当前位置:网站首页>Kafaka technology lesson 1
Kafaka technology lesson 1
2022-07-05 17:26:00 【teayear】
1, Course review
zk Distributed coordination framework
2, Key points of this chapter
The concept of message queuing
Characteristics and functions of message queue
common MQ What are the frameworks
kafka An introduction to the
Basic terminology
Cluster building , Startup and shutdown
Common commands
3, The specific content
3.1 Message queue (message queue) The concept of
A message is a unit of data passed between two computers , It can be a simple string , It can also be complex embedded objects . A message queue is a container that holds messages during message delivery , Act as a middleman when relaying messages from the source to the target .
3.2 What message queuing does 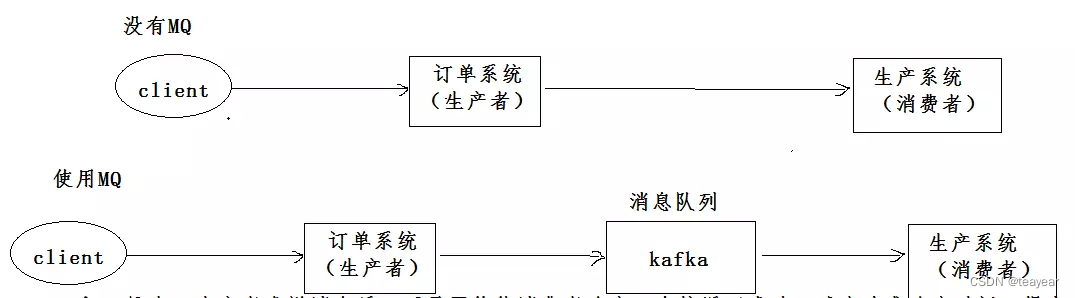
decoupling :
A The system sends data to BCD Three systems , Sent via interface call . If E The system also needs this data ? Then if
C The system is not needed now ?A The head of the system almost collapsed …A The system is heavily coupled to all sorts of other messy systems ,A System Generate a key piece of data , Many systems need A The system sends this data . If you use MQ,A The system generates a Data , Send to MQ Go inside , Which system needs the data to go by itself MQ In consumption . If the new system requires data , Directly from MQ It's OK to spend in ; If a system doesn't need this data , Just cancel it. Yes MQ The consumption of news can be . So down ,A System There's no need to think about who to send data to , There is no need to maintain this code , There is no need to consider whether the call was successful 、 Failure super Wait a minute . It's a system or a module , Multiple systems or modules called , Calls to each other are complex , It's hard to maintain . but In fact, this call does not need to directly synchronize the calling interface , If you use MQ Decouple it asynchronously .
asynchronous :
A The system receives a request , You need to write your own library , Still need to be in BCD Three system write Libraries , Write your own local library
want 3ms,BCD Three systems respectively write library requirements 300ms、450ms、200ms. The total delay of the final request is 3 + 300 + 450 + 200 = 953ms, near 1s, What's the user feeling , Slow to death... Slow to death . The user initiates the request through the browser . If you use MQ, that A The system sends 3 Message to the MQ In line , If it takes time 5ms,A The system goes from accepting a request to returning a response To the user , The total time is 3 + 5 = 8ms.
Peak shaving :
Reduce peak pressure on servers . The upstream system has good performance , The pressure suddenly increases , The performance of downstream system is slightly poor , Can't stand the sudden increase of pressure , At this time, message oriented middleware plays the role of peak shaving .
Use scenarios :
When the speed and stability of production and consumption are inconsistent in the system , Using message queuing , As the middle layer , To bridge the differences between the two sides .
Example : There is short message sending business in the business system , Dealing with timing tasks and so on
3.3 Two modes of message queuing
3.3.1 Point to point mode ( one-on-one , Consumers take the initiative to pull data , Message is cleared when received )
Message producers produce messages sent to Queue in , Then the message consumer from Queue To retrieve and consume messages .
