当前位置:网站首页>dried food! Semi supervised pre training dialogue model space
dried food! Semi supervised pre training dialogue model space
2022-07-05 16:57:00 【Aitime theory】
Click on the blue words

Pay attention to our
AI TIME Welcome to everyone AI Fans join in !

How to integrate human prior knowledge into the pre training model at low cost has always been a problem NLP The problem of . In this work , A new training paradigm based on semi supervised pre training is proposed by the dialogue intelligent team of Dharma Academy , A small amount of marked dialogue data and a large amount of non-standard dialogue data are pre trained through semi supervised method , Using the consistent regularization loss function, the dialogue strategy knowledge contained in the labeled data is injected into the pre training model , So as to learn a better model representation .
A new semi supervised pre training dialogue model SPACE(Semi-Supervised Pre-trAined Conversation ModEl) Firstly, it focuses on the knowledge of dialogue strategies , Experiments show that ,SPACE1.0 Model in Cambridge MultiWOZ2.0, Amazon MultiWOZ2.1 And other classic conversation data sets 5%+ Significantly improve , And under various low resource settings ,SPACE1.0 Better than existing sota The models have stronger small sample learning ability .
In this issue AI TIME PhD studio , We invite Alibaba Dharma Institute senior algorithm engineer —— Dai yinpei , Bring us report sharing 《 Semi supervised pre training dialogue model SPACE》.

Dai yinpei :
Senior algorithm engineer of Alibaba Dharma Academy , Master graduated from the Department of electronic engineering of Tsinghua University , His research field is natural language processing and dialogue intelligence (Conversational AI), Specific directions include dialogue and understanding 、 Dialogue management and large-scale pre training dialogue model . stay ACL / AAAI / SIGIR/ ICASSP He has published many papers and served as ACL / EMNLP / NAACL / AAAI Wait for the reviewer of the meeting .
Pre-trained Conversation Model (PCM)
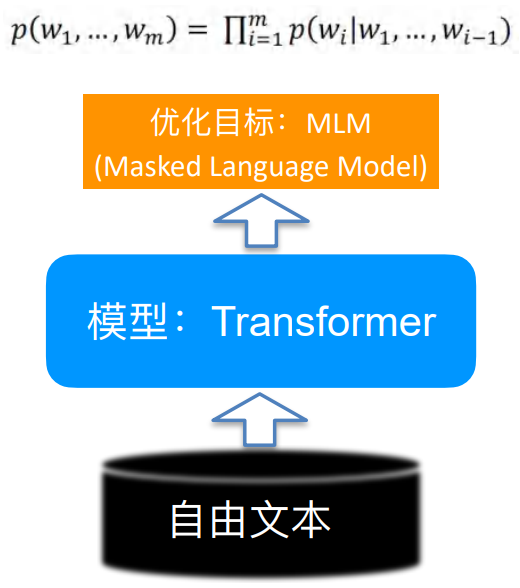
Recent pre training language models Pre-trained Language Model(PLM) It is extremely popular , Then why should we study the pre training dialogue model ? Although the former can bring a certain degree of effect improvement in many tasks , However, some articles show that a better pre training model can be obtained through the design of some loss functions . The pre training dialog model is designed for the downstream dialog tasks , It can be better improved on the basis of the pre training language model .
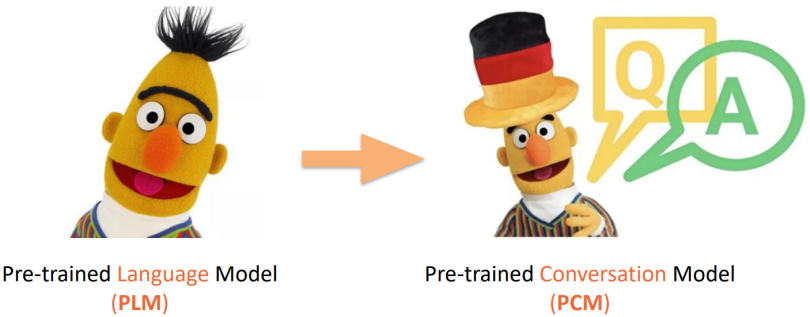
Pre training language model vs. Pre training dialogue model
• Pre-trained Language Model (PLM) Pre training language model
• What kind of sentences need to be answered ⼦ More like ⾃ But the language ⾔
• Pre-trained Conversation Model (PCM) Pre training dialogue model
• You need to answer the given dialogue history , What kind of reply is more reasonable
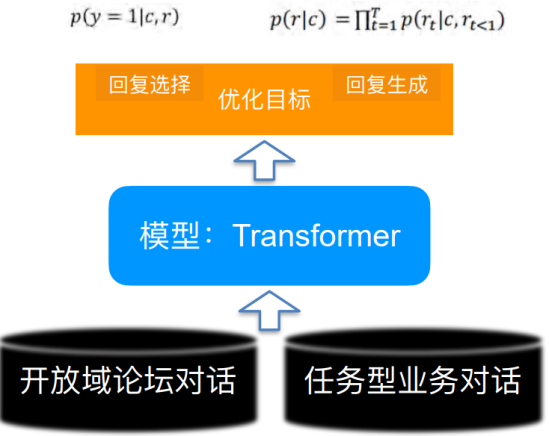
comparison plain text, What are the characteristics of dialogue ?

