当前位置:网站首页>《ClickHouse原理解析与应用实践》读书笔记(5)
《ClickHouse原理解析与应用实践》读书笔记(5)
2022-07-05 18:18:00 【Aiky哇】
开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第六章:
第7章 MergeTree系列表引擎
7.1 MergeTree
本节将进一步介绍MergeTree家族独有的另外两项能力 ——数据TTL与存储策略。
7.1.1 数据TTL
TTL即Time To Live,它表示数据的存活时间。
在MergeTree中,可以为某个列字段或整张表设置TTL。 列级别删除列数据,表级别删除表数据,同时设置的话以先到期的为主。
TTL需要依赖于DateTime或Date类型的字段。
-- 数据存活时间是time_col时间的3天之后
TTL time_col + INTERVAL 3 DAY
-- 数据存活时间是time_col时间的1月之后
TTL time_col + INTERVAL 1 MONTHINTERVAL完整的操作包括SECOND、 MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER和YEAR。
1.列级别TTL
主键字段不能被声明TTL。
举例:create_time是日期类型,列字段code与type均被设置了TTL,它们的存活时间是在 create_time的取值基础之上向后延续10秒。
sql尝试:
CREATE TABLE ttl_table_v1(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 10 SECOND,
type UInt8 TTL create_time + INTERVAL 10 SECOND
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
INSERT INTO TABLE ttl_table_v1 VALUES('A000',now(),'C1',1),
('A000',now() + INTERVAL 10 MINUTE,'C1',1);
SELECT * FROM ttl_table_v1;
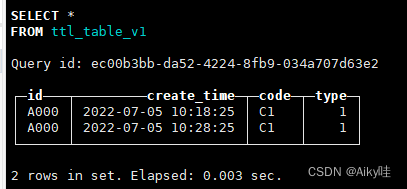
等待10s之后再次查询
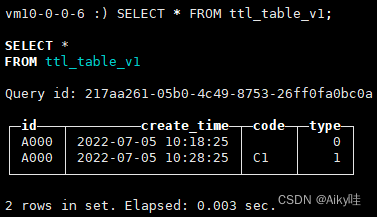
如果没有清除,执行optimize TABLE ttl_table_v1 FINAL再次尝试。
能够看到,由于第一行数据满足TTL过期条件(当前系统时间 >=create_time+10秒),它们的code和type列会被还原为数据类型的默认值。
修改列字段的TTL,或是为已有字段添加TTL,则可以使用ALTER语句:
ALTER TABLE ttl_table_v1 MODIFY COLUMN code String TTL create_time + INTERVAL 1 DAY目前ClickHouse没有提供取消列级别TTL的方法。
2.表级别TTL
当触发TTL清理时,那些满足过期时间的数据行将会被整行删除。
CREATE TABLE ttl_table_v2(
id String,
create_time DateTime,
code String TTL create_time + INTERVAL 1 MINUTE,
type UInt8
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
TTL create_time + INTERVAL 1 DAY
ALTER TABLE ttl_table_v2 MODIFY TTL create_time + INTERVAL 3 DAY表级别TTL目前也没有取消的方法。
3.TTL的运行机理
在写入数据时,会以数据分区为单位,在每个分区目录内生成一个名为ttl.txt的文件。
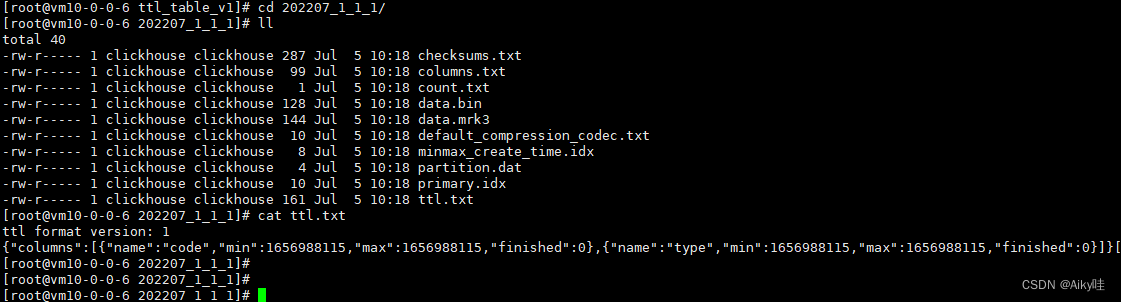
来MergeTree是通过一串JSON配置保存了TTL的相关信息。
其中:
- columns用于保存列级别TTL信息;
- table用于保存表级别TTL信息;
min和max则保存了当前数据分区内,TTL指定日期字段的最小值、最大值分别与INTERVAL表达 式计算后的时间戳。
SELECT
toDateTime('1656988115') AS ttl_min,
toDateTime('1656988115') AS ttl_max,
ttl_min - MIN(create_time) AS expire_min,
ttl_max - MAX(create_time) AS expire_max
FROM ttl_table_v1 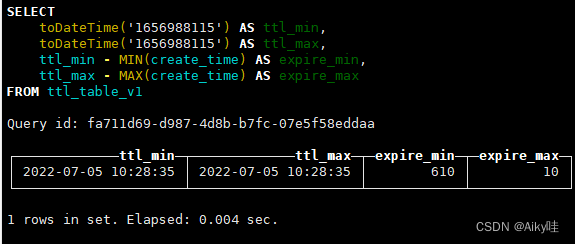
能够发现ttl.txt中记录的极值区间恰好等于当前数据分区内create_time最小与最大值增加10s。
与TTL表达式code String TTL create_time + INTERVAL 10 SECOND相符。
TTL大致处理逻辑:
- 每写入一批数据,会基于INTERVAL表达式的计算结果为这个分区生成ttl.txt文件,ttl.txt文件记录过期时间。
- 只有在MergeTree合并分区时,才会触发删除TTL过期数据的逻辑。
- 在选择删除的分区时,会使用贪婪算法,它的算法规则是尽可能找到会最早过期的,同时年纪又是最老的分区(合并次数更多,MaxBlockNum更大的)。
- 如果一个分区内某一列数据因为TTL到期全部被删除了,那么在合并之后生成的新分区目录中,将不会包含这个列字段的数据文件(.bin和.mrk)。
TTL默认的合并频率由MergeTree的merge_with_ttl_timeout参数控制,默认86400秒,即1天。它维护的是一个专有的TTL任务队列。有别于MergeTree的常规合并任务,如果这个值被设置的过小,可能会带来性能损耗。
可以使用optimize命令强制触发合并。
-- 触发一个分区合并
optimize TABLE table_name
-- 触发所有分区合并
optimize TABLE table_name FINAL
-- 控制全局TTL合并任务的启停方法
SYSTEM STOP/START TTL MERGES
7.1.2 多路径存储策略
自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
根据配置策略的不同,目前大致有三类存储策略:
- 默认策略:MergeTree原本的存储策略,无须任何配置,所有分区会自动保存到config.xml配置中path指定的路径下。
- JBOD策略:一种轮询策略,每执行一次INSERT或者 MERGE,所产生的新分区会轮询写入各个磁盘。适合服务器挂载了多块磁盘,但没有做RAID的场景,可以降低单块磁盘的负载,在一定条件下能够增加数据并行读写的性能。
- HOT/COLD策略:HOT区域使用SSD这类高性能存储媒介,注重存取性能; COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。数据在写入MergeTree 之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据大小累积到阈值时,数据会自行移动到COLD区域。每个区域内可以多块磁盘,实现JBOD策略。
存储配置需要预先定义在config.xml配置文件中,由storage_configuration标签表示。
在storage_configuration之下又分为disks和policies两组标签,分别表示磁盘与存储策略。
<storage_configuration>
<disks>
<disk_name_a> <!--自定义磁盘名称 -->
<path>/chbase/data</path><!—磁盘路径 -->
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_name_a>
<disk_name_b>
<path>… </path>
</disk_name_b>
</disks>
<policies>
<policie_name_a> <!--自定义策略名称 -->
<volumes>
<volume_name_a> <!--自定义卷名称 -->
<disk>disk_name_a</disk>
<disk>disk_name_b</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</volume_name_a>
</volumes>
<move_factor>0.2</move_factor>
</policie_name_a>
<policie_name_b>
</policie_name_b>
</policies>
</storage_configuration>
