当前位置:网站首页>Mask wearing detection based on yolov3
Mask wearing detection based on yolov3
2022-07-05 17:47:00 【Short section senior】
pick want
In order to solve the problem of low recognition accuracy caused by many small-size targets in the detection of objects worn by citizens' masks , This paper proposes a method based on YOLOv3 Improved algorithm M_YOLOv3. Reconstruct the feature pyramid mechanism , The original 3*3 The pyramid like structure of is expanded to 4*4 Size , Change the number of prior frames from 9 Add to 16, adopt The above methods reduce the receptive field of neural network , enhance M_YOLOv3 Sensitivity to small targets . Put the original loss function IoU On behalf of in by DIoU , Solve the problem that it is difficult to confirm the descending direction of the gradient when the border is regressed . Based on network disclosure 4065 The experimental results of a mask dataset show that ,M_YOLOv3 Of mAP( Average precision Degree mean ) by 88.4, a Tiny_YOLOv3 and YOLOv3 Of mAP They have been promoted separately 15.9 and 7.2.
key word object detection ;YOLOv3; Mask wearing test ; Characteristic pyramid ; Convolutional neural networks
introduction
2020 year , Novel coronavirus pneumonia rages the world , Wearing masks correctly is an important measure to prevent the virus from spreading between people . Almost all general algorithms can be applied to mask wearing detection [1], But like People block 、 The target object is small 、 Dense crowds and other issues , The effect detected by the general algorithm is not very ideal . To solve these problems , Researchers have done a lot of research work and made remarkable progress :Pang etc. [2] A spatial attention based on mask is designed Force mechanism module , Let the model pay more attention to the characteristics of the unobstructed part of the pedestrian ; Liu etc. [3] Combine the full convolution network with the idea of variable convolution , In order to increase the flexibility of model feature coding , Position sensitive DCN [4] Pooling , Let the model learn the corresponding features from the parts visible to pedestrians as much as possible , To prevent the interference of other objects . With the continuous development of computer vision technology , Target detection technology is also constantly optimized , It can be roughly divided into two categories : Two steps (Two-Stage) Dharma and single step (One-Stage) Law . Compared with , These two kinds of algorithms are also opposite , The precision of two-step detection is high , The single step method is fast . The most classic one-step method is SSD[5] (singleshot multibox detector)、YOLO[6-9] (youonlylookonce) Series algorithm ; Two step method has R-CNN(region conventionalneuralnetwork) Series algorithm . Considering the need to achieve a real-time detection state in the personnel detection task under actual monitoring , and YOLO Series network can ensure real-time performance in terms of detection speed , Among them the first 3 Substitute version YOLOV3 At the same time, the time and accuracy of detection are taken into account , Compared with its It's a higher version ,YOLOV3 Have more mature 、 More stable technology , So this paper focuses on the general target detection algorithm YOLOV3 On the basis of , Improve the algorithm , Hope to get better detection effect .
1 YOLOV3 Algorithm principle
YOLOV3 yes Redmon And so on , Mainly by backbone network Darknet-53 and YOLO Detection layer composition ,Darknet-53 The structure is mainly It is used to extract the characteristic information of the image ,YOLO Layers are used to predict their categories and Location information . The backbone network structure of the algorithm is shown in Figure 1 Shown .YOLOV3 The algorithm has two obvious advantages : The first advantage is the adoption of Darknet53 [10] Network as the backbone feature extraction network , And combined ResNet residual The idea of network structure [11]. Convolution layer mainly includes two types of filters , Namely 1×1 and 3×3, The former filter is used to compress features , The latter filter The function of the device is mainly through reducing the width and height , To expand the number of channels . One of the biggest features of this structure is that it can be raised by increasing the corresponding depth High accuracy , However, gradient explosion and gradient will also occur in the training model Vanishing question topic ,YOLOV3 The residual block inside the algorithm uses jump connection , It promotes the fusion learning of multiple different features .
