当前位置:网站首页>Optimization of aggregate mentioned at DATA AI Summit 2022
Optimization of aggregate mentioned at DATA AI Summit 2022
2022-07-31 00:14:00 【Hongnai riverside bird】
Background
This article is based on SPARK 3.3.0
Optimization of HashAggregate
This optimization is an internal optimization of FaceBook(Meta) and merged into the spark community.
The main part of this optimization is the partialaggregate part: for the aggregation operations such as count, sum, and Avg, there will be a partial aggregation operation performed by the mapper, and then the FinalAggregate operation will be performed on the reduce side.This seems to be no problem (it can reduce network IO very well), but we know that for aggregation operations, we will perform data spill operations. If the data merged in the mapper stage is so small that it cannot offset the network IO bandIf the consumption comes, this will undoubtedly bring loss to the task.

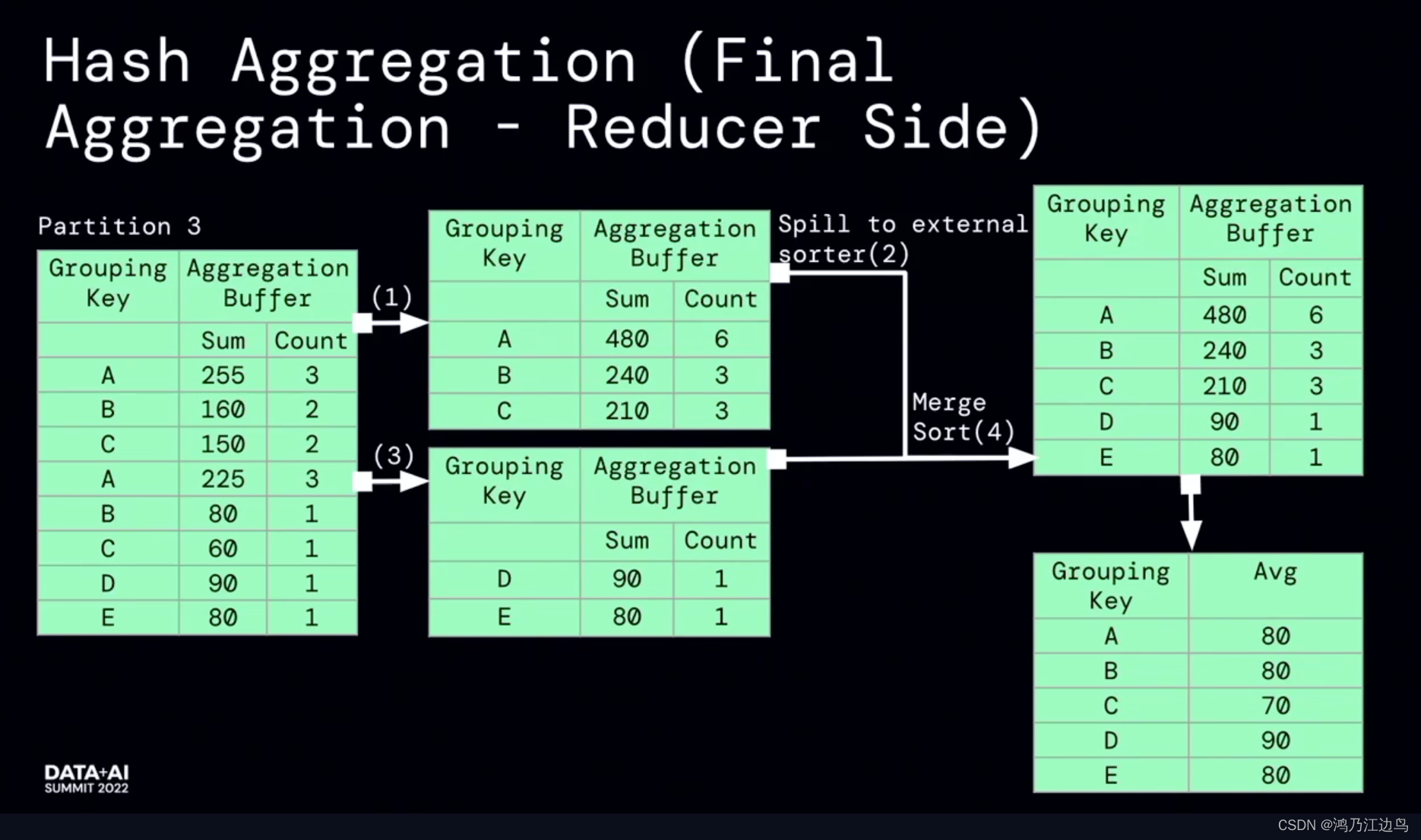

Use runtime metrics information, can achieve a better acceleration effect.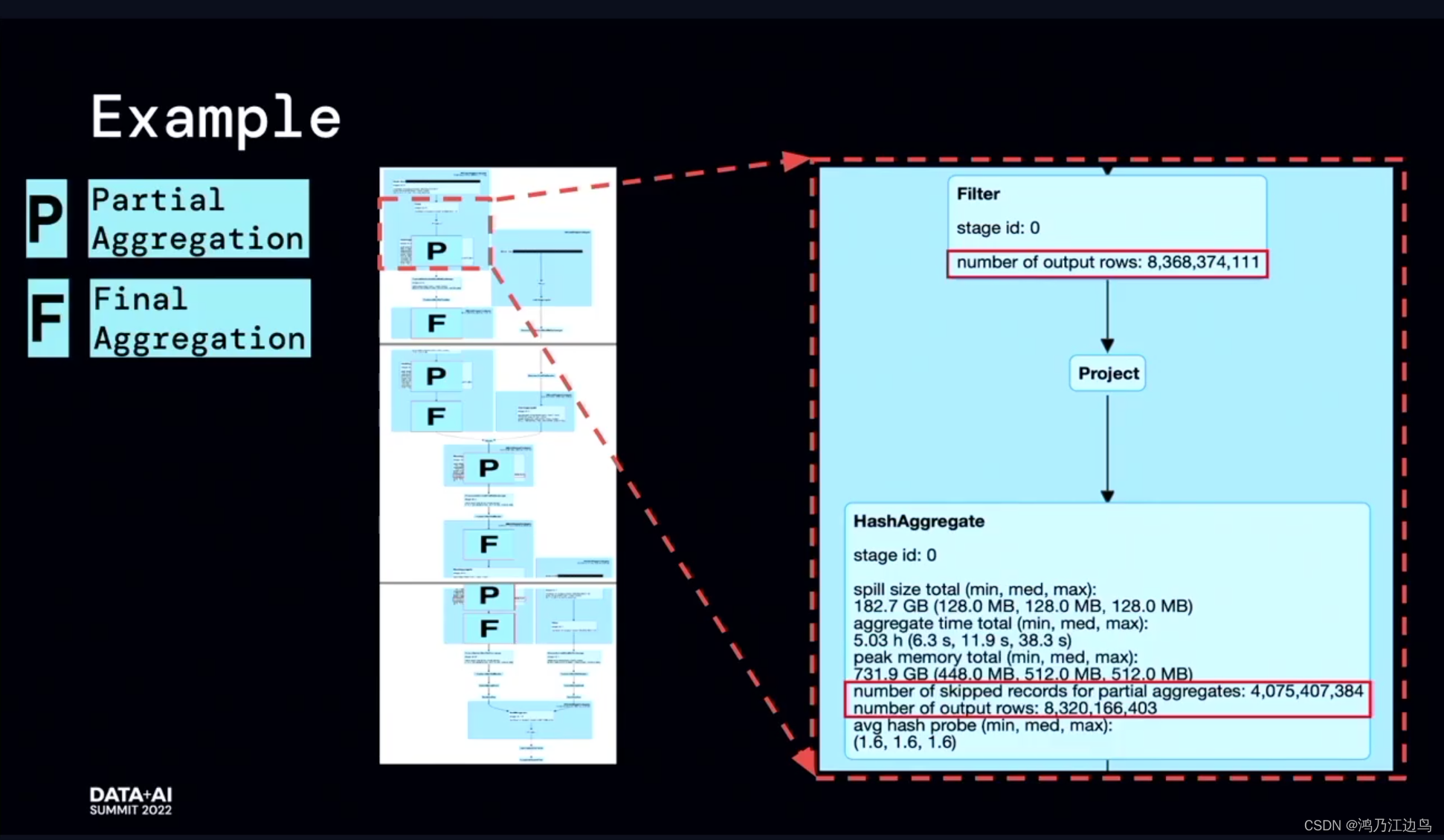
Optimization of ObjectHashAggregate
For the principle of ObjectHashAggregate, you can refer to for an in-depth understanding of HashAggregateExec and ObjectHashAggregateExec and UnsafeRow in SPARK SQL.This article can clearly explain the difference between ObjectHashAggregate and HashAggregate:
- ObjectHashAggregate can make up for HashAggregate's inability to support expressions such as collect_set, so it will not be converted to SortAggregate
- ObjectHashAggregate uses java Array object (SpecificInternalRow) to save the intermediate buffer of aggregation, which is not very friendly to jvm gc
- ObjectHashAggregate performs spill based on the size of the hashMap (128 by default), not the number of input rows, which will lead to early spill and low memory utilization.