Backgrounds
• Task-oriented dialog (TOD) systems help accomplish certain tasks
This study is mainly based on Task-based dialogue , Compared with ordinary chat, dialogue needs to complete specific tasks .

As shown in the figure above , It includes dialogue understanding 、 There are three kinds of tasks in dialog strategy and dialog generation .
Pre training dialog model summary

Understanding oriented pre training dialogue model
• On the task of dialogue understanding , Pre training dialogue model (ConveRT and ToD-BERT)⽐ Pre training language ⾔ Model promotion 10%+;
• In representation learning , Pre training the dialogue model can also learn better representation , It has better clustering effect ;
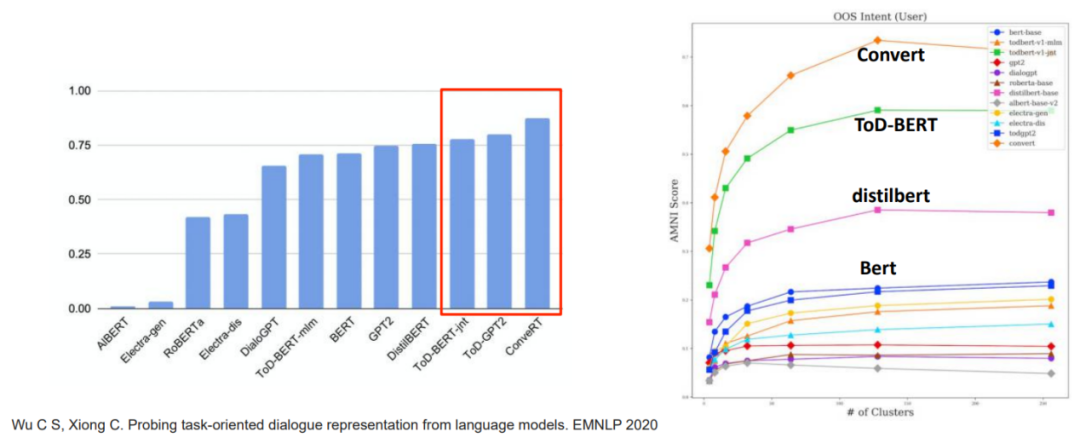
Pre training dialog model summary

Generation oriented pre training dialog model
• Facebook Quality of dialogue ⼈⼯ evaluating
• assessment ⽅ Law :A/B test, Human-to-human vs. human-to-bot, bot Include Facebook series Chatbot
• from 2018 Year to 2020 year ,facebook The series model is in A/B test Winning rate from 23% Upgrade to 49%
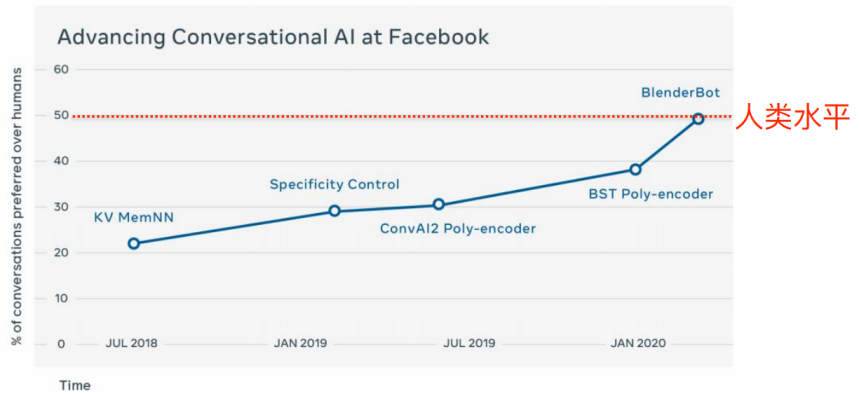
Pre training dialog model summary

The current problem is that there is little research on dialogue strategies , How to better model it ?
