当前位置:网站首页>Machine learning 02: model evaluation
Machine learning 02: model evaluation
2022-07-05 17:16:00 【Fei Fei is a princess】
Evaluation methods
- Before the learned model is put into use , Performance evaluation is usually required . So , Need to use a “ Test set ”(testing set) To test the generalization ability of the model to new samples , Then take the... On the test set “ Test error ”(testing error) As an approximation of the generalization error .
- We assume that the test set is obtained by independent sampling from the real distribution of samples , Therefore, the test set and the samples in the training set should be mutually exclusive as far as possible .
- Given a known data set , Split the data set into training sets S And test set T, Common practices include setting aside 、 Cross validation 、 Self help law .
Set aside method
- Directly divide the data set into two mutually exclusive sets , Training set S And test set T
- Generally, it is divided randomly several times , Because the same data set , The same division ratio , It can also be divided into many different training sets and test sets , such as 1000 Data sets ( These include 500 A good example ,500 A counterexample ), according to 7:3 Divided by the proportion of ( C 500 150 ) 2 (C_{500}^{150})^{2} (C500150)2 Different groups . Practical application , We were randomly assigned several times , All experiments are averaged , As a test error ( Generalization error approximation ).
- Training / The proportion of test samples is usually 2:1~4:1, About to 2/3~4/5 A sample of is used for training , The remaining samples are used for testing .
Cross validation
The data set is divided into k A mutually exclusive subset of similar size , Each time k-1 Union of subsets as training set , The remaining subset is used as the test set , Eventually return k The average of the test results ,k The most commonly used value is 10.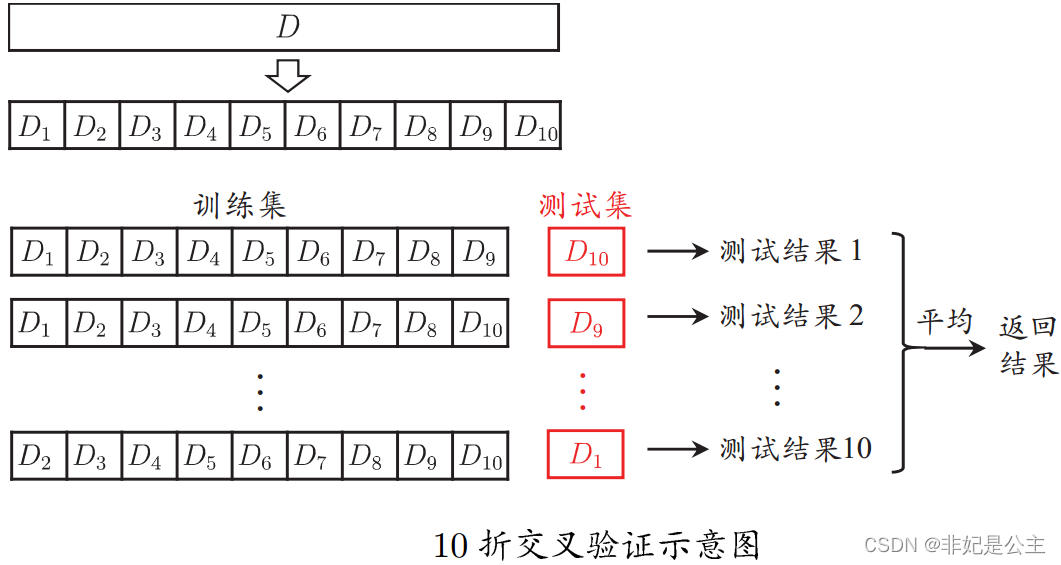
explain :D1,D2,D3…… Are different subsets , First test D 10 D_{10} D10 As test set , Second test D 9 D_{9} D9 As test set …… The first 10 Secondary test D 1 D_{1} D1 As test set , In the end, all measuring try junction fruit 1 test result _{1} measuring try junction fruit 1~ measuring try junction fruit 10 test result _{10} measuring try junction fruit 10 Take the average value as the test error .
