当前位置:网站首页>Flink - use the streaming batch API to count the number of words
Flink - use the streaming batch API to count the number of words
2022-07-02 09:08:00 【Programmer Qiqi】
Execution mode ( flow / batch )
DataStream API Support different runtime execution modes , You can choose according to your use case needs and job characteristics .
DataStream API There is a kind of ” classic “ The execution of , We call it flow (STREAMING) Execution mode . This mode is suitable for continuous incremental processing , And is expected to remain online indefinitely without boundaries .
Besides , There is also a batch execution mode , We call it batch (BATCH) Execution mode . This way of executing jobs is more reminiscent of a batch processing framework , such as MapReduce. This execution mode applies to having a known fixed input , And there are boundary jobs that will not run continuously .
Apache Flink Unified method of convection and batch processing , It means that no matter what execution mode is configured , Executed on bounded input DataStream Applications will produce the same final result . It is important to pay attention to the final What do you mean here : A job executed in stream mode may produce incremental updates ( Think about inserts in databases (upsert) operation ), And batch operation only produces a final result at the end . Although the calculation method is different , As long as the presentation is appropriate , The end result will be the same .
By enabling batch execution , We allow Flink Apply additional optimizations only when we know that the input is bounded . for example , Different associations can be used (join)/ polymerization (aggregation) Strategy , Allow for more efficient task scheduling and different failure recovery behaviors shuffle. Next, we will introduce some details of execution behavior .
When can we do that? / You should use batch mode ?
Batch execution mode can only be used for Boundary The homework /Flink Program . Boundary is an attribute of data source , Tell us before execution , Are all inputs from this data source known , Or whether there will be new data , It could be infinite . For an assignment , If all its sources have boundaries , Then it is bounded , Otherwise, there is no boundary .
And the flow execution mode , It can be used for tasks with boundaries , It can also be used for borderless tasks .
Generally speaking , When your program has boundaries , You should use batch execution mode , Because it will be more efficient . When your program is borderless , You must use stream execution mode , Because only this model is general enough , Able to handle continuous data streams .
An obvious exception is when you want to use a bounded job to self expand some job states , And use the state in the subsequent borderless operation . for example , Run a bounded job through flow mode , Take a savepoint, Then restore this on a borderless job savepoint. This is a very special use case , When we allow savepoint As an additional output of a batch job , This use case may soon become obsolete .
Another situation where you may use stream mode to run bounded jobs is when you write test code that will eventually run on unbounded data sources . For testing , In these cases, it may be more natural to use bounded data sources .
Configure batch execution mode
The execution mode can be implemented through execute.runtime-mode Set up to configure . There are three optional values :
- STREAMING: classic DataStream Execution mode ( Default )
- BATCH: stay DataStream API Batch execution on
- AUTOMATIC: Let the system decide according to the boundary of the data source
This can be done by bin/flink run ... Command line parameters of , Or create / To configure StreamExecutionEnvironment Time written into program .
Here is how to configure the execution mode through the command line :
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
This example shows how to configure the execution mode in the code :
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
We do not recommend that users set the running mode in the program , Instead, use the command line to set up when submitting the application . Keeping the application code configuration free can make the program more flexible , Because the same application can be executed in any execution mode .
Count word cases
Make statistics in batch mode
technological process

Core code

ParameterTool parameterFromArgs = ParameterTool.fromArgs(args);
String input = parameterFromArgs.getRequired("input");
// Initialization environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// Load data source
DataStreamSource<String> wordSource = env.readTextFile(input, "UTF-8");
// Data conversion
SingleOutputStreamOperator<Word> wordStreamOperator = wordSource.flatMap(new TokenizerFunction());
// Group by word
KeyedStream<Word, String> wordKeyedStream = wordStreamOperator.keyBy(new KeySelector<Word, String>() {
@Override
public String getKey(Word word) throws Exception {
return word.getWord();
}
});
// Sum up
SingleOutputStreamOperator<Word> sumStream = wordKeyedStream.sum("frequency");
sumStream.print();
env.execute("WordCountBatch");
- stay IDE Middle runtime , Need to specify -input Parameters , Enter the file address