Pre-trained Objectives for PCM
• Observe 1: Current PCMs The general focus is on understanding and ⽣ Basic modeling

We can find out , Understand and ⽣ The model of Cheng is based on ⾃ Supervised learning , It does not rely on specific knowledge and is simple and low cost , Therefore, it can also be expanded rapidly .
How to model dialogue strategies ?
• Observe 2: Dialog act (DA) as explicit policy
Let's go on , The main thinking is how to depict a unified dialogue action system to model dialogue strategies and integrate them into the pre training dialogue model .
Semi supervised pre training dialogue model SPACE
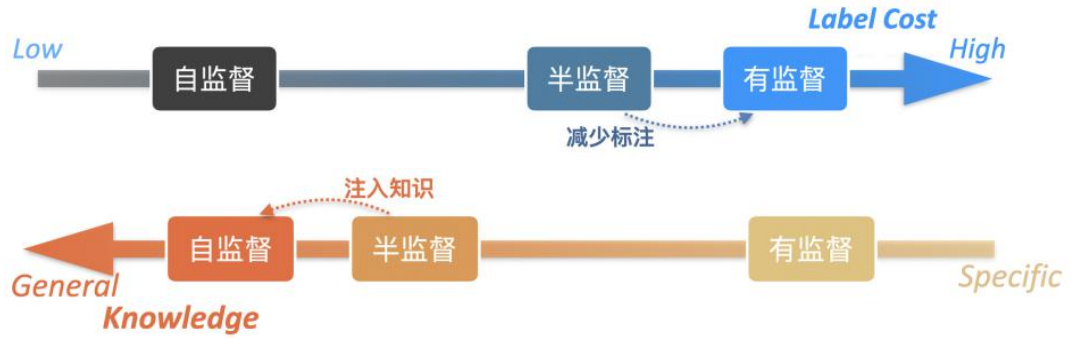
• motivation : How to melt ⼊ additional ⼈ Class annotation knowledge , Explicit interest ⽤⾼ Layer dialog semantic information ?
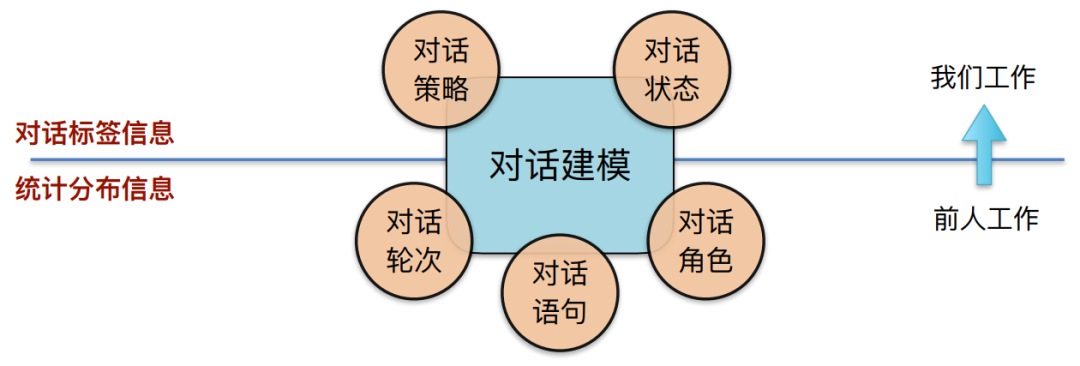
We didn't make good use of the dialog tag information before . Our work hopes to combine the two in the above figure , Low level statistical distribution information that can be used , High level dialog tag information can also be used .
