当前位置:网站首页>Activate function and its gradient
Activate function and its gradient
2022-07-05 22:43:00 【dying_ star】
Activation function ----sigmoid()

tanh Activation function
relu Activation function 
softmax Activation function


here yi representative pi, zi Independent variable ,0<=pi<=1,p1+p2+...+pi+...+pc=1
Find gradient function

autograd.grad() Directly return gradient information
.backward() Attach gradient attributes to variables
Perceptron gradient derivation
import torch
from torch.nn import functional as F
x=torch.randn(1,10)
w=torch.randn(2,10,requires_grad=True)# Mark w For objects that need gradient information
o=torch.sigmoid([email protected]())# To sum by weight , use sigmoid() Activation function
loss=F.mse_loss(torch.ones(1,2),o)# Mean square loss function
loss.backward()# Right w Gradient of
print(w.grad)Output gradient
tensor([[ 0.0066, -0.0056, -0.0027, 0.0118, -0.0050, 0.0314, 0.0100, -0.0274,
-0.0006, -0.0448],
[ 0.0182, -0.0155, -0.0075, 0.0326, -0.0138, 0.0871, 0.0277, -0.0760,
-0.0017, -0.1241]])
边栏推荐
- 509. Fibonacci Number. Sol
- Platform bus
- Go language learning tutorial (XV)
- Metasploit(msf)利用ms17_010(永恒之蓝)出现Encoding::UndefinedConversionError问题
- Global and Chinese market of networked refrigerators 2022-2028: Research Report on technology, participants, trends, market size and share
- [secretly kill little buddy pytorch20 days] - [Day2] - [example of picture data modeling process]
- 2022-07-05: given an array, you want to query the maximum value in any range at any time. If it is only established according to the initial array and has not been modified in the future, the RMQ meth
- Technology cloud report: how many hurdles does the computing power network need to cross?
- All expansion and collapse of a-tree
- APK加固技术的演变,APK加固技术和不足之处
猜你喜欢

链表之双指针(快慢指针,先后指针,首尾指针)
Solutions for unexplained downtime of MySQL services
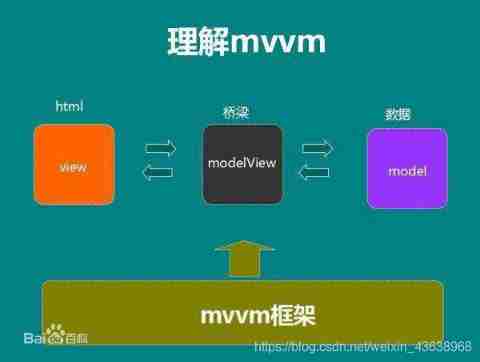
The difference between MVVM and MVC
What if the files on the USB flash disk cannot be deleted? Win11 unable to delete U disk file solution tutorial
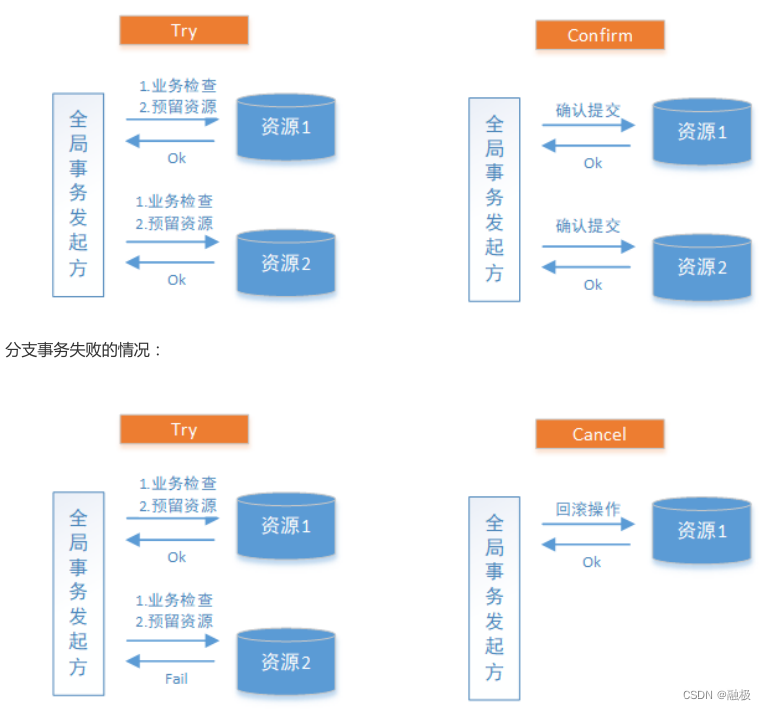
TCC of distributed solutions

Metaverse Ape获Negentropy Capital种子轮融资350万美元
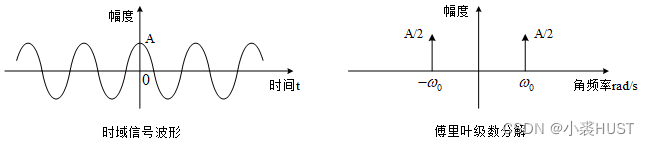
傅里叶分析概述
I closed the open source project alinesno cloud service
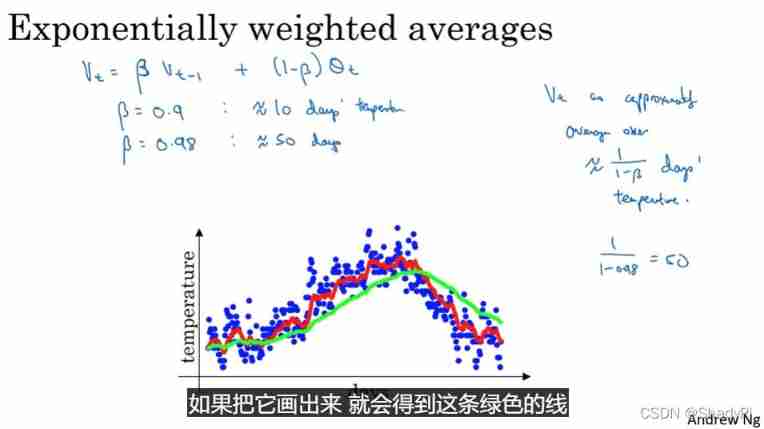
Exponential weighted average and its deviation elimination
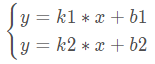
点到直线的距离直线的交点及夹角
随机推荐
记录几个常见问题(202207)
Text组件新增内容通过tag_config设置前景色、背景色
Navigation day answer applet: preliminary competition of navigation knowledge competition
VIM tail head intercept file import
[untitled]
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
FBO and RBO disappeared in webgpu
How to quickly experience oneos
Solutions for unexplained downtime of MySQL services
How to reverse a string fromCharCode? - How to reverse String. fromCharCode?
2022 Software Test Engineer salary increase strategy, how to reach 30K in three years
Nangou Gili hard Kai font TTF Download with installation tutorial
513. Find the value in the lower left corner of the tree
The new content of the text component can be added through the tag_ Config set foreground and background colors
2022-07-05: given an array, you want to query the maximum value in any range at any time. If it is only established according to the initial array and has not been modified in the future, the RMQ meth
Wonderful review of the digital Expo | highlight scientific research strength, and Zhongchuang computing power won the digital influence enterprise award
ESP32 hosted
Why does the C# compiler allow an explicit cast between IEnumerable&lt; T&gt; and TAlmostAnything?
Editor extensions in unity
基于STM32的ADC采样序列频谱分析