当前位置:网站首页>Record eval() and no in pytoch_ grad()
Record eval() and no in pytoch_ grad()
2022-07-05 18:09:00 【I am a symmetric matrix】
The origin is that I trained a model , Create a new inference script and load it checkpoint And preprocessing input post reasoning , It is found that no matter what kind of input is, or even random numbers , Its output probability is always the largest of the first kind , And always in 0.5 near , Check for a long time , It is found that model.eval() function .
Because I used model.no_grad(), Subconsciously think that there is no need to add model.eval(), This accident happened 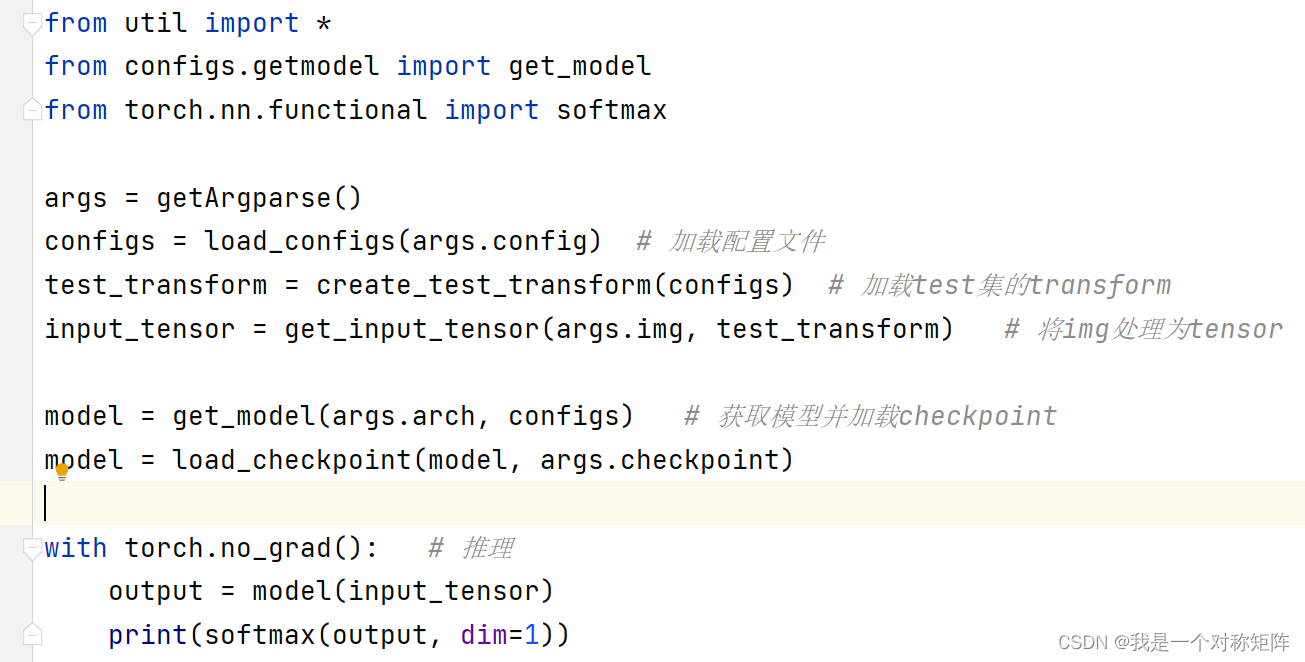
1、 Three swordsmen :train()、eval()、no_grad()
These three functions are actually very common , First, let's take a brief look at the usage
1.1 train()
train() yes nn.Module Methods , That is, you define a network model, that mdoel.train() It means that you should model Set to training mode , Usually at the beginning of a new epoch During training , We will execute the order first :
...
model.train() # Set the model to training mode
for i, data in enumerate(train_loader): # Start new epoch Training for
images, labels = data
images, labels = images.to(device), labels.to(device)
...
1.2 eval()
Same as train() equally , Its usage and meaning are the same ,eval() yes nn.Module Methods , That is, you define a network model, that mdoel.eval() It means that you should model Set to validation mode , Generally, at the beginning of verifying the current model In effect , We will execute the order first :
...
model.eval() # Set the model to validation mode
for i, data in enumerate(eval_loader): # Validate on validation set
images, labels = data
images, labels = images.to(device), labels.to(device)
...
1.3 no_grad()
no_grad() yes torch Method of library , And context manager with To use with .
Its function is to disable gradient calculation , When you're sure you won't call tensor.backward() when . It will reduce the memory consumption of calculation , Otherwise, these calculations will requires_grad=True.
If you set no_grad(), Even input tensor properties requires_grad by True, Nor will the gradient be calculated
Generally, when we carry out model verification or model reasoning , There is no need for gradient and back propagation , So we can torch.no_grad() Perform our verification or reasoning tasks in the context manager , It can significantly reduce the use of video memory .
with torch.no_grad():
output=model(input_tensor) # Model reasoning
print(output) # model Reasoning involves gradients and so on ,print It doesn't involve , So is it in with It doesn't matter anymore
2、 A brief analysis
2.1 Why use train() and eval()
We know nn.Module Medium BN Layers can accelerate convergence , But this layer needs calculation input BatchTensor The mean and variance of , After all, one. BatchSize by 64、128 Even larger , It is also simple to calculate their mean and variance .
But the problem is , When we reason , When reasoning about an image , Calculate to BN Layers also need the mean and variance of the batch . But now there is one tensor, It is meaningless to calculate its mean and variance ( The mean and variance statistics of a sample do not mean much ).
In fact, when reasoning BN The required mean and variance are the values during training ( It can be understood that the mean and variance of the training samples are recorded during training ).
The problem is coming. , How does the model know whether I am in training state or reasoning state ?
When
model.train()when , The model is in training , The model will calculate Batch The mean and variance ofWhen
model.eval()when , The model is in the validation state , The model will use the mean and variance of the training set as the mean and variance of the validation data
And the same thing Dropout layer ,Dropout The layer will inactivate some neurons randomly during training , Improve the model generalization ability , But when validating reasoning ,Dropout The layer no longer needs to be deactivated , That is, all neurons should “ work ” 了 .
All in all train() and eval() The most important thing is to affect BN Layer and the Dropout layer
2.2 Why can the statistics of the training set be used as the test set ?
Why can the statistics of the training set be used as the test set , Because whether it's a training set 、 Verification set or testing machine , Even similar images that have not been collected , They are all independent and identically distributed .
let me put it another way , Pictures of all cats in the world form a collection , Then there is a distribution in this set , This distribution is like Gaussian distribution 、 Poisson distribution, etc , But the collective distribution of this cat may be more complex , Temporarily call it cat distribution .
Every sample in this cat distribution must obey this cat distribution , But at the same time, these samples are not related to each other , We use some of them as training sets , Take another small part as the test set .
We designed a model to train on the training set , Because the training set also obeys the cat distribution , So the model is on the training set “ exercise ” The ability to come out , It is to fit the whole cat distribution from a small training set .
That is, infer all cat graphs from a small number of cat graphs , Thus, it has generalization ability , Reasoning has never seen, but similar images also have very good results . But it's also easy to catch a glimpse , Only see a part of things , See not comprehensive , So the model can't recognize all the cat pictures .
3、 My pit
I subconsciously thought I used no_grad() You don't need to set it anymore eval(), It leads to good training effect , Test yourself , The probability of its output is illogical .
eval() Is affected BN Layer and the Dropout layer
and no_grad() Is not to calculate the gradient
The two are different , Of course, the matching effect is good, and there is still memory !
边栏推荐
- Failed to virtualize table with JMeter
- ITK Example
- 模拟百囚徒问题
- Notes on common management commands of openshift
- Sophon kg upgrade 3.1: break down barriers between data and liberate enterprise productivity
- JDBC reads a large amount of data, resulting in memory overflow
- [TestLink] testlink1.9.18 solutions to common problems
- 星环科技数据安全管理平台 Defensor重磅发布
- Let more young people from Hong Kong and Macao know about Nansha's characteristic cultural and creative products! "Nansha kylin" officially appeared
- FCN: Fully Convolutional Networks for Semantic Segmentation
猜你喜欢
《力扣刷题计划》复制带随机指针的链表
星环科技重磅推出数据要素流通平台Transwarp Navier,助力企业实现隐私保护下的数据安全流通与协作

