当前位置:网站首页>NBA赛事直播超清画质背后:阿里云视频云「窄带高清2.0」技术深度解读
NBA赛事直播超清画质背后:阿里云视频云「窄带高清2.0」技术深度解读
2022-07-05 14:44:00 【阿里云视频云】
在半月前结束的NBA总决赛中,百视TV作为全网唯一采用“主播陪你看NBA”模式的直播平台,以“陪看型”赛事解说来面对内容差异化竞争。与此同时,百视TV还运用了“窄带高清2.0”直播转码技术,为观众在赛事画面质量上打造更进一步的体验提升。
简单来说,“窄带高清”是一套以“主观体验最好”为优化目标的视频编码技术,让我们看一张对比图,感受一下画质提升效果:

上图为主播推流原画,下图为修复后画面
上图上半部分是主播推流的原画,下半部分是使用窄带高清2.0技术转码后的画面。可以看到,经过窄带高清2.0 技术转码,球衣上的数字、地板上的英文字母、篮网、边界线等变得更加清晰。此外,画面整体清晰度都有明显的提升,甚至地板纹理和场外观众轮廓都会肉眼可见变得更加清晰。
下文将深度解读为NBA直播赛事带来超清画质背后的“窄带高清”技术原理。
1. 窄带高清技术
阿里云早在2015年就已经提出了“窄带高清”的概念,在2016年正式推出窄带高清技术品牌并进行产品化。窄带高清代表的是一种成本与体验相调和的视频服务理念,是以人眼主观感受最优为基准的视频编码技术。
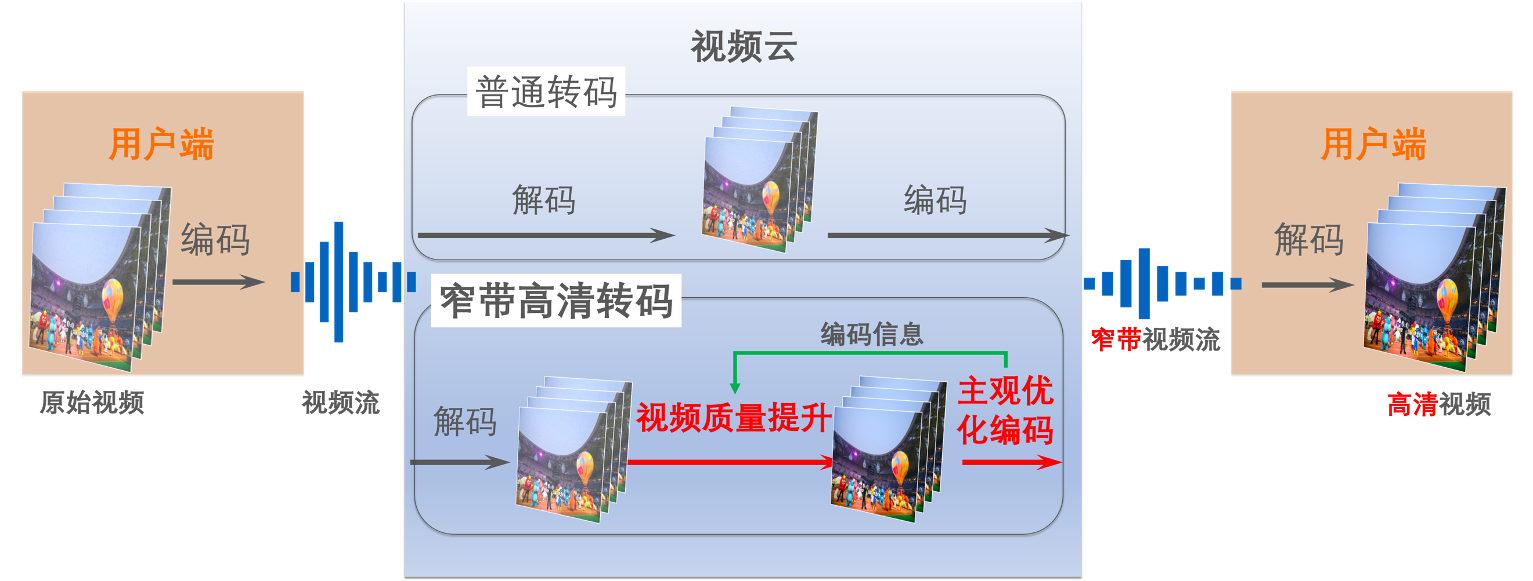
“窄带高清”示意图
窄带高清本质上是一个质量提升和压缩的问题,主要目标是追求质量、码率和成本的最优均衡。在这个方向有两个版本,即窄带高清1.0和窄带高清2.0(以下简称“窄高”)。
窄高1.0是均衡版,主要作用是如何用最少的成本去实现自适应的内容处理和编码,达到节省码率的同时实现画质的提升。所以,在窄高1.0充分利用编码器里的信息帮助视频处理,即用成本很小的前处理方法实现低成本的自适应内容处理和编码。同时,在编码器里,主要是基于主观的码控。
窄高2.0和窄高1.0相比会有更多的、更充分的和复杂度更高的技术来保证自适应能力,包括JND自适应内容编码、ROI编码、SDR+、更自然的细节增强等。同时,在窄高2.0里增加了更适用于高热内容的修复能力,在质量提升的同时,码率节省也更多。
2. 赛事直播的挑战
当前,窄带高清技术在长视频、短视频、泛娱乐、在线教育、电商直播等场景有着广泛应用。
相较于长视频和电商直播等场景,NBA篮球赛事直播由于画面切换快、运动性很强,往往需要高码率流。然而,高码率的直播尤其是NBA比赛直播在跨国传输中可能会受网络质量波动,造成音视频卡顿及延迟。
为了保证直播的稳定性和基于播放端的丝滑观赛体验,百视TV选择了较小码率的源流。于是,面临真实场景下的多个挑战:
挑战 1:低码流导致赛场画面模糊失真
相比于高码率流的画面画质,低码率流会有较明显的压缩失真、细节模糊和弱纹理丢失。对于篮球赛事场景来说,就会造成如球星球衣上的文字模糊、篮网模糊、边界线及地面上文字边缘毛刺多等诸多画质现象,导致观看体验不佳。
挑战 2:剧烈运动画面的“去交错处理”残留
除了低码率流带来的压缩失真细节模糊外,体育比赛场景还有一个特有的问题,即原始信号一般是隔行扫描采集的,在互联网传输时首先需要做“去交错处理”,但是对于剧烈运动画面,很难保证有完美的去交错处理,通常会有一些“交错”没有去除干净,形成一些残留噪声。
