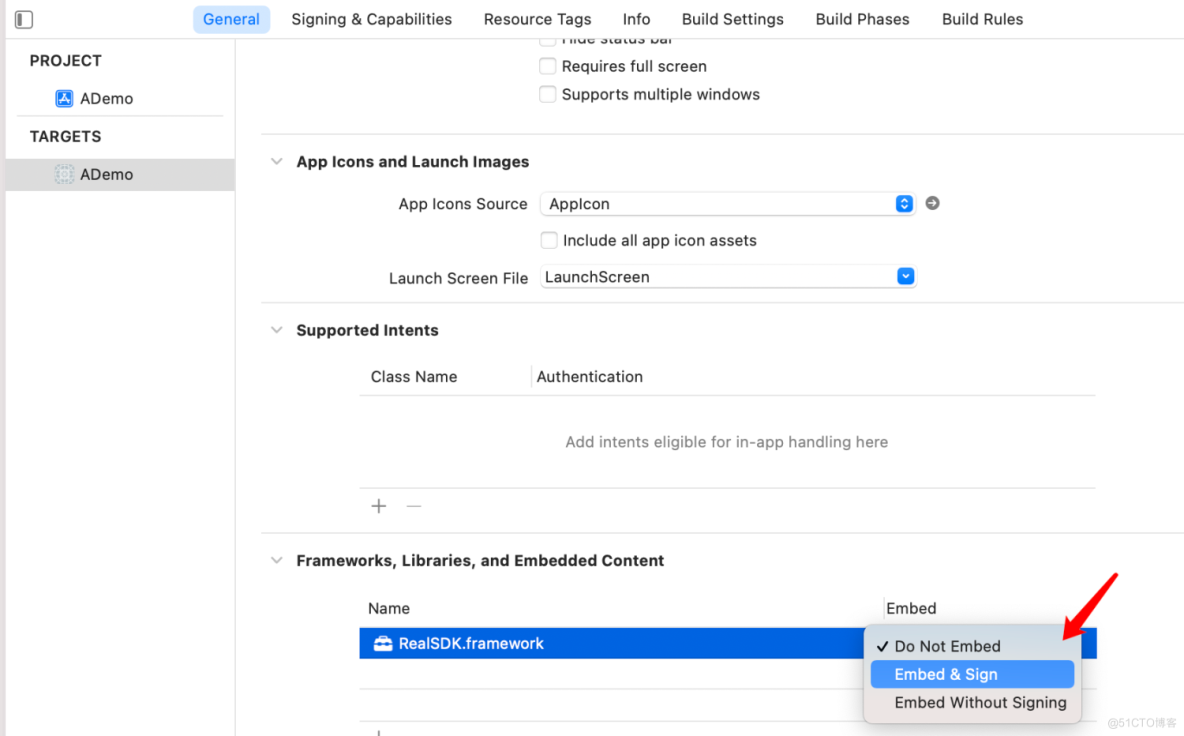
保姆级教程:写出自己的移动应用和小程序(篇三)

你接受不了60%的暴跌,就没有资格获得6000%的涨幅 2021-05-27
此次519暴跌的几点感触 2021-05-21
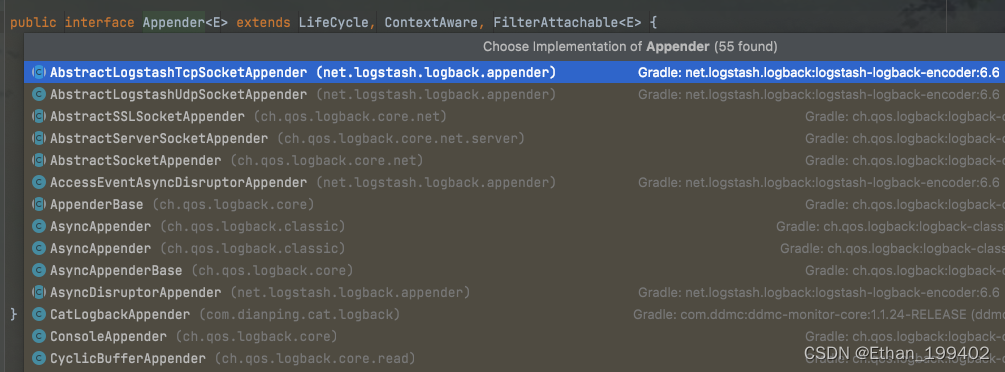
logback源码阅读(二)日志打印,自定义appender,encoder,pattern,converter
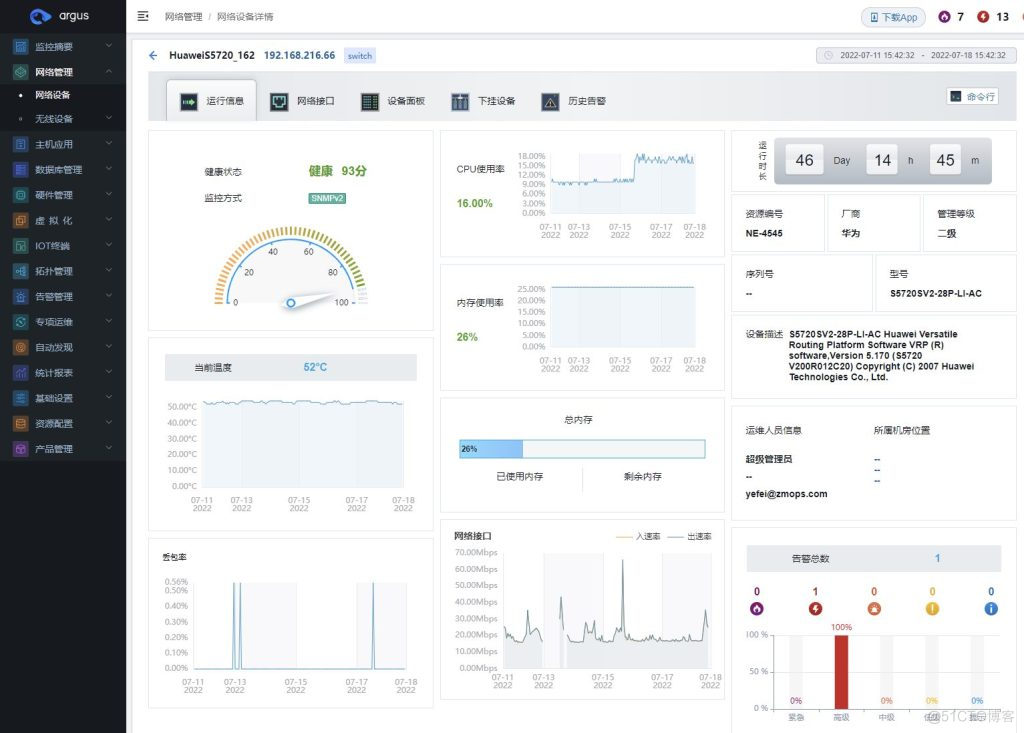
苏州大学:从 PostgreSQL 到 TDengine
随机推荐
Raft协议图解,缺陷以及优化
stack && queue
Interviewer: Can you talk about optimistic locking and pessimistic locking?
Flutter 实现光影变换的立体旋转效果
网络安全第三次作业
不精确微分/不完全微分(Inexact differential/Imperfect differential)
CVE-2020-27986(Sonarqube敏感信息泄漏) 漏洞修复
ZABBIX配置邮件报警和微信报警
SQL函数 UNIX_TIMESTAMP
WeChat Mini Program-Recent Dynamic Scrolling Implementation
网络安全第六次作业
泡利不相容原理适用的空间范围(系统)是多大?
鲲鹏devkit & boostkit
世界上最大的开源基金会 Apache 是如何运作的?
面试官:可以谈谈乐观锁和悲观锁吗
云片网案例
hsql是什么_MQL语言
SQL函数 USER
Raft对比ZAB协议
如何选择正规的期货交易平台开户?