After the news was consumed ,queue No more storage in , So it's impossible for news consumers to consume the information that has been consumed .Queue Support for multiple consumers , But for a message , Only one consumer can consume .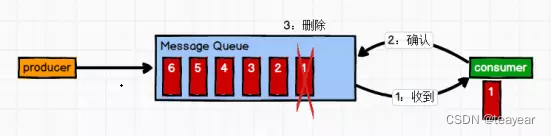
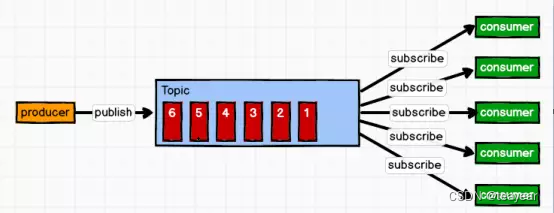
3.3.2 Release / A subscription model ( One to many , Consumer consumption data will not clear messages after )
Message producer ( Release ) Publish a message to topic in , There are multiple message consumers at the same time ( subscribe ) Consume the news . It's different from point-to-point , Publish to topic Will be consumed by all subscribers .
3.4 common MQ What are the frameworks
kafka activeMQ rabbitMQ zeroMQ metaMQ rocketMQ wait ...
3.5 kafka brief introduction
https://kafka.apachecn.org/
http://kafka.apache.org/
kafka By apache An open source stream processing framework developed by the software foundation , from JAVA and scala Language writing . It is a high-throughput distributed system for publishing and subscribing messages .Kafka It is used to build real-time data pipeline and streaming app. It can expand horizontally , High availability , Fast , And it has been running in the production environment of thousands of companies .
3.6 Basic terminology
topic( topic of conversation ):kafka Categorize messages , Each type of news is called topic , It's a logical concept , If it's really on disk , The mapping is a partition A directory of .
producer (producer): The object that publishes the message is called the producer , Only responsible for data generation , The source of production , May not be in kafka On the cluster , But from other business systems .
consumer (consumer): Subscribe to the message and handle the object that publishes the message , Called consumer .
Consumer group (consumerGroup): Multiple consumers can form a consumer group , Consumers in the same consumer group , Only one... Can be consumed topic data , Can't repeat consumption .
broker : kafka It can be a cluster itself , Each server in the cluster is a proxy , This agent is called broker. Only responsible for the storage of messages , Both producers and consumers , It has nothing to do with them . In the cluster, each broker There's only one ID, Can't repeat .
3.7 kafka Cluster building , Startup and shutdown
3.7.1 Build a stand-alone zookeeper( Cluster is the best )
Use the existing zookeeper colony
3.7.2 build kafka colony
In existing cluster1,2,3 To build
Upload kafka Compressed package , To linux On the system
decompression :
tar -xzvf /root/software/kafka_2.12-2.7.0.tgz -C /usr/
Modify name :
mv /usr/kafka_2.12-2.7.0/ /usr/kafka
Configure environment variables :
vim /etc/profile
Copy the following :
export KAFKA_HOME=/usr/kafka
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: Z K H O M E / b i n : / u s r / a p a c h e − t o m c a t − 9.0.52 / b i n : ZK_HOME/bin:/usr/apache-tomcat-9.0.52/bin: ZKHOME/bin:/usr/apache−tomcat−9.0.52/bin:KAFKA_HOME/bin
Let the configuration file take effect :
source /etc/profile
test :
echo $KAFKA_HOME
Get into kafka Catalog :
cd /usr/kafka
Create directory ( Store messages ), Prepare for later configuration
mkdir logs
Modify the configuration server.properties file :
vim /usr/kafka/config/server.properties
Modify the following :
#broker The global unique number of , Can't repeat 21 That's ok
broker.id=0
# Is deletion allowed topic 22 That's ok
delete.topic.enable=true
# Number of threads processing network requests and responses 42 That's ok
num.network.threads=3
# For processing disks IO Number of threads 45
num.io.threads=8
# The buffer size of the sent socket 48
socket.send.buffer.bytes=102400
# The buffer size of the receiving socket 51
socket.receive.buffer.bytes=102400
# The maximum buffer size of the request socket 54
socket.request.max.bytes=104857600
#kafka Run the path where the log is stored 60
log.dirs=/usr/kafka/logs
#topic At present broker The number of partitions on 65
num.partitions=1
# For recovery and cleanup data Number of threads under the data 69
num.recovery.threads.per.data.dir=1
# The following configuration controls the processing of log segments . You can set the policy to delete segments after a period of time or after a given size accumulates . As long as one of these conditions is met any term , The segment will be deleted . Deletion always starts at the end of the log .