chart 1 YOLOV3 Main network structure
For detection images with different sizes ,YOLOV3 The algorithm uses 13×13, 26×26,52×52 The characteristic map of the scale is tested [12], Because each scale Their feelings are different , The size of the detection image is also differentiated , scale The smaller the image, the larger the image will be detected , namely 13×13 Detect large image , and 52×52 Detect small size images ,26×26 Detect medium image . For each For the scale Branch , In each grid, it will detect 3 results , This is because For each ruler degree Next Meeting Yes 3 individual First Examination box (anchorbox), yes root According to the K-Means Generated by clustering . The final will be 3 The results of this test are integrated using non great value Suppression system (non-maximumsuppression,NMS), a have to junction fruit . for instance , Input an image to be detected , Just started to draw it It is divided into S×S The grid of , Need to predict C Categories , In the end 3 The scale was The tensor obtained is S×S× [3× (5+C)], Which contains the target border 4 Offset coordinates and confidence scores , Therefore, it enhances the recognition of small-scale objects Detection capability . This is also YOLOV3 Another big difference between the algorithm and other algorithms advantage . However, the task of wearing masks directly used in natural occasions is still There are some deficiencies . firstly ,YOLOV3 Although the detection accuracy of small targets There is a certain improvement in , But at the same time, there are also problems of insufficient shallow feature extraction problem ; second ,YOLOV3 The accuracy of prediction is to use IoU (intersectionoverunion) Loss function to determine the quality of the prediction box , But when IoU When the value of increases , The accuracy of detection will decrease ; third , For nature The scene is covered 、 Dense crowds and small-scale target detection etc. ask topic , YOLOV3 There are still deficiencies . For the above problems , This article is to improve Accuracy of target detection algorithm for masks in natural environment , With YOLOV3 The algorithm is improved and optimized .
2 The improved YOLOv3 Algorithm
This paper deals with YOLOV3 The improvement of mainly includes 3 In terms of , They are for the main network structure 、 Feature enhanced networks and IoU Improvement of loss function .
2.1 Feature extraction network Darknet_D
Darknet_3 As YOLOv3 Feature extraction network , stay primary count Law After feature extraction, the image information is transferred to the detector for frame regression , And by the original do person RedmonJ real Examination Prove bright ,Darknet53 stay sex can And efficiency Good morning! period Darknet The network of the series has been significantly improved [1]. from On M_YOLOv3 A prediction channel will be added , If you add directly in the shallow network Add this channel to pre measuring , because volume product layer a Less , At this time, the characteristic diagram does not Yes Effective semantic information , There is hardly any reference price for forecasting on this basis value . so M_YOLOv3 carry Out 了 Darknet_D network Collateral , it yes On Dark- net53 On the basis of , A residual structure feature extraction is added at the tail The Internet . The improved class feature pyramid uses residual structure 3、4、5、6 It's about The processed characteristic map is used for multi-scale prediction , Pictured 3 Shown .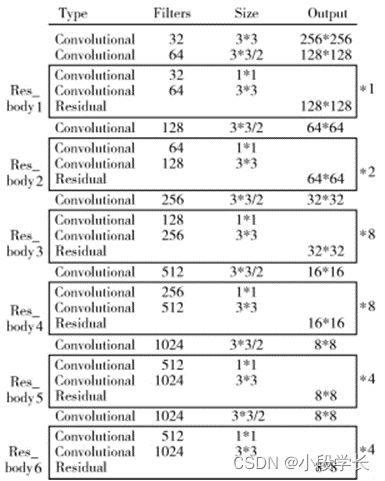
chart 3 M_YOLOv3 Feature extraction network
2.2 Class feature pyramid transformation