挑战 3:数次转码后的画面损失
此外,基于企业客户当前业务逻辑,直播视频从拍摄到终端用户,经历了数次转码,每一次转码,都会带来一定的压缩失真和画质损失。
为了更好地平衡直播流畅性、稳定性和高清画质体验,百视TV在NBA决赛转播过程中先选择相对较低的码率实现稳定的跨国传输,将源流拉到国内后再做修复,在此过程中,百视TV便使用了阿里云视频云的“窄带高清2.0”技术。
3. 针对体育赛事的解决方案
针对体育赛事视频,如果简单地使用阿里云线上常规窄带高清转码,存在两大弊端:
第一,难以修复体育赛事视频中的特有噪声,同时还有可能把一些噪声放大,从而影响观看体验。
第二,常规窄带高清无法对篮球场景的特有元素比如球衣上数字、篮网、边界线等实现完美修复。
为此,窄带高清2.0针对体育赛事场景,对已有的原子算法能力进行了优化组合,同时部分算法针对篮球赛场景进行了定向调优。
最终采用的转码流程如下图所示:
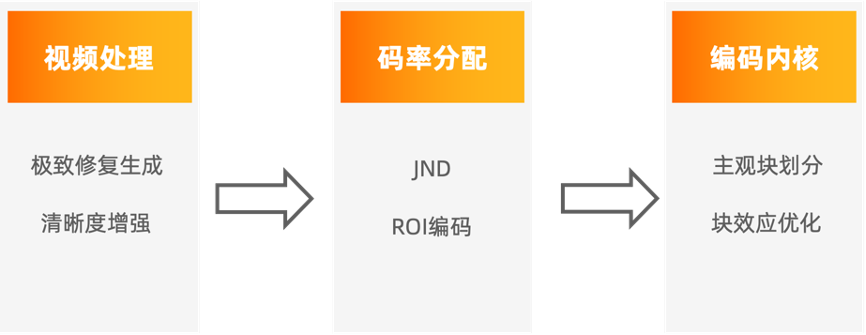
直播转码算法流程
4. 关键技术解析
4.1 视频处理
极致修复生成
前面已提到我们输入源本身画质不高,同时还经过了多次转码,因此第一个处理步骤为修复生成,其主要目的是修复视频中的多种瑕疵,比如压缩块效应、压缩伪影、边缘毛刺、去交错后残留噪声、模糊等,同时生成一些因压缩丢失的细节纹理。
学术界有不少利用深度学习去专门做去压缩失真、专门做去模糊的研究工作。比如早期做图片去压缩的ARCNN[1],做视频去压缩的MFQE[2],早期端到端去模糊算法DeepDeblur[3]。
比较新的方法有:自带压缩程度估计的图片去压缩算法FBCNN[4],基于可形变卷积的视频去压缩算法STDF[5],无需非线性激活的NAFNet[6]等等 。
这些算法大部分都是针对单一任务构造数据集和设计网络结构进行模型训练,得到的模型只能处理单一退化类型,但是在这次百视TV NBA比赛直播转码中,我们要处理的视频同时包含多种“退化降质”,除了典型的视频压缩,还有相机失焦模糊/运动模糊,去交错后残留噪声等。
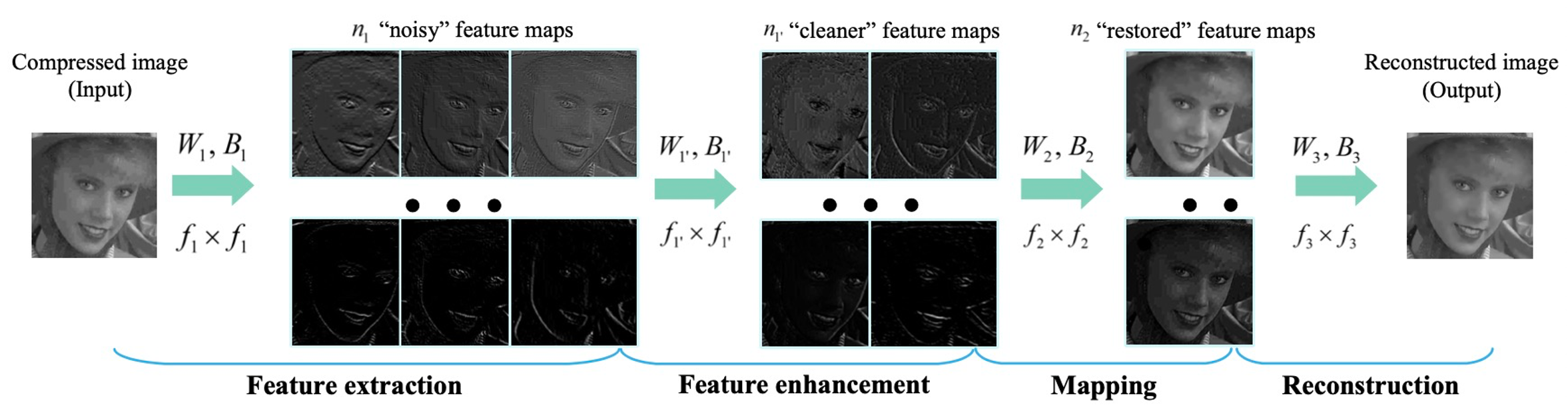
图片去压缩算法ARCNN的网络结构
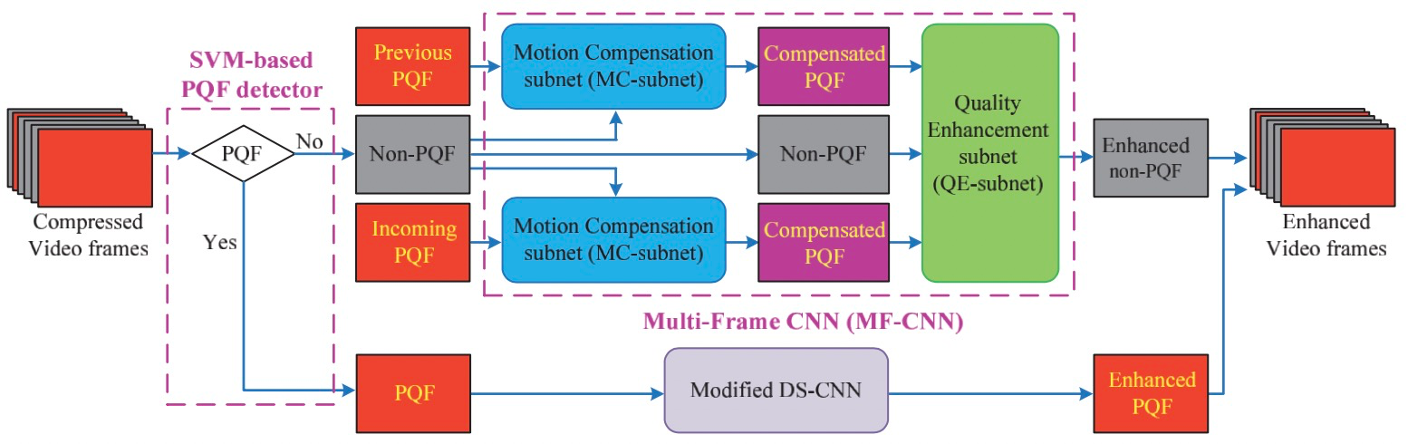
视频去压缩算法MFQE的网络结构
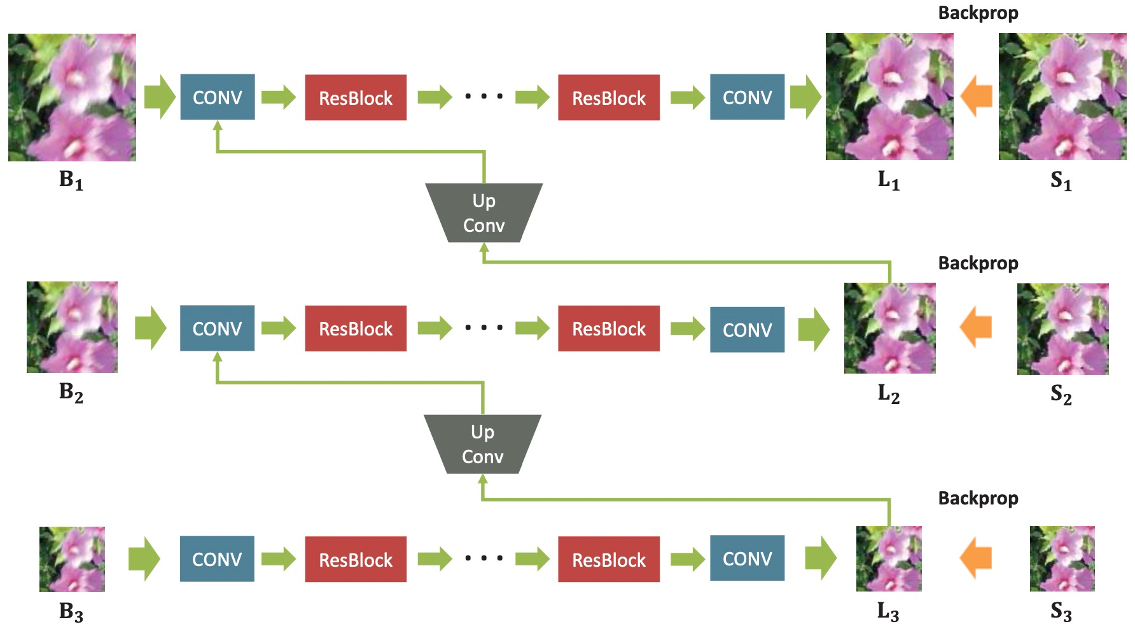
端到端去模糊算法DeepDeblur的网络结构
为了解决上述诸多“退化”,一种方式是针对每一种退化训练一个模型,然后依次运行这些模型。这种方式的优点是每个模型的任务变得比较简单,方便构造数据集和训练,但在实际使用时效果并不好,因为其他退化会带来很大的干扰,导致算法性能急剧下降。
于是,我们采用了第二种方式,即用一个模型来处理多种退化。第二种方式的好处是可以取得相对更好的处理效果,难点在于训练数据的构造比较复杂,对网络容量的要求较高,需要同时兼顾多种退化方式,这其中还可以有多种排列组合。
在训练数据构造方面,我们借鉴了图像超分领域的BSRGAN[7]/Real-ESRGAN[8]和视频超分领域的RealBasicVSR[9]中的数据退化方式,同时添加了一些体育赛事直播场景特有的退化模式来模拟场地边界线处的锯齿、白边等瑕疵。