Similar to the set aside method , Put the dataset D Divided into k There are also many ways to divide subsets , In order to reduce the differences introduced by different sample divisions ,k Fold cross validation usually repeats randomly with different partitions p Time , The final assessment is this p Time k The mean value of fold cross validation results , For example, common “10 Time 10 Crossover verification ”.
Keep one
The limit case of cross validation , When each subset has only one element , Just leave one way , Leaving one method has the following characteristics :
- Not affected by the way of random sample division
- The results are often more accurate
- When the data set is large , The computational overhead is unbearable
Self help law
Based on self-help sampling method , The data set D There is a return sample m Get a training set , As a test set, both the actual model and the expected model are used m Training samples (m About% of the total number of samples 1 3 \frac{1}{3} 31)
A plurality of different training sets are generated from the initial data set , It is very good for integrated learning
The self-help method is smaller in the data set 、 It's hard to divide training effectively / It's useful when testing sets ; Estimation bias may be introduced due to changing the data set distribution , When the amount of data is sufficient , Set aside method and cross validation method are more commonly used .
Evaluation indicators
To evaluate the quality of the model, only the evaluation method is not enough , We have to determine the evaluation indicators .
Accuracy and error rate
Compare the model results with the real situation , The two most commonly used indicators are Accuracy rate and Error rate
Accuracy rate : That is, the proportion of paired samples in the total number of test samples ;
Error rate : That is, the proportion of wrong samples in the total number of test samples
Precision and recall
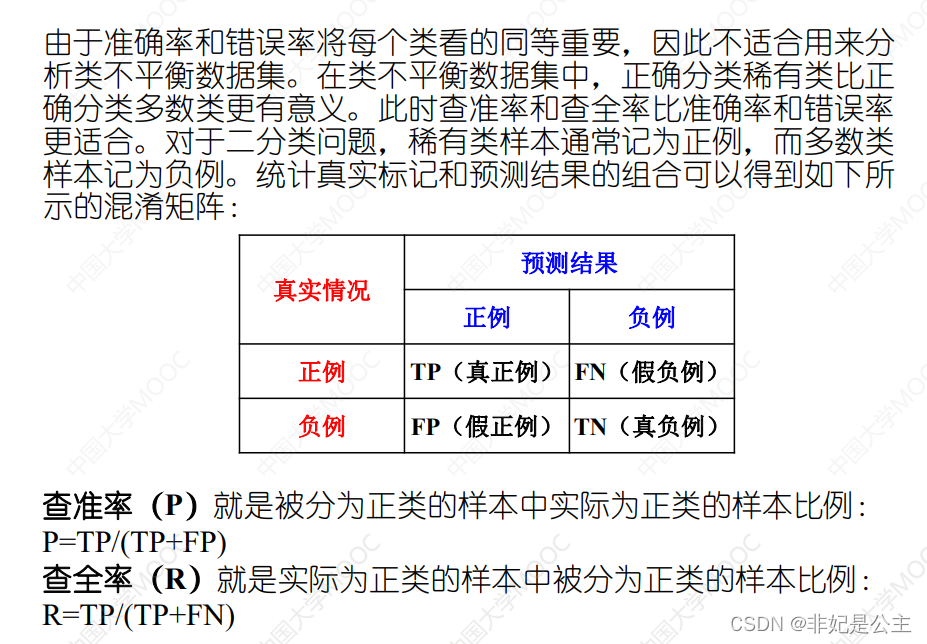


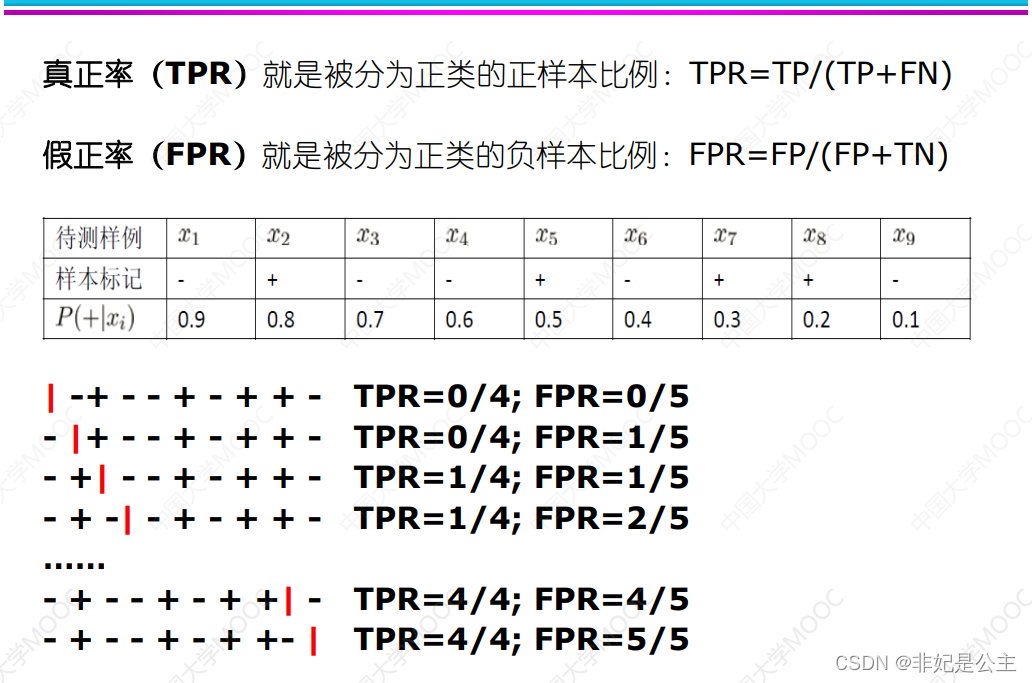
real : The proportion of all positives is divided into positive
False positive : All negatives are divided into positive proportions 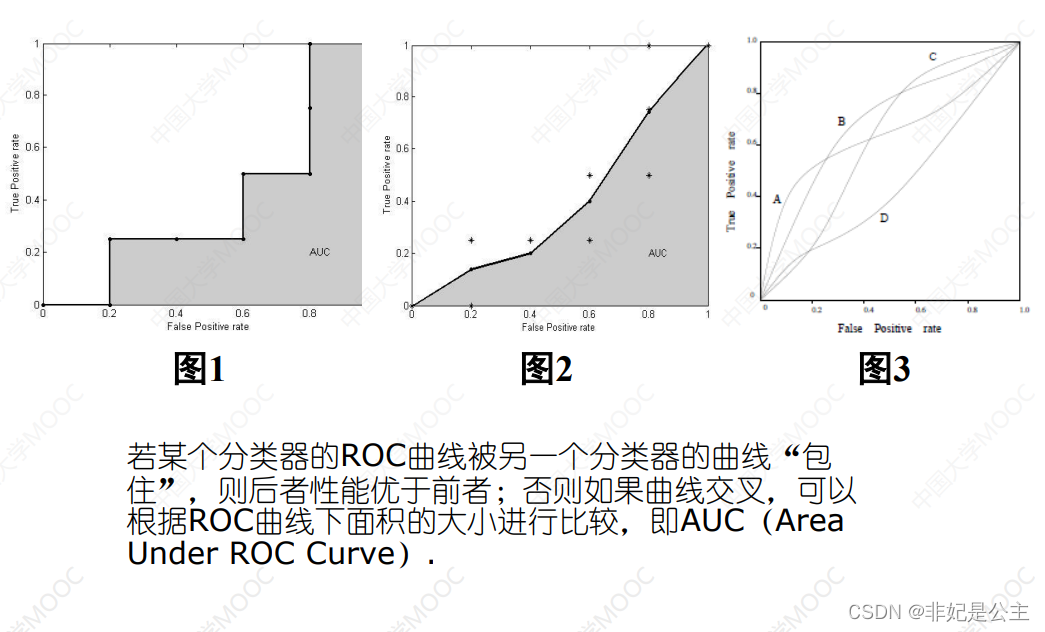
You can calculate the size of the area by integrating !