YOLOv3 The original algorithm used 3*3 Class characteristic pyramid knot of structure structure , Corresponding 9 individual ruler " Of edge box . primary The reason is yes through too Darknet53 Of 3 layer Res_body junction structure ( Its whole call by Resblock_body) class like remnant Bad network Collateral The addition principle of superimposes each feature map , and And because this have to Out 3 individual ruler Inch prediction loses Out Y. Change Into the count Law M_YOLOv3 The algorithm transforms it into 4*4 Class characteristic pyramid structure , Not only is the hierarchy more clear , More sensitive to different sizes , And in each class feature pyramid output layer, an additional Prediction candidate frames are used , Then the output prediction value Y It will be more accurate . Besides , In the residual knot structure Resblock_body in ,M_YOLOv3 Protect Stay YOLOv3 Of DBL Structure, but modify its parameters , This collection product 、 normalization 、 Activate the network module integrating functions , can enough very good Protect leave Image information and feature extraction . Data processed by feature pyramid , The model packs it into 4 individual Y value , each individual Y value from 4 individual ’anchor junction structure ’ Group become , Every time One individual ’anchor structure ’ And the central coordinate containing this predicted value x、y, Offset value and prediction edge The width and height of the frame w、h, And Its pre measuring class other classes and Set up Letter degree score, Such as chart 4 Shown .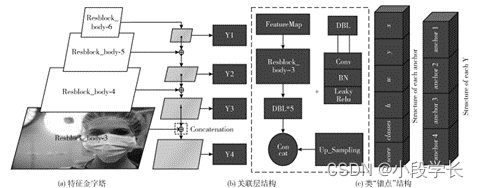
chart 4 Improved pyramid structure with similar characteristics
2.3 The number of prior frames increases
primary YOLOv3 There are algorithms 9 individual First Examination edge box , and And use this 9 individual Different sizes Of edge box branch become 3 Group , Yes No Same as ruler degree Of 3 individual , sign chart Into the Line forecast .
The target object size of the experimental data varies greatly , some some mouth cover Of Pixels less than 64*64px, Some masks have pixels larger than 512*512px. this Some excessive size differences lead to the original YOLOv3 The algorithm is listed on the mask data set Not good now . Improve the algorithm M_YOLOv3 send use 了 16 Forecast frames as Candidate box . Each of them 4 Candidate boxes correspond to a feature map , Every time individual , sign chart Use 4 Candidate edges box Into the That's ok pre measuring . Therefore, increasing the number of prior frames Law , can more good optimum Should be Count According to the , carry high count Law knowledge other fine degree , and increase strong Its extensive Chemical ability .
2.4 Replacement of the loss function of the intersection and union ratio

IoU (intersectionoverunion) Of in writing name call yes “ hand over and Than ”, That is, the intersection of the prediction frame and the real frame , And the union of two boxes Than , Among many target detection algorithms based on deep learning ,IoU all yes One An important regional plan count finger mark , Such as type (1) the in , Its in B and Bgt branch Do not represent the area of the prediction box and the real box .
YOLOv3 Use 1 and IoU Gradient regression is carried out for the difference of , send use The The loss function can simply and effectively converge the loss value of the training network , Such as type (2) Shown . However, this loss function cannot be used normally under certain circumstances , example Such as really There is no intersection between the real frame and the prediction frame , nothing On edge box far near , this when LIoU Are equal to 1, Then there is no distance between the predicted frame and the real frame significance . In this case, the algorithm cannot judge the quality and damage of the two frames The direction of valueless convergence , Pictured 5 Shown 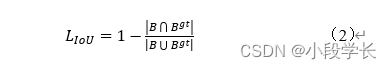
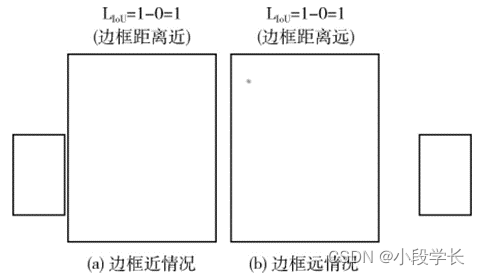
chart 5 The border has no intersection
In response to this question ,Rezatofighi H Put forward 〖G_IoU〗^([10]) idea , The penalty term is added to the original loss function , When there is no intersection of borders , The farther the distance between the two frames is, the greater the loss value , Such as the type (3) Shown .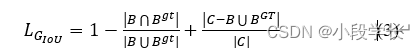
In style :C Is the smallest circumscribed rectangle of two borders , In this case , When there is no intersection between borders , Can also judge the distance , And therefore find the descending gradient .