#segment The maximum length of time a document can be retained , The timeout will be deleted , Unit hour , The default is 168 Hours , That is to say 7 God 103
log.retention.hours=168
# Size based log retention policy . Unless the remaining segments are lower than log.retention.bytes, Otherwise, the segment will be deleted from the log . Independent of log.retention.hours The function of
#log.retention.bytes=1073741824
# Maximum size of log segment file . When this size is reached , A new log segment will be created .
log.segment.bytes=1073741824
# Check the log segment to see if the interval of the log segment can be deleted according to the retention policy
log.retention.check.interval.ms=300000
# configure connections Zookeeper The cluster address 123
zookeeper.connect=hdcluster1:2181,hdcluster2:2181,hdcluster3:2181
Because... Is used in the configuration file zk Host name link , So configure the local domain name :
vim /etc/hosts
complete hosts:
192.168.170.41 cluster1
192.168.170.42 cluster2
192.168.170.43 cluster3
modify producer.properties:
vim /usr/kafka/config/producer.properties
modify 21 Behavior :
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
modify consumer.properties:
vim /usr/kafka/config/consumer.properties
modify 19 Behavior :
bootstrap.servers=cluster1:9092,cluster2:9092,cluster3:9092
Send configured kafka To the other two machines ( First, log in without secret ):
ssh-keygen -t rsa
ssh-copy-id cluster2
ssh-copy-id cluster3
scp -r /usr/kafka/ cluster2:/usr/
scp -r /usr/kafka/ cluster3:/usr/
Check whether the sending is successful , stay all session perform :
ls /usr
modify broker.id( Bear in mind )
stay cluster2 and cluster3 Modify the broker.id
vim /usr/kafka/config/server.properties
modify 21 Behavior
broker.id=1
broker.id=2
Send environment variable configuration file :
scp -r /etc/profile cluster2:/etc/
scp -r /etc/profile cluster3:/etc/
stay all session perform :
source /etc/profile
echo $KAFKA_HOME
send out hosts The configuration file :
scp -r /etc/hosts cluster2:/etc/
scp -r /etc/hosts cluster3:/etc/
Test success :
stay all session perform :
cat /etc/hosts
3.7.3 Startup and shutdown of cluster
start-up kafka Make sure before you do zk Start up , And available :
start-up zk:
/root/shelldir/zk-start-stop.sh
Test if it starts :
jps // stay all session perform :
start-up kafka:
// stay all session perform
kafka-server-start.sh -daemon /usr/kafka/config/server.properties
jps
stop it kafka:
kafka-server-stop.sh
jps
3.8 Common commands
View all in the current server topic The theme :
kafka-topics.sh --zookeeper cluster1:2181 --list
If it is zk Clusters can use such commands :
kafka-topics.sh --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --list
establish topic: list
kafka-topics.sh --zookeeper cluster2:2181 --create --replication-factor 3 --partitions 5 --topic ordertopic
kafka-topics.sh --zookeeper cluster2:2181 --create --replication-factor 2 --partitions 2 --topic goodstopic
Parameter description :
–zookeeper link zk
–replication-factor Specify the number of copies ( The number of copies cannot be greater than the total brokers number )
–partitions Specify the number of partitions
–topic Appoint topic name
Delete topic:
kafka-topics.sh --zookeeper cluster1:2181 --delete --topic tp3
This will have no impact if delete.topic.enable is not set to true
Production news :
kafka-console-producer.sh --broker-list cluster2:9092 --topic goodstopic
News consumption :
kafka-console-consumer.sh --bootstrap-server cluster2:9092 --from-beginning --topic goodstopic
Consumption news of the same group of consumers ( Multiple windows ):
kafka-console-consumer.sh --bootstrap-server kafka1:9092 --consumer-property group.id=gtest --from-beginning --topic tp1
View one topic details :
kafka-topics.sh --zookeeper cluster2:2181,cluster1:2181 --describe --topic tp1
picture : https://uploader.shimo.im/f/qxOF7yGzME5lSY0F.png
partitioncount Total number of partitions
replicationfactor Copy number
partition Partition
leader Each partition has 3 Copies , Every copy has leader
replicas All replica nodes , No matter leader follower
isr: Node in service
4, Summary of knowledge points
5, Interview questions in this chapter
https://www.cnblogs.com/kx33389/p/11182082.html
https://blog.csdn.net/qq_28900249/article/details/90346599
kafka Zoning , Yes leader and follower How to synchronize data ,ISR(In Sync Replica) What does that mean? ?
