当前位置:网站首页>Data Lake (VII): Iceberg concept and review what is a data Lake
Data Lake (VII): Iceberg concept and review what is a data Lake
2022-07-05 13:34:00 【51CTO】
Iceberg Concept and review what a data lake is
One 、 Review what a data lake is
Data lake is a centralized repository , Allows you to store multiple sources at any size 、 All structured and unstructured data , Data can be stored as is , No need to process structured data , And run different types of analysis , Process the data , for example : Big data processing 、 Real time analysis 、 machine learning , To guide better decisions .
Two 、 Why does big data need data lake
Currently based on Hive Our offline data warehouse is very mature , It is very troublesome to update the record level data in the traditional offline data warehouse , The entire partition to which the data to be updated belongs , Even the whole table can be covered completely , Due to the architecture design of multi-level layer by layer processing of off-line data warehouse , When updating data, it also needs to be reflected layer by layer from the paste source layer to the subsequent derived tables .
With the continuous development of real-time computing engine and business demand for real-time report output continues to expand , In recent years, the industry has been focusing on and exploring the construction of real-time warehouse . According to the evolution process of data warehouse architecture , stay Lambda The architecture includes two links: offline processing and real-time processing , The architecture is shown below :
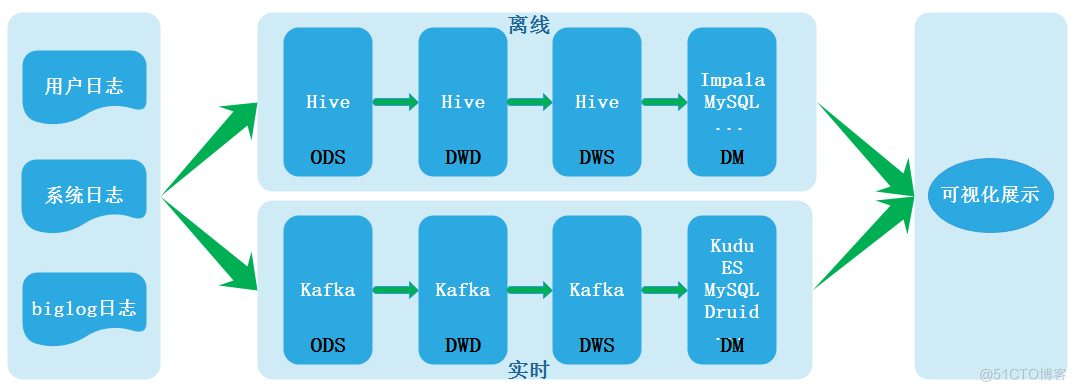
 edit
edit
It is precisely because the two links process data, resulting in data inconsistency and other problems, so there is Kappa framework ,Kappa The structure is as follows :
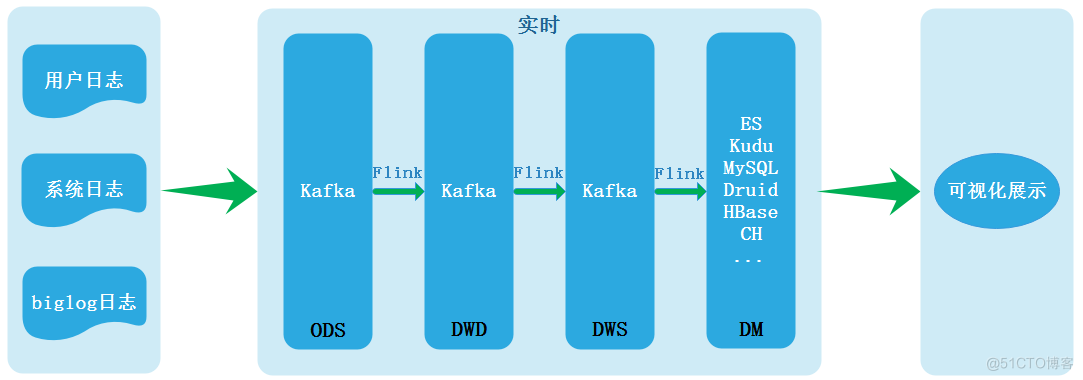
 edit
edit
Kappa Architecture can be called real-time data warehouse , At present, the most commonly used implementation in the industry is Flink + Kafka, However, based on Kafka+Flink The real-time data warehouse scheme also has several obvious defects , Therefore, in many enterprises, hybrid architecture is often used in the construction of real-time data warehouse , Not all businesses adopt Kappa Implementation of real-time processing in the architecture .Kappa The architecture defects are as follows :
- Kafka Can't support massive data storage . For lines of business with massive amounts of data ,Kafka Generally, it can only store data for a very short time , Like the last week , Even the last day .
- Kafka Can't support efficient OLAP Inquire about , Most businesses want to be in DWD\DWS Layer supports ad hoc queries , however Kafka It's not very friendly to support such a demand .
- It is impossible to reuse the mature data consanguinity based on offline data warehouse 、 Data quality management system . We need to re implement a set of data consanguinity 、 Data quality management system .
- Kafka I won't support it update/upsert, at present Kafka Support only append.
In order to solve Kappa The pain point of Architecture , The mainstream in the industry is to adopt “ Batch flow integration ” The way , Here, the integration of batch and stream can be understood as the use of batch and stream SQL Same processing , It can also be understood as the unification of processing framework , for example :Spark、Flink, But what's more important here is the unity on the storage layer , As long as you do it at the storage level “ Batch flow integration ” Can solve the above Kappa All kinds of problems . Data Lake technology can well realize the storage level “ Batch flow integration ”, This is why data lake is needed in big data .
3、 ... and 、Iceberg Concept and characteristics
1、 Concept
Apache Iceberg It is an open table format for large-scale data analysis scenarios (Table Format).Iceberg Use a method similar to SQL High performance table format for tables ,Iceberg The format form table can store tens of PB data , adapter Spark、Trino、PrestoDB、Flink and Hive And other computing engines provide high-performance read-write and metadata management functions ,Iceberg Is a data Lake solution .
Be careful :Trino It's the original PrestoSQL ,2020 year 12 month 27 Japan ,PrestoSQL The project was renamed Trino,Presto Split into two branches :PrestoDB、PrestorSQL.
2、 characteristic
Iceberg Very lightweight , It can be used as lib And Spark、Flink To integrate
Iceberg Official website : https://iceberg.apache.org/
Iceberg It has the following characteristics :
- Iceberg Support real-time / Batch data writing and reading , Support Spark/Flink Calculation engine .
- Iceberg Support transactions ACID, Support adding 、 Delete 、 Update data .
- Do not bind any underlying storage , Support Parquet、ORC、Avro The format is compatible with row storage and column storage .
- Iceberg Support hidden partition and partition change , Facilitate business data partition strategy .
- Iceberg Support repeated query of snapshot data , With version rollback function .
- Iceberg The scan plan is fast , Reading tables or querying files can be done without the need for distributed SQL engine .
- Iceberg Efficiently filter queries through table metadata .
- Concurrency support based on optimistic locking , Provide multi-threaded concurrent writing capability and ensure linear consistency of data .
边栏推荐
猜你喜欢