在网络结构方面,为了减少计算量,我们采用了单张图片处理方式,可以采用经典的ESRGAN[10]模型或常见的UNet[12]结构,亦或ResSR[13]提到的VGG-Style结构。
在损失函数方面,考虑到需要修复因各种退化丢失的细节,除了使用常见的L1/L2 loss外,还使用了percectual loss 和 GAN loss。
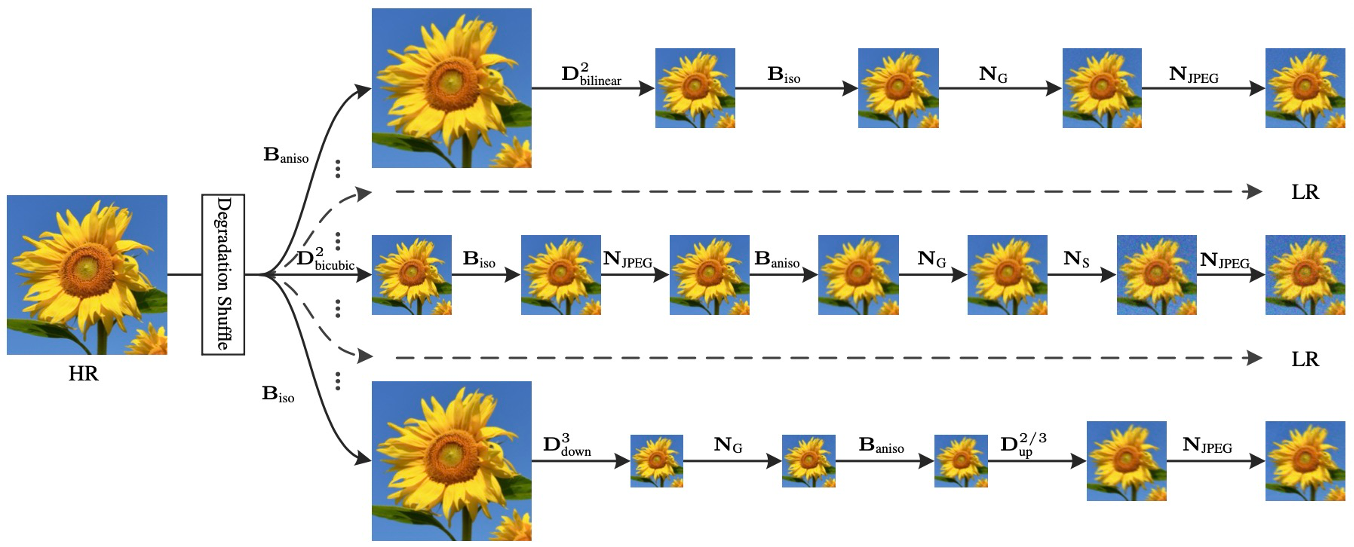
BSRGAN提出的多种图像退化方式
基于GAN的生成网络的一个主要问题是鲁棒性和时域连续性不够好。鲁棒性问题是指能否稳定地生成比较自然的纹理,比如有些GAN模型有时生成出来的细节纹理比较奇怪不自然,尤其是当在人脸区域生成一些奇怪纹理时会比较恐怖。
时域连续性问题是指相邻帧生成出来的纹理是否保持一致,如果不一致则会产生闪烁现象,降低观看体验。
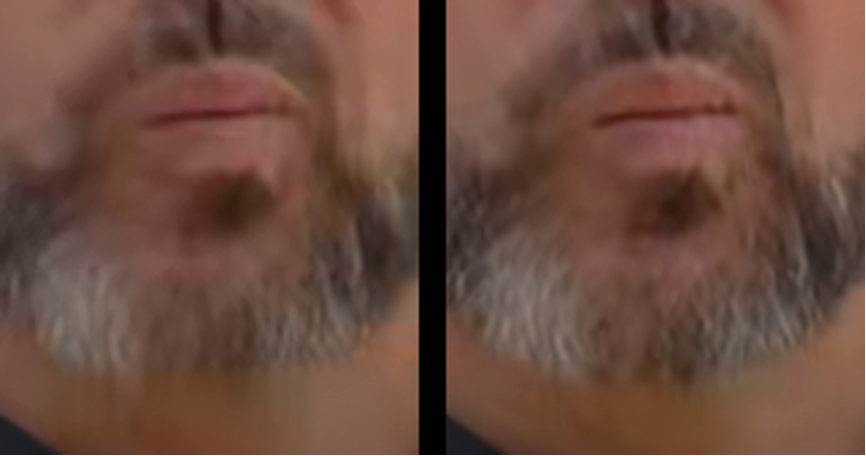
为了解决鲁棒性问题,尤其是人脸区域鲁棒性,我们借鉴了LDL[14]中通过检测fine-scale details区域并加以额外惩罚来提升fine-scale details生成效果的思想,通过人脸区域分割得到人脸区域,对人脸区域生成效果施加额外的惩罚来提升人脸区域细节生成的鲁棒性。

人脸区域分割
针对时域连续性问题,我们采用了TCRnet网络来作为额外监督信号来提升。TCRnet网络原本用于超分任务,通过简单改造可用于修复任务,该网络用IRRO偏移迭代修正模块结合可变形卷积,来提高运动补偿的精度,同时利用ConvLSTM进行时序信息的补偿防止造成信息误差,从而提升时域连续性。
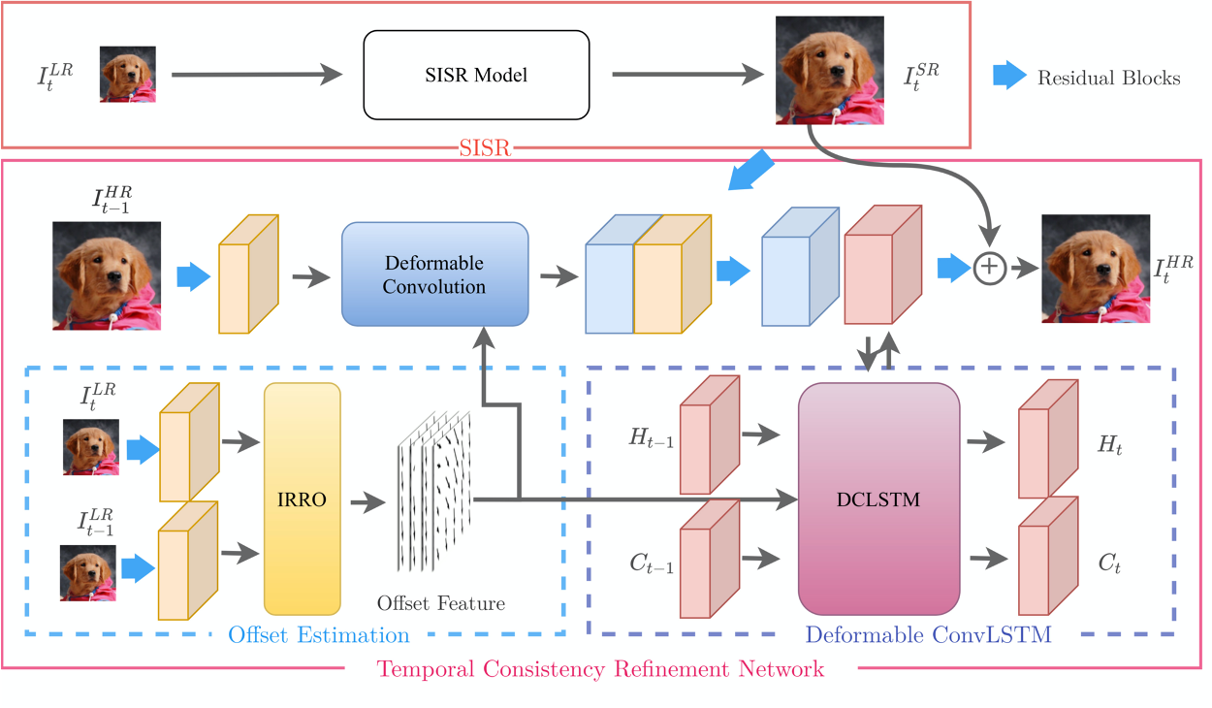
TRCNet网络结构
下面两张图对比了源流和修复后效果。
从第一张对比图可以看出,修复后地板上的字母GARDEN的边缘变得非常清晰锐利,边界线、球员轮廓及球衣上数字22也变得更清晰,此外地板纹理也得到修复。
第二张对比图也能看到场外观众轮廓和衣服上线条变得更清晰,此外原本扭曲成锯齿状的地板边界线也变直了。

模型加速
为了获得极致修复生成效果,基于深度学习的AI算法通常是首选算法。但深度学习算法的一个问题是计算量大,而对于视频修复生成这种low level视觉任务来说,计算量比普通high level视觉任务还要大很多。
一方面,视频修复生成模型的输入通常是视频原分辨率,而像检测分类这种high level处理模型的输入分辨率,可以比原分辨率小很多,且基本不影响检测分类性能。而同样的网络结构,输入分辨率越大计算量越大,所以视频修复模型的计算量要大很多。
另一方面,视频修复生成模型的输出是和输入视频同分辨率的视频帧,这势必使得模型后半部分的计算量也会很大,因为后半部分也需要在比较高的分辨率特征图上做计算,不像检测分类high level任务只输出目标框或类别这种语义信息,模型后半部分虽然通道数多但因为特征图分辨率小所以总体计算量小很多。
此外,对于体育赛事直播,视频帧率通常都是50fps,蓝光档位的分辨率通常是1080p,也就是深度学习模型在1080p输入下需要至少跑到50fps,这对深度学习算法是非常大的挑战。