- Due to the early spill, ObjectHashAggregate will perform an additional sorting operation on all the remaining data (if there is no spill, no additional sorting operation is required), while HashAggregate will sort the data that needs to be spilled each time
Use the memory usage of the jvm heap and the number of rows processed to guide when to start spill.
However, in the case of skewed data, it will increase the risk of OOM.
SortAggregate Optimization
The current status of SortAggreaget is:
- Each task needs to be sorted by key before sort Aggregate
- According to the sorted result, perform aggregation operation between adjacent rows
Different from Hash Aggregate: - There is no need for hashTable, so there is no memory overflow and fallback to sortAggregate
- Optimizer prefers to choose hashAggregate
- No codegen implementation.
Currently added features in spark 3.3.0:
- If the data is ordered, it will choose to use sortAggragate instead of HashAggregate
through the physical plan RuleReplaceHashWithSortAggto do the replacement, of course throughspark.sql.execution.replaceHashWithSortAggto turn it on (off by default), because for any new feature, it is turned off by default in the release version, and it is turned on in the master branch - Support codegen code generation for sortAggretate (without keys)
Other
For more details about Aggregate, please refer to sparksql source code series | One article to understand the execution principle of with one count distinct
边栏推荐
猜你喜欢









随机推荐
正则表达式密码策略与正则回溯机制绕过
Point Cloud Scene Reconstruction with Depth Estimation
【深入浅出玩转FPGA学习15----------时序分析基础】
Axure Carousel
background对float的子元素无效
软考学习计划
MySQL面试题
@requestmapping注解的作用及用法
Android security optimization - APP reinforcement
如何在 AWS 中应用 DevOps 方法?
uniapp折叠框二级循环
xss的绕过
Machine Learning 1-Regression Model (2)
Calico 网络通信原理揭秘
HCIP第十六天笔记
The difference between ?? and ??= and ?. and || in JS
Axure轮播图
Steven Giesel recently published a 5-part series documenting his first experience building an application with the Uno Platform.
从两个易错的笔试题深入理解自增运算符
Flex布局使用