当前位置:网站首页>论文阅读_中文NLP_LTP
论文阅读_中文NLP_LTP
2022-07-05 17:16:00 【xieyan0811】
英文题目:N-LTP: An Open-source Neural Language Technology Platform for Chinese
中文题目:开源中文神经网络语言技术平台N-LTP
论文地址:https://arxiv.org/pdf/2009.11616v4.pdf
领域:自然语言处理
发表时间:2021
作者:Wanxiang Che等,哈工大
出处:EMNLP
被引量:18+
代码和数据:https://github.com/HIT-SCIR/ltp
阅读时间:22.06.20
读后感
它是一个基于Pytorch的针对中文的离线工具,带训练好的模型,最小模型仅164M。直接支持分词,命名实体识别等六种任务,六种任务基本都围绕分词、确定词的成份、关系。
实测:比想象中好用,如果用于识别人名,效果还可以,直接用于垂直领域,效果一般,可能还需要进一步精调。
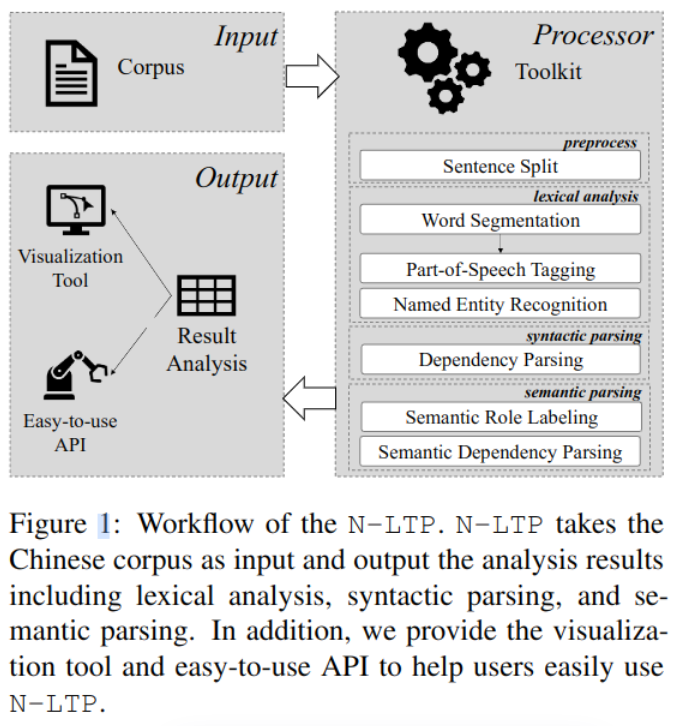
文章贡献
- 支持六项中文自然语言任务。
- 基于多任务框架,共享知识,减少内存用量,加快速度。
- 高扩展性:支持用户引入的BERT类模型。
- 容易使用:支持多语言接口 C++, Python, Java, Rust
- 达到比之前模型更好的效果
设计和架构
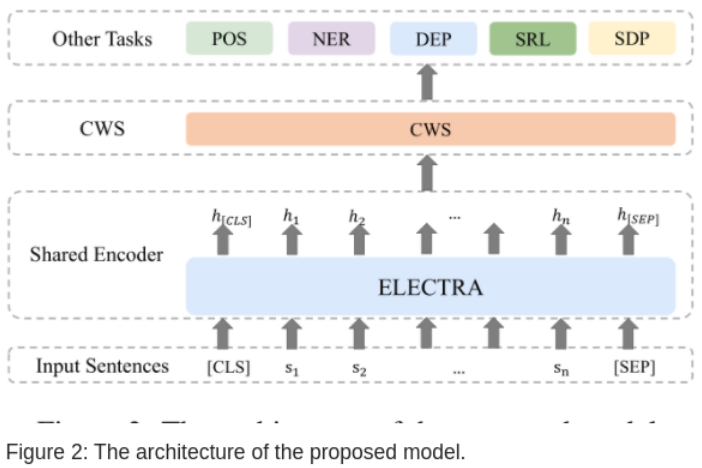
图-2展示了软件架构,由一个多任务共享的编码层和各任务别实现的解码层组成。
共享编码层
使用预训练的模型 ELECTRA,输入序列是s=(s1,s2,…,sn),加入符号将其变成 s = ([CLS], s1, s2, . . . , sn, [SEP]),请见BERT原理,输出为对应的隐藏层编码
H = (h[CLS],h1, h2, . . . , hn, h[SEP])。
中文分词 CWS
将编码后的H代入线性解码器,对每个字符分类:
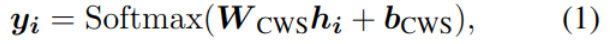
y是每个字符类别为各标签的概率。
位置标注 POS
位置标注也是NLP中的一个重要任务,用于进一步的语法解析。目前的主流方法是将其视为序列标注问题。也是将编码后的H作为输入,输出位置的标签:
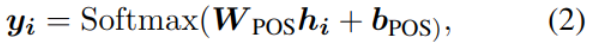
y是该位置字符属于某一标签的概率,其中i是位置信息。
命名实体识别 NER
命名实体识别的目标是寻找实体的开始位置和结束位置,以及该实体的类别。工具中使用Adapted-Transformer方法,加入方向和距离特征:

最后一步也使用线性分类器计算每个词的类别:
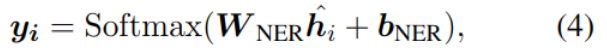
其中y是NER属于某一标签的概率。
依赖性解析 DEP
依赖性解析主要是分析句子的语义结构(详见网上示例),寻找词与词之间的关系。软件中具体使用了双仿射神经网络和einser算法。
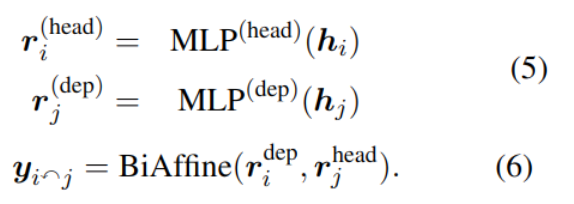
语义依解析 SDP
与依赖性分析相似,语义依赖分析也是捕捉句子的语义结构。它将句子分析成一棵依存句法树,描述出各个词语之间的依存关系。也即指出了词语之间在句法上的搭配关系,这种搭配关系是和语义相关联的。具体包括:主谓关系SBV,动宾关系VOB,定中关系ATT等,详见:
从0到1,手把手教你如何使用哈工大NLP工具——PyLTP
具方法是查找语义上相互关联的词对,并找到预定义的语义关系。实现也使用了双仿射模型。