针对这一情况,我们从多个维度进行模型推理加速。
首先,对深度学习模型做压缩,比如通过神经架构搜索(Neural Architecture Search,NAS)或剪枝降低模型大小,为了弥补模型变小之后的性能损失,需要对压缩后的模型,进行知识蒸馏训练提升小模型的性能,此外还可以通过8bit整型量化或者FP16半精度来进一步降低计算量。
其次,可以通过选择合适的硬件和推理框架来获得极致的速度提升,比如使用高性能GPU卡和配套的推理框架实现最优配置。为了进一步提升推理速度,还可以使用多GPU卡并行计算。
通过上述多种方式加速,在1080p分辨率输入下,处理速度从8fps提升到67fps,完全满足50fps直播转码需求。
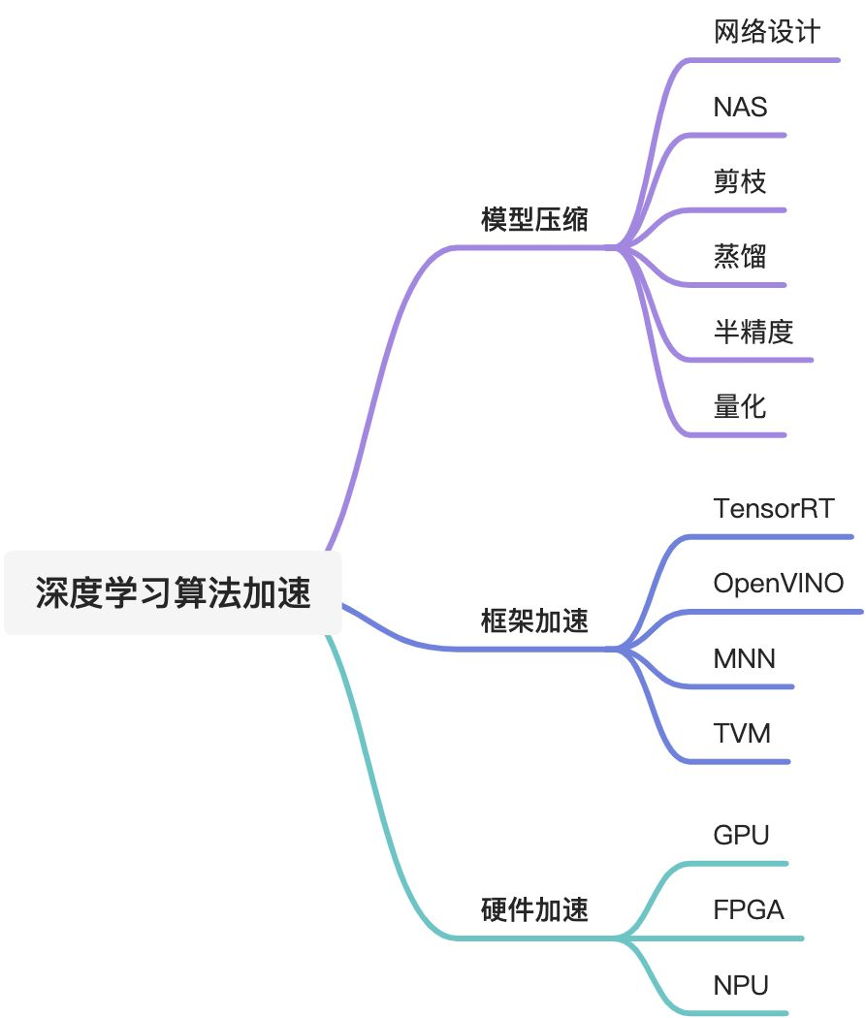
深度学习算法加速分类
清晰度增强
为了提升观看体验,在上述极致修复生成基础上,进一步做了清晰度增强处理。
最简单的清晰度增强算法就是做锐化处理,比如ffmpeg自带的unsharp和cas就是两种简单的锐化算法。unsharp和cas这两种方法都是基于USM(UnSharp Mask)框架设计的,USM框架可以用如下公式[15]来描述:
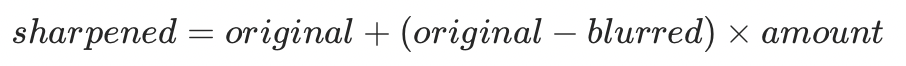
其中,original待锐化的图像,blurred是original的模糊版本,比如高斯模糊后的版本,这也是unsharp名字的由来。(original - blurred)表征的是原始图像的细节部分,乘以amount之后叠加到原图,即可获得细节更锐利看起来更清晰的图sharpened。
除了锐化,还可以通过调节对比度、亮度、色彩等方法来提升清晰度。在百视TV篮球赛直播中,我们使用自研的锐化、亮度、对比度和色彩增强算法来实现清晰度的进一步提升。
其中,相比开源锐化算法如unsharp,阿里云视频云自研锐化算法具有如下特点:
- 更精细的图像纹理细节提取方式:能提取不同尺寸,不同特征的图像纹理结构,增强效果更优;
- 通过对图像内容纹理结构分析,根据区域纹理复杂度实现局部区域自适应增强;
- 与编码结合,根据编码器的编码信息反馈,来自适应调整增强策略。

细节增强(锐化)算法流程
4.2 码率分配
JND
通过前面的极致修复生成和清晰度增强,细节信息得到极大增加,同时我们希望经过压缩编码后能尽量保留这些信息。我们知道,传统的视频编码是基于信息论的,所以它在一直做时域冗余、空域冗余、统计冗余等等冗余的去除,但是对视觉冗余的挖掘是远远不够的。下图取自于王海强博士的一篇paper,它的思路是传统做RDO ,是一个连续的凸曲线,但在人眼中它是个阶梯形的,那我们只要找到这个阶梯就可以省下码率,同时不影响主观质量。JND(Just Noticeable Difference)正是基于这个思路对视觉冗余进行挖掘。

比特率与感知失真关系
阿里云视频云自研的JND算法从空域和时域两个维度,对视觉冗余进行充分挖掘,实现在通用场景下,同等主观质量码率节省30%以上。
有了该自研JND算法,使得通过极致修复生成和清晰度增强获得的细节信息经过较低码率编码后,仍然得以保留。
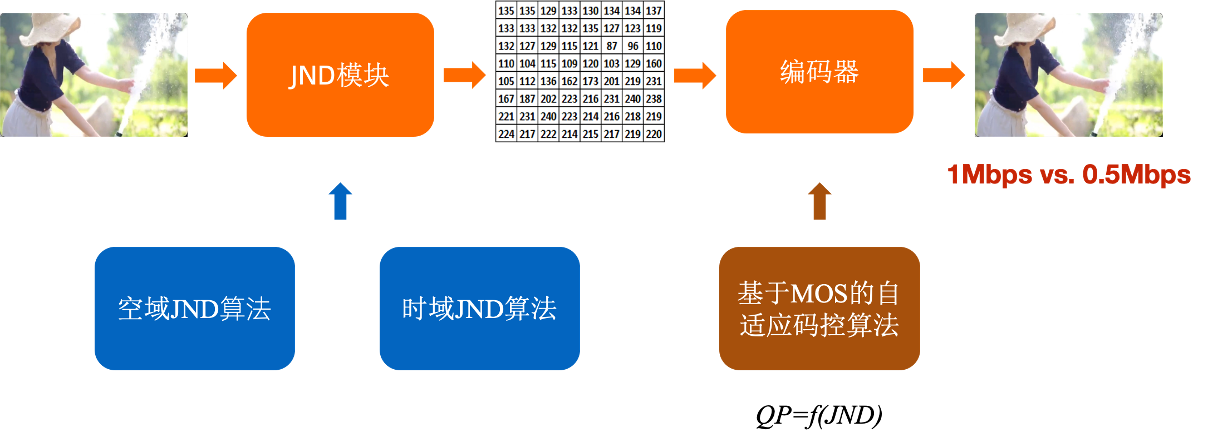
