当前位置:网站首页>CVPR 2022 | greatly reduce the manual annotation required for zero sample learning. Mapu and Beiyou proposed category semantic embedding rich in visual information
CVPR 2022 | greatly reduce the manual annotation required for zero sample learning. Mapu and Beiyou proposed category semantic embedding rich in visual information
2022-06-30 11:25:00 【PaperWeekly】

author | Beijing University of Posts and telecommunications 、 Maphouse
source | Almost Human
From Beijing University of Posts and telecommunications 、 Researchers from Mapu Institute and other institutions put forward Category embedding mining network , It improves the completeness of category embedding in visual space , It plays an important role in promoting knowledge transfer between categories in zero sample learning .
Zero sample learning aims to imitate human reasoning process , Using knowledge of visible categories , Identify invisible categories without training samples . Category embedding (class embeddings) It is a vector that describes category semantics and visual features , It can realize the transfer of knowledge between categories , Therefore, it plays an irreplaceable role in zero sample learning .

▲ Zero sample classification diagram
As shown in the figure above , Because of attributes (attributes) Can be shared by different categories , Promote the transfer of knowledge between categories , Therefore, it is the most widely used category embedding . And in other computer vision tasks ( Such as face recognition 、 Fine grained classification 、 Fashion trend forecast ) Is widely used as auxiliary information .
However, the process of attribute annotation requires a lot of manpower input and expert knowledge , It limits the expansion of zero sample learning on new data sets . Besides , Limited by human cognitive limitations , Its labeled attributes cannot traverse the visual space , Therefore, some distinguishing features in the image cannot be captured by attributes , Result in poor learning effect of zero samples .
For the above problems , From Beijing University of Posts and telecommunications 、 Researchers from Mapu Institute and other institutions have proposed category embedding mining network (Visually-Grounded Semantic Embedding Network, VGSE), This article mainly answers two questions :1) How to automatically discover category embedding with semantic and visual features from visible class images ;2) How to... Without training samples , Forecast category embedding for invisible categories .

Paper title :
VGSE: Visually-Grounded Semantic Embeddings for Zero-Shot Learning
Thesis link :
https://arxiv.org/abs/2203.10444
Thesis link :
https://github.com/wenjiaXu/VGSE
In order to fully mine the shared visual features among different categories ,VGSE The model clusters a large number of local image slices according to their visual similarity to form attribute clusters , Summarize the visual features shared by different categories of instances from the underlying features of the image . Besides VGSE The model proposes the category relation module , Learning category relationships with the help of a small number of external knowledge sources , Ability to transfer knowledge from source category to target category , Predict class embedding for target classes without training images .
Compared with other attributes obtained from corpus based automatic mining ,VGSE Model in CUB、SUN、AWA2 Very competitive results are obtained on the zero sample classification dataset . As shown in the figure below , This paper can explore the visual features that are complementary to the manual annotation attributes , Improve the completeness of category embedding in visual space , It plays an important role in promoting knowledge transfer between categories in zero sample learning . This paper has been published by CVPR 2022 Employment .


Category embedded mining model
Category embedded mining model VGSE The flow of the algorithm is shown below , The model is mainly composed of two modules :(1) Slice clustering module (Patch Clustering, PC) Take training data set as input , Cluster image slices into different clusters .(2) Category relation module (Class Relation, CR) Semantic embedding for predicting invisible classes .