• Propose benefits ⽤ Semi supervised pre training , Fully combine marked and ⽆ Mark dialog data
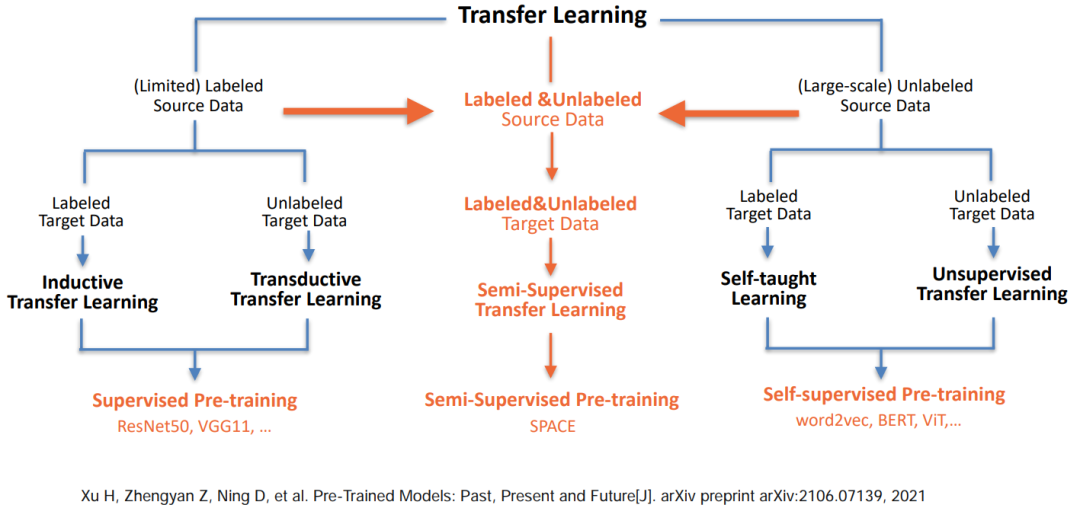
ad locum , Combined with the work of predecessors, we put forward semi supervised pre training , We hope to make better use of both standard and non-standard data , Get a better pre training dialogue model . Next , We need to look at the inconsistency of dialog action label systems in different data sets .
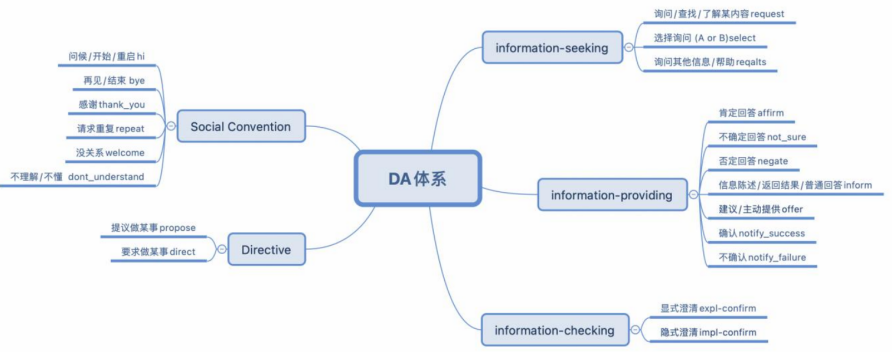
preparation : Define English Task-based dialogues DA system
• Method: Propose unified DA schema for TOD
• UniDA: common 5⼤ class ,20 A label , Comprehensive consideration often ⻅ Dialogue action ( Don't think about language for the time being ⾳ class )
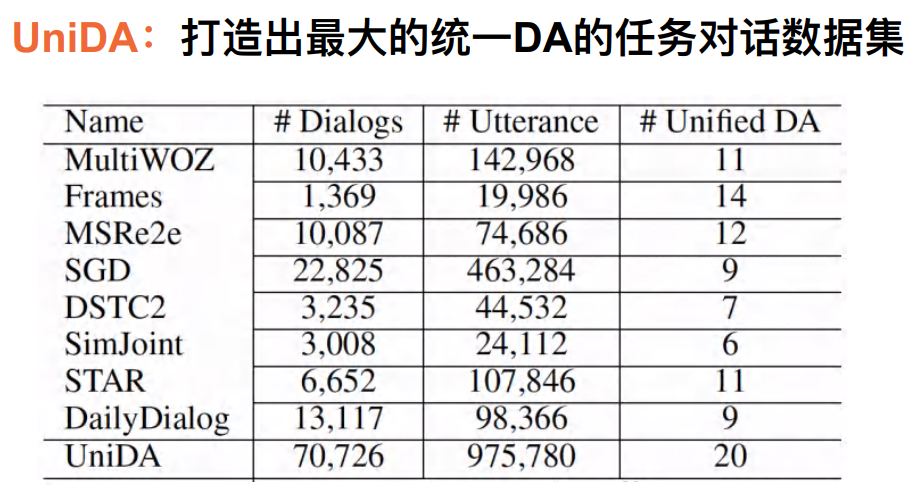
preparation : Build a pre training dialog data set
• ⽬ mark : structure ⾯ To task-based dialogue system ⼀DA System data
• difficulty : The system is complex 、 The amount of data is limited
At present, we have summarized 8 Data sets , We hope to create a label system with unified dialog action .