G_IoU Nor can it be applied to all situations , If there is a containment relationship between two borders , Such as one big one small two borders A and B, Small border A Area and B The union of areas equals A The area of , namely B^A ⋃▒〖BB=BA 〗. Then in any case Loss Values are always equal , This is the sum of On Statement L_IoU The problems are similar , The algorithm cannot find the decreasing direction of the loss value , Pictured 6 Shown .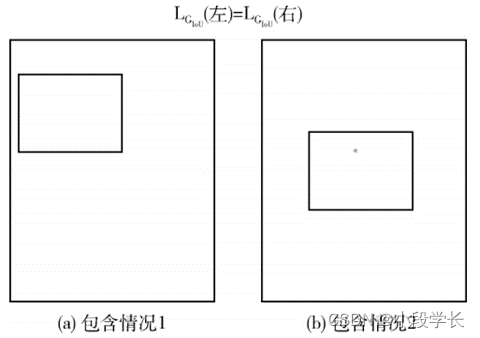
chart 6 The border has a containment relationship
D_IoU yes zhengzhaohui etc. ^([12]) stay G_IoU On the basis of Another loss function of intersection and union ratio deduced from this 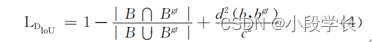
In style :d Represents the Euclidean distance between the center points of two frames .c Is the diagonal distance of the smallest circumscribed rectangle . The way it's calculated and G_IoU class like , Also in the original IoU The penalty term is added to the loss function . The difference is G_IoU The punishment of is more reasonable , It can solve the problem that it is difficult to find the regression gradient when the border contains , Pictured 7 Shown .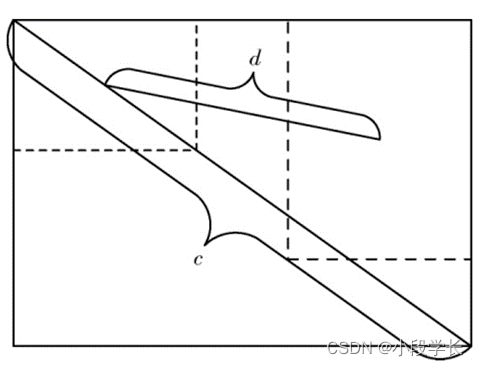
chart 7 DIoU Frame
D_IoU It can also provide the moving direction of the prediction frame . But if two boxes contain ,G_IoU Unable to adapt , and D_IoU Not only can we find the direction of the prediction box , And the loss function converges very quickly .
As mentioned above IoU Loss function , Its role is to assist the final Loss convergence , More reasonable IoU The loss function enables the algorithm to better fit the data .
stay M_YOLOv3 The algorithm uses D_IoU To replace the original L_IoU As a loss function , On this basis, the intersection and union ratio of the prediction frame and the real frame is calculated , The experiment proves that it has better detection effect .
2.5 The increase of the proportionality coefficient
stay YOLOv3 In the algorithm, , The loss function of the training network is actually the loss of the central point 、 Loss of width and height 、 Classification loss and confidence loss , This loss value is summed up to , Such as the type (5) Shown
Loss=L_xy+L_wh+L_c+L_s (5)
2.4 As mentioned in section D_IoU The loss function will improve L_xy and L_wh Of meter count , Make the calculation of these two loss values more reasonable . because YOLOv3 It's multiscale check measuring , When the loss value converges, each frame will be calculated once . So wide and high Big Of Frame Lxy and Lwh The value of will be higher , On the whole Loss Value has the wrong effect .
