当前位置:网站首页>ConvMAE(2022-05)
ConvMAE(2022-05)
2022-07-05 17:54:00 【GY-赵】

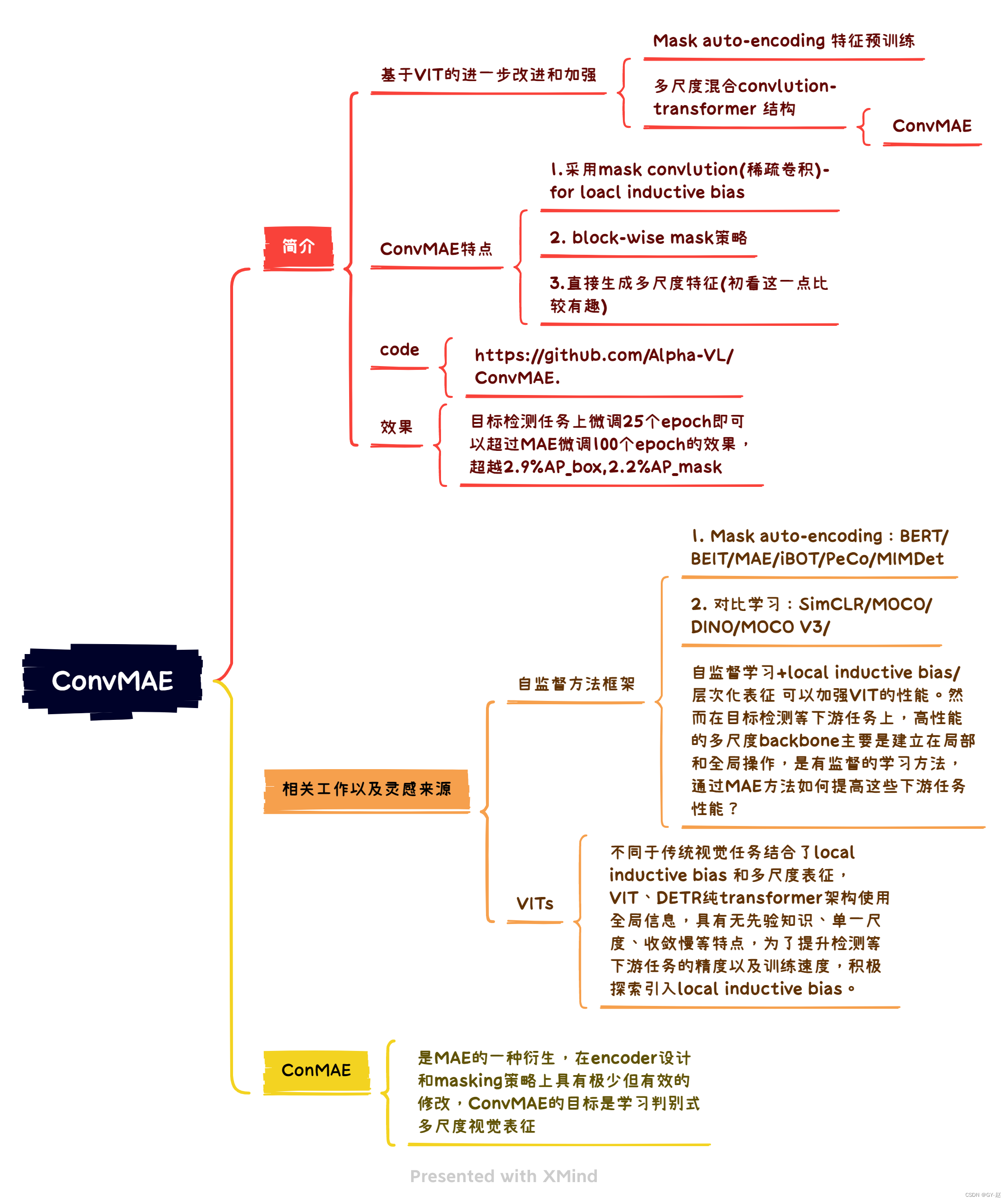
ConMAE
ConvMAE可以视为基于MAE的一种简单而有效的衍生品,对其编码器设计和掩码策略的最小但有效的修改。ConvMAE在Conv-transformer网络中应用时,其目的是学习判别性的多尺度视觉表示,并防止pre-train finetune差异化。
ConvMAE直接使用MAE的掩码策略将会使transformer layer在预训练期间保持所有的tokens,影响训练效率。因此,作者引入了一种层次化掩码策略对应于卷积阶段的掩码卷积,确保只有一小部分可视化token(没有mask掉的)送入transformer layer。
Encoder部分
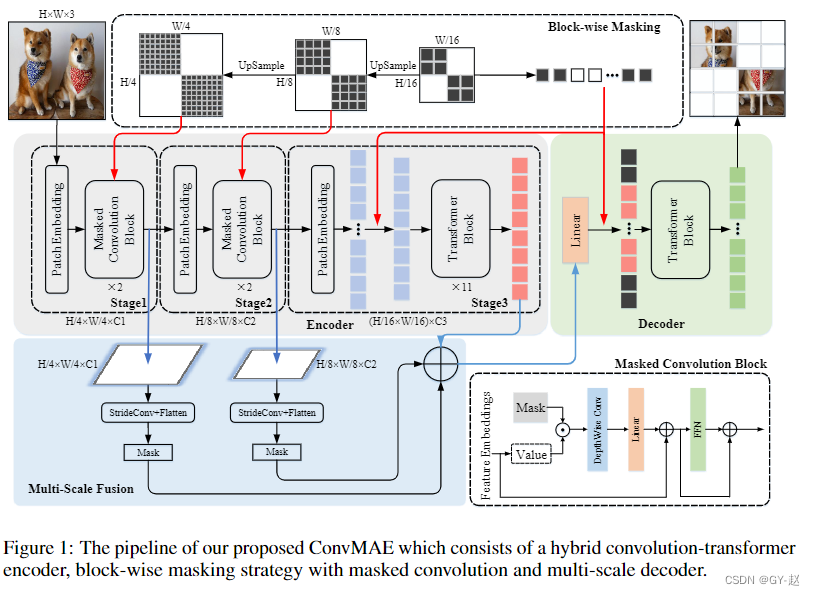
- 整体框架如图1,encoder包含3个stage,输入图像分辨率假设为(H,W,3),3个阶段输出空间分辨率分别为 ( H / 4 , W / 4 ) , ( H / 8. W / 8 ) , ( H / 16 , W / 16 ) (H/4,W/4),(H/8.W/8),(H/16,W/16) (H/4,W/4),(H/8.W/8),(H/16,W/16),前两个stage使用卷积层将输入转换为token Embeedings,分别为 E 1 ∈ R H 4 ∗ W 4 ∗ C 1 E_1 \in\mathbb{R}^{\frac{H}{4}*\frac{W}{4}*C_1} E1∈R4H∗4W∗C1, E 2 ∈ R H 8 ∗ W 8 ∗ C 2 E_2 \in\mathbb{R}^{\frac{H}{8}*\frac{W}{8}*C_2} E2∈R8H∗8W∗C2.卷积block的设计遵循transformer block的原则,仅仅将self-attention操作用 5 × 5 5\times5 5×5的卷积替代。第3个stage使用通用的self-attention blocks获取token Embeedings E 3 ∈ R H 16 × W 16 × C 3 E_3\in \mathbb{R}^{\frac{H}{16}\times\frac{W}{16}\times C_3} E3∈R16H×16W×C3。在每个stage之间,stride为2的卷积被用来下采样tokens到之前分辨率的一半。
- stages 1 和2 的卷积有较小的视野(可以理解为卷积的局部性),在stage3 transformer blocks对粗粒度特征进行聚合和复用,扩展视野到整张图像(全局信息).