▲ VGSE Model structure
1.1 Slice clustering module
Because attributes usually appear in local areas of the image , For example, animal body parts 、 The shape and texture of objects in the scene , Therefore, this paper proposes to use the clustering of image local slices to explore visual attribute clusters . In order to get the information that covers the whole semantic image area ( For example, animal head ) The image block of , The slice clustering module adopts the unsupervised compact watershed segmentation algorithm [4] Divide the image into regular shaped areas , Then the visual similarity of image slices is used for clustering .
The slice clustering module is a differentiable deep neural network , Given image slice , The network first extracts the features of the image , Then through the clustering layer Predict the probability that the feature will be predicted in each attribute cluster :

In this paper, the clustering loss function based on visual similarity is used to train the clustering network . Force image slicing And its similar slice sets are clustered into the same attribute cluster :

In order to enhance the discrimination of category embedding , So that it can distinguish the significant differences between categories , This paper proposes adding discernibility information , By learning the full connectivity layer , The prediction of each picture is mapped to its category prediction probability , Then the cross entropy loss training model is used :

This article aims to learn about attribute clusters shared between categories , Promote the transfer of knowledge between categories , Therefore, attribute clusters are encouraged to contain semantic links between categories . To achieve this goal , By learning the full connectivity layer S, Map the embedding of each picture to the semantic tags of the category ( Use the... Of the category name here w2v vector ). And then through the regression loss training model , To strengthen the semantic connection of category embedding :

Final , The image embedding of a complete image is calculated by averaging the embedding of all slices in the image :

And the category The embedding of is obtained by averaging all the images of this class :

1.2 Category relation module
The embedding of visible classes can be predicted by the slice clustering module . But in reality, there are a lot of invisible classes , Its category embedding cannot be predicted by image . Because semantically related categories usually share some attributes , For example, pandas and zebras share “ Black and white “ attribute , Both elk and bull contain “ horn ” This property . This section proposes to learn the semantic similarity between visible and invisible classes , And predict the embedding of invisible classes through semantically related visible classes . Any external semantic knowledge , for example w2v、glove And other category semantic embedded or manually annotated attributes , Can be used to learn the relationship between two classes . Below to w2v An example is given to illustrate the proposed class relation mining module .
For a given visible class w2v Semantic label , And the semantic tags of invisible categories , In this section, you learned about similarity mapping , Where represents the similarity between the target class and the source class . Similarity mapping is learned through the following optimization problems :

among , The attribute value of the target category is the weighted sum of all the attribute values of the source category .

experimental result
In this paper, three general zero sample classification datasets (CUB、AWA2、SUN) To verify the effectiveness of the proposed method .
The figure below shows AWA2 Attribute clusters learned from data sets . We will 10,000 The embedding and utilization of image slices t-SNE Map to 2D space . This paper samples several attribute clusters ( Use dots of the same color ) The image slices from the attribute cluster are marked in the figure .

