当前位置:网站首页>数据湖(八):Iceberg数据存储格式
数据湖(八):Iceberg数据存储格式
2022-07-06 12:44:00 【51CTO】
Iceberg数据存储格式
一、Iceberg术语
- data files(数据文件):
数据文件是Apache Iceberg表真实存储数据的文件,一般是在表的数据存储目录的data目录下,如果我们的文件格式选择的是parquet,那么文件是以“.parquet”结尾,例如:
00000-0-root_20211212192602_8036d31b-9598-4e30-8e67-ce6c39f034da-job_1639237002345_0025-00001.parquet 就是一个数据文件。
Iceberg每次更新会产生多个数据文件(data files)。
- Snapshot(表快照):
快照代表一张表在某个时刻的状态。每个快照里面会列出表在某个时刻的所有 data files 列表。data files是存储在不同的manifest files里面,manifest files是存储在一个Manifest list文件里面,而一个Manifest list文件代表一个快照。
- Manifest list(清单列表):
manifest list是一个元数据文件,它列出构建表快照(Snapshot)的清单(Manifest file)。这个元数据文件中存储的是Manifest file列表,每个Manifest file占据一行。每行中存储了Manifest file的路径、其存储的数据文件(data files)的分区范围,增加了几个数文件、删除了几个数据文件等信息,这些信息可以用来在查询时提供过滤,加快速度。
- Manifest file(清单文件):
Manifest file也是一个元数据文件,它列出组成快照(snapshot)的数据文件(data files)的列表信息。每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、文件的大小以及文件里面数据行数等信息。其中列级别的统计信息可以在扫描表数据时过滤掉不必要的文件。
Manifest file是以avro格式进行存储的,以“.avro”后缀结尾,例如:8138fce4-40f7-41d7-82a5-922274d2abba-m0.avro。
二、表格式Table Format
Apache Iceberg作为一款数据湖解决方案,是一种用于大型分析数据集的开放表格式(Table Format),表格式可以理解为元数据及数据文件的一种组织方式。Iceberg底层数据存储可以对接HDFS,S3文件系统,并支持多种文件格式,处于计算框架(Spark、Flink)之下,数据文件之上。

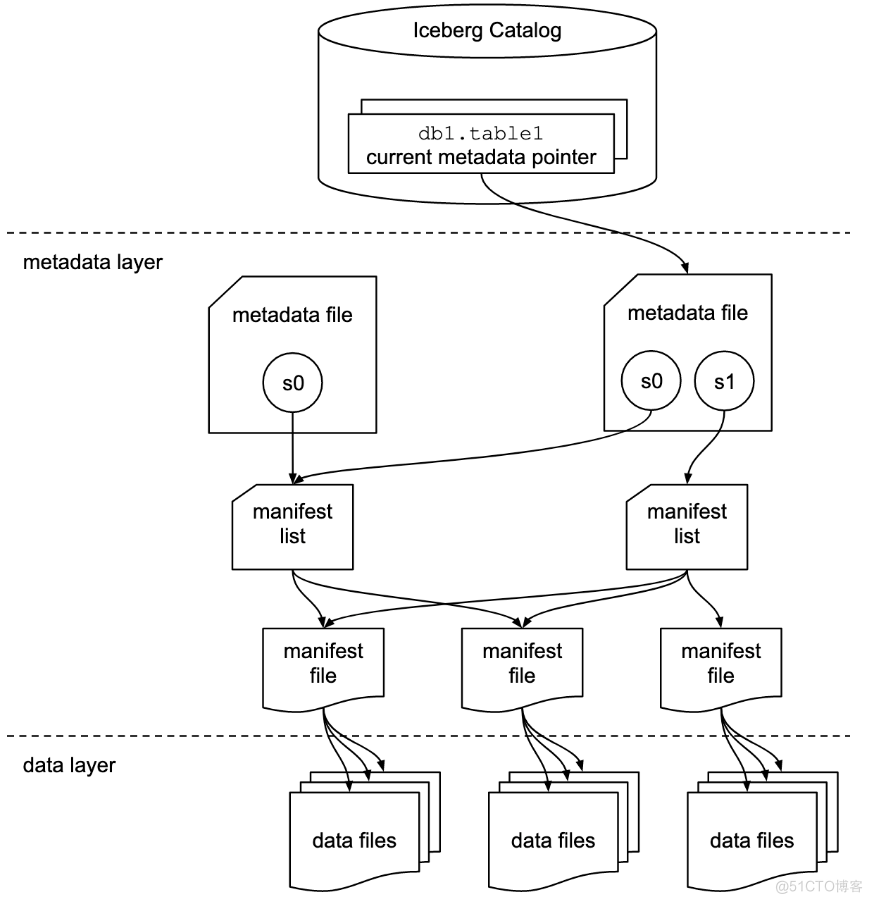
下面介绍下Iceberg底层文件组织方式,下图是Iceberg中表格式,s0、s1代表的是表Snapshot信息,每个表示当前操作的一个快照,每次commit都会生成一个快照Snapshot,每个Snapshot快照对应一个manifest list 元数据文件,每个manifest list 中包含多个Manifest元数据文件,manifest中记录了当前操作生成数据所对应的文件地址,也就是data file的地址。
基于snapshot的管理方式,Iceberg能够获取表历史版本数据、对表增量读取操作,data files存储支持不同的文件格式,目前支持parquet、ORC、Avro格式。