- <disk_name_*> 必填项,必须全局唯一,表示磁盘的自定义名称;
- <path>必填项,用于指定磁盘路径;
- <keep_free_space_bytes>选填项,以字节为单位,用于定义磁盘的预留空间。
- <policie_name_*>必填项,必须全局唯一,表示策略的自定义名称;
- <volume_name_*>必填项,必须全局唯一,表示卷的自定义名称;
- <disk>必填项,引用先前定义的disks磁盘,用于关联配置内的磁盘,可以声明多个disk,MergeTree会按定义的顺序选择disk;
- <max_data_part_size_bytes>选填项,以字节为单位,表示在这个卷的单 个disk磁盘中,一个数据分区的最大存储阈值,如果当前分区的数据大小超过阈 值,则之后的分区会写入下一个disk磁盘;
- <move_factor>选填项,默认为0.1;如果当前卷的可用空间小于factor因子,并且定义了多个卷,则数据会自动向下一个卷移动。
1.JBOD策略
<storage_configuration>
<!--自定义磁盘配置 -->
<disks>
<disk_hot1> <!--自定义磁盘名称 -->
<path>/chbase/data</path>
</disk_hot1>
<disk_hot2>
<path>/chbase/hotdata1</path>
</disk_hot2>
<disk_cold>
<path>/chbase/cloddata</path>
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_cold>
</disks>
<!-- 实现JDOB效果 -->
<policies>
<default_jbod> <!--自定义策略名称 -->
<volumes>
<jbod> <!—自定义名称 磁盘组 -->
<disk>disk_hot1</disk>
<disk>disk_hot2</disk>
</jbod>
</volumes>
</default_jbod>
</policies>
</storage_configuration>首先在disks中配置3块磁盘。
然后配置一个存储策略,在volumes卷下引用两块磁盘,组成一个磁盘组。
一个支持JBOD策略的存储策略就配置好了。
直接使用书中的演示:
-- 查看磁盘配置
SELECT
name,
path,formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved
FROM system.disks
┌─name─────┬─path────────┬─free────┬─total────┬─reserved─┐
│ default │ /chbase/data/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
│ │ │ │ │ │
│ disk_cold │ /chbase/cloddata/ │ 37.26 GiB │ 48.09 GiB │ 1.00 GiB │
│ disk_hot1 │ /chbase/data/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
│ disk_hot2 │ /chbase/hotdata1/ │ 38.26 GiB │ 49.09 GiB │ 0.00 B │
└────────┴────────────┴────────┴────────┴───────┘
-- 查看配置的存储策略
SELECT policy_name,
volume_name,
volume_priority,
disks,
formatReadableSize(max_data_part_size) max_data_part_size ,
move_factor FROM
system.storage_policies
┌─policy_name─┬─volume_name─┬─disks──────────┬─max_data_part_size─┬─move_factor─┐
│ default │ default │ ['default'] │ 0.00 B │ 0 │
│ default_jbod │ jbod │ ['disk_hot1','disk_hot2']│ 0.00 B │ 0.1 │
└────────┴────────┴─────────────┴──────────┴─────────┘
-- 定义表的时候使用jbod
CREATE TABLE jbod_table(
id UInt64
)ENGINE = MergeTree()
ORDER BY id
SETTINGS storage_policy = 'default_jbod'
-- 写入第一批数据
INSERT INTO TABLE jbod_table SELECT rand() FROM numbers(10)
-- 查询分区系统表,可以看到第一个分区写入了第一块磁盘disk_hot1
SELECT name, disk_name FROM system.parts WHERE table = 'jbod_table'
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
└────────┴───────┘
-- 写入第二批数据
INSERT INTO TABLE jbod_table SELECT rand() FROM numbers(10)
-- 第二个分区写入了第二块磁盘disk_hot2:
SELECT name, disk_name FROM system.parts WHERE table = 'jbod_table'
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
│ all_2_2_0 │ disk_hot2 │
└────────┴───────┘
-- 触发一次分区合并动作,生成一个合并后的新分区目录:
optimize TABLE jbod_table
-- 新分区再一次写入了第一块磁盘disk_hot1:
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
│ all_1_2_1 │ disk_hot1 │
│ all_2_2_0 │ disk_hot2 │
└────────┴───────┘
2.HOT/COLD策略
添加一 个新的策略:
<policies>
…省略
<moving_from_hot_to_cold><!--自定义策略名称 -->
<volumes>
<hot><!--自定义名称 ,hot区域磁盘 -->
<disk>disk_hot1</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold><!--自定义名称 ,cold区域磁盘 -->
<disk>disk_cold</disk>
</cold>
</volumes>
<move_factor>0.2</move_factor>
</moving_from_hot_to_cold>
</policies>moving_from_hot_to_cold存储策略拥有hot和cold两个磁盘卷,在每个卷下各拥有1块磁盘。
使用书中的演示:
-- 查询system.storage_policies系统表
┌─policy_name────────┬─volume_name┬─disks────┬max_data_part_size─┬─move_factor─┐
│ moving_from_hot_to_cold │ hot │ ['disk_hot1']│ 1.00 MiB │ 0.2 │
│ moving_from_hot_to_cold │ cold │ ['disk_cold']│ 0.00 B │ 0.2 │
└───────────────┴───────┴────────┴──────────┴────────┘
-- 创建表
CREATE TABLE hot_cold_table(
id UInt64
)ENGINE = MergeTree()
ORDER BY id
SETTINGS storage_policy = 'moving_from_hot_to_cold'
-- 写入500K大小,分区会写入hot
INSERT INTO TABLE hot_cold_table SELECT rand()FROM numbers(100000)
-- 查询分区
SELECT name, disk_name FROM system.parts WHERE table = 'hot_cold_table'
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
└────────┴───────┘
-- 写入第二批数据
INSERT INTO TABLE hot_cold_table SELECT rand()FROM numbers(100000)