▲ Mining attribute cluster visualization results
The data in the figure illustrates the following points : First , It can be observed that image slices in the same cluster tend to cluster together , And convey a consistent visual message , This indicates that image embedding provides discernible information . Besides , Almost all attribute clusters contain image slices from multiple categories . for example , Stripes from different animals , Although the color is slightly different, the texture is similar . This phenomenon shows that the category embedding studied in this paper contains the information shared between classes . Another interesting observation is , The model proposed in this paper can find the visual attributes neglected by human annotation , It can enhance the visual completeness of human annotation attributes .
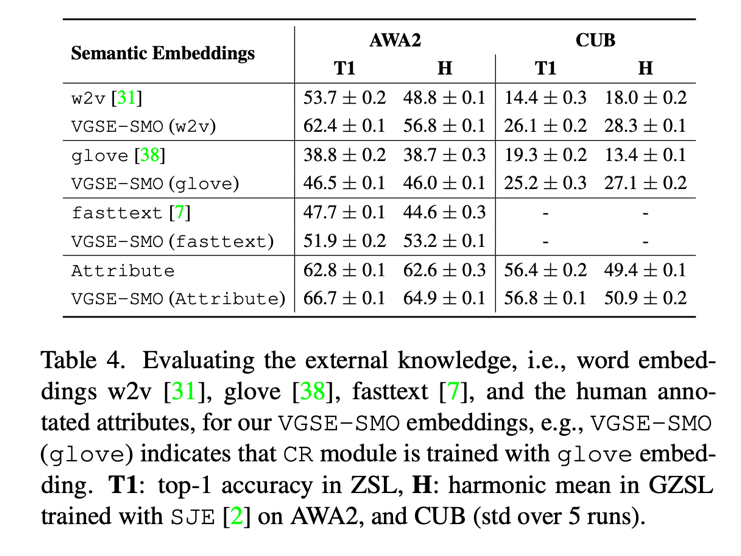
Table 1 It shows the class embedding VGSE-SMO With category w2v The representation of vectors on three data sets . To test the ability to embed two categories , We f-VAEGAN-D2[5] And so on , The results show that the category embedding proposed in this paper can greatly surpass w2v The performance of vectors .
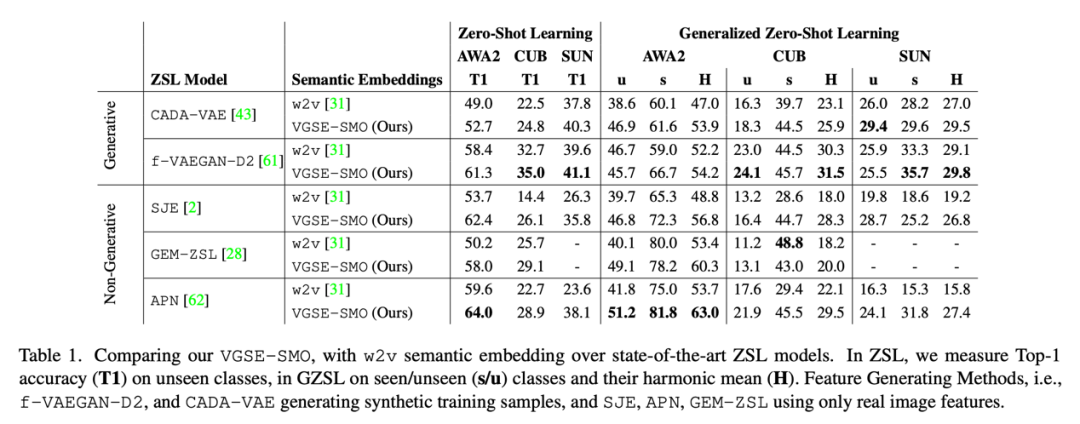
Table 2 In the task of zero sample classification, the effects of category embedding proposed in this paper and several other methods of corpus attribute mining are compared , The results show that the method in this paper only uses w2v In the case of vectors , The effect is better than other methods using online corpus .
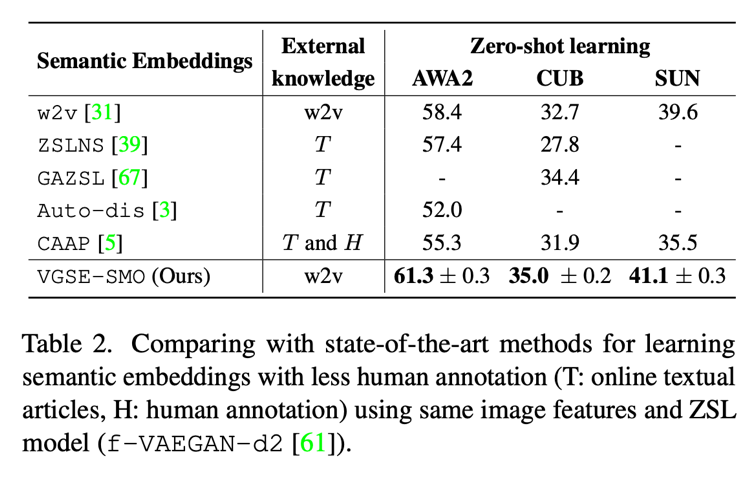
As mentioned earlier , The class relation module proposed in this paper can use a variety of external semantic knowledge to learn class similarity ,Table 4 Shows the effect of using different semantic knowledge .
This paper investigates the semantic consistency and visual consistency of the category embedding . Random selection 50 Attribute clusters , And show the 30 A picture . The user is first asked to view an example image of the attribute cluster . Then answer the following questions to measure the effect of attribute clusters .