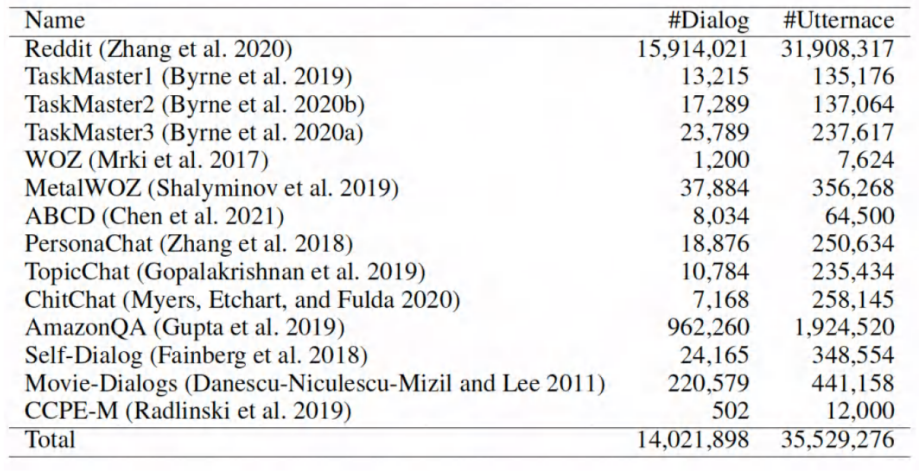
preparation : Build a pre training dialog data set
• ⽬ mark :⼤ scale ⽆ Mark the dialogue corpus UnDial
Use dialogue strategy knowledge — Definition DA Prediction task
• Explicitly modeling dialog strategies : Given the history of the conversation , Forecast ⼀ At the end of the gear train DA
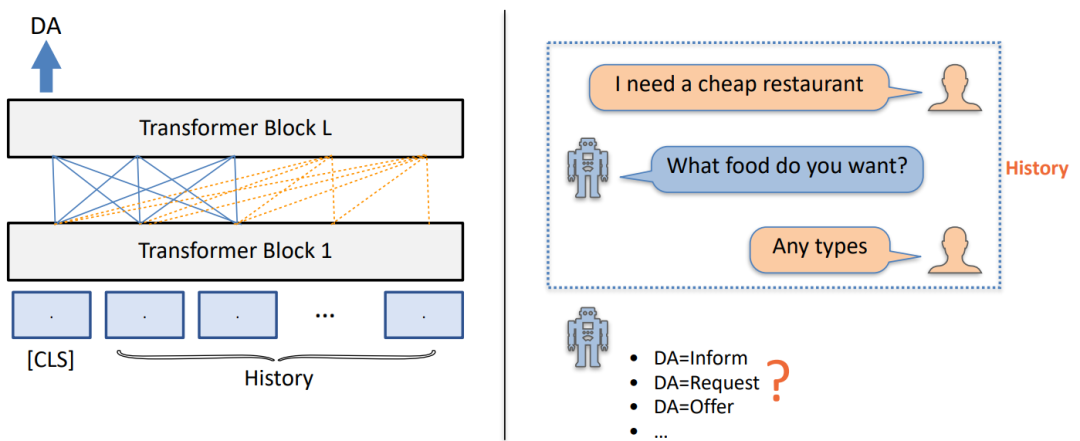
Through us, we can realize the sorted data , We can use the marked data to train the dialogue model .
Model input characterizes structure
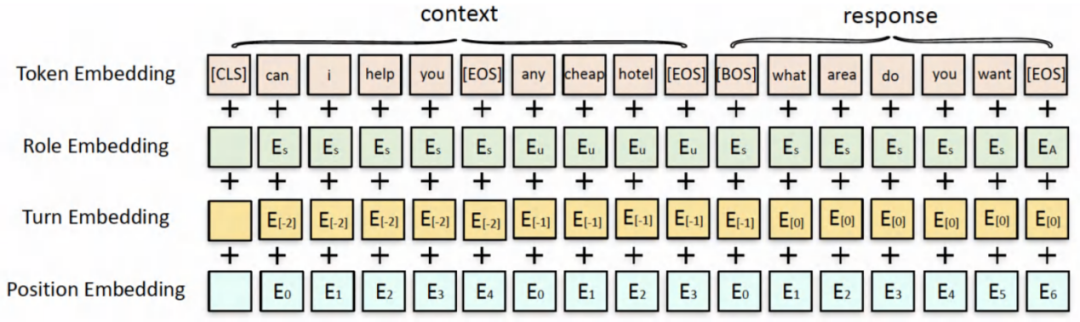
above , It's the data we sorted out , Well designed DA Supervised loss And the representation of the input of the training dialogue model . Next , We hope to use semi supervised pre training method to learn better models .