Make statistics in stream processing
technological process

Core code

// Initialization environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Definition kafka data source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.0.192:9092")
.setTopics("TOPIC_WORD")
.setGroupId("TEST_GROUP")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
// Load data source
DataStreamSource<String> kafkaWordSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Word Source");
// Data conversion
SingleOutputStreamOperator<Word> wordStreamOperator = kafkaWordSource.flatMap(new TokenizerFunction());
// Group by word
KeyedStream<Word, String> wordKeyedStream = wordStreamOperator.keyBy(new KeySelector<Word, String>() {
@Override
public String getKey(Word word) throws Exception {
return word.getWord();
}
});
// Sum up
SingleOutputStreamOperator<Word> sumStream = wordKeyedStream.sum("frequency");
sumStream.print();
env.execute("WordCountStream");
Full code address
https://github.com/Mr-LuXiaoHua/study-flink
com.example.datastream.wordcount.DataStreamApiWordCountBatch -- Read data from the file for word statistics
com.example.datastream.wordcount.DataStreamApiWordCountStream -- from Kafka Consumption data for word statistics
Submitted to the flink The cluster to perform :
bin/flink run -m 127.0.0.1:8081 -c com.example.datastream.wordcount.DataStreamApiWordCountBatch -input /mnt/data/words.txt /opt/apps/study-flink-1.0.jar
-input Specify the input file path 边栏推荐
- 队列的基本概念介绍以及典型应用示例
- Npoi export word font size correspondence
- 汉诺塔问题的求解与分析
- Synchronize files using unison
- Installing Oracle database 19C RAC on Linux
- Aneng logistics' share price hit a new low: the market value evaporated by nearly 10 billion yuan, and it's useless for chairman Wang Yongjun to increase his holdings
- Minecraft install resource pack
- Don't spend money, spend an hour to build your own blog website
- There is a problem with MySQL installation (the service already exists)
- Analysis and solution of a classical Joseph problem
猜你喜欢
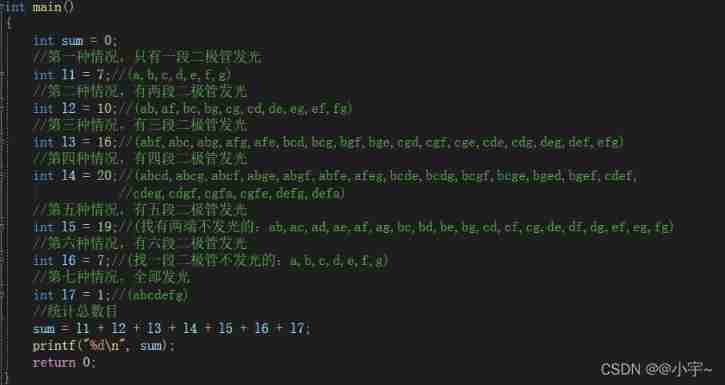
C language - Blue Bridge Cup - 7 segment code
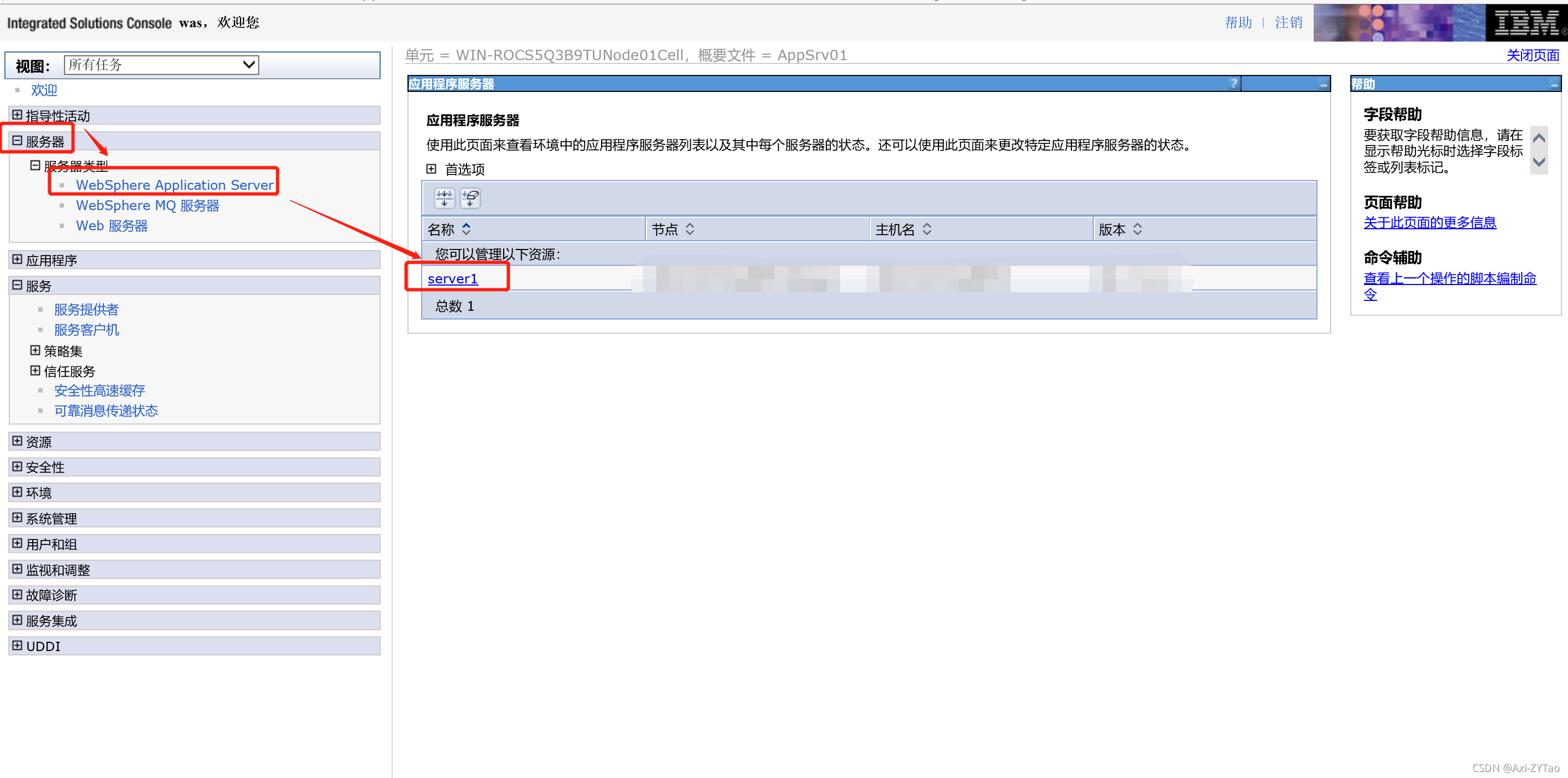
查看was发布的应用程序的端口

