当前位置:网站首页>[paddlepaddle] paddedetection face recognition custom data set
[paddlepaddle] paddedetection face recognition custom data set
2022-07-05 18:02:00 【mtl1994】
【PaddlePaddle】 PaddleDetection Face recognition Custom datasets
Use paddleDetection Face recognition is realized
List of articles
# Preface
Use paddleDetection Face recognition
brief introduction
PaddleDetection Development kit of flying propeller target detection , It aims to help developers complete the construction of detection model faster and better 、 Training 、 Optimize and deploy the whole development process .
PaddleDetection A variety of mainstream target detection algorithms are modularized , Provides a wealth of data enhancement strategies 、 Network module components ( Such as backbone network )、 Loss function, etc , It integrates model compression and cross platform high-performance deployment capabilities .
After a long period of industrial practice ,PaddleDetection Have a smooth 、 Excellent use experience , Industrial quality inspection 、 Remote sensing image detection 、 There's no patrol 、 The new retail 、 Internet 、 It is widely used by developers in more than ten industries such as scientific research .
characteristic
- The model is rich : contain object detection 、 Instance segmentation 、 Face detection etc. 100+ Pre training models , It covers a variety of Global champion programme
- Simple to use : Modular design , Decouple the various network components , Developers can easily build 、 Try various detection models and optimization strategies , Get high performance quickly 、 Customized Algorithm .
- Open end to end : Enhanced from data 、 networking 、 Training 、 Compress 、 Deploy end-to-end connection , And fully support Cloud / Border Multi architecture 、 Multi device deployment .
- High performance : High performance kernel based on propeller , Model training speed and video memory occupation advantages are obvious . Support FP16 Training , Support multi machine training .
One 、 Data set production
1. collecting data
Collect and run the following code from the local camera , It can also be obtained from other places
# -*- coding: utf-8 -*-
####### Run locally !!!!!!!!!
import cv2
import os
path = "./pictures/" # Image saving path
if not os.path.exists(path):
os.makedirs(path)
cap = cv2.VideoCapture(0)
i = 0
while (1):
ret, frame = cap.read()
k = cv2.waitKey(1)
if k == 27:
break
elif k == ord('s'):
cv2.imwrite(path + str(i) + '.jpg', frame)
print("save" + str(i) + ".jpg")
i += 1
cv2.imshow("capture", frame)
cap.release()
cv2.destroyAllWindows()
2. mark
open labelimg
1. Open the picture folder
2. Click on change_save_dir choice xml Save the path
3. mark
Two 、 download
# Download propeller
https://www.paddlepaddle.org.cn/
# download paddleDetection
# pip install paddledet
pip install paddledet==2.1.0 -i https://mirror.baidu.com/pypi/simple
# Download and use the configuration files and code samples in the source code
git clone https://github.com/PaddlePaddle/PaddleDetection.git
cd PaddleDetection
# Install other dependencies
pip install -r requirements.txt
3、 ... and 、 Training
1. Modify the configuration file
# Use ssd_mobilenet
#vim configs/ssd/ssd_mobilenet_v1_voc.yml
# Mainly modify the data set location
TrainReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class']
dataset:
!VOCDataSet
anno_path: trainval.txt
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
EvalReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class', 'im_shape', 'im_id', 'is_difficult']
dataset:
!VOCDataSet
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: val.txt
TestReader:
inputs_def:
image_shape: [3,300,300]
fields: ['image', 'im_id', 'im_shape']
dataset:
!ImageFolder
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: label_list.txt
Full profile
architecture: SSD
pretrain_weights: https://paddlemodels.bj.bcebos.com/object_detection/ssd_mobilenet_v1_coco_pretrained.tar
use_gpu: true
max_iters: 2800
snapshot_iter: 2000
log_iter: 1
metric: VOC
map_type: 11point
save_dir: output
weights: output/ssd_mobilenet_v1_voc/model_final
# 20(label_class) + 1(background)
num_classes: 25
SSD:
backbone: MobileNet
multi_box_head: MultiBoxHead
output_decoder:
background_label: 0
keep_top_k: 200
nms_eta: 1.0
nms_threshold: 0.45
nms_top_k: 400
score_threshold: 0.01
MobileNet:
norm_decay: 0.
conv_group_scale: 1
conv_learning_rate: 0.1
extra_block_filters: [[256, 512], [128, 256], [128, 256], [64, 128]]
with_extra_blocks: true
MultiBoxHead:
aspect_ratios: [[2.], [2., 3.], [2., 3.], [2., 3.], [2., 3.], [2., 3.]]
base_size: 300
flip: true
max_ratio: 90
max_sizes: [[], 150.0, 195.0, 240.0, 285.0, 300.0]
min_ratio: 20
min_sizes: [60.0, 105.0, 150.0, 195.0, 240.0, 285.0]
offset: 0.5
LearningRate:
schedulers:
- !PiecewiseDecay
milestones: [10000, 15000, 20000, 25000]
values: [0.001, 0.0005, 0.00025, 0.0001, 0.00001]
OptimizerBuilder:
optimizer:
momentum: 0.0
type: RMSPropOptimizer
regularizer:
factor: 0.00005
type: L2
TrainReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class']
dataset:
!VOCDataSet
anno_path: trainval.txt
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !RandomDistort
brightness_lower: 0.875
brightness_upper: 1.125
is_order: true
- !RandomExpand
fill_value: [127.5, 127.5, 127.5]
- !RandomCrop
allow_no_crop: false
- !NormalizeBox {}
- !ResizeImage
interp: 1
target_size: 300
use_cv2: false
- !RandomFlipImage
is_normalized: true
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 4
shuffle: true
drop_last: true
worker_num: 8
bufsize: 16
use_process: true
EvalReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class', 'im_shape', 'im_id', 'is_difficult']
dataset:
!VOCDataSet
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: val.txt
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !NormalizeBox {}
- !ResizeImage
interp: 1
target_size: 300
use_cv2: false
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 4
worker_num: 8
bufsize: 16
use_process: false
TestReader:
inputs_def:
image_shape: [3,300,300]
fields: ['image', 'im_id', 'im_shape']
dataset:
!ImageFolder
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: label_list.txt
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !ResizeImage
interp: 1
max_size: 0
target_size: 300
use_cv2: true
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 1
2. Start training
python -u tools/train.py -c configs/ssd/ssd_mobilenet_v1_voc.yml -o --eval
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-qhhnrgL3-1656931184790)(C:\Users\e9\AppData\Roaming\Typora\typora-user-images\image-20210712141658919.png)]
3. The export model
python tools/export_model.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model
Four 、 Use
python -u deploy/python/infer.py --model_dir D:/Paddle/PaddleDetection/PaddleDetection/output/ssd_mobilenet_v1_voc/ssd_mobilenet_v1_voc
nfigs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model ```
Four 、 Use
python -u deploy/python/infer.py --model_dir D:/Paddle/PaddleDetection/PaddleDetection/output/ssd_mobilenet_v1_voc/ssd_mobilenet_v1_voc
# summary
边栏推荐
- Cmake tutorial Step2 (add Library)
- Generate XML schema from class
- 星环科技重磅推出数据要素流通平台Transwarp Navier,助力企业实现隐私保护下的数据安全流通与协作
- Nanjing University: Discussion on the training program of digital talents in the new era
- Privacy computing helps secure data circulation and sharing
- IDC report: Tencent cloud database ranks top 2 in the relational database market!
- 小林coding的内存管理章节
- JVM third talk -- JVM performance tuning practice and high-frequency interview question record
- Find the first k small element select_ k
- Zabbix
猜你喜欢