JND算法流程
ROI
前面所述的JND算法通过对视觉冗余的挖掘能节省30%以上的码率,但这种码率节省是完全基于low level统计信息来获得的,并没有考虑high level语义信息。
针对体育赛事场景中观众们很关注的人物近景特写镜头,我们希望能够让人物特写更清晰地呈现在观众面前。除了通过极致修复生成获得清晰人物特写外,还要通过某种方法使得编码后仍然保持清晰。在此,需要用到我们自研的ROI编码技术。
ROI(Region Of Interest)编码是一项基于感兴趣区域的视频编码技术,简单来说就是给图像中感兴趣区域分配更多码率已提升画质,对其他不感兴趣区域分配较少码率,可实现总体码率基本不变的情况下提升视频整体观看体验。
ROI编码的主要难点在于:
1)要有成本足够低速度足够快的ROI算法,以满足高分辨率高帧率体育赛事直播要求;
2)如何基于ROI进行码控决策,使得ROI区域主观质量提升,非ROI区域主观不下降,同时保持时域连续不闪烁。
在低成本ROI计算方面,我们自研了自适应决策的人脸检测跟踪算法,即大部分时间只需要做计算量极小的人脸跟踪,只有少部分时间需要做人脸检测,从而实现超低成本和快速ROI获取,同时保持很高的精度。

在码控决策上,一方面与编码器结合,在主观和客观之间取得均衡,保持时域一致;另一方面与JND结合,在ROI和非ROI之间取得主观均衡,从而实现场景、质量自适应的码率分配。

ROI算法流程
4.3 编码内核
针对体育赛事直播场景,在视频编码内核方面,我们做了主观快划分优化和块效应优化,以提升压缩后视频的主观清晰度,降低块效应,从而提升整体观看体验。
主观块划分
编码器的块划分模式决策是根据最佳率失真模型RDO (Rate Distortion Optimization,率失真优化)来决策:
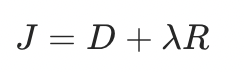
其中D表示失真,R表示编码当前模式所需的bit数。
在块划分决策时,有时会出现最终决策为大块,但从主观上看划分为小块的结果更好的情况。这是因为大块模式虽然失真D更大,但R更小,导致编码器最终决策为大块划分。
针对这种情况,我们修改了不同块划分模式的失真表达式,针对不同大小的块增加不同的权重系数,使得最终划分的结果与主观更一致。
优化前 优化后

优化前块划分 优化后块划分
块效应优化
视频编码的率失真理论与人眼感受比较贴切,按照率失真理论构建的编码器也是对人眼主观质量的优化,唯一的问题在块效应,因为人眼会放大直线,对块效应很敏感。
我们观察到,在基于客观的RDO(Rate Distortion Optimization,率失真优化),编码部分模式会放大块效应,而265协议中的deblock在该场景失效。同时我们发现在平坦区域场景,模糊加噪声的效果要优于清晰块效应。
基于以上观察,我们采用了如下块效应优化策略以尽量减少块效应,提升观看体验。
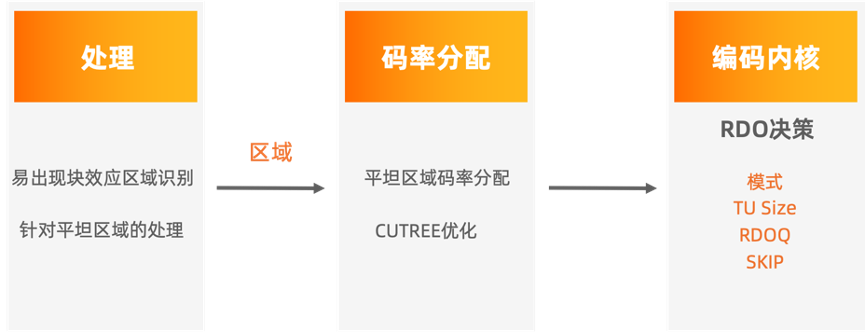
块效应优化算法流程
下图是我们做块效应优化前后的对比图。可以看出,右边做了优化的结果中块效应明显降低。

优化前 优化后
4.4 视频效果展示