Minecraft模组服开服

C4D quick start tutorial - C4d mapping

Minecraft插件服开服

commands out of sync. did you run multiple statements at once
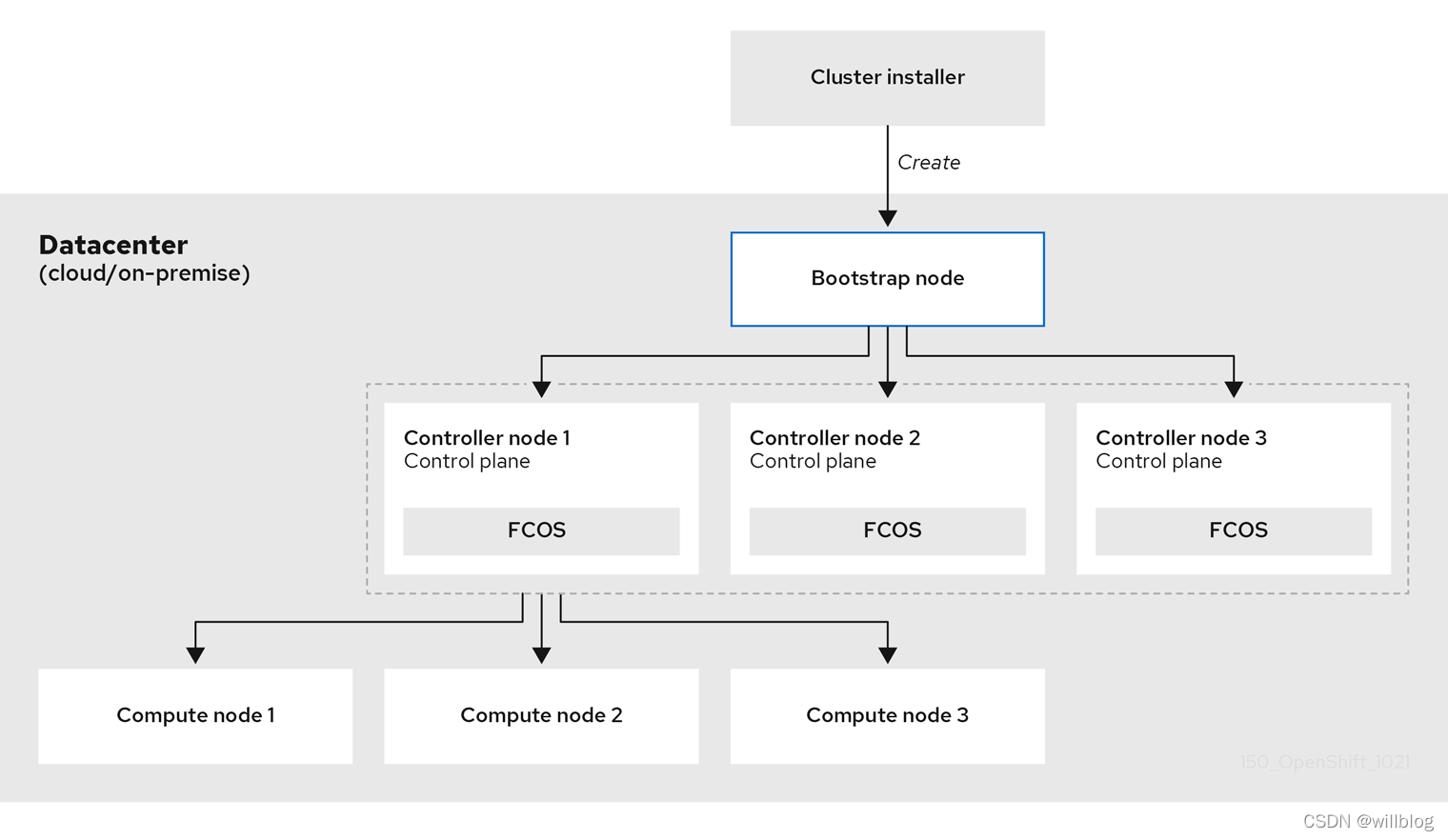
Openshift container platform community okd 4.10.0 deployment
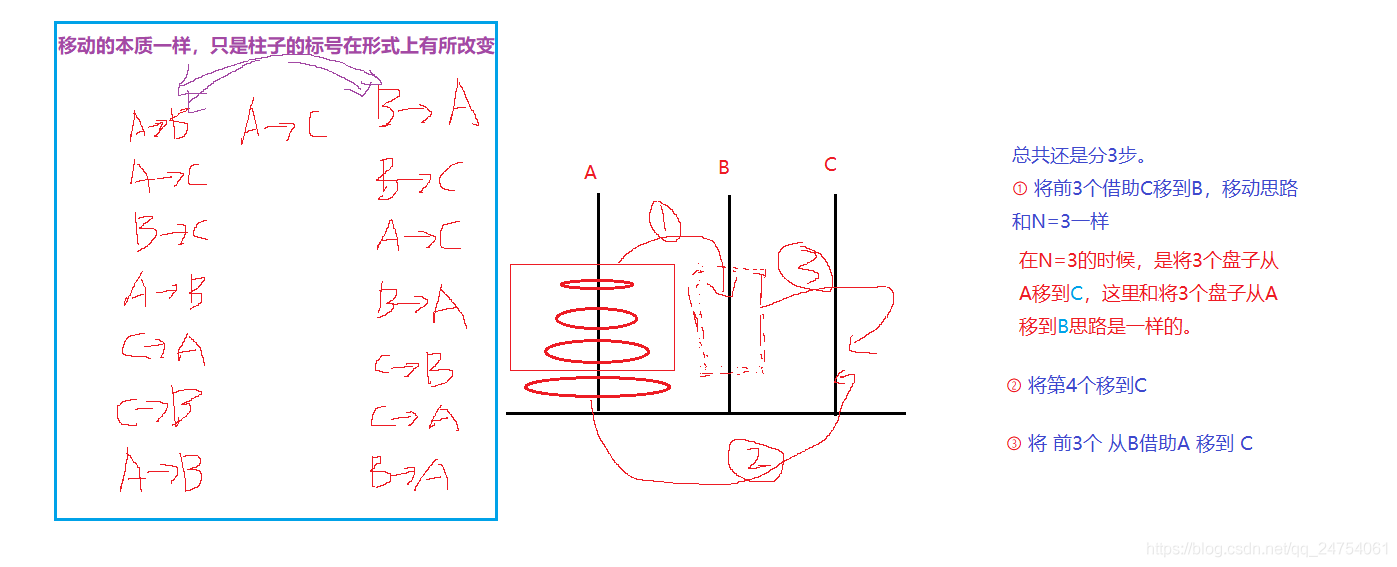
Solution and analysis of Hanoi Tower problem

Synchronize files using unison
Servlet全解:继承关系、生命周期、容器和请求转发与重定向等
随机推荐
Minecraft插件服开服
【Go实战基础】gin 如何设置路由
Minecraft group service opening
Illegal use of crawlers, an Internet company was terminated, the police came to the door, and 23 people were taken away
Gocv split color channel
C# 高德地图 根据经纬度获取地址
远程连接IBM MQ报错AMQ4036解决方法
以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
Sentinel reports failed to fetch metric connection timeout and connection rejection
Dix ans d'expérience dans le développement de programmeurs vous disent quelles compétences de base vous manquez encore?
【Go实战基础】gin 如何获取 GET 和 POST 的请求参数
Minecraft plug-in service opening
Finishing the interview essentials of secsha system!!!
图像变换,转置
Openshift build image
cmd窗口中中文呈现乱码解决方法
gocv opencv exit status 3221225785
C # save web pages as pictures (using WebBrowser)
gocv边界填充
Leetcode sword finger offer brush questions - day 23