Explore semi supervised pre training methods
Explore semi supervised pre training
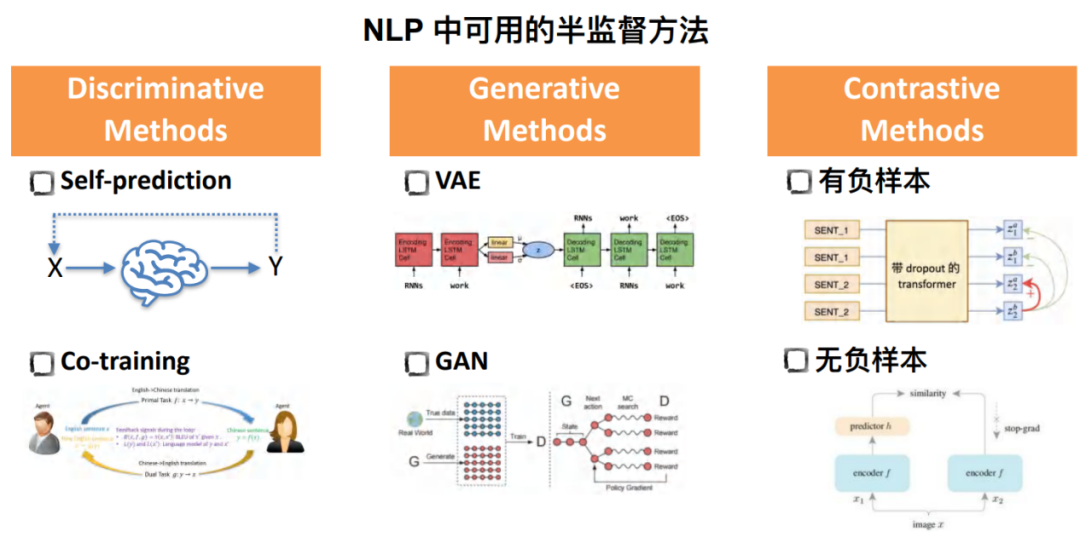
at present , Semi supervised methods can be divided into three categories :
• Discriminative Methods
The most representative of this method is the representation of self prediction , That is, after learning from a small batch of standard data, the model adopts self prediction representation on non-standard data , Pseudo label the unlabeled data to realize secondary training .
about Co-training Method , There are two models . Its input and output are the output and input of the other party respectively .
• Generative Methods
Before the general sampling VAE and GAN Methods , Such as VAE Modeling based on implicit variables is generated in the dialogue response.
• Contrastive Methods
The common classification of comparative learning is based on whether to construct negative samples , Its advantage is to realize self supervised learning to some extent .