- 不同于之前的CPT、Container、Uniformer、Swin等。将绝对位置嵌入替换为第一阶段输入的相对位置嵌入或零填充卷积,作者认为在变压器第3阶段的输入中添加绝对位置嵌入可以获得最优性能,class token也从编码器中移除,几乎没有什么影响。
Encoder具体细节:
- 给定输入图像 I ∈ R 3 × H × W I \in \mathbb{R}^{3×H×W} I∈R3×H×W, ConvMAE编码器的第1阶段首先使用非重叠4 × 4卷积生成一个高分辨率的token embeeding, E 1 ∈ R C 1 × H 4 × W 4 E_1∈R^{C_1 × \frac{H}{4} × \frac{W}{4}} E1∈RC1×4H×4W。然后将 E 1 E_1 E1送入堆叠的卷积块中,重复 L 1 L_1 L1次, L 1 L_1 L1表示第1阶段的层数。
- 与stage 1相似,stage 2使用非重叠2×2卷积进一步下采样特征映射到token embeedings : E 2 ∈ R C 2 × H 8 × W 8 E_2 \in \mathbb{R}^{C_2× \frac{H}{8} × \frac{W}{8}} E2∈RC2×8H×8W。 E 2 E_2 E2被 L 2 L_2 L2层卷积块再次处理。在第1阶段和第2阶段进行局部信息融合后,第3阶段利用transformer block进行全局特征融合。利用非重叠2 × 2卷积将 E 2 E_2 E2投影到token embeedings E 3 ∈ R ( H 16 × W 16 ) × C 3 E_3\in \mathbb{R}^{(\frac{H}{16} × \frac{W}{16})×C_3} E3∈R(16H×16W)×C3。将E3与中间位置嵌入(IPL)混合送入具有 L 3 L_3 L3层的纯transformer block。我们将阶段3中注意头的数量表示为 H a H_a Ha。不同时期FFN的mlp-比值分别记为 P 1 、 P 2 、 P 3 P_1、P_2、P_3 P1、P2、P3。
- Stage 1和Stage 2设计用于在高分辨率feature map上捕获细粒度的细节。Stage 3可以在一个低分辨率的特征映射上高效地执行动态全局推理。同时,第三阶段可以扩大backbone的视场(FOV),有利于广泛的下游任务。ConvMAE编码器可以无缝地继承卷积和transformer的优点。
表8列出了小模型、基础模型和大模型的架构细节。ConvMAE small、base、large和huge与MAE-small、MAE-base、MAE-large和MAE-huge的编码器具有相似的参数尺度.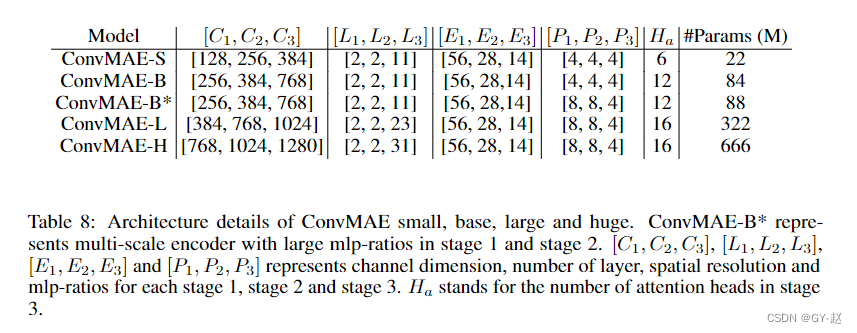
带有Masked-Convlutions 的Block-wise 掩码
- Maks auto-encoders,如MAE和BEiT,在输入token上采用随机掩码。然而,同样的策略不能直接应用于我们的ConvMAE encoder。统一mask掉 H 4 × W 4 \frac{H}{4}\times \frac{W}{4} 4H×4W特征图中的第1阶段输入标记会导致第3阶段的所有tokens中具有部分可见信息,并需要保留所有第3阶段tokens。因此,作者首先生成随机掩码,mask第3阶段输入token的p%(例如,75%),并对mask上采样2倍和4倍,分别得到对应的block-wise掩码,用于掩码第2阶段和第1阶段输入。在encoder过程中丢弃这三个阶段对应的掩码令牌,由解码器重构进行特征学习。这样,ConvMAE只需要在耗时的transformer block中保留25%的tokens进行训练,且不影响ConvMAE的效率。
