当前位置:网站首页>From concept to method, the statistical learning method -- Chapter 3, k-nearest neighbor method
From concept to method, the statistical learning method -- Chapter 3, k-nearest neighbor method
2022-07-02 09:11:00 【Qigui】
Individuality signature : The most important part of the whole building is the foundation , The foundation is unstable , The earth trembled and the mountains swayed .
And to learn technology, we should lay a solid foundation , Pay attention to me , Take you to firm the foundation of the neighborhood of each plate .
Blog home page : Qigui's blog
special column :《 Statistical learning method 》 The second edition —— Personal notes
From the south to the North , Don't miss it , Miss this article ,“ wonderful ” May miss you la
Triple attack( Three strikes in a row ):Comment,Like and Collect--->Attention
K- Nearest neighbor algorithm (KNN) It is a simple model for regression tasks and classification tasks . Neighbors are used to estimate a test case ( Unclassified samples ) Corresponding response variable value . Hyperparametric k Used to specify how many neighbors should be included in the estimation process . Hyperparametric k It is a parameter used to control how the algorithm learns , It is not estimated by training data , Samples need to be specified manually . Last , The algorithm passes some distance function , Select from the feature space k Neighbors closest to the test instance .
For the classification problem : For new samples , According to its 𝑘 The category of the nearest neighbor training samples , To predict by a majority vote, etc .
For the return question : For new samples , According to its 𝑘 The mean value of the label value of the nearest neighbor training sample is used as the prediction value .
KNN The model does not estimate a fixed number of model parameters from the training data k, It will store all training instances , And use the instance closest to the test instance to predict the response variables .
One 、k Nearest neighbor algorithm
Given a training data set , For new input instances , Find the closest neighbor to the instance in the training dataset k An example , this k Most of the instances belong to a class , The input instance is divided into this class . and k The special case of neighborhood law is k=1 The circumstances of , Called nearest neighbor algorithm . For the input instance point ( Eigenvector )x, The nearest neighbor method sets the training data to x The nearest neighbor class is used as x Class .
Basic practice : For a given training instance point and input instance point , First, determine the of the input instance point k Nearest neighbor training instance points , Then use k And the number of classes of training instance points to predict the classes of input instance points .
KNN The working principle of the algorithm is to find the classification samples with the closest distance , It can be described in one sentence :” Who lies , Who keeps company with the wolf will learn to howl “.KNN The whole algorithm is divided into three steps : First of all 、 Calculate the distance between the sample to be classified and other samples ; second 、 Count the nearest k Nearest neighbor point ; Third 、 about k The nearest neighbor point , Which category do they belong to the most , So what kind of sample to be classified belongs to .
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’)
- n_neighbors: By default kneighbors Number of neighbors used by query . Namely k-NN Of k Value , Pick the nearest k A little bit . Number of adjacent points , namely k The number of .( The default is 5)
- weights: The default is “uniform” It means that each nearest neighbor is assigned the same weight , That is to determine the weight of the nearest neighbor ; Can be specified as “distance” It indicates that the distribution weight is inversely proportional to the distance of the query point ; At the same time, you can also customize the weight .
- algorithm: Nearest neighbor algorithm , Optional {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}. Optional fast k Nearest neighbor search algorithm , The default parameter is auto, It can be understood that the algorithm decides the appropriate search algorithm by itself ; You can also specify your own search algorithm ball_tree、kd_tree、brute Method to search ,brute It's brute force search , That's linear scanning .
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# get data
iris = load_iris()
data = iris.data
target = iris.target
# Processing data --- Divide the data ,random_state The effect of is equivalent to random seed , It is to ensure that the training set and test set are the same for each segmentation
x_train, x_test, y_train, y_test = train_test_split(data, target, random_state=0)
# Set the number of neighbors K, namely n_neighbors Size
KNN = KNeighborsClassifier(n_neighbors=6)
# Build the model
KNN.fit(x_train, y_train)
# Evaluation model
print('score:{:.2f}'.format(KNN.score(x_test, y_test)))score:0.97Two 、k The nearest neighbor model
Three elements : Distance metric 、k Worth choosing and classification decision rules .