To solve this problem , The original author proposed the proportional coefficient box_loss_ scale This indicator , It is made up of numbers 2 And the offset value w and h The product of It is calculated that , among w and h yes 0 To 1 Between ground_truth wide High offset value , Such as the type (6) Shown . stay Lxy and Lwh The last step of the calculation will be the proportional system Count discharge shrink , Increase the influence weight of the small size frame , And then reduce the meaningless influence caused by different prior frame sizes
2.6 Weighted correction of loss function
Such as the type (5) Shown , total Loss Values are determined by 4 Independent Of Loss Add up and get . because M_YOLOv3 Used DIoU And the scale coefficient is increased , In the type (5) Medium right 4 Add items and divide Lc The weight calculation has been carried out outside . For balance 4 Influence weight of loss value ,M_YOLOv3 stay most end Loss When calculating , hold branch class damage loss value Lc Weighted calculation , Such as the type (8) Shown 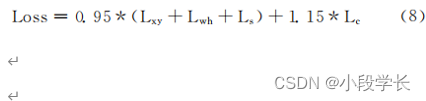
3 Experimental results and Analysis
3.1 Experimental data preparation
3.1.1 Data set introduction
In this experiment, the public mask data set is selected 1, This data set comes from the network , from labelimg Software annotation . according to 300px Divide the input image into , Small size 、 Medium ruler " 、 Big ruler " 、 super Big ruler " ( Any attribute of length and width is greater than 900px), , respectively, Yes 658 Zhang 、1557 Zhang 、566 Zhang 、134 Zhang , not notes Ming Xiaoyou 1150 Zhang , total 4065 A picture . This data set is related to VOC2007 The data set format is consistent , Each piece of data uses a picture corresponding to it xml phase junction close . Each picture corresponds to a xml file , Record various attributes of the target object on the picture , For example, the target object is at the center of the picture 、 The width and height of the marking box 、 Information such as the category of the target object . There are only two classes in this dataset ,”face_mask” and ”face”. In the above properties of the target object , The length and width of the target object marking box appear especially by heavy want , They can represent the size of the target object . because YOLOv3 Original algorithm Of real Examination yes stay VOC2007 On the dataset , The data of this experiment is to detect faces and masks , And VOC2007 Compared with the data set, the target size is generally smaller . Therefore, this data set and VOC2007 Compare the target size of the data set , According to unilateral 64、128、256、512 Size the boundaries , See table 1.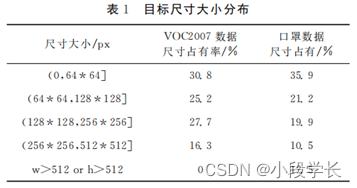
thus it can be seen , The distribution of this data set is more extensive and detailed , And the size of small targets is too large . Improved algorithm proposed 4 Three layer pyramid structure , And will anchors The number is from 9 increase Add To 16 How to do it , Theoretically support M_YOLOv3 Can get better recognition effect .
3.1.2 Data to enhance
In deep learning theory , The more training data you have , The better the effect of the training model . Because this experimental data only 4000 The remaining pictures are not enough , It is necessary to use data enhancement methods to simulate more data samples . It can not only make the algorithm model have more learning samples , At the same time, the noise is increased due to data enhancement , Reduce the phenomenon of model over fitting .
In this experiment , Zoom image used 、 Translation transformation 、 Flip 、 Color jitter (RGB->HSV->RGB) as well as boxes Relocation and other data enhancement means , Ensure that the experimental data is sufficient , Enhance the generalization ability of the model , Improve the robustness of the algorithm .
3.2 The process of training the model
To get the appropriate a priori box size , The most common method is to cluster the labeled data . Among many clustering methods , Under the condition that the number of clusters is set in advance ,K-Means Undoubtedly, it has become the preferred solution .
