当前位置:网站首页>视频自监督学习综述
视频自监督学习综述
2022-07-05 18:32:00 【智源社区】

https://arxiv.org/abs/2207.00419
深度学习在各个领域的显著成功依赖于大规模注释数据集的可用性。然而,使用人工生成的注释会导致模型有偏差学习、领域泛化能力差和鲁棒性差。获取注释也很昂贵,需要付出很大的努力,这对视频来说尤其具有挑战性。作为另一种选择,自监督学习提供了一种不需要注释的表示学习方法,在图像和视频领域都显示出了前景。与图像域不同,学习视频表示更具有挑战性,因为时间维度,引入了运动和其他环境动力学。这也为在视频和多模态领域推进自监督学习的独家想法提供了机会。在这项综述中,我们提供了一个现有的方法在视频领域的自监督学习重点。我们根据它们的学习目标将这些方法总结为三种不同的类别: 1) 文本预置任务,2) 生成式建模,和 3)对比学习。这些方法在使用的方式上也有所不同; 1) video, 2) video-audio, 3) video-text, 4) video-audio-text。我们进一步介绍了常用的数据集、下游评估任务、现有工作的局限性以及该领域未来的潜在方向。
对大规模标记样本的要求限制了深度网络在数据有限且标注困难的问题上的使用,例如医学成像Dargan et al. [2020]。虽然在ImageNet Krizhevsky等人[2012a]和Kinetics Kay等人[2017]的大规模标记数据集上进行预训练确实能提高性能,但这种方法存在一些缺陷,如注释成本Yang et al. [2017], Cai et al. [2021],注释偏差Chen和Joo [2021], Rodrigues和Pereira[2018],缺乏域泛化Wang等人[2021a], Hu等人[2020],Kim等人[2021],以及缺乏鲁棒性Hendrycks和Dietterich[2019]。Hendrycks等[2021]。自监督学习(SSL)已经成为预训练深度模型的一种成功方法,以克服其中一些问题。它是一种很有前途的替代方案,可以在大规模数据集上训练模型,而不需要标记Jing和Tian[2020],并且具有更好的泛化性。SSL使用一些来自训练样本本身的学习目标来训练模型。然后,这个预训练的模型被用作目标数据集的初始化,然后使用可用的标记样本对其进行微调。图1显示了这种方法的概览。
边栏推荐
- sample_rate(采样率),sample(采样),duration(时长)是什么关系
- 【在优麒麟上使用Electron开发桌面应】
- node_exporter内存使用率不显示
- How can cluster deployment solve the needs of massive video access and large concurrency?
- Maximum artificial island [how to make all nodes of a connected component record the total number of nodes? + number the connected component]
- 爬虫01-爬虫基本原理讲解
- node_ Exporter memory usage is not displayed
- SAP feature description
- FCN: Fully Convolutional Networks for Semantic Segmentation
- rust统计文件中单词出现的次数
猜你喜欢

图片数据不够?我做了一个免费的图像增强软件

LeetCode 6111. 螺旋矩阵 IV
Thoroughly understand why network i/o is blocked?
Use JMeter to record scripts and debug
node_ Exporter memory usage is not displayed
![Maximum artificial island [how to make all nodes of a connected component record the total number of nodes? + number the connected component]](/img/8b/a60fc36115580f018445e4c2a28a9d.png)
Maximum artificial island [how to make all nodes of a connected component record the total number of nodes? + number the connected component]
Reptile 01 basic principles of reptile
Wu Enda team 2022 machine learning course, coming
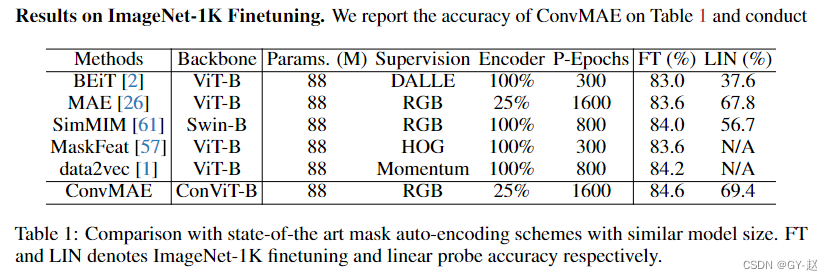
ConvMAE(2022-05)
buuctf-pwn write-ups (9)
随机推荐
ConvMAE(2022-05)
U-Net: Convolutional Networks for Biomedical Images Segmentation
U-Net: Convolutional Networks for Biomedical Images Segmentation
[paddleclas] common commands
Exemple Quelle est la relation entre le taux d'échantillonnage, l'échantillon et la durée?
技术分享 | 常见接口协议解析
About statistical power
The origin of PTS, DTS and duration of audio and video packages
第十一届中国云计算标准和应用大会 | 云计算国家标准及白皮书系列发布 华云数据全面参与编制
7-2 keep the linked list in order
《ClickHouse原理解析与应用实践》读书笔记(5)
ViewPager + RecyclerView的内存泄漏
What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
Record a case of using WinDbg to analyze memory "leakage"
vulnhub之darkhole_2
常见时间复杂度
sample_ What is the relationship between rate, sample and duration
ClickHouse(03)ClickHouse怎么安装和部署
Maximum artificial island [how to make all nodes of a connected component record the total number of nodes? + number the connected component]
sample_rate(采样率),sample(采样),duration(时长)是什么关系