通过前述视频处理、码率分配优化和编码内核优化,最终实现画质极致修复和1080p下50fps直播转码,为观众提供流畅、稳定和高清的观看体验。
由此可见,通过与百视TV的NBA赛事合作,充分体现了“窄带高清2.0”技术在篮球赛事直播中对视觉体验提升的重要价值,其带来同等画质下更省流、同等带宽下更高清的商业意义与观看体感平衡。
未来,窄带高清技术也将持续升级,通过算法能力进一步提升修复生成效果、降低码率和优化成本。于此同时,该项技术也将应用于更多的顶级赛事活动,在成本优化调和之上,实现视效体验的全新升级。
参考文献:
[1] ARCNN:Chao Dong, et al., Compression Artifacts Reduction by a Deep Convolutional Network, ICCV2015
[2] MFQE:Ren Yang, et al., Multi-Frame Quality Enhancement for Compressed Video, CVPR2018
[3] DeepDeblur:Seungjun Nah, et al., Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring, CVPR2017
[4] FBCNN:Towards Flexible Blind JPEG Artifacts Removal, ICCV2021
[5] STDF:Jianing Deng, et al., Spatio-Temporal Deformable Convolution for Compressed Video Quality Enhancement, AAAI2020
[6] NAFNet:Liangyu Chen, et al., Simple Baselines for Image Restoration,https://arxiv.org/abs/2204.04676
[7] BSRGAN: Kai Zhang, et al., Designing a Practical Degradation Model for Deep Blind Image Super-Resolution, CVPR2021
[8] Real-ESRGAN: Xintao Wang, et al., Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data, ICCVW2021
[9] RealBasicVSR: Kelvin C.K. Chan, et al., Investigating Tradeoffs in Real-World Video Super-Resolution, CVPR2022
[10] ESRGAN: Xintao Wang, et al., ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks, ECCVW2018
[11] ESRGAN: Xintao Wang, et al., ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks, ECCVW2018