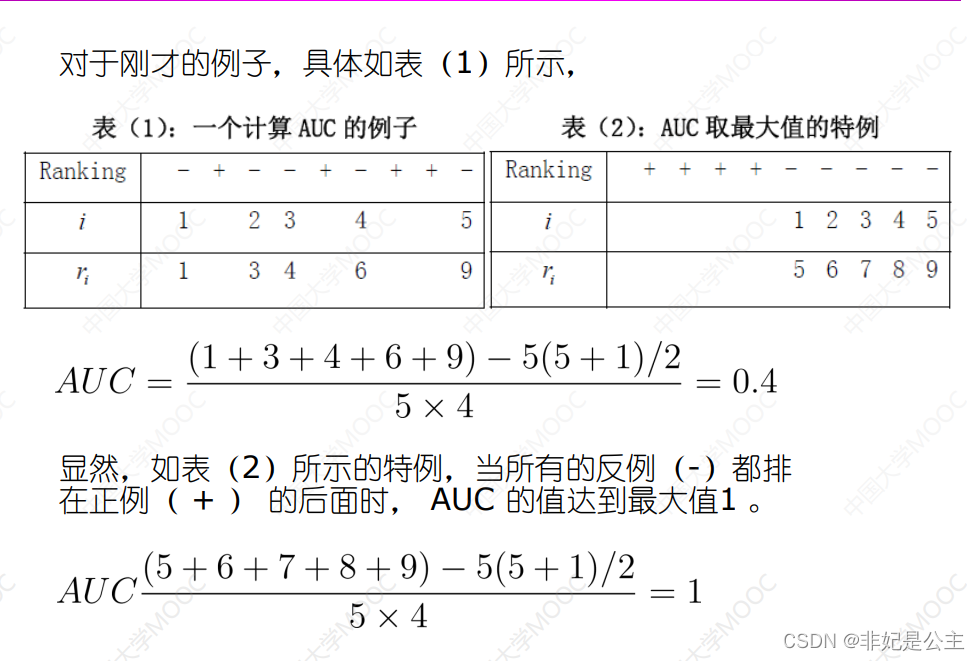

Comparative test
There are the following questions about performance comparison :
- Test performance is not equal to generalization performance
- Test performance will change as the test set changes
- Many machine learning algorithms have certain randomness
therefore , It is not advisable to evaluate directly through evaluation indicators , Because what we get is the expression effect on a specific data set , To be more persuasive in Mathematics , We also need to test hypotheses .
Hypothesis testing It provides an important basis for the performance comparison of classifiers , Based on the results, we can infer , If in Test set Observe the classifier A Than B good , be A Of Generalization performance Whether in Statistically higher than B, And how sure this conclusion is .
Paired bilateral t test

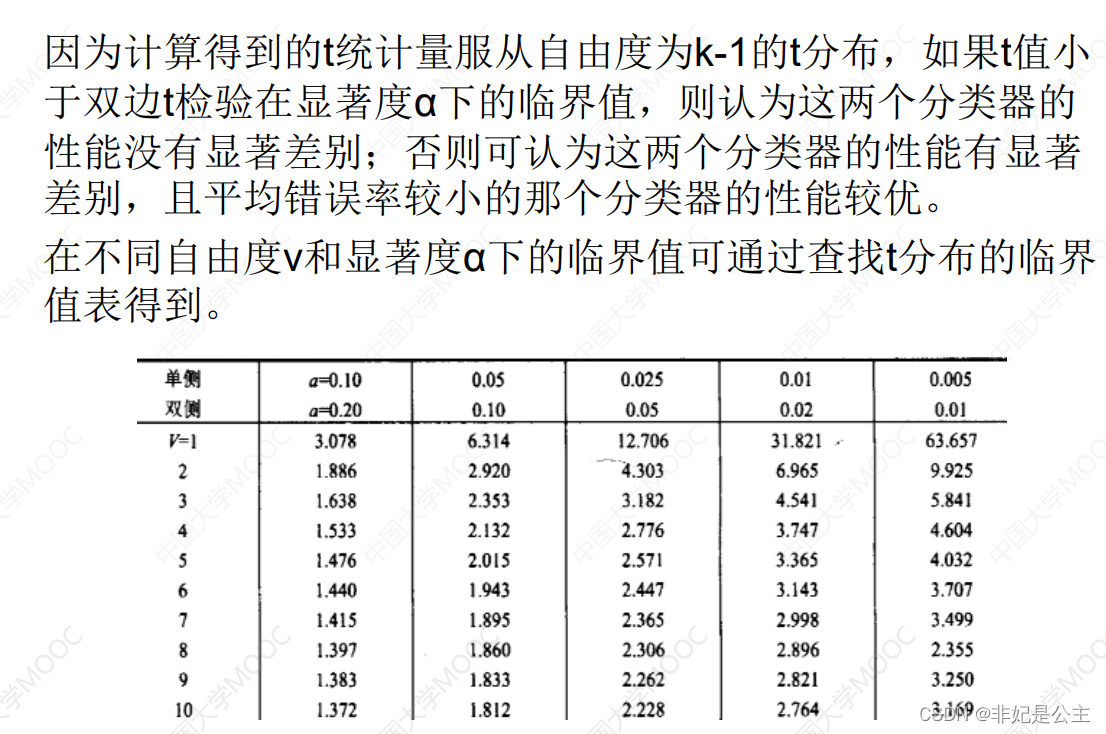
Simply speaking , Divided into the following steps
- Calculate the mean μ \mu μ
- Calculate variance σ 2 \sigma^2 σ2
- Calculation T statistic τ t \tau_t τt
