当前位置:网站首页>HIRO: Hierarchical Reinforcement Learning 】 【 Data - Efficient Hierarchical Reinforcement Learning
HIRO: Hierarchical Reinforcement Learning 】 【 Data - Efficient Hierarchical Reinforcement Learning
2022-08-01 01:36:00 【little handsome acridine】
Paper Title: Data-Efficient Hierarchical Reinforcement Learning
Authors: Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, Sergey Levine
Published by: NeurIPS 2018
Summary
Hierarchical reinforcement learning (HRL) is a promising approach to extending traditional reinforcement learning (RL) methods to solve more complex tasks.Most current HRL methods require careful task-specific design and policy training, which makes them difficult to apply to real-world scenarios.In this paper, we examine how to develop general HRL algorithms because they do not make onerous additional assumptions beyond standard RL algorithms and are efficient because they can be used with a modest number of interaction samples, making themIt is suitable for real-world problems such as robot control.For generality, we develop a scheme in which the low-level controller is automatically learned and supervised by the proposed objective by the high-level controller.To improve efficiency, we recommend using off-policy experience in both high-level and low-level training.This poses a considerable challenge, as changes in lower-level behavior can alter the action space for higher-level policies, and we introduce a type of Off-Policy Corrections to address this challenge.This allows us to take advantage of recent advances in off-policy
model-free RL to learn higher-level and lower-level policies using much less environment interaction than on-policy algorithms.We called the generated HRL proxy HIRO and found it to be generally applicable and sample efficient.Our experiments show that HIRO can be used to learn to simulate highly complex behaviors of robots, such as pushing objects and using them to reach target locations, learning from millions of samples, equivalent to days of real-time interactions.Compared with many previous HRL methods, we find that our method outperforms the previous state-of-the-art by a large margin.
Algorithmic Framework


Internal Rewards
where the high-level policy produces a target gt indicating the desired relative change in state observations.That is, at step t, the high-level policy produces a goal gt, indicating that it expects the lower-level agent to take action, producing an observation st+c that is close to st+gt.Although some state dimensions are more natural as target subspaces, we choose this more general goal representation to have broad applicability without the need to manually design the target space, primitives, or controllable dimensions. This makes ourThe method is general and applicable to new problem settings.
In order to maintain the same absolute position of the target regardless of the state change, the target transition model h is defined as

Define intrinsic reward as based on current observation and target observationA parameterized reward function for the distance between: 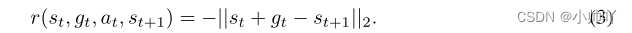
aboveThis reward function targets low-level policies for taking actions that yield observations close to the expected value st + gt.
Lower-level policies can be trained using standard methods by simply incorporating gt as an additional input into the value and policy models.For example, in DDPG, low-level criticism is achieved by minimizing the error of the following equation: 
The policy actor is updated with:
Off-Policy Corrections for Higher-Level Training
What is the non-stationarity problem?


Here my understanding is that by modifying the target in the transition, when encountering the same state, the underlying strategy will eventuallyThe resulting result passed to the upper layer is consistent with the result passed to the upper layer when this state was encountered before.
Reference:
https://zhuanlan.zhihu.com/p/86602304
HIRO's pytorch code: https://github.com/watakandai/hiro_pytorch
边栏推荐
猜你喜欢

Summary of MVCC

ECCV2022 Workshop | Multi-Object Tracking and Segmentation in Complex Environments

Compiled on unbutu with wiringPi library and run on Raspberry Pi

leetcode:1562. 查找大小为 M 的最新分组【模拟 + 端点记录 + 范围合并】

ROS2系列知识(4): 理解【服务】的概念

RTL8762DK 点灯/LED(三)
Blueprint: Yang Hui's Triangular Arrangement
ECCV2022 Workshop | 复杂环境中的多目标跟踪和分割
Data Middle Office Construction (VII): Data Asset Management
解决安装MySQL后,Excel打开很慢的问题
随机推荐
Daily practice of LeetCode - Circular linked list question (interview four consecutive questions)
IDEA 找不到或无法加载主类 或 Module “*“ must not contain source root “*“ The root already belongs to module “*“
RTL8762DK PWM(七)
leetcode: 1648. Color ball with decreasing sales value [Boundary find by two points]
Introduction to machine learning how to?
GDB 源码分析系列文章五:动态库延迟断点实现机制
High dimensional Gaussian distribution basics
[Data analysis] Based on matlab GUI student achievement management system [including Matlab source code 1981]
七月集训(第31天) —— 状态压缩
OSF一分钟了解敏捷开发模式
MYSQL逻辑架构
Simple vim configuration
GDB source code analysis series of articles five: dynamic library delay breakpoint implementation mechanism
OSD读取SAP CRM One Order应用日志的优化方式
【Cryptography/Cryptanalysis】Cryptanalysis method based on TMTO
Flink 部署和提交job
Unity3D study notes 10 - texture array
北京突然宣布,元宇宙重大消息
Basic implementation of vector
【 】 today in history: on July 31, "brains in vats" the birth of the participant;The father of wi-fi was born;USB 3.1 standard