Our semi supervised pre training exploration program 1: Method based on self prediction
• There will be supervision loss and ⾃ supervise loss Into the ⾏ Simple mix
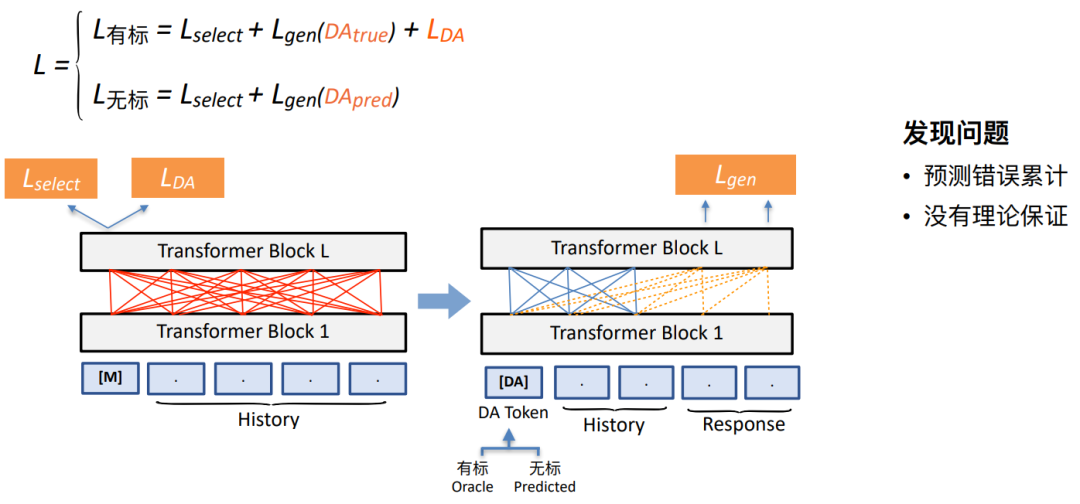
Whether it is marked or unmarked data , There's a loss Name it Lselect, Used to represent the role of dialogue understanding . As shown in the figure above , Our model is given at the understanding end on the left History Under the circumstances , Use these two loss To predict the next round DA The label of , Write it down as LDA. Because there is no DA label , We need the method of self prediction to put DA The tag is predicted and placed on DA token The location of , and History Together, they produce a dialogue response .
However , This may also lead to the problem of fitting . On this basis, we try to adopt the second scheme as follows .
Our semi supervised pre training exploration program 2: be based on VAE Of ⽅ Law
• be based on PLATO improvement , benefit ⽤ A small amount of supervised knowledge guides the implicit space close to the explicit DA Space • be based on PLATO improvement , benefit ⽤ A small amount of supervised knowledge guides the implicit space close to the explicit DA Space
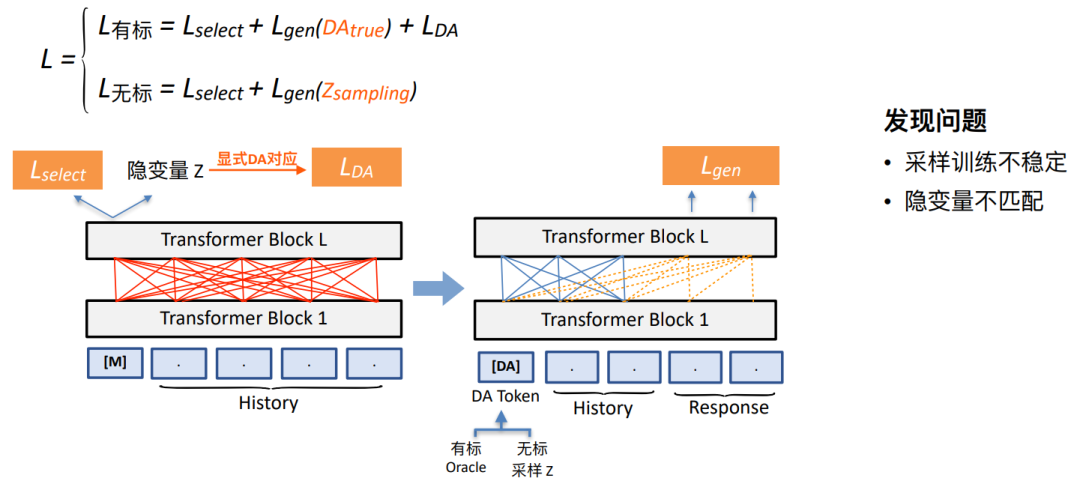
In this way, we can sample DA The label is sent to DA token Location , Realize dialogue prediction . We use Oracle label , We will sample the non-standard data .
However , We found that the performance of the current method is still very limited .