-- 查询发现仍然写入了hot卷
-- 由于hot磁盘卷的max_data_part_size是1MB,而前两次数据写入所创建的分区,单个分区大小是500KB,自然分区目录都被保存到了hot磁盘卷下的disk_hot1磁盘。
SELECT name, disk_name FROM system.parts WHERE table = 'hot_cold_table'
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
│ all_2_2_0 │ disk_hot1 │
└────────┴───────┘
-- 触发一次分区合并动作
optimize TABLE hot_cold_table
-- 新分区的大小超过了1MB,所以它被写入了cold卷
┌─name─────┬─disk_name─┐
│ all_1_1_0 │ disk_hot1 │
│ all_1_2_1 │ disk_cold │
│ all_2_2_0 │ disk_hot1 │
└────────┴───────┘
如果一次性写入大于1MB的数据,分区也会被写入cold卷。
HOT/COLD策略中,多个磁盘卷(volume卷)组成了一个volume组。
每个新分区的数据,按照阈值大小(max_data_part_size),分区目录会依照volume组中磁盘卷定义的顺序,依次轮询并写入各个卷下的磁盘。
虽然MergeTree的存储策略目前不能修改,但是分区目录却支持移动。
例如,将某个分区移动至当前存储策略中当前volume卷下的其他disk磁盘:
ALTER TABLE hot_cold_table MOVE PART 'all_1_2_1' TO DISK 'disk_hot1'
ALTER TABLE hot_cold_table MOVE PART 'all_1_2_1' TO VOLUME 'cold'
7.2 ReplacingMergeTree
普通的MergeTree主键没有唯一键的约束。
ReplacingMergeTree能够在合并分区时删除重复的数据。
只需要替换Engine :ENGINE = ReplacingMergeTree(ver)。ver参数决定了数据去重时所使用的算法。
CREATE TABLE replace_table(
id String,
code String,
create_time DateTime
)ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,code)
PRIMARY KEY id
ORDER BY所声明的表达式是后续作为判断数据是否重复的依据。
在执行optimize强制触发合并后,会按照id和code分组,保留分组内的最后一条(观察create_time日期字段),将其余重复的数据删除。
但是ReplacingMergeTree是以分区为单位删除重复数据的,只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
ReplacingMergeTree:
- 使用ORBER BY排序键作为判断重复数据的唯一键。
- 只有在合并分区的时候才会触发删除重复数据的逻辑。
- 以数据分区为单位删除重复数据。当分区合并时,同一分区 内的重复数据会被删除;不同分区之间的重复数据不会被删除。
- 在进行数据去重时,因为分区内的数据已经基于ORBER BY进 行了排序,所以能够找到那些相邻的重复数据。
- 如果没有设置ver版本号,则保留同一组重复数据中的最后一 行。如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
7.3 SummingMergeTree
查询场景:
- 用户只需要查询数据的汇总结果, 不关心明细数据
- 数据的汇总条件是预先明确的(GROUP BY条件明确,且不会随意改变)。
如果是普通的MergeTree,因为用户不会查询明细数据,所以存储所有的数据并非必要。而且每次需要计算,也不是必要的。
SummingMergeTree能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
通常情况下,order by键和primiary key是相同的,但是明确不同的情况只会在SummingMergeTree与AggregatingMergeTree中出现。两点原因:主键与聚合的条件定义分离,为修改聚合条件留下空间。
ENGINE = SummingMergeTree((col1,col2,…))
-- col1、col2为columns参数值,这是一个选填参数,用于设置除主键外的其他数值类型字段,以指定被SUM汇总的列字段。
-- 如若不填写此参数,则会将所有非主键的数值类型字段进行SUM汇总。
-- 创建表
CREATE TABLE summing_table(
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
)ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id, city)
PRIMARY KEY id;
-- SummingMergeTree也支持嵌套类型的字段。
-- 需要被SUM汇总的字段名称必须以Map后缀结尾。
CREATE TABLE summing_table_nested(
id String,
nestMap Nested(
id UInt32,
key UInt32,
val UInt64
),
create_time DateTime
)ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id
-- 默认情况下,会以嵌套类型中第一个字段作为聚合条件Key
-- 也支持使用复合Key。
-- 除第一个字段以外,任何名称是以Key、Id或Type为后缀结尾的字段,都将和第一个字段一起组成复合Key
nestMap Nested(
id UInt32,
Key UInt32,
val UInt64
),
-- 上述例子中数据会以id和Key作为聚合条件。SummingMergeTree:
- 用ORBER BY排序键作为聚合数据的条件Key。
- 只有在合并分区的时候才会触发汇总的逻辑。
- 以数据分区为单位来聚合数据。不同数据分区不会合并。
- 如果在定义引擎时指定了columns汇总列(非主键的数值类型 字段),则SUM汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段。
- 相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
- 支持嵌套结构,但列字段名称必须以Map后缀结尾。嵌套类型中,默认以第一个字段作为聚合Key。除第一个字段以外,任何名称以 Key、Id或Type为后缀结尾的字段,都将和第一个字段一起组成复合 Key。
7.4 AggregatingMergeTree
在合并分区的时候,按照预先定义的条件聚合数据。
AggregatingMergeTree是SummingMergeTree的升级版。
【感觉可以完全代替SummingMergeTre】
声明使用AggregatingMergeTree的方式如下:ENGINE = AggregatingMergeTree()
没有任何额外的设置参数,在分区合并时,在每个数据分区内,会按照ORDER BY聚合。
使用何种聚合函数,以及针对哪些列字段计算,则是通过定义AggregateFunction数据类型实现的 。
CREATE TABLE agg_table(
id String,
city String,
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime
)ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,city)
PRIMARY KEY idid和city是聚合条件,等同于GROUP BY id,city
code和value是聚合字段,其语义等同于:UNIQ(code), SUM(value)
AggregateFunction是一种特殊的数据类型,它能够以二进制的形式存储中间状态结果。
需要调用*State函数写入,需要调用*Merge函数查询。*表示定义时使用的聚合函数。例如:
-- 写入数据
INSERT INTO TABLE agg_table
SELECT 'A000','wuhan',
uniqState('code1'),
sumState(toUInt32(100)),
'2019-08-10 17:00:00'
-- 查询数据
SELECT id,city,uniqMerge(code),sumMerge(value)
FROM agg_table
GROUP BY id,city看起来很繁琐,但是其实并不常用。
AggregatingMergeTree更为常见的应用方式是结合物化视图使用,将它作为物化视图的表引擎。
