当前位置:网站首页>yolov5detect. Py comment
yolov5detect. Py comment
2022-07-02 23:43:00 【Recursions】
import argparse
import time
from pathlib import Path
import warnings
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from utils.plots import plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
def detect(save_img=False):
# Get output folder , Input source , The weight , Parameters and other parameters
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Save the path
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
# Get the device
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
# load Float32 Model , Ensure that the input picture resolution set by the user can be divided 32( If not, adjust it to be divisible and return )
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
# Set the second classification , Default not to use
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
# Different data loading methods can be set through different input sources
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
cudnn.benchmark = True
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Get names and colors
# Get category name
names = model.module.names if hasattr(model, 'module') else model.names
# Set the color of the frame
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
# Make a forward reasoning , Test whether the procedure is normal
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
"""
path picture / Video path
img Conduct resize+pad After the picture
img0 primary size picture
cap When reading a picture, it is None, When reading video, it is the video source
"""
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
"""
Forward propagation return pred Of shape yes (1, num_boxes, 5+num_class)
h,w The length and width of the incoming network picture , Be careful dataset Rectangular reasoning is used in detection , So here h Not necessarily equal to w
num_boxes = h/32 * w/32 + h/16 * w/16 + h/8 * w/8
pred[..., 0:4] Is the coordinate of the prediction frame
The coordinates of the prediction frame are xywh( Center point + Width length ) Format
pred[..., 4] by objectness Degree of confidence
pred[..., 5:-1] For classification results
"""
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
"""
pred: The output of forward propagation
conf_thres: Confidence threshold
iou_thres:iou threshold
classes: Whether to keep only specific categories
agnostic: Conduct nms Whether to also remove the box between different categories
after nms after , Forecast box format :xywh-->xyxy( Top left, bottom right )
pred It's a list list[torch.tensor], The length is batch_size
every last torch.tensor Of shape by (num_boxes, 6), The content is box+conf+cls
"""
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
# Add secondary classification , Default not to use
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
# Process each picture
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
# Set save picture / The path of the video
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
# Set the coordinates of the save box txt Path to file
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
# Set print information ( Picture length and width )
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
# Adjust the coordinates of the prediction box : be based on resize+pad The coordinates of the picture --> Based on the original size The coordinates of the picture
# At this time, the coordinate format is xyxy
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
# Print the number of categories detected
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
# Save forecast results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
# take xyxy( top left corner + The lower right corner ) Format to xywh( Center point + Width length ) Format , And divide w,h Normalization , Convert to a list and save
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
# Draw a frame on the original picture
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# Print time (inference + NMS)
# Print forward propagation +nms Time
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
# If set, display , be show picture / video
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
# Set save picture / video
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':# Parameter resolver
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5l.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.5, help='object confidence threshold')# Degree of confidence
parser.add_argument('--iou-thres', type=float, default=0.20, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')# Multiple tags
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')# by true No generation expxx
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov5s.pt', 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()
边栏推荐
- Speech recognition Series 1: speech recognition overview
- Compose 中的 'ViewPager' 详解 | 开发者说·DTalk
- Win11麦克风测试在哪里?Win11测试麦克风的方法
- C MVC creates a view to get rid of the influence of layout
- Boost库链接错误解决方案
- JDBC練習案例
- Flexible combination of applications is a false proposition that has existed for 40 years
- 采用VNC Viewer方式遠程連接樹莓派
- leetcode 650. 2 keys keyboard with only two keys (medium)
- Request and response
猜你喜欢
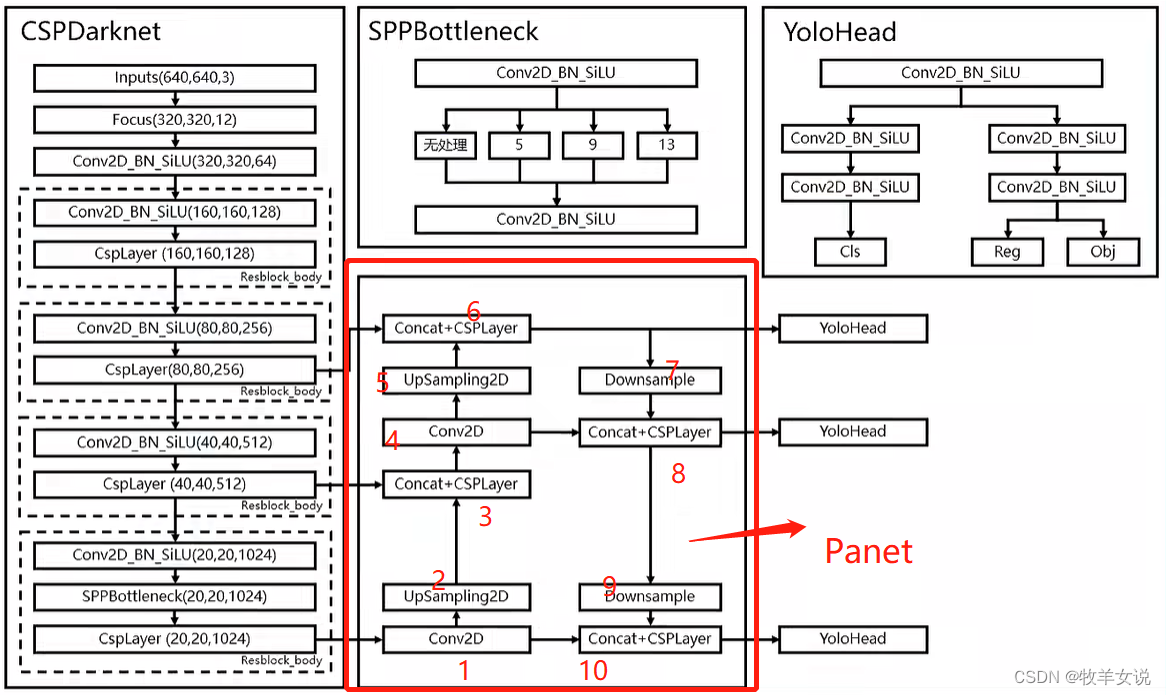
YOLOX加强特征提取网络Panet分析
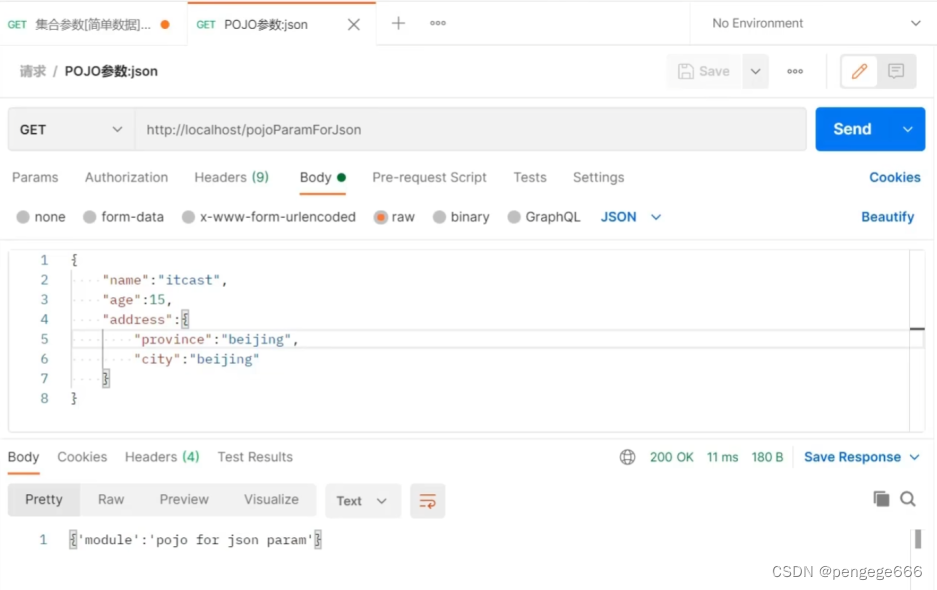
JSON数据传递参数