- According to degrees of freedom V V V And confidence α \alpha α Look up the table , Get the critical value , If τ t < In the world value \tau_t< critical value τt< In the world value , shows “ In confidence α \alpha α Under the premise of , It can be considered that the performance of the two classifiers is not significantly different , Otherwise, the performance of the two classifiers is considered to be significantly different , The classifier with low average error rate has better performance .”
Friedman Test and Nemenyi Follow up inspection
Paired bilateral t The test is to compare the performance of two classifiers on a data set , And a lot of the time , We need to compare the performance of multiple classifiers on a set of data , This requires the use of sorting based Friedman test .
Suppose we are going to N Compare... On two data sets k Algorithms , First, use the set aside method or cross validation method to get the test results of each algorithm on each data set , Then sort on each data set according to the performance , And assign order value 1,2,…; If the algorithm performance is the same, then bisect the order value , Then we get the average order value of each algorithm on all data sets .
explain : The figure above is calculating “ Chi square distribution ” τ χ 2 \tau_{\chi^2} τχ2
N: Number of data sets
k: Number of models
And then calculate F statistic τ F \tau_F τF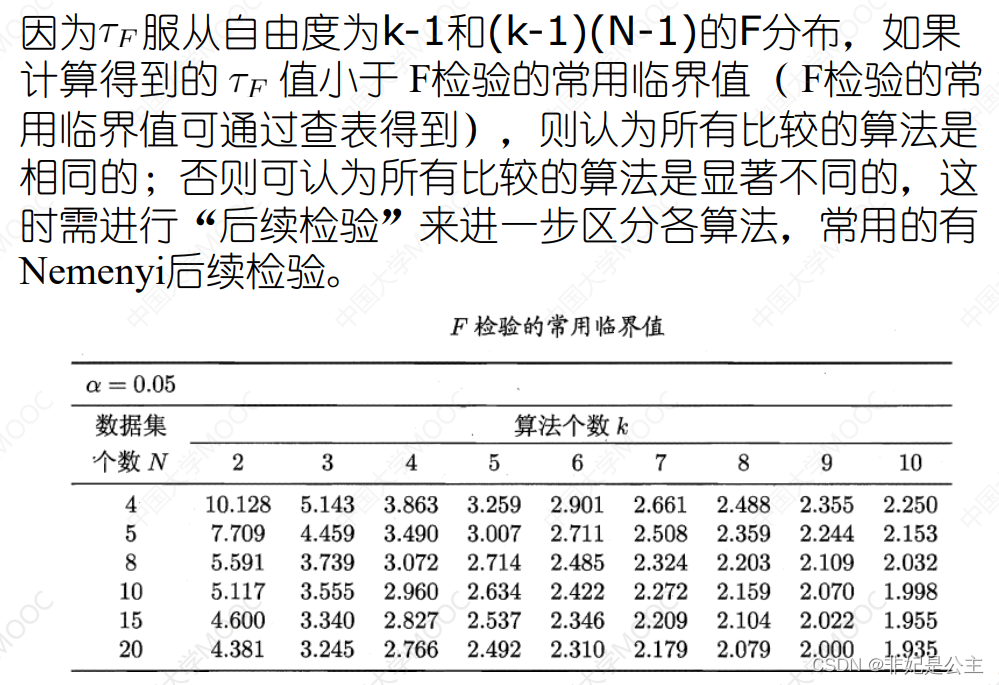
explain : according to N and k Look up the table , And then F statistic τ F \tau_F τF Compare , If τ F < often use In the world value \tau_F< Common critical values τF< often use In the world value , It is considered that the comparison algorithm is the same , Otherwise, the algorithm is considered to be significantly different , Only when the algorithm is considered to be significantly different , Before proceeding to the next step N e m e n y i check Examination Nemenyi test Nemenyi check Examination .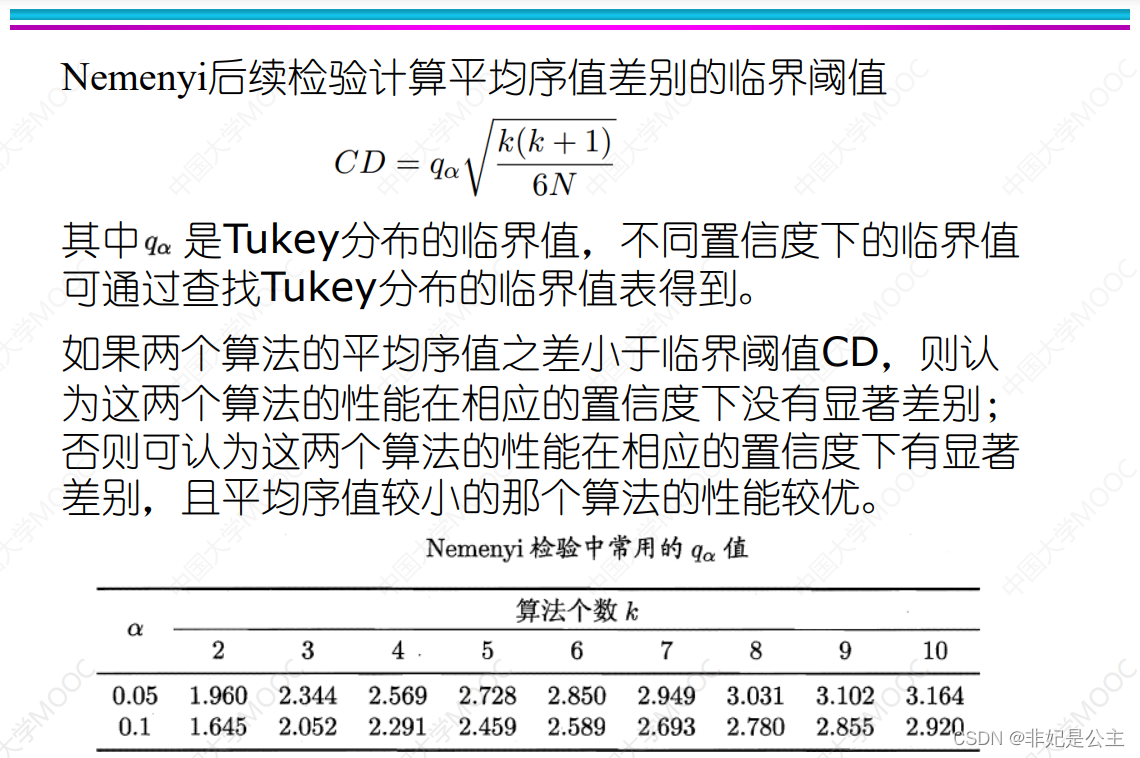
explain : Calculation CD value , q α q_\alpha qα By looking up the table of algorithm quantity (k,N It is known that )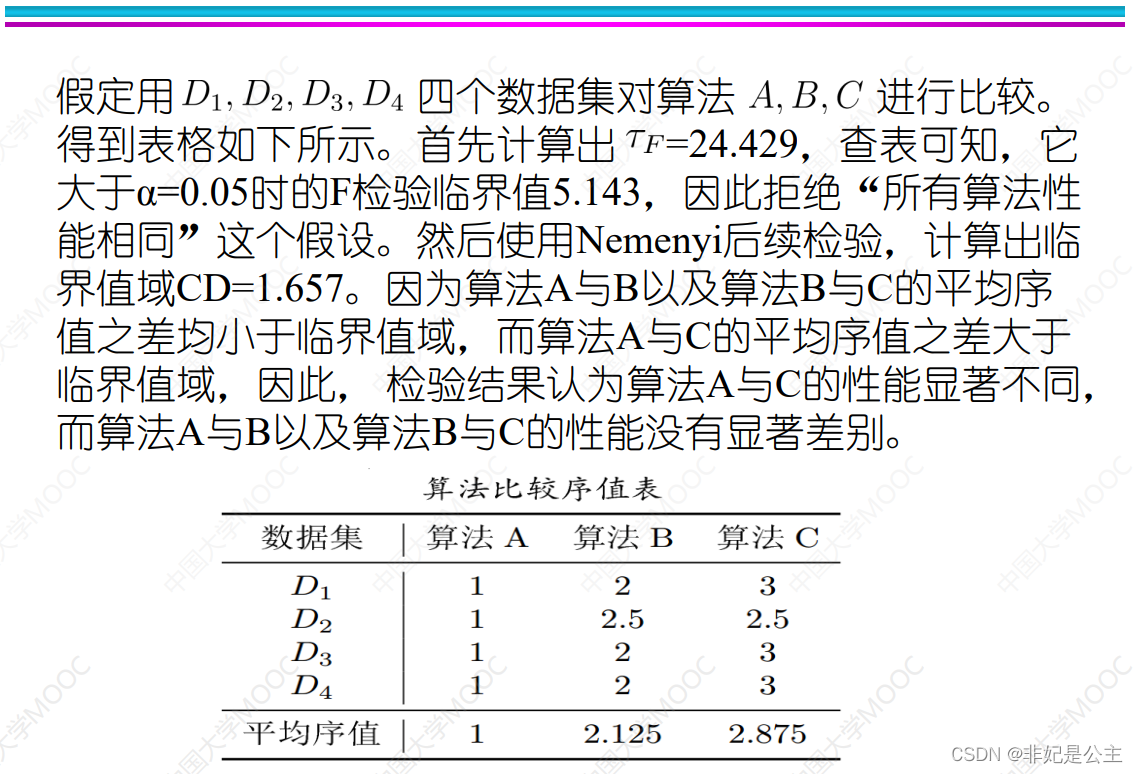