K-Means The algorithm is very intuitive , The initial artificial constant K,K Represents the number of categories finally divided by the algorithm . The algorithm will randomly select the initial point as the centroid , And by calculating the similarity between each sample and the centroid ( Euclidean distance is generally used ), Classify the sample points into the most similar cluster , next , Recalculate the centroid of each cluster ( Cluster heart ), Repeat the process , Until the cluster heart no longer changes , Finally, the cluster and cluster center of each sample are determined . M_YOLOv3 Used The number of clusters is 16 Of K-Means The algorithm clustering . Got 16 Group anchors After that, a similar normalization process was carried out , Final have to Out anchors ruler " Such as Next :(23,23),(35,34),(44,44), (53,54),(65,63),(76,75),(89,91),(108,105),(121,123),(142,142),(164,175),(167,158),(190,190),(215,212), (253,254),(372,362). Two values in brackets (width,hight) branch Don't mean anchor Width and height .
Considering the hardware conditions of this experiment , Input the picture size uniformly resize by 352*352, The initial learning rate is set to 0.001, Use monitoring during callback val_loss Change the way to reduce the learning rate , Its in The parameter of is set to patience=6,factor=0.4. total training Practice batch Time epoch= 800,batch_size=10, training Practice network Collateral Loss The convergence of values is shown in Figure 8 Shown .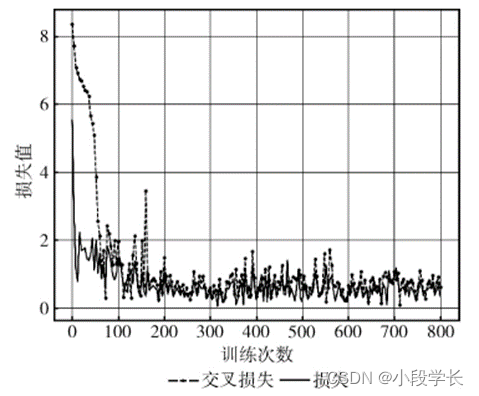
chart 8 Loss convergence
3.3 Evaluation index and experimental results
3.3.1 The recognition effect of small targets
When detecting the input picture , A picture often includes many goals , It is easy to miss inspection , In particular, the missing detection of small-size objects is more common , Pictured 9 Shown ( A rectangular box with a long text box representative “ masks ”, The shorter rectangle of the text box represents “ Face ”). chart 9 in YOLOv3 Algorithm and Tiny_YOLOv3 The algorithm has missed detection , and M_YOLOv3 With a variety of improvement measures , It is more important for small targets sensitive , It is not easy to miss inspection . Experimental results show that , The improved algorithm , To some extent, it improves the problem of difficult recognition of small target objects , Pictured 9 Shown .
chart 9 3 Comparison of detection effects of two algorithms
3.3.2 Recognition effect under difficult conditions
In the experiment ,3 This detection algorithm has a good detection effect for most pictures , Errors mainly occur On confused and occluded data . Such as chart 10 in , The mask in the first row of pictures is very similar to the face color , Only M_ YOLOv3 Algorithm sentence set just indeed ( The longer rectangle of the text box represents “ masks ”, The shorter rectangle of the text box represents “ Face ”); The second row of pictures are paper folding fans covering the face , Its shape, color and size are very similar to masks , The recognition results of all algorithms are wrong .