1、 Model
k Near neighbor method , When training set 、 Distance metric ( Such as Euclidean distance )、k Value and classification decision rules ( If majority vote ) after , For any new input instance , The class to which it belongs is uniquely certain .
In feature space , For each training instance point , All points closer to this point than others make up an area , It's called a unit . Each training instance point has a unit , The units of all training instance points constitute a division of feature space . The nearest neighbor method takes the class of the instance as the class mark of all points in its cell , thus , The category of instance points of each cell is determined .
2、 Distance metric
The distance between two sample points represents the similarity between the two samples , The greater the distance , The greater the difference ; The smaller the distance , The greater the similarity .
The distance between two instance points in feature space is a reflection of the similarity degree of two instance points .k The characteristic space of the nearest neighbor model is n Dimension real number vector space . The distance used is Euclidean distance , In addition to the Euclidean distance formula, you can calculate the distance , What other distance formulas can make ⽤? But it can also be other distances , Like more general  Distance or Minkowski distance .
Distance or Minkowski distance .
(1)、 Euclidean distance
Also known as Euclidean distance , In fact, this distance calculation formula is mathematical Two point distance Calculation formula : ( Two dimensional Euclidean distance ), Also called Euclidean distance . As follows :
( Two dimensional Euclidean distance ), Also called Euclidean distance . As follows : ( Three dimensional Euclidean distance ), So we can get the Euclidean distance between two points :
( Three dimensional Euclidean distance ), So we can get the Euclidean distance between two points : (n Dimension vector ).
(n Dimension vector ).
import numpy as np
# Calculate the Euclidean distance between two data points
def Distance(x, y, length):
distance = 0
for i in range(length):
distance += np.square(x[i] - y[i])
return np.sqrt(distance)
d = Distance([1, 2, 3], [4, 5, 6], 3)
print(d)5.196152422706632(2)、 Manhattan distance
Represents the sum of the absolute axes of two points in the standard coordinate system , The formula : .
.
x = [1, 2, 3]
y = [4, 5, 6]
print(sum(map(lambda i, j: abs(i - j), x, y)))
9(3)、 Minkowski distance and Chebyshev distance
Minkowski distance is not a strict distance, but a set of distances . The formula :![d=\sqrt[p]{\sum_{i=1}^{n}\left | x_{1}-y_{i} \right |^p}](http://img.inotgo.com/imagesLocal/202207/02/202207020624132426_8.gif) , among p Represents the dimension of space , Is a variable parameter . When p=1 when , It's Manhattan distance ; When p=2 when , It's Euclidean distance ; When
, among p Represents the dimension of space , Is a variable parameter . When p=1 when , It's Manhattan distance ; When p=2 when , It's Euclidean distance ; When  when , It's Chebyshev distance .
when , It's Chebyshev distance .
(4)、 Cosine distance
The cosine distance is used to analyze the correlation between two eigenvectors . The formula :![dist(A,B)=1-cos(A,B\in)\in [0,2]](http://img.inotgo.com/imagesLocal/202207/02/202207020624132426_9.gif) .
.
The cosine value of the angle between two vectors is the cosine similarity , Its value range is [-1,1], The cosine of the angle between two vectors is closer to 1, The more similar the two vectors are .
The commonly used distance measures are Euclidean distance and more generally distance .
3.k Choice of value
k The choice of will have a significant impact on the results , So how to choose k Value size ?
If k The value is relatively small , Then it is equivalent to that the unclassified sample is closer to the input instance ( alike ) Training examples are very close , Only in this way can the prediction result work . But if the adjacent instance point is a noise point , Then the classification of samples will produce errors , That is, the prediction will go wrong , Classification will produce the problem of fitting . in other words ,k A small value means that the overall model becomes complex , It's easy to get fitted .——k It's too small , Vulnerable to outliers .