RuntimeError: no valid convolution algorithms available in CuDNN

Fusion de la conversion et de la normalisation des lots

LINQ usage collection in C #

基于OpenCV实现口罩识别
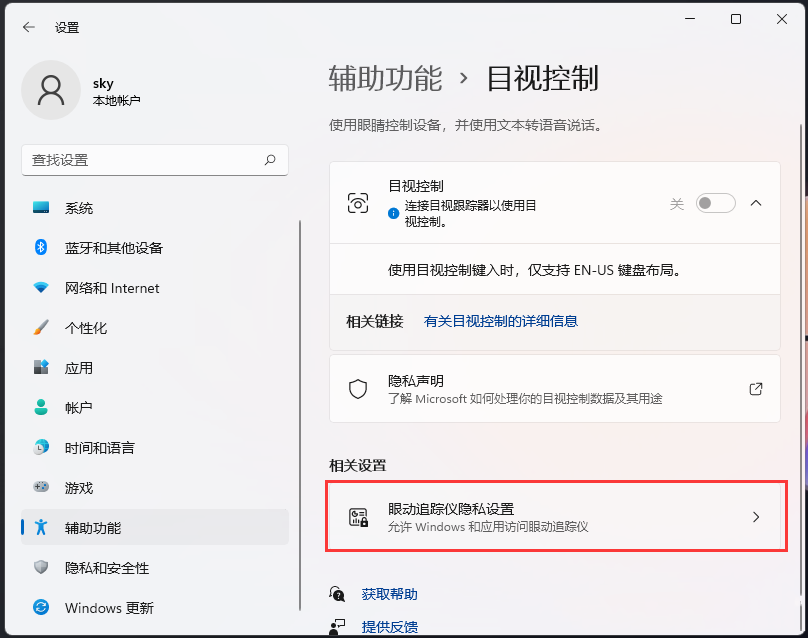
Win11如何开启目视控制?Win11开启目视控制的方法
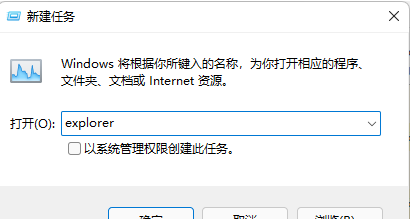
Win11系统explorer频繁卡死无响应的三种解决方法

PR FAQ, what about PR preview video card?

一文掌握基于深度学习的人脸表情识别开发(基于PaddlePaddle)
随机推荐
Fusion de la conversion et de la normalisation des lots
How difficult is it to be high? AI rolls into the mathematics circle, and the accuracy rate of advanced mathematics examination is 81%!
Convolution和Batch normalization的融合
面试过了,起薪16k
JSON data transfer parameters
How can cross-border e-commerce achieve low-cost and steady growth by laying a good data base
php 获取真实ip
Connexion à distance de la tarte aux framboises en mode visionneur VNC
What is the official website address of e-mail? Explanation of the login entry of the official website address of enterprise e-mail
非路由组件之头部组件和底部组件书写
Go basic constant definition and use
Markdown basic grammar
Three solutions to frequent sticking and no response of explorer in win11 system
[proteus simulation] 51 MCU +lcd12864 push box game
JDBC tutorial
可知论与熟能生巧
富滇银行完成数字化升级|OceanBase数据库助力布局分布式架构中台
Flexible combination of applications is a false proposition that has existed for 40 years
判断二叉树是否为满二叉树
JDBC练习案例