-- 创建基础表
CREATE TABLE agg_table_basic(
id String,
city String,
code String,
value UInt32
)ENGINE = MergeTree()
PARTITION BY city
ORDER BY (id,city)
-- 创建物化视图
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id,city)
AS
SELECT
id,
city,
uniqState(code) AS code,
sumState(value) AS value
FROM agg_table_basic
GROUP BY id, city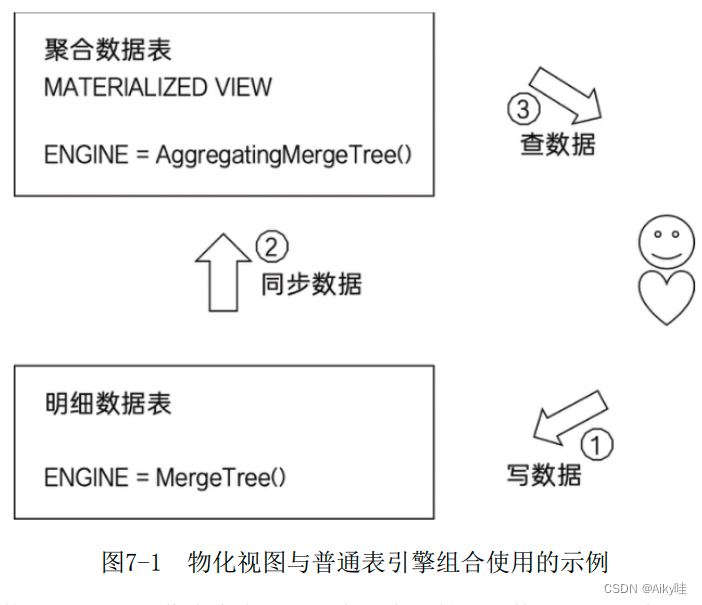 这样在新增数据时,面向的对象是底表MergeTree,数据会自动同步到物化视图,并按照AggregatingMergeTree引擎的规则处理。
这样在新增数据时,面向的对象是底表MergeTree,数据会自动同步到物化视图,并按照AggregatingMergeTree引擎的规则处理。
在查询数据时,面向的对象是物化视图AggregatingMergeTree。
SELECT id, sumMerge(value), uniqMerge(code) FROM agg_view GROUP BY id, cityAggregatingMergeTree:
- 用ORBER BY排序键作为聚合数据的条件Key。
- 使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字段。
- 只有在合并分区的时候才会触发聚合计算的逻辑。
- 以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并计算,而不同分区之间的数据则不会被计算。
- 对于那些非主键、非AggregateFunction类型字段,则会使用第一行数据的取值。
- AggregateFunction类型的字段使用二进制存储,在写入数据时,需要调用 *State函数;而在查询数据时,则需要调用相应的*Merge函数。其中,*表示定义时使用的聚合函数。
- AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用。
7.5 CollapsingMergeTree
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。
通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1, 则表示这行数据需要被删除。
-- 声明方法,sign用于指定一个Int8类型的标志位字段。
ENGINE = CollapsingMergeTree(sign)
-- 创建表
CREATE TABLE collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8
)ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
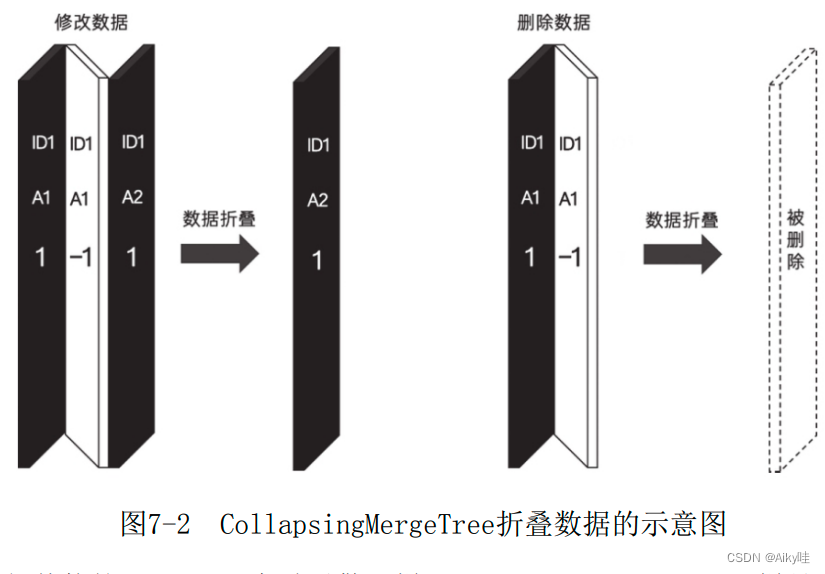
除了常规的新增数据操作之外,还能够支持两种操作。
-- 删除一行数据
--修改前的源数据, 它需要被删除
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1)
--镜像数据, ORDER BY字段与源数据相同, sign取反为-1, 它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1)
-- 修改一行数据
--修改前的源数据, 它需要被修改
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1)
--镜像数据, ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1)
--修改后的数据 ,sign为1
INSERT INTO TABLE collpase_table VALUES('A000',120,'2019-02-20 00:00:00',1)- 如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。
- 如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。
- 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
- 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1, 则什么也不保留。
- 其余情况,ClickHouse会打印警告日志,但不会报错,在这种情形下,查询结果不可预知。
CollapsingMergeTree:
- 折叠数据并不是实时触发的,合并触发。
- 相同分区内的数据才有可能被折叠。
- CollapsingMergeTree对于写入数据的顺序有着严格要求。先写入sign=1,再写入sign=-1,则能够正常折叠 。先写入sign=-1,再写入sign=1,则不能够折叠。并发写入的时候会出现这种问题。ClickHouse另外提供了一 个名为VersionedCollapsingMergeTree的表引擎解决。
7.6 VersionedCollapsingMergeTree
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写 入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
在定义VersionedCollapsingMergeTree的时候,除了需要指定sign标记字段以外,还需要指定一个UInt8类型的ver版本号字段:
ENGINE = VersionedCollapsingMergeTree(sign,ver)
CREATE TABLE ver_collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
)ENGINE = VersionedCollapsingMergeTree(sign,ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
VersionedCollapsingMergeTree会自动将ver作为排序条件并增加到ORDER BY的末端。
在每个数据分区内,数据会按照ORDER BY id,ver DESC排序。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
-- 删除
INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1,1)
-- 修改
INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A000',103,'2019-02-20 00:00:00',1,2)【感觉也很鸡肋】
7.7 各种MergeTree之间的关系总结
7.7.1 继承关系
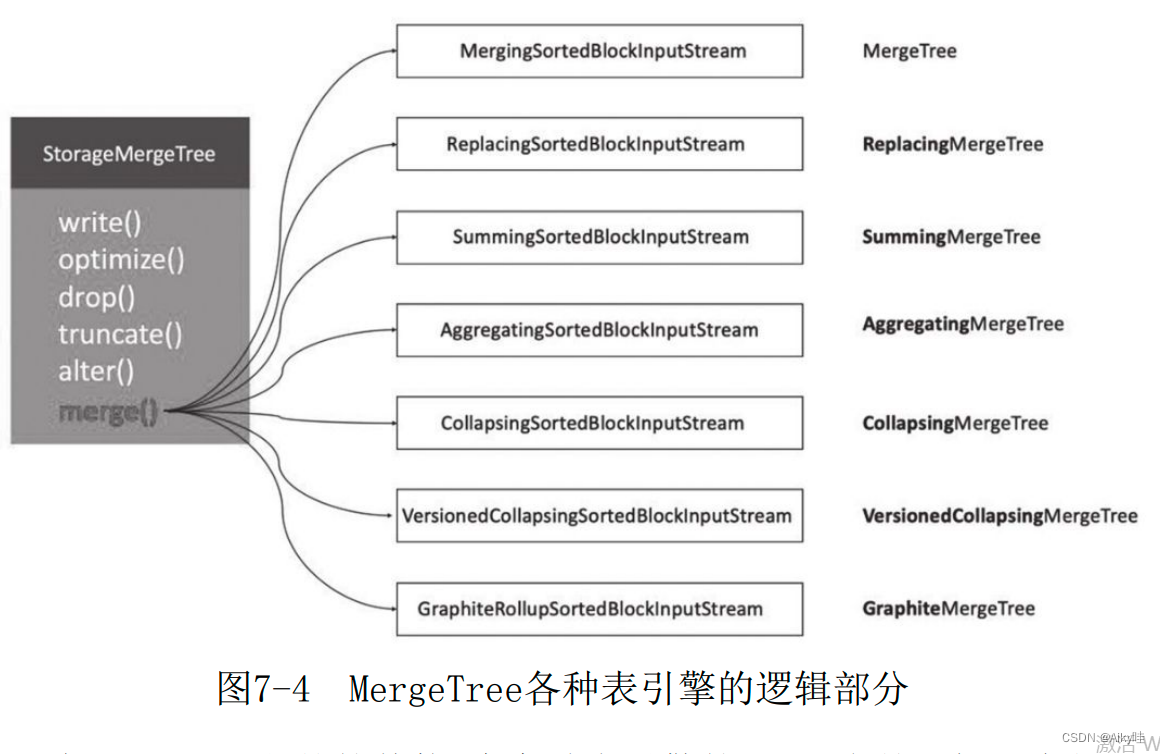
除MergeTree之外的其他6个变种表引擎的Merge合并逻辑,全部是建立在MergeTree基础之上的,且均继承于MergeTree的 MergingSortedBlockInputStream。
MergingSortedBlockInputStream的主要作用是按照ORDER BY的规则保持新分区数据的有序性。而其他6种变种MergeTree的合并逻辑, 则是在有序的基础之上“各有所长”
7.7.2 组合关系
介绍 ReplicatedMergeTree。
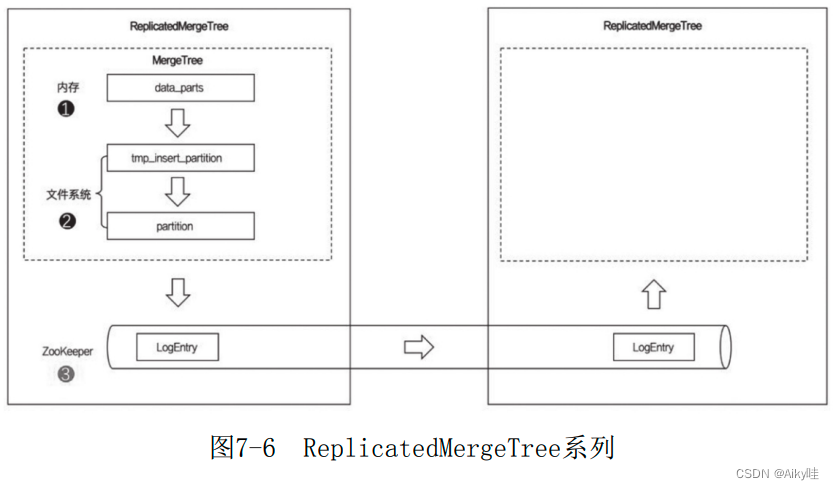
上图中的虚线框部分是MergeTree的能力边界,而 ReplicatedMergeTree在MergeTree能力的基础之上增加了分布式协同的能力,其借助ZooKeeper的消息日志广播功能,实现了副本实例之间的数据同步功能。
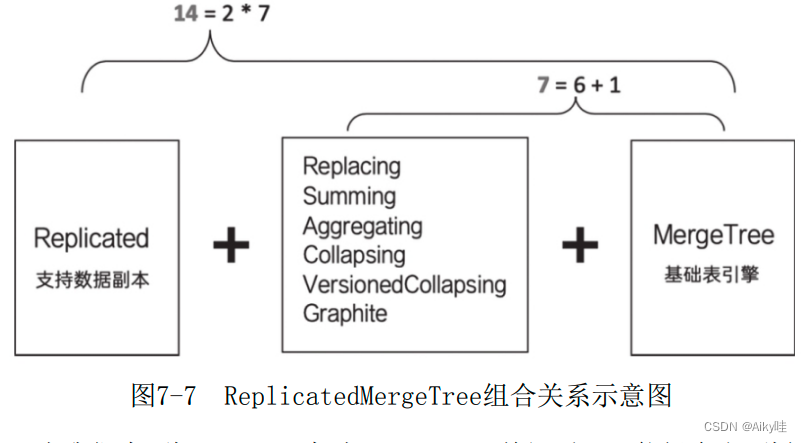
关于 ReplicatedMergeTree表引擎的详细说明见第10章。
7.8 本章小结
介绍TTL机制和多数据块存储。
MergeTree各个变种表引擎的特点和使用方法。
这些 MergeTree系列的表引擎,都用ORDER BY作为条件Key,在分区合并时 触发各自的处理逻辑。
【除了ReplacingMergeTree,AggregateMergeTree外,感觉都没有什么用】
第8章 其他常见类型表引擎
8.1 外部存储类型
外部存储表引擎直接从其他的存储系统读取数据。