leetcode每日一练:旋转数组
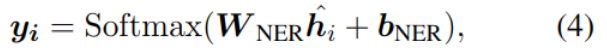
Thesis reading_ Chinese NLP_ LTP
Neural network self cognition model

Ten capabilities that cyber threat analysts should have

ISPRS2020/云检测:Transferring deep learning models for cloud detection between Landsat-8 and Proba-V
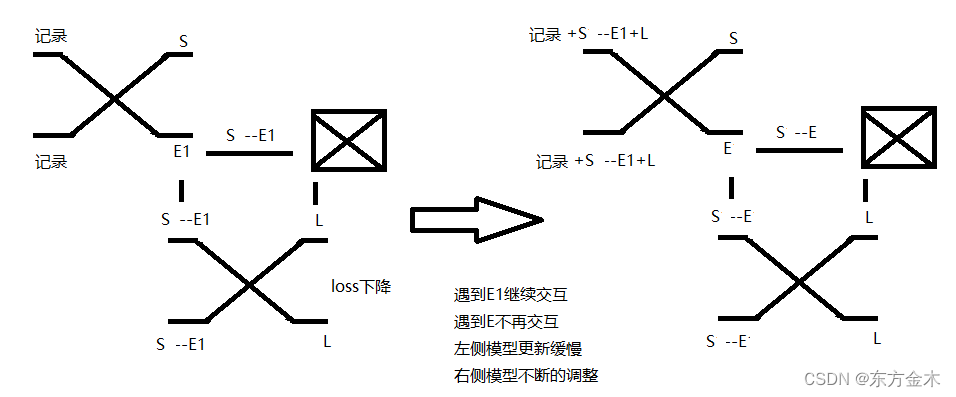
flask接口响应中的中文乱码(unicode)处理
Unicode processing in response of flash interface

南京大学:新时代数字化人才培养方案探讨
Sophon Base 3.1 推出MLOps功能,为企业AI能力运营插上翅膀
Sophon CE社区版上线,免费Get轻量易用、高效智能的数据分析工具
随机推荐
Privacy computing helps secure data circulation and sharing
OpenShift常用管理命令杂记
在一台服务器上部署多个EasyCVR出现报错“Press any to exit”,如何解决?
Gimp 2.10 tutorial "suggestions collection"
星环科技重磅推出数据要素流通平台Transwarp Navier,助力企业实现隐私保护下的数据安全流通与协作
Ten top automation and orchestration tools
Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
Why is February 28 in the Gregorian calendar
小林coding的内存管理章节
Leetcode exercise - 206 Reverse linked list
访问数据库使用redis作为mysql的缓存(redis和mysql结合)
Sophon CE社区版上线,免费Get轻量易用、高效智能的数据分析工具
Operation before or after Teamcenter message registration
华夏基金:基金行业数字化转型实践成果分享
Six bad safety habits in the development of enterprise digitalization, each of which is very dangerous!
Customize the theme of matrix (I) night mode
使用QT遍历Json文档及搜索子对象
Huaxia Fund: sharing of practical achievements of digital transformation in the fund industry
数值计算方法 Chapter8. 常微分方程的数值解
Cmake tutorial step5 (add system self-test)