If k It's worth more , This is far away from the input instance ( Dissimilar ) Training examples will also play a role in the prediction results , Make a prediction wrong , Classification will cause the problem of under fitting , The reason is that unclassified samples are not really classified .k A larger value means that the overall model becomes simple , It is easy to underfit .——k Overvalued , Affected by sample equilibrium .
k Value is usually a small value . In practice , Generally, cross validation is used to select the best k value . The core idea of cross validation is to put some possible k It's worth trying one by one , Then choose the best k value .
Cross validation is in machine learning Build a model and Verify model parameters Commonly used methods . seeing the name of a thing one thinks of its function , It's the reuse of data , Cut the sample data , Combine them into different training sets and test sets . Use training sets to train models , Use the test set to evaluate the quality of the model prediction, which is ” verification “; On this basis, we can get many different training sets and test sets , A sample in a training set may become a sample in a test set next time , The so-called “ cross ”.
The most effective cross validation method is to retest the model for the entire data set . The purpose of cross validation is to get a reliable and stable model .
The following three cross validation methods are introduced :
Holdout Cross validation : Divide the data set into training set and test set according to a certain proportion
K-Fold Cross validation : Divide the data into K Parts of , Each part is treated as a test set
Leave-P-Out Cross validation : Use P Selective ~CPN CNP The possibility is tested separately
among , stay KNN Commonly used in the algorithm is K-Fold Cross validation .
K-Fold Cross validation divides the data set into K Parts of , One of the individual samples is used as the test set , And the rest K-1 Samples as training set . Cross validation K Time , Each subset will be used as a test set , Test the model . The final average K The results obtained this time , Finally, a single model is obtained . If there is 100 Data points , And divided into ten cross validation . Then the data will be divided into ten parts , There are ten data points in each part . Ten data points can be verified respectively , And use another 90 Data points for training . Repeat this operation ten times , You will get ten models . Average these models , Finally, a suitable model is obtained .K-Fold Cross validation is applicable to the case where the data set sample is relatively small .
import numpy as np
from sklearn.model_selection import KFold
# Create a dataset -- get data
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Set up K The value is 2
k = 2
# Import cross validation , take K Value is set to 2
kfold = KFold(n_splits=k)
# Use kfold Split data -- Processing data
split_data = kfold.split(data)
# Use for The loop is exported twice KFold The data content of training set and test set
for train, test in split_data:
# The initial output is set to null
output_train = ''
output_test = ''
# Mark all initial conditions as T
mark = ["T"] * (len(train) + len(test))
for i in train:
# Data subscript and data content of training set
output_train = f"{output_train}({i}: {data[i]}) "
for i in test:
# Change the flag of the test set to t
mark[i] = "t"
# Data subscript and data content of the test set
output_test = f"{output_test}({i}: {data[i]}) "
# Output training set and test set
print(f"[ {' '.join(mark)} ]")
print(f" Training set : {output_train}")
print(f" Test set : {output_test}\n")[ t t T ]
Training set : (2: [7 8 9])
Test set : (0: [1 2 3]) (1: [4 5 6])
[ T T t ]
Training set : (0: [1 2 3]) (1: [4 5 6])
Test set : (2: [7 8 9]) k It's worth hours ,k The nearest neighbor model is more complex ;k When it's high ,k The nearest neighbor model is simpler .k The choice reflects the trade-off between approximation error and estimation error , Generally, the cross validation method is used to select the best k value .PS:k The value selection should be as odd as possible .
4、 Classification decision rules
k The rule of classification decision-making in neighbor method is usually majority voting , That is, by entering the instance k Most of the classes in the adjacent training instances determine the class of the input instance .
The common classification decision rule is majority voting , Corresponding to empirical risk minimization .
k Near neighbor method , When training set 、 Distance metric 、k After the value and classification decision rules are determined , The result is only certain .
summary KNN Workflow :
1. Calculate the distance between the object to be classified and other objects ;
2. Count the nearest K A neighbor ;
3. about K The nearest neighbor , Which category do they belong to the most , Where the object to be classified belongs ⼀ class .