这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。
8.1.1 HDFS
HDFS是一款分布式文件系统,HDFS表引擎则能够直接与它对接,读取HDFS内的文件。
HDFS表引擎的定义方法如下:
ENGINE = HDFS(hdfs_uri,format)- hdfs_uri表示HDFS的文件存储路径;
- format表示文件格式(指ClickHouse支持的文件格式,常见的有CSV、TSV 和JSON等)。
通常有两种使用形式:
- 既负责读文件,又负责写文件。
- 只负责读文件,文件写入工作则由其他外部系统完成。
-- 第一种使用方式
CREATE TABLE hdfs_table1(
id UInt32,
code String,
name String
)ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table1','CSV')
INSERT INTO hdfs_table1 SELECT number,concat('code',toString(number)),
concat('n',toString(number)) FROM numbers(5);
SELECT * FROM hdfs_table1
┌─id─┬─code─┬─name─┐
│ 0 │ code0 │ n0 │
│ 1 │ code1 │ n1 │
│ 2 │ code2 │ n2 │
│ 3 │ code3 │ n3 │
│ 4 │ code4 │ n4 │
└───┴─────┴────┘
此时,HDFS的指定目录下创建了一个名为hdfs_table1的文件,并且按照CSV格式写入了数据。
$ hadoop fs -cat /clickhouse/hdfs_table1
0,"code0","n0"
1,"code1","n1"
2,"code2","n2"
3,"code3","n3"
4,"code4","n4"ClickHouse并没有提供删除HDFS文件的方法,即便将数据表hdfs_table1删除,在HDFS上文件依然存在。
第二种使用方式由其他系统直接将文件写入HDFS。
通过HDFS表引擎的hdfs_uri和format参数分别与HDFS 的文件路径、文件格式建立映射。
hdfs_uri支持以下几种常见的配置方法:
- 绝对路径:会读取指定路径的单个文件,例如/clickhouse/hdfs_table1。
- *通配符:匹配所有字符,例如路径为/clickhouse/hdfs_table/*,则会读取/click-house/hdfs_table路径下的所有文件。
- ?通配符:匹配单个字符,例如路径为/clickhouse/hdfs_table/organization_?.csv,则会读 取/clickhouse/hdfs_table路径下与organization_?.csv匹配的文件,其中?代 表任意一个合法字符。
- {M..N}数字区间:匹配指定数字的文件,例如路径 为/clickhouse/hdfs_table/organization_{1..3}.csv,则会读取/clickhouse/hdfs_table/路径下的文件organization_1.csv、 organization_2.csv和organization_3.csv。
CREATE TABLE hdfs_table2(
id UInt32,
code String,
name String
) ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
-- *通配符
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
-- ?通配符
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_?.csv','CSV')
-- {M..N}数字区间
HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_{1..3}.csv','CSV')
8.1.2 MySQL
MySQL表引擎可以与MySQL数据库中的数据表建立映射,并通过SQL向其发起远程查询,包括 SELECT和INSERT,它的声明方式如下:
ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause'])- host:port表示MySQL的地址和端口。
- database表示数据库的名称。
- table表示需要映射的表名称。
- user表示MySQL的用户名。
- password表示MySQL的密码。
- replace_query默认为0,对应MySQL的REPLACE INTO语法。如果将它设置为1,则会用REPLACE INTO代替INSERT INTO。
- on_duplicate_clause默认为0,对应MySQL的ON DUPLICATE KEY语法。如果需要使用该设置, 则必须将replace_query设置成0。
CREATE TABLE dolphin_scheduler_table(
id UInt32,
name String
)ENGINE = MySQL('10.37.129.2:3306', 'escheduler', 't_escheduler_process_definition', 'root', '')
INSERT INTO TABLE dolphin_scheduler_table VALUES (4,'流程4')
发现数据已被写入远端的MySQL表内了。
此时可以使用物化视图搭配mysql来使用
CREATE MATERIALIZED VIEW view_mysql1
ENGINE = MergeTree()
ORDER BY id
AS SELECT * FROM dolphin_scheduler_table当通过MySQL表引擎向远端MySQL数据库写入数据的同时,物化视图也会同步更新数据。
目前MySQL表引擎不支持任何UPDATE和DELETE操作,如果有数据更新方面的诉求,可以考虑使用CollapsingMergeTree作为视图的表引擎。
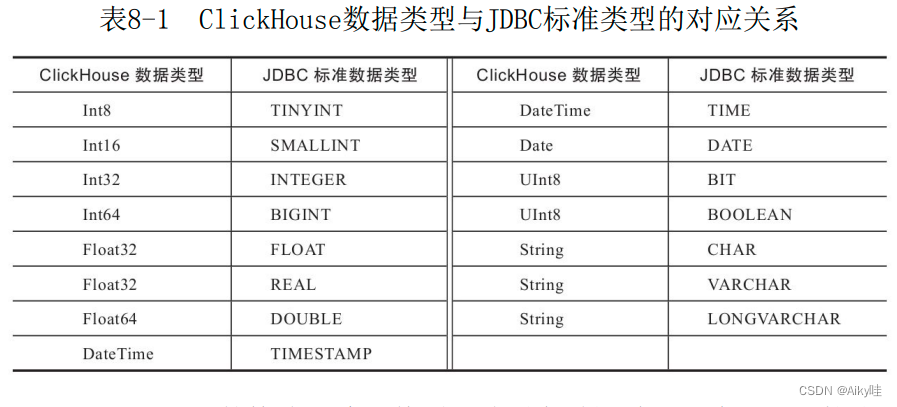
8.1.3 JDBC
JDBC表引擎不仅可以对接MySQL数据库,还能够与PostgreSQL、SQLite和H2数据库对接。
但是,JDBC表引擎无法单独完成所有的工作,它需要依赖名为clickhouse-jdbc-bridge的查询代理服务。
clickhouse-jdbc-bridge可以为 ClickHouse代理访问其他的数据库,并自动转换数据类型。
在使用JDBC表引擎之前,首先需要启动clickhouse-jdbc-bridge代理服务:
java -jar ./clickhouse-jdbc-bridge-1.0.jar --driver-path /chbase/jdbc-bridge --listen-host ch5.nauu.com- --driver-path用于指定放置数据库驱动的目录,例如要代理查询PostgreSQL数据库,则需要将它 的驱动jar放置到这个目录。
- --listen-host用于代理服务的监听端口,通过这个地址访问代理服务,ClickHouse的jdbc_bridge 配置项与此参数对应。
接下来,需要在config.xml全局配置中增加代理服务的访问地址:
……
<jdbc_bridge>
<host>ch5.nauu.com</host>
<port>9019</port>
</jdbc_bridge>
</yandex>
-- JDBC表引擎的声明方式:
ENGINE = JDBC('jdbc:url', 'database', 'table')
CREATE TABLE t_ds_process_definition (
id Int32,
name String
)ENGINE = JDBC('jdbc:postgresql://ip:5432/dolphinscheduler?user=test&password=test, '', 't_ds_process_definition')
-- 查询
SELECT id,name FROM t_ds_process_definition
每一次的SELECT查询,JDBC表引擎首先会向clickhouse-jdbc-bridge发送一次ping 请求,以探测代理是否启动。如果ping服务访问不到,或者返回值不是“Ok.”,就会报错:DB::Exception: jdbc-bridge is not running. Please, start it manually。
在ping探测之后,JDBC表引擎向代理服务发送了查询请求:
<Trace> ReadWriteBufferFromHTTP: Sending request to http://ch5.nauu.com:9019/ ?connection_string=jdbc%3Apo.....