5 individual broker For example
leader follower
2 3 4 0 1
kafka Not fully synchronized , It's not completely asynchronous , It's a special kind ISR(In Sync Replica)
1.leader Will maintain a synchronized replica aggregate , The set is ISR, every last partition There is one. ISR, It is from leader Dynamic maintenance .
2. We need to make sure kafka No loss message, Just make sure that ISR The group survived ( At least one survived ), And the news commit success .
So what is our concept of survival ? The distributed message system has two conditions to judge whether a node survives :
first , Nodes must be maintained and maintained zookeeper The connection of ,zookeeper Check the connection of each node through the heartbeat mechanism ;
the second , If the node follower, It must be able to synchronize with leader Write operations for , Not too long .
If you meet the above 2 Conditions , It can be said that when nodes “in-sync“( In sync ).leader I'll track it ” In sync “ node , If a node hangs , Stuck. , Or delay too long , that leader It will be removed , The delay time is determined by the parameter replica.log.max.messages decision , Determine if it's stuck , By the parameter replica.log.time.max.ms decision .
边栏推荐
- BigDecimal除法的精度问题
- Design of electronic clock based on 51 single chip microcomputer
- 关于mysql中的json解析函数JSON_EXTRACT
- Rider 设置选中单词侧边高亮,去除警告建议高亮
- 基于Redis实现延时队列的优化方案小结
- Using C language to realize palindrome number
- 【beanshell】数据写入本地多种方法
- 网上办理期货开户安全吗?网上会不会骗子比较多?感觉不太靠谱?
- Function sub file writing
- winedt常用快捷键 修改快捷键latex编译按钮
猜你喜欢
thinkphp3.2.3
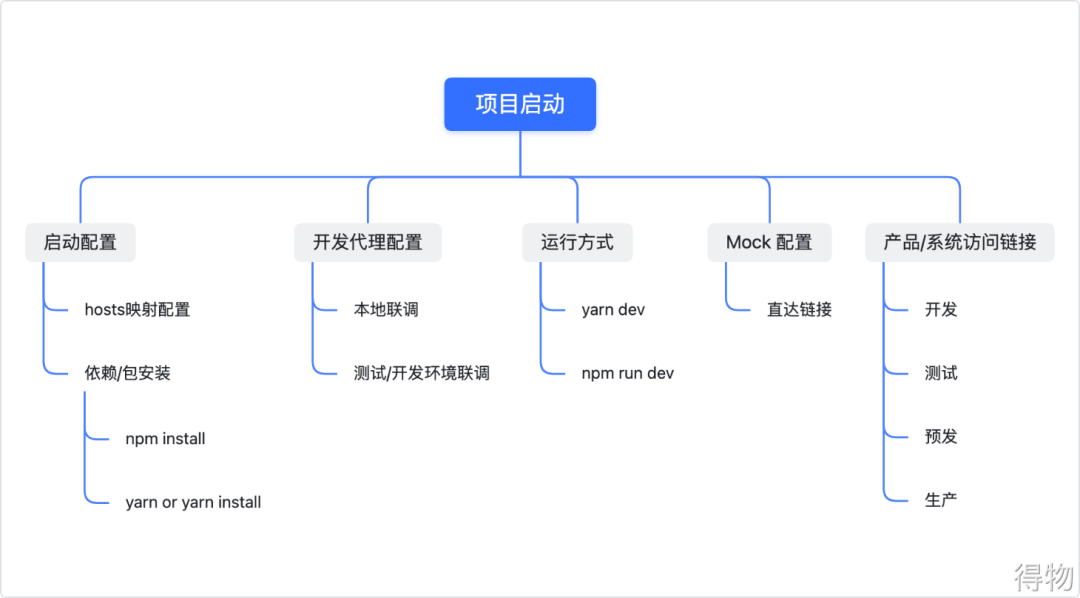
How to write a full score project document | acquisition technology

Etcd build a highly available etcd cluster
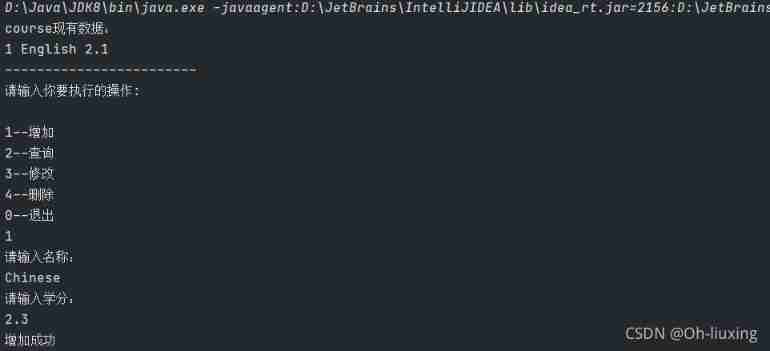
Use JDBC technology and MySQL database management system to realize the function of course management, including adding, modifying, querying and deleting course information.