3、 ... and 、k Implementation of nearest neighbor method :KD Trees
Realization k Nearest neighbor time , The main consideration is how to quickly analyze the training data k Neighborhood search . In two dimensions , The similarity of two features is generally expressed by Euclidean distance , in other words , Each new input instance needs to calculate the distance with all training instances and sort . When the training set is very large , Calculation is very time-consuming 、 Memory consumption , The efficiency of the algorithm is reduced , This method is not feasible . In order to improve the k Search efficiency of nearest neighbors , There is a way to reduce the number of distance calculations ——KD Tree method .
The tree is made up of  A finite set of nodes or elements . Tree is a recursively defined data structure .
A finite set of nodes or elements . Tree is a recursively defined data structure .
The characteristics of the tree : Each node has zero countries and multiple child nodes ; There is only one node without a precursor called the root node ; The remaining nodes have only one precursor , But there can be zero or more successors ; Each non root node has and only has one parent node ; Except for the root node , Each sub node can be divided into multiple disjoint subtrees .
A binary tree is a finite set of nodes , This collection may be empty , Or it is composed of a root node and two disjoint binary trees called left subtree and right subtree . The difference between a tree and a binary tree is , Each node of a binary tree has at most two sub trees and is orderly 、 Strictly distinguish the left subtree 、 Right subtree .
KD The tree is on data points in K Divided in dimensional space ⼀ Data structures . stay KD In the construction of trees , Every node is k Dimension value point ⼆ Fork tree . Since it is ⼆ Fork tree , You can pick ⽤⼆ Add, delete, change and query fork tree , This greatly improves the search efficiency .
KD The tree adopts the idea of partition . Use the existing data to k Segmentation of dimensional space , The binary tree structure that is then stored for fast search , utilize KD The tree can save the search of most data points , So as to achieve the purpose of reducing the amount of calculation of search .
KD The tree algorithm is divided into two parts , The first part is the structure KD Trees , Establish data points KD Tree data structure ; The second part is search KD Trees , In the establishment of KD Algorithm for nearest neighbor search on tree .
1、 structure KD Trees
First, calculate separately x,y Dimensional variance , Choose a dimension with a larger variance ; Then determine the root node of the binary tree, that is, construct the root node , Sort the values on the dimension and select the node as the median, which is the syncopation point , Determine a hyperplane , Then, the whole space is divided into two subspaces by using the split hyperplane ; Last , The instance is divided into two subspaces , Until there is no instance . This is to save the instance on the corresponding node . Get balanced KD Trees , But balanced KD The search efficiency of trees is not necessarily optimal .
2、 Search element KD Trees
How to use it KD Tree fast search k Nearest neighbors . Given a target instance point , Search for its nearest neighbor . First, find the leaf node containing the target instance point ; Then start from the leaf node , Fall back to the parent node in turn ; Constantly find the point closest to the target instance point , Terminate when it is determined that there can be no closer node .
《 Statistical learning method 》—— Chapter two 、 Perceptron model
http://t.csdn.cn/wFuy0http://t.csdn.cn/wFuy0 http://t.csdn.cn/wFuy0
http://t.csdn.cn/wFuy0
Reference material
1.《 Statistical learning method 》 The second edition -- expericnce
2.《 machine learning 》-- zhou
3.《 Mathematical basis and application of artificial intelligence Python machine learning 》-- Liu Runsen
4.《scikit-learn machine learning 》 The second edition -- Gavin . Written by Haike , Translated by Zhang Haoran
5. Machine learning personal notes complete -- Huang haiguang
边栏推荐
- Right click menu of QT
- Oracle修改表空间名称以及数据文件
- C Baidu map, Gaode map, Google map (GPS) longitude and latitude conversion
- [staff] time mark and note duration (staff time mark | full note rest | half note rest | quarter note rest | eighth note rest | sixteenth note rest | thirty second note rest)
- How to realize asynchronous programming in a synchronous way?