当p>0.5时,则认为词 i 与 j 之间存在关联。
语义角色标注 SRL
语义角色标注主要目标是识别句子以谓语为中心的结构,具体方法是使用端到端的SRL模型,它结合了双仿射神经网络和条件随机场作为编码器,条件随机场公式如下:
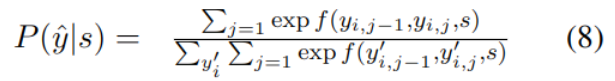
其中f用于计算从yi,j-1到yi,j的转移概率。
知识蒸馏
为了比较单独训练任务和多任务训练,引入了BAM方法: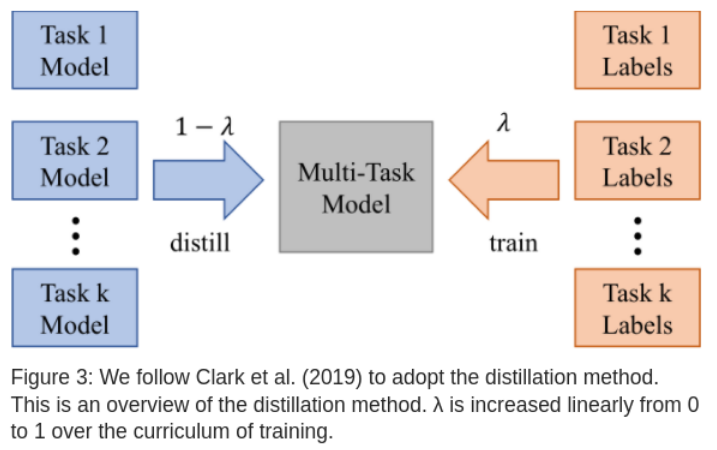
用法
安装
$ pip install ltp
在线demo
http://ltp.ai/demo.html
示例代码
from ltp import LTP
ltp = LTP()
seg, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
pos = ltp.pos(hidden)
ner = ltp.ner(hidden)
srl = ltp.srl(hidden)
dep = ltp.dep(hidden)
sdp = ltp.sdp(hidden)
其中seg函数实现了分词,并输出了切分结果,及各词的向量表示。
精调模型
下载源码
$ git clone https://github.com/HIT-SCIR/ltp
在其 ltp 目录中有 task_xx.py,可训练及调优模型,用法详见py内部的示例。形如:
python ltp/task_segmention.py --data_dir=data/seg --num_labels=2 --max_epochs=10 --batch_size=16 --gpus=1 --precision=16 --auto_lr_find=lr
实验
Stanza是支持一个多语言的NLP工具,中文建模效果比较如下:
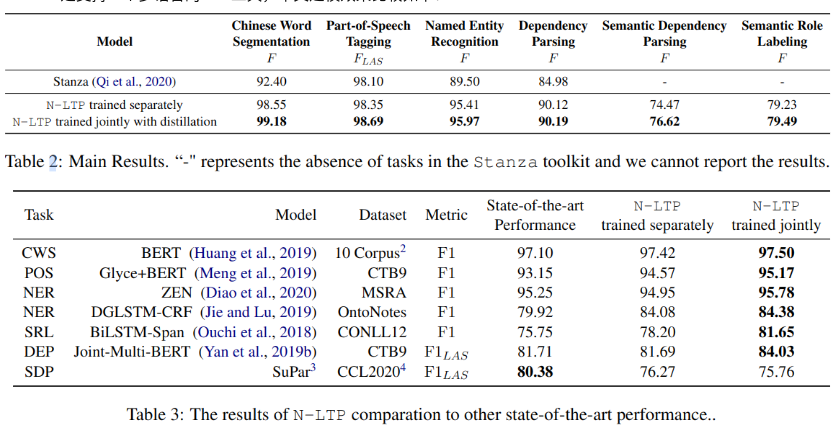
另外,实验也证明,使用联合模型速度更快,占用内存更少。
参考
边栏推荐
- stirring! 2022 open atom global open source summit registration is hot!
- Tips for extracting JSON fields from MySQL
- Domain name resolution, reverse domain name resolution nbtstat
- 外盘黄金哪个平台正规安全,怎么辨别?
- 查看自己电脑连接过的WiFi密码
- Disabling and enabling inspections pycharm
- Ant financial's sudden wealth has not yet begun, but the myth of zoom continues!
- Humi analysis: the integrated application of industrial Internet identity analysis and enterprise information system
- 漫画:有趣的【海盗】问题
- Machine learning 01: Introduction
猜你喜欢
ICML 2022 | Meta提出鲁棒的多目标贝叶斯优化方法,有效应对输入噪声
Summary of optimization scheme for implementing delay queue based on redis
CMake教程Step1(基本起点)
33:第三章:开发通行证服务:16:使用Redis缓存用户信息;(以减轻数据库的压力)
深入理解Redis内存淘汰策略
Count the running time of PHP program and set the maximum running time of PHP
In depth understanding of redis memory obsolescence strategy

网络威胁分析师应该具备的十种能力
統計php程序運行時間及設置PHP最長運行時間

URP下Alpha从Gamma空间到Linner空间转换(二)——多Alpha贴图叠加

随机推荐
MySQL queries the latest qualified data rows
2022年信息系统管理工程师考试大纲
Redis+caffeine two-level cache enables smooth access speed
证券网上开户安全吗?证券融资利率一般是多少?
C (WinForm) the current thread is not in a single threaded unit, so ActiveX controls cannot be instantiated
提高应用程序性能的7个DevOps实践
Cloud security daily 220705: the red hat PHP interpreter has found a vulnerability of executing arbitrary code, which needs to be upgraded as soon as possible
Humi analysis: the integrated application of industrial Internet identity analysis and enterprise information system
使用QT设计师界面类创建2个界面,通过按键从界面1切换到界面2
哈趣K1和哈趣H1哪个性价比更高?谁更值得入手?
Abnormal recovery of virtual machine Oracle -- Xi Fenfei
Understand the usage of functions and methods in go language
漫画:寻找无序数组的第k大元素(修订版)
漫画:有趣的【海盗】问题
Winedt common shortcut key modify shortcut key latex compile button
机器学习01:绪论
关于mysql中的json解析函数JSON_EXTRACT
To solve the problem of "double click PDF file, pop up", please install Evernote program
漫画:有趣的海盗问题 (完整版)
漫画:如何实现大整数相乘?(整合版)