Android本地Sqlite数据库的备份和还原
STM32 reverse entry

“百度杯”CTF比赛 九月场,Web:SQL

CAN和CAN FD
Write API documents first or code first?

法国学者:最优传输理论下对抗攻击可解释性探讨
![[深度学习论文笔记]UCTransNet:从transformer的通道角度重新思考U-Net中的跳跃连接](/img/b6/f9da8a36167db10c9a92dabb166c81.png)
[深度学习论文笔记]UCTransNet:从transformer的通道角度重新思考U-Net中的跳跃连接

Asemi rectifier bridge hd06 parameters, hd06 pictures, hd06 applications
FPGA 学习笔记:Vivado 2019.1 添加 IP MicroBlaze
Shandong University Summer Training - 20220620
随机推荐
时钟周期
从外卖点单浅谈伪需求
My colleague didn't understand selenium for half a month, so I figured it out for him in half an hour! Easily showed a wave of operations of climbing Taobao [easy to understand]
MySQL --- 数据库查询 - 排序查询、分页查询
蜀天梦图×微言科技丨达梦图数据库朋友圈+1
【Hot100】34. Find the first and last positions of elements in a sorted array
Godson 2nd generation burn PMON and reload system
The "Baidu Cup" CTF competition was held in February 2017, Web: explosion-2
Personal component - message prompt
Idea设置方法注释和类注释
Could not set property 'ID' of 'class xx' with value 'XX' argument type mismatch solution
MySQL - database query - sort query, paging query
MATLAB论文图表标准格式输出(干货)
APICloud Studio3 API管理与调试使用教程
[深度学习论文笔记]UCTransNet:从transformer的通道角度重新思考U-Net中的跳跃连接
Go string operation
go 指针
MMSeg——Mutli-view时序数据检查与可视化
使用Dom4j解析XML
个人组件 - 消息提示