- 然而,前两个阶段的5 × 5深度卷积自然会导致感受野超过掩码patch,当restructing masked tokens时造成信息泄露。为了避免这种信息泄露,同时保证预训练的质量,前两个阶段采用了掩码卷积,使掩码区域不参与encoding过程。掩蔽卷积的使用对ConvMAE的性能至关重要,并通过去除部分mask token来防止预训练和测试的差异。
多尺度decoder及loss
MAE decoder的输入部分是来源于Encoder的的可视化token E d E_d Ed以及mask tokens,在transformer blocks中进行组合用于图像重建任务。
- ConvMAE encoder获取多尺度特征 E 1 , E 2 , E 3 E_1,E_2,E_3 E1,E2,E3,捕获了细粒度和粗粒度图像信息。为了更好的监督这种多粒度表示的预训练,通过stride-4 和stride-2 卷积将 E 1 , E 2 E_1,E_2 E1,E2下采样到与 E 3 E_3 E3相同的尺寸大小,通过一个linear 层融合多粒度tokens以获取用于输入到decoder的可视化token。 E d = L i n e a r ( S t r i d e C o n v ( E 1 , 4 ) + S t r i d e C o n v ( E 2 , 2 ) + E 3 ) E_d=Linear(StrideConv(E_1,4)+StrideConv(E_2,2)+E_3) Ed=Linear(StrideConv(E1,4)+StrideConv(E2,2)+E3) StrideConv(.,K)表示stride-K的卷积。
- 损失函数与MAE一样考虑重建任务损失,目标函数只计算masked patches。
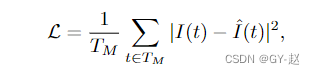
T M T_M TM是一系列masked token 而且t是token索引,重建目标 I I I为输入图像的归一化像素值, I ^ \hat{I} I^是重建图像。
ConvMAE 用于目标检测和语义分割等下游任务(只关注检测部分)
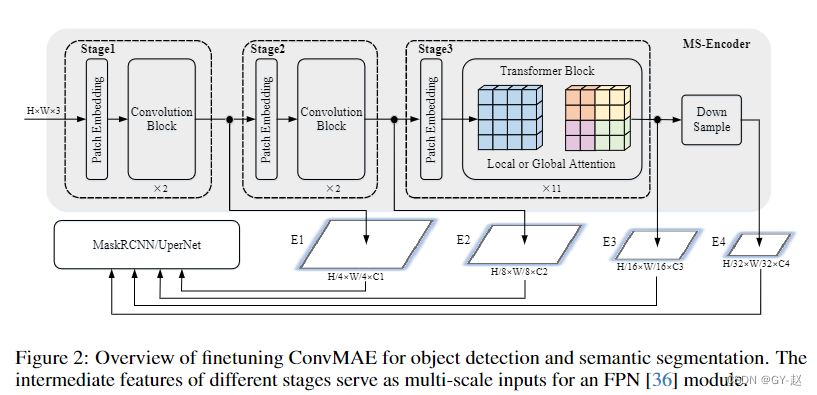
如上图2所示,通过 2 × 2 2 \times 2 2×2的最大池化下采样首先得到具有输入1/32的 E 4 E_4 E4。由于ConvMAE stage3有11个全局self-attention layers(在ConvMAE-base模型中),计算成本过高,作者按照Benchmarking ViT将stage3中除第1、4、7、11个全局self-attention layer外的所有层替换为shift-window局部slef-attention—shifted 7 × 7 7 \times 7 7×7windows(Swin中的窗口自注意力).