[12] UNet: Olaf Ronneberger, et al., U-Net: Convolutional Networks for Biomedical Image Segmentation, MICCAI2015
[13] RepSR: Xintao Wang, et al., RepSR: Training Efficient VGG-style Super-Resolution Networks with Structural Re-Parameterization and Batch Normalization, https://arxiv.org/abs/2205.05671
[14] LDL:Jie Liang, et al., Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution, CVPR2022
[15] USM:https://en.wikipedia.org/wiki/Unsharp_masking
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。
边栏推荐
- Intelligent supply chain collaboration system solution for daily chemical products industry: digital intelligent SCM supply chain, which is the "acceleration" of enterprise transformation
- Selection and use of bceloss, crossentropyloss, sigmoid, etc. in pytorch classification
- 日化用品行业智能供应链协同系统解决方案:数智化SCM供应链,为企业转型“加速度”
- Thymeleaf th:with局部变量的使用
- CPU design practice - Chapter 4 practical task 2 using blocking technology to solve conflicts caused by related problems
- C language -- structure and function
- 选择排序和冒泡排序
- 世界环境日 | 周大福用心服务推动减碳环保
- CPU设计相关笔记
- CPU design practice - Chapter 4 practice task 3 use pre delivery technology to solve conflicts caused by related issues
猜你喜欢
leetcode:881. 救生艇
想进阿里必须啃透的12道MySQL面试题
Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 2)
如何将电脑复制的内容粘贴进MobaXterm?如何复制粘贴
CPU设计相关笔记

Run faster with go: use golang to serve machine learning
Thymeleaf 使用后台自定义工具类处理文本