explain : Compare the sum of the difference of the average order values between the algorithms CD Size , If it is greater than CD Think significantly different , Less than CD Think there is no significant difference .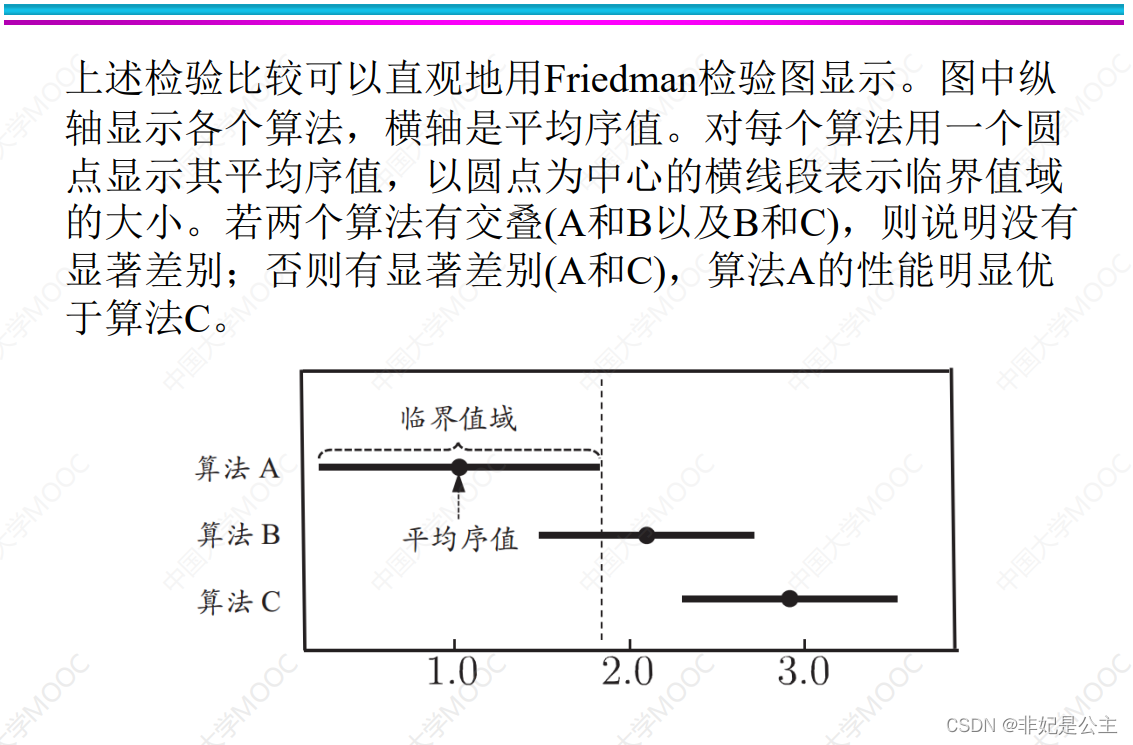
explain :Friedman The test chart can intuitively show the performance difference between the algorithms , It's just an intuitive representation , There is no new way .
边栏推荐
- 域名解析,反向域名解析nbtstat
- 云安全日报220705:红帽PHP解释器发现执行任意代码漏洞,需要尽快升级
- 时间戳strtotime前一天或后一天的日期
- Is it safe for qiniu business school to open a stock account? Is it reliable?
- [729. My Schedule i]
- 【jmeter】jmeter脚本高级写法:接口自动化脚本内全部为变量,参数(参数可jenkins配置),函数等实现完整业务流测试
- 基于Redis实现延时队列的优化方案小结
- Copy mode DMA
- 浏览器渲染原理以及重排与重绘
- [7.7 live broadcast preview] the lecturer of "typical architecture of SaaS cloud native applications" teaches you to easily build cloud native SaaS applications. Once the problem is solved, Huawei's s
猜你喜欢