3.3.3 mAP The evaluation index
The goal is The evaluation indicators used in the detection field are mainly mAP(mean averageprecision), Average accuracy mean , That is to say AP Average value . and AP Is through (9) obtain , In essence, it is to choose 0.1 As γ The interval of , Put each γ Yes Should be Of Pinterp Value addition , Finally, take the mean . among Pinterp yes PR In the curve , With a recall rate (recall) As the abscissa point , The ordinate value corresponding to the curve , Such as the type (10) Shown ( In the calculation process in , If abscissa x1 There is no corresponding ordinate value , Then use the closest two points x2、x3 Points on the corresponding curve , Make extension cord and x=x1 Straight lines intersect , The intersection point is x1 Corresponding ordinate value )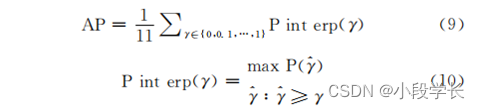
chart 11 It's a category ”face” Corresponding P-R curve , In the figure, we can see M_YOLOv3 Of PR The curve is slightly better than the unchanged calculation Law . There are two in this experiment individual class ,”face_mask” class and ”face” class .mAP Value is for two classes AP Sum the values and average .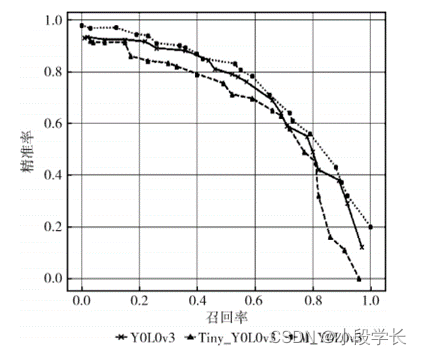
chart 11 “face” Category P-R curve
3.3.4 experimental result
The experiment shows that ,M _YOLOv3 Algorithm comparison with the original Tiny_ YOLOv3 and YOLOv3 Algorithm in mAP The value has increased 15.9 and 7.2, The detection ability is better than the original algorithm .M_YOLOv3 Of fps The value is 24, To a certain extent, it can detect the wearing of masks in real time. See the table 2.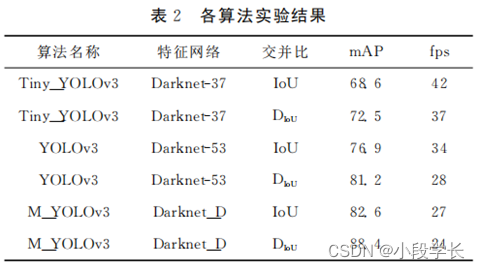
4 Conclusion
Improve the algorithm M_YOLOv3 Algorithm in YOLOv3 Deepen the feature extraction network and add prediction channels , And a more reasonable loss function is used , To improve the YOLOv3 The algorithm is difficult to recognize small-scale targets , It is applicable to the detection of small target objects . The conclusion is drawn in the experiment of mask data set based on more small-size targets ,mAP Index compared with the original YOLOv3 Promoted 7.2. In the experiment , Some data are extremely confusing , For example, figure 10 Chinese women use paper folding fans to cover their mouths , Several algorithms in this paper all incorrectly determine that it is a mask . In response to this question , temporary Unable to resolve , It's worth thinking about and finding the answer in the next step , Maybe use something similar DOTA The data format of the four point coordinates of the dataset will Improve this problem . except YOLOv3 Outside the algorithm , Other target detection algorithms are also contending . As a scholar, we should follow the times Step , Continue to learn and understand other target detection algorithms and their network structures , Such as single-stage RetinaNet[13]、
YOLOv4, Two stage DCR、SNIP[14]、SNIPER etc. .
reference :
[1]NIUZuodong,QINTao,LIHandong,etal.Improvedalgo-
rithmofretinafacefornaturalscenemaskweardetection [J].
ComputerEngineeringandApplications,2020,56 (12):1-7
(inChinese). [ Niu Zuodong , Qin Tao , Li Handong , etc. . improvement RetinaFace
Natural field view mouth cover palin wear check measuring count Law [J]. meter count machine work cheng And Should be use ,
2020,56 (12):1-7.]
[2]PangY,XieJ,HarisKhan M,etal.Mask-guidedattention
networkforoccludedpedestriandetection [C]//IEEE/CVF
InternationalConferenceon Computer Vision.arXiv,2019:
4967-4975.
