当前位置:网站首页>Pat class B "1104 forever" DFS optimization idea
Pat class B "1104 forever" DFS optimization idea
2022-07-03 03:12:00 【Sumzeek】
This paper introduces the author's views on B1104 The optimization idea of ,AC The code is at the end of the article Case3
If you don't answer , I strongly recommend that you read as needed Case1-3, After reading it, write the code by yourself , Think about your own optimization ideas , And do it , This article only plays a role of throwing a brick to attract jade , Welcome to share your optimization ideas in the comment area .
“ Count forever ” It means a  Positive integer
Positive integer  , The conditions are : The sum of the figures is
, The conditions are : The sum of the figures is  ,
, The sum of the figures is
The sum of the figures is  , And And The greatest common divisor of is a greater than 2 The prime . Please find out these eternal numbers .
, And And The greatest common divisor of is a greater than 2 The prime . Please find out these eternal numbers .
Input format :
The input gives a positive integer on the first line  , And then N That's ok , Each line gives a pair of
, And then N That's ok , Each line gives a pair of  and
and  , Its meaning is as described in the title .
, Its meaning is as described in the title .
Output format :
For each pair of inputs and , First, output... On one line Case X, among X Is the number of the output ( from 1 Start ); Then output the corresponding... Line by line and , Numbers are separated by spaces . If the solution is not unique , Then each group occupies one line , Press Incremental order output ; If it's not the only one , Then press Incremental order output . If the solution does not exist , Output in one line No Solution.
sample input :
2
6 45
7 80
sample output :
Case 1
10 189999
10 279999
10 369999
10 459999
10 549999
10 639999
10 729999
10 819999
10 909999
Case 2
No Solution
Case 1:
Seeing this question, the author first thought of using dfs Backtracking pruning for violent solution , A total of three functions need to be customized
- isPrime(): Find prime number
- gcd(): Find the greatest common factor
- dfs(): Back pruning
And then through dfs Accumulate string s1, for example k=4, Just try 0000-9999 Between all situations , Finally, judge the boundary conditions
- The greatest common factor is prime and greater than 2
- s1 All of you add up to m
If boundary conditions are met , Then print the corresponding data .
#include<bits/stdc++.h>
using namespace std;
int N, k, m, n;
string s1;
bool flag;
bool isPrime(int a) {
if (a == 0 || a == 1)return false;
for (int i = 2; i <= sqrt(a); i++) {
if (a % i == 0)return false;
}
return true;
}
int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
int add(string s) {
int sum = 0;
for (int i = 0; i < s.length(); i++)
sum += s[i] - '0';
return sum;
}
void dfs(int step) {
if (step == k) {
int t = gcd(m, add(to_string(stoi(s1) + 1)));
if (t > 2 && add(s1) == m && isPrime(t)) {
printf("%d %s\n", add(to_string(stoi(s1) + 1)), s1.c_str());
flag = true;
}
return;
}
for (int i = 0; i <= 9; i++) {
s1 += i + '0';
dfs(step + 1);
s1.erase(s1.length() - 1);
}
}
int main() {
cin >> N;
int i;
for (i = 0; i < N; i++) {
cin >> k >> m;
s1 = "";
flag = false;
printf("Case %d\n", i + 1);
dfs(0);
if (!flag) cout << "No Solution\n";
}
return 0;
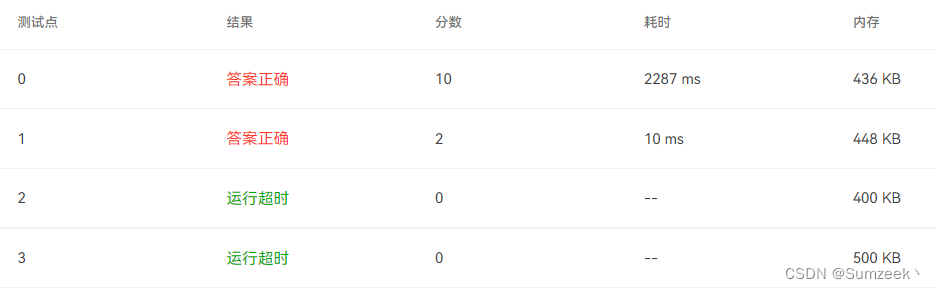
}Here are the results of the run , There are two test point timeouts , But the basic logic is ok , So we need to optimize the algorithm .
Case 2:
My first thought is to use a tepm Record s1 The maximum length that a string can also use , For example, the input (6,44),s1 The length is 6 When you add, you must be equal to 44, Suppose that s1=99999 when ,s1 The length of is only 5 however s1 You have accumulated to 45, Therefore, there is no need to try in the future ( prune ), It can reduce the running time of the algorithm , At the same time dfs When judging the boundary conditions , Some statements are redundant , Twice , Therefore, you can also use a temporary variable to store , Avoid multiple operations .