修改后的local self-attention layer仍然由预训练的全局self-attention layer进行初始化。全局transformer block之间共享全局relative positional bias。同样,局部relative positional bias由局部transformer blocks共享。
通过这种方式stage3 的内存消耗和计算代价大大降低,多尺度特征 E 1 , E 2 , E 3 , E 4 E_1,E_2,E_3,E_4 E1,E2,E3,E4然后输入到MaskRCNN头用于目标检测。
实验
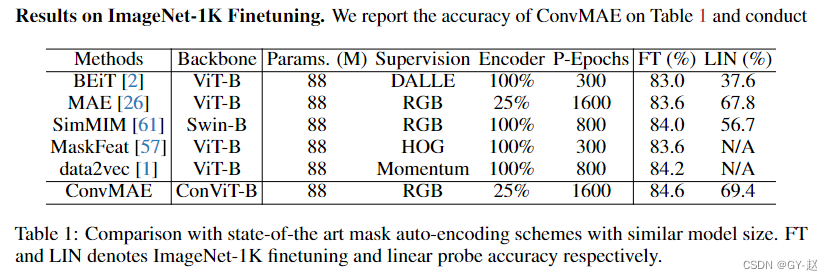
- 在ImageNet 1K上进行预训练后,再次在该数据集上进行微调100 epochs,下表是在ImageNet validation上分类准确率。P-Epochs代表预训练,FT代表finetune,LIN代表linear probe,Encoder部分代表mask ratio(1-表中数据)
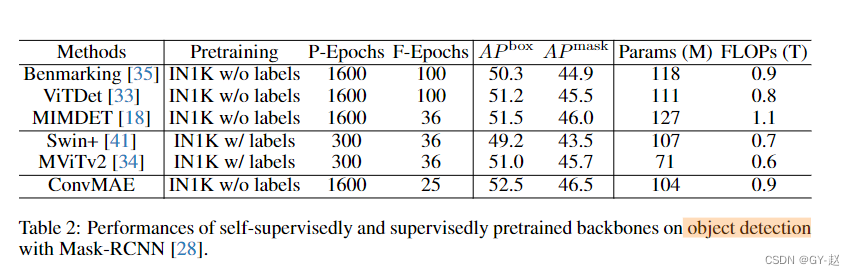
- 在目标检测中,使用COCO数据集,使用预训练的ConvMAE Encoder作为Mask RCNN的backbone,在COCO train2017数据集上进行finetune,在Val2017 split上报告AP值,与其它有监督和自监督方法比较如下。可以发现ConvMAE在finetune epoch只有25的情况下实现了最高性能。
消融实验
Pretraining epochs.
800和1600仅有细微的差别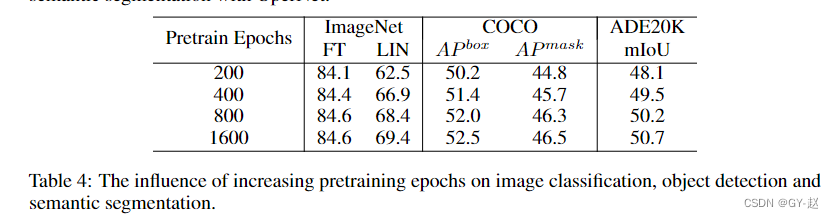
Input token random masking.
表格前两行表示mask策略的使用,第一行表示作者提出的block-wise mask ,第二行表示全部使用MAE mask策略
中间两行表示是否使用Mask Convlution
第一行和最后两行代表不同卷积核尺寸的影响,实验表明kernel 尺寸几乎没有影响。
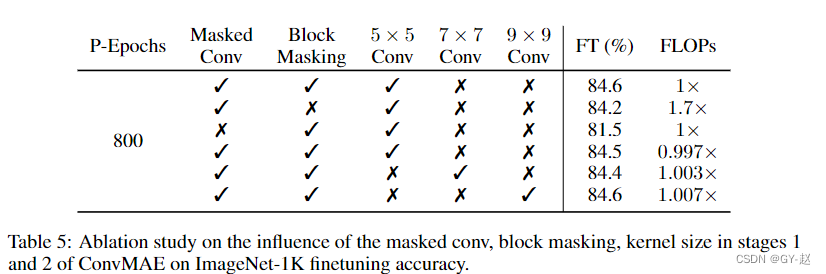
Multi-scale Decoder.
多尺度Decoder的影响,可以提高精度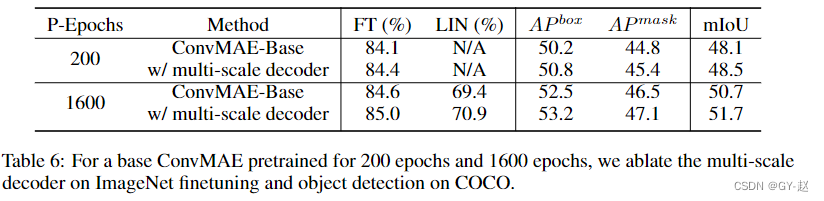
Model Scaling up and down.