代理查询通过JDBC协议访问数据库,并将数据返回给JDBC表引擎:
┌─id─┬─name───┐
│ 3 │ db2测试 │
│ 4 │ dag2 │
│ 5 │ hive │
│ 6 │ db2 │
│ 7 │ flink-A │
└───┴───────┘
jdbc函数也能够通过clickhouse-jdbc-bridge代理访问其他数据库。
SELECT id,name FROM
jdbc('jdbc:postgresql://ip:5432/dolphinscheduler?user=test&password=test, '', 't_ds_process_definition')查询结果将会与示例中的JDBC表相同。
8.1.4 Kafka
Kafka是大数据领域非常流行的一款分布式消息系统。Kafka表引擎能够直接与Kafka系统对接,进而订阅Kafka中的主题并实时接收消息数据。
ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port,... ',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol']
[kafka_schema = '']
[kafka_num_consumers = N]
[kafka_skip_broken_messages = N]
[kafka_commit_every_batch = N]带有方括号的参数表示选填项。
- kafka_broker_list:表示Broker服务的地址列表,多个地址之间使用逗号分隔,例 如'hdp1.nauu.com:6667,hdp2.nauu.com:6667'。
- kafka_topic_list:表示订阅消息主题的名称列表,多个主题之间使用逗号分隔,例 如'topic1,topic2'。多个主题中的数据均会被消费。
- kafka_group_name:表示消费组的名称,表引擎会依据此名称创建Kafka的消费组。
- kafka_format:表示用于解析消息的数据格式,在消息的发送端,必须按照此格式发送消息。数据格式必须是ClickHouse提供的格式之一,例如TSV、JSONEachRow和CSV等。
【选填参数可自行查看资料】
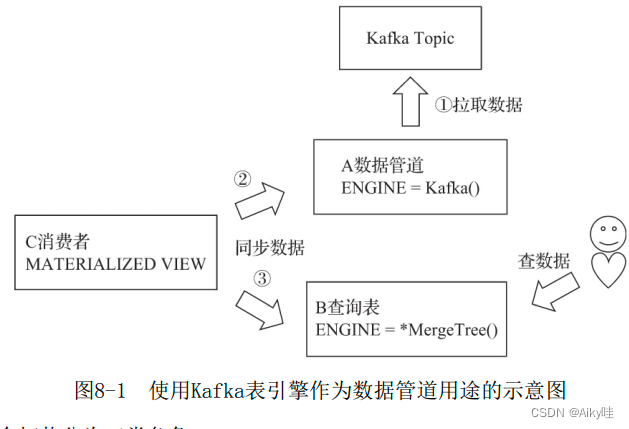
举例:
-- 新建一张Kafka引擎的表,让其充当数据管道
CREATE TABLE kafka_queue(
id UInt32,
code String,
name String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'hdp1.nauu.com:6667',
kafka_topic_list = 'sales-queue',
kafka_group_name = 'chgroup',
kafka_format = 'JSONEachRow',
kafka_skip_broken_messages = 100
-- 新建一张面向终端用户的查询表
CREATE TABLE kafka_table (
id UInt32,
code String,
name String
) ENGINE = MergeTree()
ORDER BY id
-- 新建一张物化视图,用于将数据从kafka_queue同步到kafka_table:
CREATE MATERIALIZED VIEW consumer TO kafka_table
AS SELECT id,code,name FROM kafka_queue
-- 现在可以继续向Kafka主题发送消息,数据查询则只需面向kafka_table:
SELECT * FROM kafka_table
┌─id─┬─code──┬─name──┐
│ 1 │ code1 │ name1 │
│ 1 │ code1 │ name1 │
│ 2 │ code2 │ name2 │
│ 3 │ code3 │ name3 │
└───┴─────┴─────┘8.1.5 File
File表引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用。
可以将ClickHouse数据导出为本地文件;它还可以用于数据格式转换等场景。
File表引擎也被应用于clickhouse-local工具。
ENGINE = File(format)
类型必须是ClickHouse支持 的数据格式,例如TSV、CSV和JSONEachRow等。
在File表引擎的定义参数中,并没有包含文件路径这一项。所以,File表引擎的数据文件只能保存在config.xml配置中由path指定的路径下。
每张File数据表均由目录和文件组成,其中目录以表的名称命名,而数据文件则固定以data.format命名。
创建File表目录和文件的方式有自动和手动两种。
-- 自动创建
CREATE TABLE file_table (
name String,
value UInt32
) ENGINE = File("CSV")
INSERT INTO file_table VALUES ('one', 1), ('two', 2), ('three', 3)在数据写入之后,file_table目录下便会生成一个名为data.CSV的数据文件:
# pwd
/chbase/data/default/file_table
# cat ./data.CSV
"one",1
"two",2
"three",3手动创建的形式,即表目录和数据文件由ClickHouse之外的其他系统创建。比如使用shell创建。
在表目录和数据文件准备妥当之后,挂载这张数据表:
ATTACH TABLE file_table1(
name String,
value UInt32
)ENGINE = File(CSV)查询file_table1内的数据:
SELECT * FROM file_table1
┌─name──┬─value─┐
│ one │ 1 │
│ two │ 2 │
│ three │ 3 │
└─────┴─────┘
即便是手动创建的表目录和数据文件,仍然可以对数据表插入数据。File表引擎会在数据文件中追加数据。
8.2 内存类型
面向内存查询。
除了Memory表引擎之外,其余的几款表引擎都会将数据写入磁盘,这是为了防止数据丢失,是一种故障恢复手段。
数据全量放在内存中,对于表引擎来说是一把双刃剑:
一方面,这意味着拥有较好的查询性能;
而另一方面,如果 表内装载的数据量过大,可能会带来极大的内存消耗和负担。
8.2.1 Memory
直接将数据保存在内存,数据既不会被压缩也不会被格式转换,数据在内存中保存的形态与查询时看到的如出一辙。
ClickHouse服务重启,Memory表内的数据会丢失。
不需要磁盘读取、序列化以及反序列等操作,所以 Memory表引擎支持并行查询,并且在简单的查询场景中能够达到与 MergeTree旗鼓相当的查询性能(一亿行数据量以内)。
CREATE TABLE memory_1 (
id UInt64
)ENGINE = Memory()Memory表更为广泛的应用场景是在ClickHouse的内部,它会作为集群间分发数据的存储载体来使用。例如在分布式IN查询的场合中,会利用Memory临时表保存IN子句的查询结果,并通过网络将它传输到远端节点。
8.2.2 Set
Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中。
服务重启,文件数据会再次被全量加载至内存。
Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略。
它虽然支持正常的INSERT写入,但并不能直接使用 SELECT对其进行查询,Set表引擎只能间接作为IN查询的右侧条件被查询使用。
Set表引擎的存储结构由两部分组成,它们分别是:
- [num].bin数据文件:保存了所有列字段的数据。其中,num是一个自增id,从1开始。伴随着每一批数据的写入(每一次INSERT), 都会生成一个新的.bin文件,num也会随之加1。
- tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕之后,数据文件会被移出此目录。
CREATE TABLE set_1 (
id UInt8
)ENGINE = Set()
INSERT INTO TABLE set_1 SELECT number FROM numbers(10)
-- 直接查询报错
SELECT * FROM set_1
DB::Exception: Method read is not supported by storage Set.
--正确使用方法:将Set表引擎作为IN查询的右侧条件
SELECT arrayJoin([1, 2, 3]) AS a WHERE a IN set_18.2.3 Join
等同于将JOIN查询进行了一层简单封装。与Set表引擎共用了大部分的处理逻辑。所以存储和set一样。
但是相比Set表引擎,Join表引擎有着更加广泛的应用场景,它既能够作为JOIN查询的连接表,也能够被直接查询使用。
声明方式:
ENGINE = Join(join_strictness, join_type, key1[, key2, ...])- join_strictness:连接精度,它决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、ANY 和ASOF三种类型。
- join_type:连接类型,它决定了JOIN查询组合左右两个数据集合的策略,它们所形成的结果是交集、并集、笛卡儿积或其他形式,目前支持INNER、OUTER和CROSS三种类型。当join_type被设置为ANY 时,在数据写入时,join_key重复的数据会被自动忽略。
- join_key:连接键,它决定了使用哪个列字段进行关联。
-- 创建一张主表
CREATE TABLE join_tb1(
id UInt8,
name String,
time Datetime
) ENGINE = Log
INSERT INTO TABLE join_tb1 VALUES (1,'ClickHouse','2019-05-01 12:00:00'),(2,'Spark', '2019-05-01 12:30:00')
-- 接着创建Join表:
CREATE TABLE id_join_tb1(
id UInt8,
price UInt32,
time Datetime
) ENGINE = Join(ANY, LEFT, id)
-- join_strictness为ANY,所以join_key重复的数据会被忽略
INSERT INTO TABLE id_join_tb1 VALUES (1,100,'2019-05-01 11:55:00'),(1,105,'2019-05-01 11:10:00')
-- join 查询
SELECT id,name,price FROM join_tb1 LEFT JOIN id_join_tb1 USING(id)
-- 通过join函数访问
SELECT joinGet('id_join_tb1', 'price', toUInt8(1))8.2.4 Buffer
完全使用内存装载数据,不支持文件的持久化存储。
作用是充当缓冲区的角色,并非查询。
场景:
- 将数据并发写入目标MergeTree表A 。
- MergeTree表A的合并速度慢于写入速度。
此时,可以引入Buffer表来缓解这类问题,将Buffer表作为数据写入的缓冲区。
数据首先被写入Buffer表,当满足预设条件时,Buffer表会自动将数据刷新到目标表。
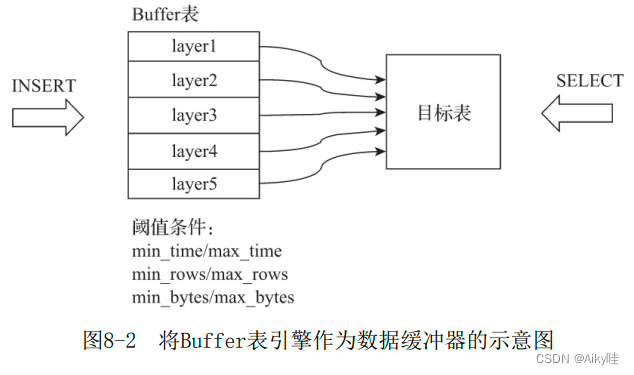
Buffer表引擎的声明方式如下所示:
ENGINE = Buffer(database, table, num_layers, min_time, max_time, min_rows, max_rows, min_bytes, max_bytes)基础参数:
- database:目标表的数据库。
- table:目标表的名称,Buffer表内的数据会自动刷新到目标表
- num_layers:可以理解成线程数,Buffer表会按照num_layers的数量开启线程,以并行的方式 将数据刷新到目标表,官方建议设为16。
在阈值条件满足时它才会刷新。阈值条件由三组最小和最大值组成:
- min_time和max_time:时间条件的最小和最大值,单位为秒,从第一次向表内写入数据的时候开始计算;
- min_rows和max_rows:数据行条件的最小和最大值;
- min_bytes和max_bytes:数据体量条件的最小和最大值,单位为字节。
满足其中任意一个,Buffer表就会刷新数据。
- 如果三组条件中所有的最小阈值都已满足,则触发刷新动作。
- 如果三组条件中至少有一个最大阈值条件满足,则触发刷新动作
- 如果写入的一批数据的数据行大于max_rows,或者数据体量大于max_bytes,则数据直接被写入目标表。
上述三组条件在每一个num_layers中都是单独计算的。
假设num_layers=16, 则Buffer表最多会开启16个线程来响应数据的写入,它们以轮询的方式接收请求,在每个线程内,会独立进行上述条件判断的过程。
假设一张Buffer表的max_bytes=100000000(约100 MB), num_layers=16,那么这张Buffer表能够同时处理的最大数据量约是1.6 GB。
CREATE TABLE buffer_to_memory_1 AS memory_1
ENGINE = Buffer(default, memory_1, 16, 10, 100, 10000, 1000000, 10000000, 100000000)
INSERT INTO TABLE buffer_to_memory_1 SELECT number FROM numbers(1000000)
此时buffer_to_memory_1内有数据,而目标表memory_1是没有的。
等到阈值最大值,100秒之后,数据才会从 buffer_to_memory_1刷新到memory_1。
-- 再次写入数据,这一次写入一百万零一行数据:
INSERT INTO TABLE buffer_to_memory_1 SELECT number FROM numbers(1000001)
-- 查询目标表,可以看到数据不经等待即被直接写入目标表:
SELECT COUNT(*) FROM memory_1
┌─COUNT()─┐
│ 2000001 │
└──────┘8.3 日志类型
适用场景:
- 使用的数据量很小(100万以下)
- 面对的数据查询场景也比较简单
- “一次”写入多次查询的模式
日志家族系列的表引擎也拥有一些共性特征:
- 均不支持索引、 分区等高级特性
- 不支持并发读写。当针对一张日志表写入数据时, 针对这张表的查询会被阻塞,直至写入动作结束
- 同时拥有物理存储,数据会被保存到本地文件中。
8.3.1 TinyLog
TinyLog是日志家族系列中性能最低的表引擎。存储结构由数据文件和元数据两部分组成。
数据文件是按列独立存储的,每一个列字段都拥有一个与之对应的.bin文件。
只适合在非常简单的场景下使用。
CREATE TABLE tinylog_1 (
id UInt64,
code UInt64
)ENGINE = TinyLog()
INSERT INTO TABLE tinylog_1 SELECT number,number+1 FROM numbers(100)
查看文件:
# pwd
/chbase/data/default/tinylog_1
ll
total 12
-rw-r-----. 1 clickhouse clickhouse 432 23:39 code.bin
-rw-r-----. 1 clickhouse clickhouse 430 23:39 id.bin
-rw-r-----. 1 clickhouse clickhouse 66 23:39 sizes.json
# 进一步查看sizes.json文件:
# cat ./sizes.json
{"yandex":{"code%2Ebin":{"size":"432"},"id%2Ebin":{"size":"430"}}}在sizes.json文件内使用JSON格式记录了每个.bin文件内对应的数据大小的信息。
8.3.2 StripeLog
由固定的3个文件组成:
- data.bin:数据文件,所有的列字段使用同一个文件保存,数据都会被写入data.bin。
- index.mrk:数据标记,保存了数据在data.bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
- sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息。
相比TinyLog而言,StripeLog拥有更高的查询性能(拥有.mrk标记文件,支持并行查询),同时其使用了更少的文件描述符(所有数据使用同一个文件保存)。
CREATE TABLE spripelog_1 (
id UInt64,
price Float32
)ENGINE = StripeLog()
INSERT INTO TABLE spripelog_1 SELECT number,number+100 FROM numbers(1000)# pwd
/chbase/data/default/spripelog_1
# ll
total 16
-rw-r-----. 1 clickhouse clickhouse 8121 01:10 data.bin
-rw-r-----. 1 clickhouse clickhouse 70 01:10 index.mrk
-rw-r-----. 1 clickhouse clickhouse 69 01:10 sizes.json
# cd /chbase/data/default/spripelog_1
# cat ./sizes.json
{"yandex":{"data%2Ebin":{"size":"8121"},"index%2Emrk":{"size":"70"}}}在sizes.json文件内,使用JSON格式记录了每个data.bin和 index.mrk文件内对应的数据大小的信息。
8.3.3 Log
日志家族系列中性能最高的表引擎。由3个部分组成:
- [column].bin:数据文件,数据文件按列独立存储,每一个列字段都拥有一个与之 对应的.bin文件。
- __marks.mrk:数据标记,统一保存了数据在各个[column].bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取.bin内的压缩数据块,从而提升数据查询的性能。
- sizes.json:元数据文件,记录了[column].bin和__marks.mrk大小的信息。
CREATE TABLE log_1 (
id UInt64,
code UInt64
)ENGINE = Log()
INSERT INTO TABLE log_1 SELECT number,number+1 FROM numbers(200)# pwd
/chbase/data/default/log_1
# ll
total 16
-rw-r-----. 1 clickhouse clickhouse 432 23:55 code.bin
-rw-r-----. 1 clickhouse clickhouse 430 23:55 id.bin
-rw-r-----. 1 clickhouse clickhouse 32 23:55 __marks.mrk
-rw-r-----. 1 clickhouse clickhouse 96 23:55 sizes.json
# cd /chbase/data/default/log_1
# cat ./sizes.json
{"yandex":{"__marks%2Emrk":{"size":"32"},"code%2Ebin":{"size":"432"},"id%2Ebin":{"size":"430"}}}
8.4 接口类型
自身并不存储任何数据,而是像黏合剂一样可以整合其他的数据表。
8.4.1 Merge
场景:
- 数据按年分表存储,例如test_table_2018、test_table_2019和test_table_2020。
- 现在需要跨年度查询这些数据
Merge表引擎负责合并多个查询的结果集。Merge表引擎可以代理查询任意数量的数据表,这些查询会异步且并行执行,并最终合成一个结果集返回。
被代理查询的数据表被要求处于同一个数据库内,且拥有相同的表结构,但是它们可以使用不同的表引擎以及不同的分区定义(对于 MergeTree而言)。
-- database表示数据库名称
-- table_name表示数据表的名称,它支持使用正则表达式,
-- 例如^test表示合并查询所有以test为前缀的数据表。
ENGINE = Merge(database, table_name)
-- 原数据表
CREATE TABLE test_table_2018(
id String,
create_time DateTime,
code String
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
CREATE TABLE test_table_2019(
id String,
create_time DateTime,
code String
)ENGINE = Log
-- 创建merge 表
CREATE TABLE test_table_all as test_table_2018
ENGINE = Merge(currentDatabase(), '^test_table_')
SELECT _table,* FROM test_table_all
┌─_table────────┬─id──┬───────create_time─┬─code─┐
│ test_table_2018 │ A001 │ 2018-06-01 11:00:00 │ C2 │
└────────────┴────┴──────────────┴────┘
┌─_table────────┬─id──┬───────create_time─┬─code─┐
│ test_table_2018 │ A000 │ 2018-05-01 17:00:00 │ C1 │
│ test_table_2018 │ A002 │ 2018-05-01 12:00:00 │ C3 │
└────────────┴────┴──────────────┴────┘
┌─_table────────┬─id──┬───────create_time─┬─code─┐
│ test_table_2019 │ A020 │ 2019-05-01 17:00:00 │ C1 │
│ test_table_2019 │ A021 │ 2019-06-01 11:00:00 │ C2 │
│ test_table_2019 │ A022 │ 2019-05-01 12:00:00 │ C3 │
└────────────┴────┴──────────────┴────┘
所有以^test_table_为前缀的数据表被分别查询后进行了合并返回。
在上述示例中用到了虚拟字段_table,它表示某行数据的来源表。
如果在查询语句中,将虚拟字段_table作为过滤条件:
SELECT _table,* FROM test_table_all WHERE _table = 'test_table_2018'那么它将等同于索引,Merge表会忽略那些被排除在外的数据表, 不会向它们发起查询请求。