调查显示传统数据安全工具面对勒索软件攻击的失败率高达 60%
Learnopongl notes (II) - Lighting
![[Jianzhi offer] 63 Maximum profit of stock](/img/b6/c1dec97a23ac13aa53d1d202b83ef5.png)
[Jianzhi offer] 63 Maximum profit of stock
【Web攻防】WAF检测技术图谱

国内首家 EMQ 加入亚马逊云科技「初创加速-全球合作伙伴网络计划」
高数 | 旋转体体积计算方法汇总、二重积分计算旋转体体积

Embedded-c Language-1

Error in composer installation: no composer lock file present.

Application of threshold homomorphic encryption in privacy Computing: Interpretation

Iphone14 with pill screen may trigger a rush for Chinese consumers
随机推荐
网上办理期货开户安全吗?网上会不会骗子比较多?感觉不太靠谱?
CMake教程Step4(安装和测试)
Thoughtworks 全球CTO:按需求构建架构,过度工程只会“劳民伤财”
飞桨EasyDL实操范例:工业零件划痕自动识别
stirring! 2022 open atom global open source summit registration is hot!
【Web攻防】WAF检测技术图谱
ECU简介
高数 | 旋转体体积计算方法汇总、二重积分计算旋转体体积
IDC报告:腾讯云数据库稳居关系型数据库市场TOP 2!
MySQL queries the latest qualified data rows
Wsl2.0 installation
The third lesson of EasyX learning
CMake教程Step6(添加自定义命令和生成文件)
浏览器渲染原理以及重排与重绘
Twig数组合并的写法
easyNmon使用汇总
调查显示传统数据安全工具面对勒索软件攻击的失败率高达 60%
【性能测试】全链路压测
[Jianzhi offer] 66 Build product array
机器学习02:模型评估