不同规模模型尺寸对性能影响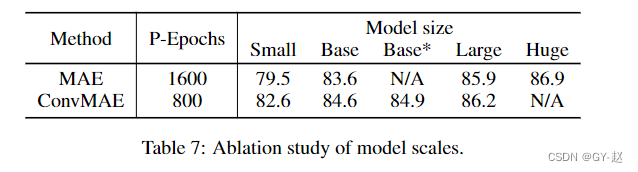
Convergence speed.
收敛速度,可以看到红色(ConvMAE)的精度要比绿色高,收敛速度也比较快。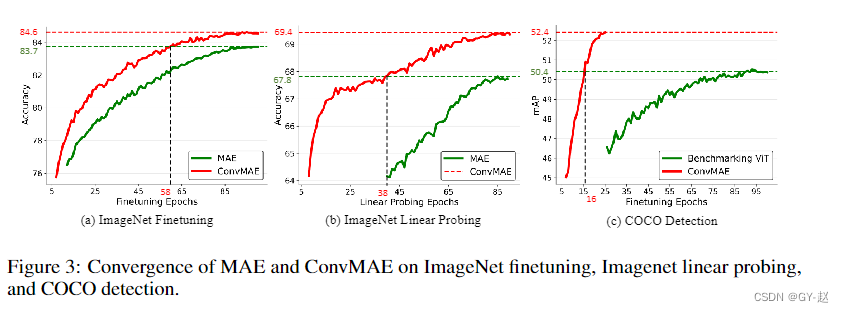
边栏推荐
猜你喜欢

南京大学:新时代数字化人才培养方案探讨
nacos -分布式事务-Seata** linux安装jdk ,mysql5.7启动nacos配置ideal 调用接口配合 (保姆级细节教程)
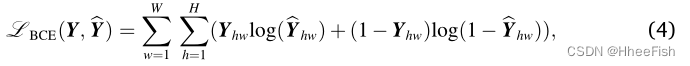
Isprs2022 / Cloud Detection: Cloud Detection with Boundary nets Boundary Networks Based Cloud Detection
FCN: Fully Convolutional Networks for Semantic Segmentation

星环科技数据安全管理平台 Defensor重磅发布

Mask wearing detection based on yolov3

寻找第k小元素 前k小元素 select_k

Redis基础
![[JMeter] advanced writing method of JMeter script: all variables, parameters (parameters can be configured by Jenkins), functions, etc. in the interface automation script realize the complete business](/img/a6/aa0b8d30913dc64f3c0cd891528c40.png)
[JMeter] advanced writing method of JMeter script: all variables, parameters (parameters can be configured by Jenkins), functions, etc. in the interface automation script realize the complete business

Six bad safety habits in the development of enterprise digitalization, each of which is very dangerous!
随机推荐
About Estimation with Cross-Validation
访问数据库使用redis作为mysql的缓存(redis和mysql结合)
How to modify MySQL fields as self growing fields
Star Ring Technology launched transwarp Navier, a data element circulation platform, to help enterprises achieve secure data circulation and collaboration under privacy protection
「运维有小邓」用于云应用程序的单点登录解决方案
Anaconda中配置PyTorch环境——win10系统(小白包会)
Cmake tutorial Step4 (installation and testing)
华夏基金:基金行业数字化转型实践成果分享
星环科技重磅推出数据要素流通平台Transwarp Navier,助力企业实现隐私保护下的数据安全流通与协作
GIMP 2.10教程「建议收藏」
破解湖+仓混合架构顽疾,星环科技推出自主可控云原生湖仓一体平台
Configure pytorch environment in Anaconda - win10 system (small white packet meeting)
Matlab built-in function how different colors, matlab subsection function different colors drawing
Sophon AutoCV:助力AI工业化生产,实现视觉智能感知
Interpretation: how to deal with the current security problems faced by the Internet of things?
"Xiaodeng in operation and maintenance" is a single sign on solution for cloud applications
Action avant ou après l'enregistrement du message teamcenter
tkinter窗口预加载
小林coding的内存管理章节
2022新版PMP考试有哪些变化?