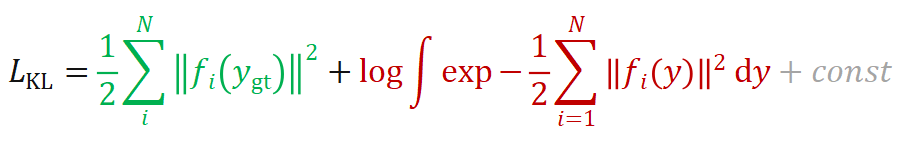
CVPR 2022最佳学生论文:单张图像估计物体在3D空间中的位姿估计
腾讯音乐上线新产品“曲易买”,提供音乐商用版权授权

Embedded-c Language-1
Judge whether a string is a full letter sentence
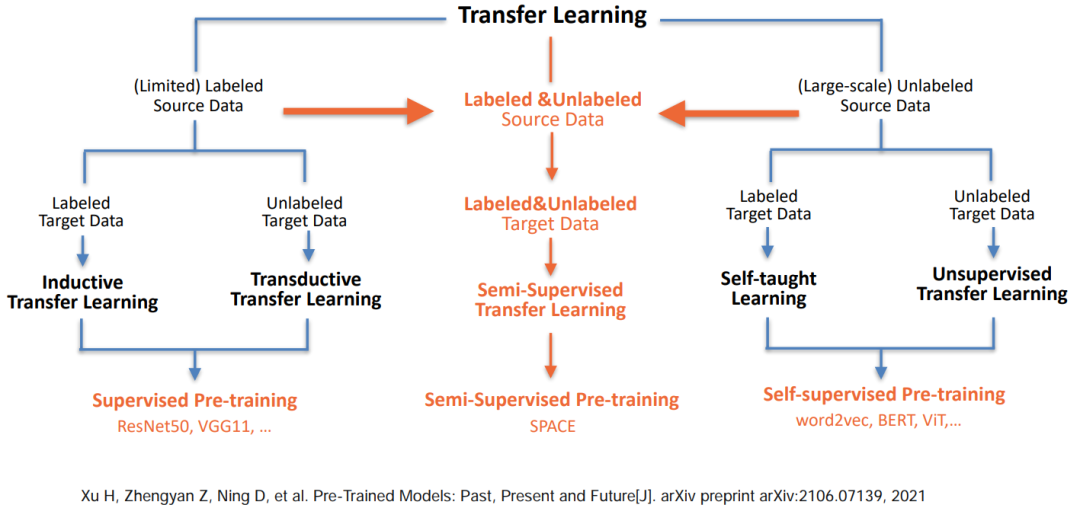
干货!半监督预训练对话模型 SPACE
Use of ThinkPHP template
随机推荐
Embedded UC (UNIX System Advanced Programming) -3
云安全日报220705:红帽PHP解释器发现执行任意代码漏洞,需要尽快升级
一文了解Go语言中的函数与方法的用法
Embedded-c Language-1
漫画:寻找股票买入卖出的最佳时机
【性能测试】jmeter+Grafana+influxdb部署实战
In depth understanding of redis memory obsolescence strategy
Design of electronic clock based on 51 single chip microcomputer
goto Statement
力扣解法汇总1200-最小绝对差
About JSON parsing function JSON in MySQL_ EXTRACT
高数 | 旋转体体积计算方法汇总、二重积分计算旋转体体积
mysql5.6解析JSON字符串方式(支持复杂的嵌套格式)
Is it safe for qiniu business school to open a stock account? Is it reliable?
Read the basic grammar of C language in one article
中国银河证券开户安全吗 开户后多久能买股票
dried food! Semi supervised pre training dialogue model space
Rider 设置选中单词侧边高亮,去除警告建议高亮
mysql如何使用JSON_EXTRACT()取json值
WebApp开发-Google官方教程