▲ User survey interface
It turns out that , stay 88.5% and 87.0% Under the circumstances , Users think that the attribute clusters mined by this method convey consistent visual and semantic information .

summary
To reduce the manual annotation required for zero sample learning , Improve the semantic and visual completeness of category embedding , This paper presents an automatic class embedding mining network VSGE Model , It can use the visual similarity of image slices to explore category embedding . The results on three datasets show that , The class embedding scheme proposed in this paper can effectively improve the quality of semantic embedding , And it can mine fine-grained attributes that are difficult for human beings to label . Besides playing an important role in zero sample learning , The category embedding proposed in this paper can also provide new ideas for other attribute related research .

reference
[1] Al-Halah, Ziad, and Rainer Stiefelhagen. "Automatic discovery, association estimation and learning of semantic attributes for a thousand categories." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
[2] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Proceedings of the Advances in neural information processing systems. 2013.
[3] Wang, Xiaolong, Yufei Ye, and Abhinav Gupta. "Zero-shot recognition via semantic embeddings and knowledge graphs." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Neubert, Peer, and Peter Protzel. "Compact watershed and preemptive slic: On improving trade-offs of superpixel segmentation algorithms." Proceedings of the IEEE International Conference on Pattern Recognition. 2014.
[5] Xian, Yongqin, et al. "f-vaegan-d2: A feature generating framework for any-shot learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- 数字化不是试出来,而是蹚出来的|行知数字中国 × 富士康史喆
- Mathematics (fast power)
- [IC5000 tutorial] - 01- use daqdea graphical debug to debug C code
- Handler source code analysis
- AMS源码解析
- How harmful are these "unreliable" experiences in the postgraduate entrance examination?
- The jetpack compose dropdownmenu is displayed following the finger click position
- It's time for the kotlin coroutine to schedule thread switching to solve the mystery
- 100 important knowledge points that SQL must master: creating and manipulating tables
- Understanding society at the age of 14 - reading notes on "happiness at work"
猜你喜欢
相对位置编码Transformer的一个理论缺陷与对策

Jetpack Compose DropdownMenu跟随手指点击位置显示

Wireguard simple configuration

Methods and usage of promise async and await

中移OneOS开发板学习入门

Wechat Emoji is written into the judgment, and every Emoji you send may become evidence in court

Cp2112 teaching example of using USB to IIC communication
![When does the database need to use the index [Hangzhou multi surveyors] [Hangzhou multi surveyors _ Wang Sir]](/img/2a/f07a7006e0259d78d046b30c761764.jpg)
When does the database need to use the index [Hangzhou multi surveyors] [Hangzhou multi surveyors _ Wang Sir]

Oceanbase installation Yum source configuration error and Solutions

达梦数据冲刺科创板,或成A股市场“国产数据库第一股”
随机推荐
Go语言学习之Switch语句的使用
Iptables target tproxy
DataX JSON description
一个人就是一本书
暑假学习记录
promise async和await的方法与使用
Multiparty Cardinality Testing for Threshold Private Set-2021:解读
LeetCode Algorithm 86. 分隔链表
SQL必需掌握的100个重要知识点:插入数据
LiveData源码赏析三 —— 常见问题
Introduction to game theory
100 important knowledge points that SQL must master: updating and deleting data
Kotlin 协程调度切换线程是时候解开谜团了
win10 R包安装报错:没有安装在arch=i386
什么是微信小程序,带你推开小程序的大门
R语言查看版本 R包查看版本
Kongsong (ICT Institute) - cloud security capacity building and trend in the digital age
WireGuard简单配置
dplyr 中的filter报错:Can‘t transform a data frame with duplicate names
IDEA 又出新神器,一套代码适应多端!