#include<bits/stdc++.h>
using namespace std;
int N, k, m, n;
int tmpm;
string s1;
bool flag;
bool isPrime(int a) {
if (a == 0 || a == 1)return false;
for (int i = 2; i <= sqrt(a); i++) {
if (a % i == 0)return false;
}
return true;
}
int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
int add(string s) {
int sum = 0;
for (int i = 0; i < s.length(); i++)
sum += s[i] - '0';
return sum;
}
void dfs(int step) {
if (step == k) {
int n1 = add(to_string(stoi(s1) + 1));
int t = gcd(m, n1);
if (t > 2 && 0 == tmpm && isPrime(t)) {
printf("%d %s\n", n1, s1.c_str());
flag = true;
}
return;
}
for (int i = 0; i <= 9; i++) {
s1 += i + '0';
tmpm -= i;
if (tmpm >= 0)
dfs(step + 1);
tmpm += i;
s1.erase(s1.length() - 1);
}
}
int main() {
cin >> N;
int i;
for (i = 0; i < N; i++) {
printf("Case %d\n", i + 1);
cin >> k >> m;
tmpm = m;
if (k * 9 < m)
cout << "No Solution\n";
else {
s1 = "";
flag = false;
dfs(0);
if (!flag) cout << "No Solution\n";
}
}
return 0;
}
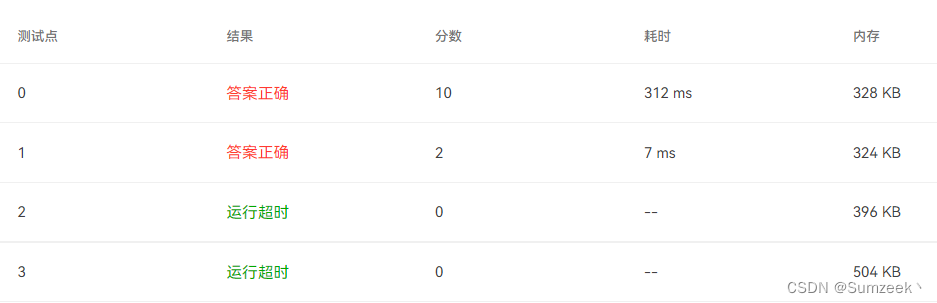
Although the test point 0 The time consumption is reduced , But the test point 2,3 Or overtime , Therefore, we need to optimize our thinking .
Case 3:
The optimization idea comes from Handsome BIA The blog of , We neglected a very important point when examining the question , That's it m and n The greatest common factor of must be greater than 2, It's easy to know s1 The bit of the final result must be 9, If not 9 be n=m+1, that n And m The greatest common factor of must only be 1, Because the greatest common factor of two adjacent positive integers is 1, Only s1 The last digit of is 9 Or the end is continuous 9, After adding one, the end becomes 0 It is possible to make m And n The greatest common factor of is greater than 2.
We also ignore a condition of the topic , That is the result according to n In ascending order of size , Therefore, the vector group is used to store the results , Then sort the vector group and output , We can get the result .
#include<bits/stdc++.h>
using namespace std;
int N, k, m, n;
int tmpm;
string s1;
struct node {
int n;
string s;
}tmp;
vector<node> v;
bool cmp(node a, node b) {
if (a.n != b.n) return a.n < b.n;
else return a.s < b.s;
}
bool isPrime(int a) {
if (a == 0 || a == 1)return false;
for (int i = 2; i <= sqrt(a); i++) {
if (a % i == 0)return false;
}
return true;
}
int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
int add(string s) {
int sum = 0;
for (int i = 0; i < s.length(); i++)
sum += s[i] - '0';
return sum;
}
void dfs(int step) {
if (tmpm < 0)
return;
if (step == k - 2) {
s1 += "99";
int n1 = add(to_string(stoi(s1) + 1));
int t = gcd(m, n1);
if (t > 2 && 0 == tmpm && isPrime(t)) {
tmp.n = n1; tmp.s = s1;
v.push_back(tmp);
}
s1.erase(s1.length() - 2);
return;
}
for (int i = 0; i <= 9; i++) {
s1 += i + '0';
tmpm -= i;
dfs(step + 1);
tmpm += i;
s1.erase(s1.length() - 1);
}
}
int main() {
cin >> N;
int i, j;
for (i = 0; i < N; i++) {
printf("Case %d\n", i + 1);
cin >> k >> m;
tmpm = m - 18;
if (k * 9 < m)
cout << "No Solution\n";
else {
s1 = "";
v.clear();
dfs(0);
if (v.size() == 0) cout << "No Solution\n";
else {
sort(v.begin(), v.end(), cmp);
for (j = 0; j < v.size(); j++)
printf("%d %s\n", v[j].n, v[j].s.c_str());
}
}
}
return 0;
}
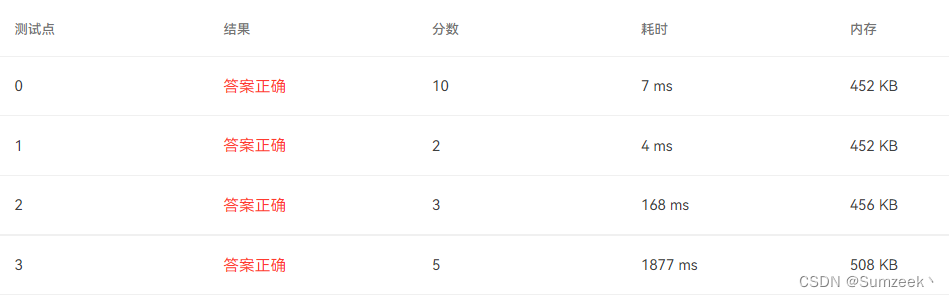
The optimized algorithm can run past the test point 2,3 , a AC.
边栏推荐
- 你真的懂继电器吗?
- 销毁Session和清空指定的属性
- [C language] MD5 encryption for account password
- JS finds all the parent nodes or child nodes under a node according to the tree structure
- Idea format code idea set shortcut key format code
- Practice of traffic recording and playback in vivo
- 左连接,内连接
- Force deduction ----- the minimum path cost in the grid
- Cron表达式介绍
- How to return ordered keys after counter counts the quantity
猜你喜欢
VS code配置虚拟环境
【PyG】理解MessagePassing过程,GCN demo详解