日化用品行业智能供应链协同系统解决方案:数智化SCM供应链,为企业转型“加速度”

Section - left closed right open
Principle and performance analysis of lepton lossless compression
随机推荐
[C question set] of Ⅷ
微帧科技荣获全球云计算大会“云鼎奖”!
How to protect user privacy without password authentication?
leetcode:881. lifeboat
Mongdb learning notes
STM32+BH1750光敏传感器获取光照强度
Photoshop插件-动作相关概念-ActionList-ActionDescriptor-ActionList-动作执行加载调用删除-PS插件开发
Section - left closed right open
注意!软件供应链安全挑战持续升级
Countermeasures of enterprise supply chain management system in UCA Era
想进阿里必须啃透的12道MySQL面试题
Online electronic component purchasing Mall: break the problem of information asymmetry in the purchasing process, and enable enterprises to effectively coordinate management
APR protocol and defense
Solution of commercial supply chain collaboration platform in household appliance industry: lean supply chain system management, boosting enterprise intelligent manufacturing upgrading
729. My schedule I: "simulation" & "line segment tree (dynamic open point) &" block + bit operation (bucket Division) "
Principle and performance analysis of lepton lossless compression
Run faster with go: use golang to serve machine learning
Matrix chain multiplication dynamic programming example
Total amount analysis accounting method and potential method - allocation analysis
SaaS multi tenant solution for FMCG industry to build digital marketing competitiveness of the whole industry chain