- Taking the upgrade of ByteDance internal data catalog architecture as an example, talk about the performance optimization of business system
- Pdf document of distributed service architecture: principle + Design + practice, (collect and see again)
- 一、Qt的核心类QObject
- 微服务实战|熔断器Hystrix初体验
- 十年開發經驗的程序員告訴你,你還缺少哪些核心競爭力?
猜你喜欢
概念到方法,绝了《统计学习方法》——第三章、k近邻法

概率还不会的快看过来《统计学习方法》——第四章、朴素贝叶斯法
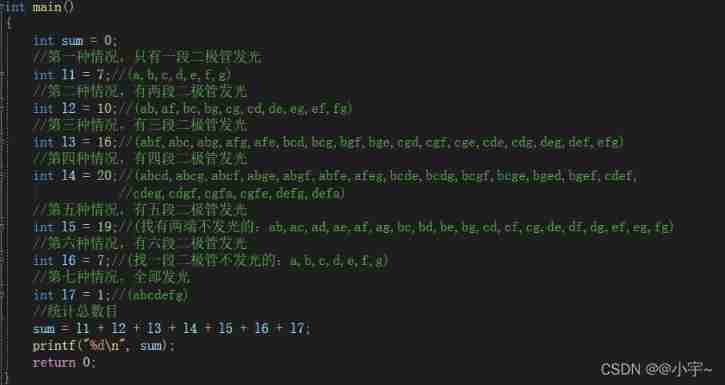
C language - Blue Bridge Cup - 7 segment code
![[staff] time mark and note duration (staff time mark | full note rest | half note rest | quarter note rest | eighth note rest | sixteenth note rest | thirty second note rest)](/img/7f/2cd789339237b7a881bfed7b7545a9.jpg)
[staff] time mark and note duration (staff time mark | full note rest | half note rest | quarter note rest | eighth note rest | sixteenth note rest | thirty second note rest)

Dix ans d'expérience dans le développement de programmeurs vous disent quelles compétences de base vous manquez encore?
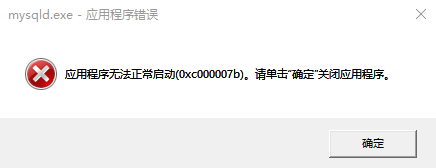
During MySQL installation, mysqld Exe reports that the application cannot start normally (0xc000007b)`
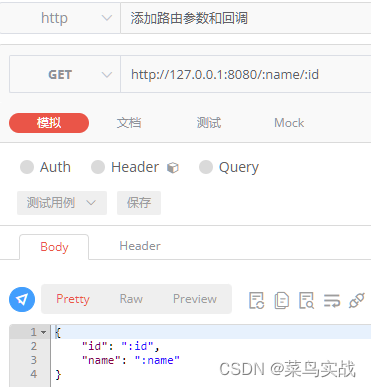
【Go实战基础】gin 如何绑定与使用 url 参数
西瓜书--第五章.神经网络

一篇详解带你再次重现《统计学习方法》——第二章、感知机模型

微服务实战|原生态实现服务的发现与调用
随机推荐
机器学习之数据类型案例——基于朴素贝叶斯法,用数据辩男女
Qt QTimer类
How to realize asynchronous programming in a synchronous way?
Introduction to the basic concept of queue and typical application examples
Move a string of numbers backward in sequence
C# 百度地图,高德地图,Google地图(GPS) 经纬度转换
统计字符串中各类字符的个数
Shengshihaotong and Guoao (Shenzhen) new energy Co., Ltd. build the charging pile industry chain
Using recursive functions to solve the inverse problem of strings
小米电视不能访问电脑共享文件的解决方案
Kubernetes deploys Loki logging system
西瓜书--第六章.支持向量机(SVM)
「面试高频题」难度大 1.5/5,经典「前缀和 + 二分」运用题
WSL安装、美化、网络代理和远程开发
【Go实战基础】gin 如何设置路由
"Redis source code series" learning and thinking about source code reading
QT drag event
C # save web pages as pictures (using WebBrowser)
Function ‘ngram‘ is not defined
Oracle related statistics