Privatization lightweight continuous integration deployment scheme -- 01 environment configuration (Part 2)
vfork执行时出现Segmentation fault

VS 2019 配置tensorRT生成engine
From C to capable -- use the pointer as a function parameter to find out whether the string is a palindrome character

用docker 连接mysql的过程

The idea cannot be loaded, and the market solution can be applied (pro test)

C语言初阶-指针详解-庖丁解牛篇
![[error record] the parameter 'can't have a value of' null 'because of its type, but the im](/img/1c/46d951e2d0193999f35f14d18a2de0.jpg)
[error record] the parameter 'can't have a value of' null 'because of its type, but the im
随机推荐
程序员新人上午使用 isXxx 形式定义布尔类型,下午就被劝退?
com.fasterxml.jackson.databind.exc.InvalidFormatException问题
Left connection, inner connection
内存泄漏工具VLD安装及使用
别再用 System.currentTimeMillis() 统计耗时了,太 Low,StopWatch 好用到爆!
Segmentation fault occurs during VFORK execution
The file marked by labelme is converted to yolov5 format
How to use asp Net MVC identity 2 change password authentication- How To Change Password Validation in ASP. Net MVC Identity 2?
迅雷chrome扩展插件造成服务器返回的数据js解析页面数据异常
Model transformation onnx2engine
Destroy the session and empty the specified attributes
Basic information of Promethus (I)
ASP. Net core 6 framework unveiling example demonstration [02]: application development based on routing, MVC and grpc
为什么线程崩溃不会导致 JVM 崩溃
Vs Code configure virtual environment
PAT乙级“1104 天长地久”DFS优化思路
[Chongqing Guangdong education] cultural and natural heritage reference materials of China University of Geosciences (Wuhan)
Vs 2019 configure tensorrt to generate engine
I2C 子系统(一):I2C spec
[combinatorics] number of solutions of indefinite equations (number of combinations of multiple sets R | number of non negative integer solutions of indefinite equations | number of integer solutions