8.4.2 Dictionary
Dictionary表引擎是数据字典的一层代理封装,它可以取代字典函数,让用户通过数据表查询字典。
字典内的数据被加载后,会全部保存到内存中,所以使用 Dictionary表对字典性能不会有任何影响。
ENGINE = Dictionary(dict_name)
CREATE TABLE tb_test_flat_dict (
id UInt64,
code String,
name String
)Engine = Dictionary(test_flat_dict);
SELECT * FROM tb_test_flat_dict
┌─id─┬─code──┬─name─┐
│ 1 │ a0001 │ 研发部 │
│ 2 │ a0002 │ 产品部 │
│ 3 │ a0003 │ 数据部 │
│ 4 │ a0004 │ 测试部 │
└───┴─────┴────┘
如果字典的数量很多,可以使用Dictionary引擎类型的数据库来解决这个问题。
CREATE DATABASE test_dictionaries ENGINE = Dictionary
SELECT database,name,engine_full FROM system.tables WHERE database = 'test_dictionaries'
┌─database──────┬─name─────────────────┬─engine───┐
│ test_dictionaries │ test_cache_dict │ Dictionary │
│ test_dictionaries │ test_ch_dict │ Dictionary │
│ test_dictionaries │ test_flat_dict │ Dictionary │
└────────────┴────────────────────┴────────┘在这个数据库中,ClickHouse会自动为每个字典分别创建它们的 Dictionary表。
8.4.3 Distributed
【这个很重要,业务常用表类型但是是在之后重点介绍的。】
Distributed表引擎等同于是中间件。
自身不存储任何数据,它能够作为分布式表的一层透明代理,在集群内部自动开展数据的写入分发以及查询路由工作。
关于Distributed表引擎的详细介绍,将会在后续章节展开。
8.5 其他类型
8.5.1 Live View
Live View是一种特殊的视图,虽然它并不属于表引擎,但是它与数据表息息相关,所以我还是把Live View归类到了这里。
Live View的作用类似事件监听器,它能够将一条SQL查询结果作为监控目标,当目标数据增加时,Live View可以及时发出响应。
需要将allow_experimental_live_view 参数设置为1才能够使用Live View。
--查看参数
SELECT name, value FROM system.settings WHERE name LIKE '%live_view%'
-- 原表
CREATE TABLE origin_table1(
id UInt64
) ENGINE = Log
-- 创建Live View
CREATE LIVE VIEW lv_origin AS SELECT COUNT(*) FROM origin_table1
-- 执行watch命令以开启监听模式:
WATCH lv_origin
┌─COUNT()─┬─_version─┐
│ │ │
│ 0 │ 1 │
└───────┴───────┘
Progress: 1.00 rows, 16.00 B (0.07 rows/s., 1.07 B/s.)
开启另外一个客户端:
INSERT INTO TABLE origin_table1 SELECT rand() FROM numbers(5)
此时再观察Live View,可以看到它做出了实时响应:
WATCH lv_origin
┌─COUNT()─┬─_version──┐
│ 0 │ 1 │
└──────┴────────┘
┌─COUNT()─┬─_version──┐
│ 5 │ 2 │
└──────┴────────┘
↓ Progress: 2.00 rows, 32.00 B (0.04 rows/s., 0.65 B/s.)虚拟字段_version伴随着每一次数据的同步,它的位数都会加1。
8.5.2 Null
如果用户向Null表写入数据,系统会正确返回,但是Null表会自动忽略数据,不会将它们保存。
如果用户向Null表发起查询,那么它将返回一张空表。
在使用物化视图的时候,如果不希望保留源表的数据,那么将源表设置成Null引擎将会是极好的选择。
-- 创建NULL表
CREATE TABLE null_table1(
id UInt8
) ENGINE = Null
-- 接着以null_table1为源表,建立一张物化视图:
CREATE MATERIALIZED VIEW view_table10
ENGINE = TinyLog
AS SELECT * FROM null_table1现在向null_table1写入数据,会发现数据被顺利同步到了视图 view_table10中,而源表null_table1依然空空如也。
8.5.3 URL
可以通过HTTP/HTTPS协议,直接访问远端的REST服务。
当执行SELECT查询的时候,底层会将其转换为GET请求的远程调用。
而执行INSERT查询的时候,会将其转换为POST请求的远程调用。
ENGINE = URL('url', format)
url表示远端的服务地址,而format则是ClickHouse支持的数据格 式,如TSV、CSV和JSON等。
CREATE TABLE url_table(
name String
)ENGINE = URL('http://client1.nauu.com:3000/users', JSONEachRow)
-- 执行查询
SELECT * FROM url_table
-- 此时SELECT会转换成一次GET请求,访问远端的HTTP服务:
<Debug> executeQuery: (from 10.37.129.2:62740) SELECT * FROM url_table
<Trace> ReadWriteBufferFromHTTP: Sending request to http://client1.nauu.com:3000/users
--数据以表的形式被呈现在用户面前:
┌─name──┐
│ nauu0 │
│ nauu1 │
│ nauu2 │
│ nauu3 │
│ nauu4 │
└─────┘
-- 执行写入
INSERT INTO TABLE url_table VALUES('nauu-insert')
-- INSERT会转换成一次POST请求,访问远端的HTTP服务:
<Debug> executeQuery: (from 10.37.129.2:62743) INSERT INTO TABLE url_table VALUES
<Trace> WriteBufferToHTTP: Sending request to http://client1.nauu.com:3000/users8.6 本章小结
除了MergeTree外的其他一些数据表引擎。
外部存储类型的表引擎、内存类型的表引擎、日志类型表引擎、接口类型的表引擎和其他类型的表引擎。
边栏推荐
- 苹果手机炒股安全吗?打新债是骗局吗?
- English sentence pattern reference
- Failed to virtualize table with JMeter
- Multithreading (I) processes and threads
- Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
- Problems encountered in the project u-parse component rendering problems
- About Estimation with Cross-Validation
- 最大人工岛[如何让一个连通分量的所有节点都记录总节点数?+给连通分量编号]
- Writing writing writing
- 兄弟组件进行传值(显示有先后顺序)
猜你喜欢
Sophon KG升级3.1:打破数据间壁垒,解放企业生产力
node_exporter内存使用率不显示
About Statistical Power(统计功效)
吴恩达团队2022机器学习课程,来啦
Privacy computing helps secure data circulation and sharing
JVM third talk -- JVM performance tuning practice and high-frequency interview question record
使用JMeter录制脚本并调试

Fix vulnerability - mysql, ES
使用Jmeter虚拟化table失败
Record eval() and no in pytoch_ grad()
随机推荐
生词生词生词生词[2]
How to improve the thermal management in PCB design with the effective placement of thermal through holes?
苹果手机炒股安全吗?打新债是骗局吗?
【PaddlePaddle】 PaddleDetection 人脸识别 自定义数据集
JVM third talk -- JVM performance tuning practice and high-frequency interview question record
Nanjing University: Discussion on the training program of digital talents in the new era
Access the database and use redis as the cache of MySQL (a combination of redis and MySQL)
Is it safe to open an account and register stocks for stock speculation? Is there any risk? Is it reliable?
Trust counts the number of occurrences of words in the file
模拟百囚徒问题
通过SOCKS代理渗透整个内网
OpenShift常用管理命令杂记
Sophon kg upgrade 3.1: break down barriers between data and liberate enterprise productivity
华夏基金:基金行业数字化转型实践成果分享
Let more young people from Hong Kong and Macao know about Nansha's characteristic cultural and creative products! "Nansha kylin" officially appeared
Tupu software digital twin | visual management system based on BIM Technology
Sophon AutoCV:助力AI工业化生产,实现视觉智能感知
Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
使用Jmeter虚拟化table失败
[PM2 details]