[3]Liu T,Luo W, Ma L,etal.Couplednetworkforrobust
pedestriandetection with gated multi-layerfeatureextraction
anddeformableocclusionhandling [J].IEEE Transactionson
ImageProcessing,2020,30:1.
[4]ZhuX,HuH,LinS,etal.DeformableConvNetsV2:More
deformable,betterresults [C]//IEEE/CVF Conferenceon
ComputerVisionandPatternRecognition.IEEE,2019:9308-
9316.
[5]LiuW,AnguelovD,ErhanD,etal.SSD:Singleshotmulti-
boxdetector [C]//EuropeanConferenceonComputerVision.
SpringerInternationalPublishing,2016:21-37.
[6]RedmonJ,DivvalaS,GirshickR,etal.Youonlylookonce:
Unified,real-timeobjectdetection [C]//ComputerVision &
PatternRecognition.IEEE,2016:779-788.
[7]RedmonJ,FarhadiA.YOLO9000:Better,faster,stronger
[C]//IEEEConferenceonComputerVision& PatternRecog-
nition.IEEE,2017:6517-6525.
[8]REDMON J, FARHADI A. YOLOV3: An incremental
improvement [C]//ProceedingsofIEEEConferenceonCom-
puter Vision and Pattern Recognition.Washington:IEEE
Press,2018:1-6.
[9]BochkovskiyA, Wang CY,Liao HYM.YOLOv4:Optimal
speedandaccuracyofobjectdetection [J].arXiv:2004.10934,
2020.
[10]WangY,ZhengJC.Real-timefacedetectionbasedonYOLO
[C]//IEEEInternationalConferenceon KnowledgeInnova-
tionandInvention,2018:221-224.
Welcome to join me for wechat exchange and discussion ( Please note csdn Add )
边栏推荐
- Humi analysis: the integrated application of industrial Internet identity analysis and enterprise information system
- Design of electronic clock based on 51 single chip microcomputer
- Thesis reading_ Chinese NLP_ LTP
- Independent development is a way out for programmers
- [binary tree] insufficient nodes on the root to leaf path
- PMP认证需具备哪些条件啊?费用多少啊?
- mybash
- Disabling and enabling inspections pycharm
- 哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
- Short the command line via jar manifest or via a classpath file and rerun
猜你喜欢
mongodb(快速上手)(一)
統計php程序運行時間及設置PHP最長運行時間
VBA驱动SAP GUI实现办公自动化(二):判断元素是否存在

十个顶级自动化和编排工具

Beijing internal promotion | the machine learning group of Microsoft Research Asia recruits full-time researchers in nlp/ speech synthesis and other directions
漏洞复现----48、Airflow dag中的命令注入(CVE-2020-11978)
ELK日志分析系统

2022新版PMP考试有哪些变化?

Six bad safety habits in the development of enterprise digitalization, each of which is very dangerous!

EPM相关
随机推荐
Matlab reference
漫画:如何实现大整数相乘?(上) 修订版
How to modify MySQL fields as self growing fields
QT控制台打印输出
ClickHouse(03)ClickHouse怎么安装和部署
Oracle Recovery Tools ----oracle数据库恢复利器
北京内推 | 微软亚洲研究院机器学习组招聘NLP/语音合成等方向全职研究员
Cmake tutorial Step3 (requirements for adding libraries)
2022新版PMP考试有哪些变化?
PMP认证需具备哪些条件啊?费用多少啊?
Disabling and enabling inspections pycharm
一口气读懂 IT发展史
ICML 2022 | Meta propose une méthode robuste d'optimisation bayésienne Multi - objectifs pour faire face efficacement au bruit d'entrée
为什么阳历中平年二月是28天
基于YOLOv3的口罩佩戴检测
flask接口响应中的中文乱码(unicode)处理
较文心损失一点点性能提升很多
To solve the problem of "double click PDF file, pop up", please install Evernote program
The comprehensive competitiveness of Huawei cloud native containers ranks first in China!
这个17岁的黑客天才,破解了第一代iPhone!