Nanjing University: Discussion on the training program of digital talents in the new era
RSE2020/云检测:基于弱监督深度学习的高分辨率遥感图像精确云检测
Sophon base 3.1 launched mlops function to provide wings for the operation of enterprise AI capabilities
mybash

寻找第k小元素 前k小元素 select_k
buuctf-pwn write-ups (9)

How awesome is the architecture of "12306"?
Sophon AutoCV:助力AI工业化生产,实现视觉智能感知
随机推荐
爱因斯坦求和einsum
检查命名空间和类
文章中的逻辑词
Introduction to Resampling
ClickHouse(03)ClickHouse怎么安装和部署
吴恩达团队2022机器学习课程,来啦
JVM third talk -- JVM performance tuning practice and high-frequency interview question record
Leetcode daily question: merge two ordered arrays
Sophon Base 3.1 推出MLOps功能,为企业AI能力运营插上翅膀
node_ Exporter memory usage is not displayed
Star ring technology data security management platform defender heavy release
《力扣刷题计划》复制带随机指针的链表
JDBC reads a large amount of data, resulting in memory overflow
JVM第三话 -- JVM性能调优实战和高频面试题记录
nacos -分布式事务-Seata** linux安装jdk ,mysql5.7启动nacos配置ideal 调用接口配合 (保姆级细节教程)
小林coding的内存管理章节
第十一届中国云计算标准和应用大会 | 云计算国家标准及白皮书系列发布 华云数据全面参与编制
Tencent music launched its new product "quyimai", which provides music commercial copyright authorization
EasyCVR平台通过接口编辑通道出现报错“ID不能为空”,是什么原因?
[paddlepaddle] paddedetection face recognition custom data set