关于Iceberg表数据底层组织详细信息,可关注后面得文章,会详细讲解的。
边栏推荐
- OSPF多区域配置
- Can novices speculate in stocks for 200 yuan? Is the securities account given by qiniu safe?
- 全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
- Tips for web development: skillfully use ThreadLocal to avoid layer by layer value transmission
- OAI 5G NR+USRP B210安装搭建
- Detailed explanation of knowledge map construction process steps
- use. Net drives the OLED display of Jetson nano
- OLED屏幕的使用
- Leetcode hot topic Hot 100 day 32: "minimum coverage substring"
- Redis insert data garbled solution
猜你喜欢
![[DSP] [Part 1] start DSP learning](/img/81/051059958dfb050cb04b8116d3d2a8.png)
[DSP] [Part 1] start DSP learning
请问sql group by 语句问题
![[weekly pit] information encryption + [answer] positive integer factorization prime factor](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[weekly pit] information encryption + [answer] positive integer factorization prime factor
1_ Introduction to go language

知识图谱构建流程步骤详解
What is the problem with the SQL group by statement

15million employees are easy to manage, and the cloud native database gaussdb makes HR office more efficient

Spark SQL chasing Wife Series (initial understanding)
电子游戏的核心原理
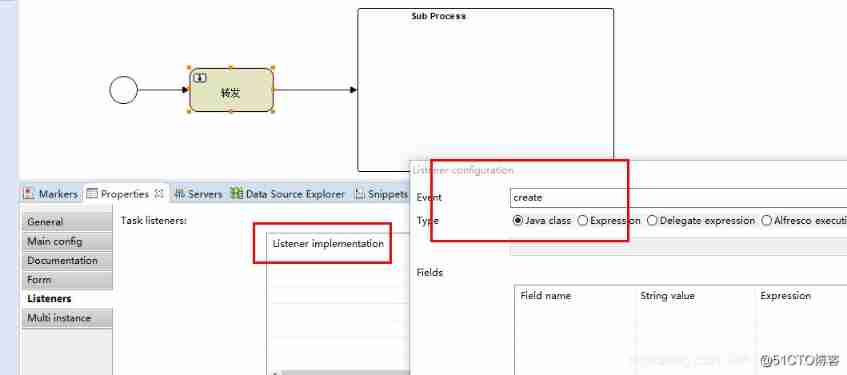
Activiti global process monitors activitieventlistener to monitor different types of events, which is very convenient without configuring task monitoring in acitivit
随机推荐
[weekly pit] calculate the sum of primes within 100 + [answer] output triangle
Infrared thermometer based on STM32 single chip microcomputer (with face detection)
2022 Guangdong Provincial Safety Officer C certificate third batch (full-time safety production management personnel) simulation examination and Guangdong Provincial Safety Officer C certificate third
Huawei device command
use. Net drives the OLED display of Jetson nano
OLED屏幕的使用
Kubernetes learning summary (20) -- what is the relationship between kubernetes and microservices and containers?
Function optimization and arrow function of ES6
PHP online examination system version 4.0 source code computer + mobile terminal
1500万员工轻松管理,云原生数据库GaussDB让HR办公更高效
【微信小程序】运行机制和更新机制
What is the difference between procedural SQL and C language in defining variables
性能测试过程和计划
Entity alignment two of knowledge map
Performance test process and plan
【DSP】【第一篇】开始DSP学习
Review questions of anatomy and physiology · VIII blood system
什么是RDB和AOF
The mail command is used in combination with the pipeline command statement
Boder radius has four values, and boder radius exceeds four values