A semi supervised pre training dialogue model based on comparative learning
• Simplify the prediction process , eliminate DA Uncertainty error accumulation
• To forecast DA Distribution direct comparative learning
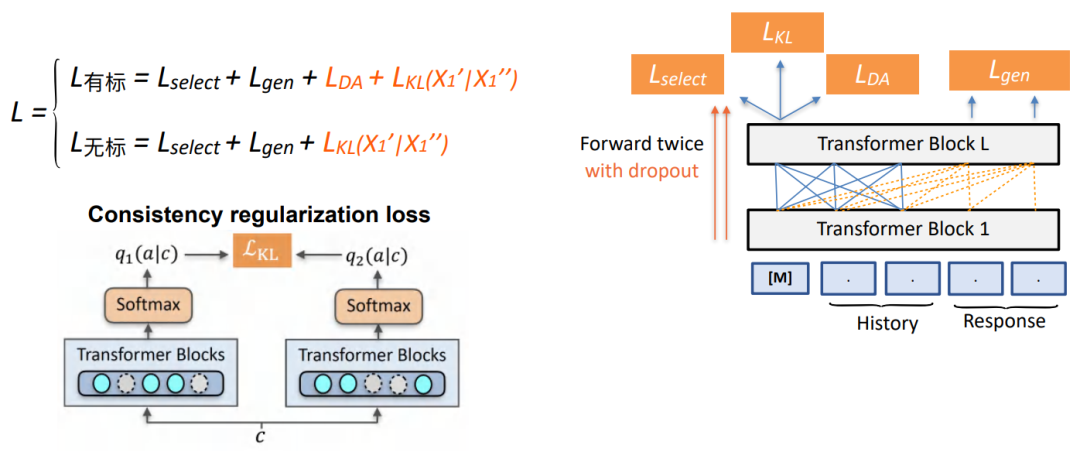
We use the method of comparative learning , It is mainly aimed at how to build better on the non-standard data loss Thus making DA Regularization constraint of prediction results . Given the same input , Pass twice drop out Get the predicted DA Different distributions in distribution , And make these two distributions close enough .
A semi supervised pre training dialogue model based on comparative learning
• ⼀ Schematic diagram of conformal regular semi supervised training
• Under low density assumption
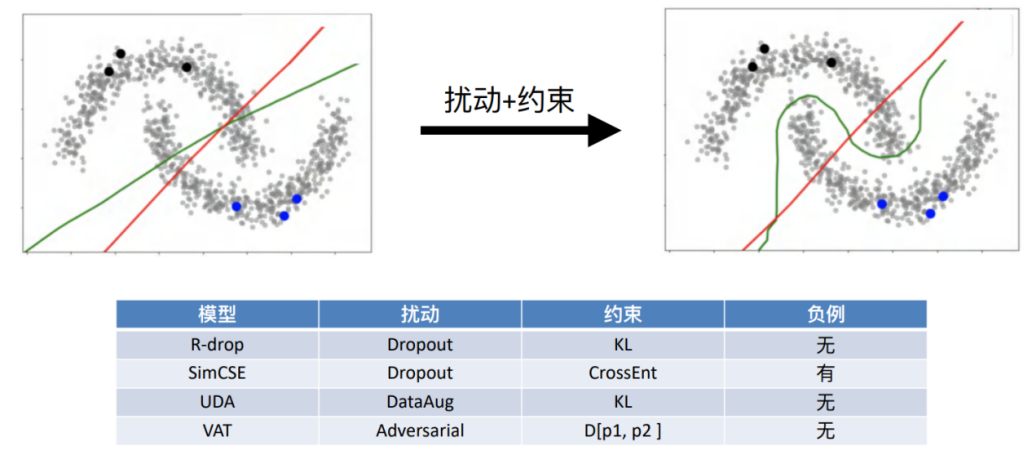
Suppose our semantic space satisfies separability , Through disturbance + The characteristics of this distribution can be obtained by means of constraints . Different algorithms , Such as R-drop、SimCSE And other methods are under the framework of consistent regularity , However, the method of disturbance is inconsistent with the goal of constraint .
Semi supervised pre training dialogue model SPACE
• Method: Learn policy from UniDA and UnDial via semi-supervised pre-training Put forward SPACE Series model 1.0 edition (GALAXY)
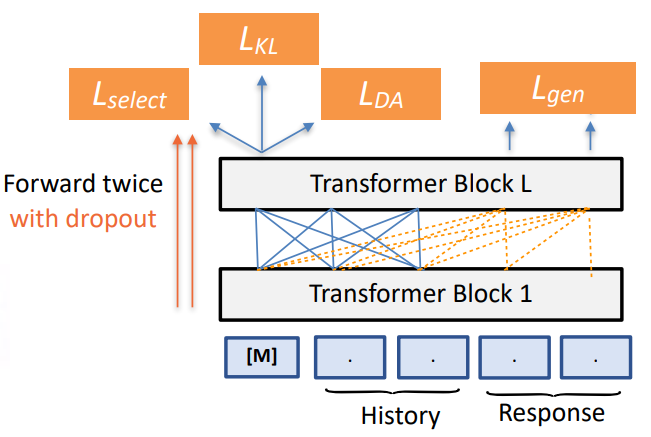
• Based on UniLM Architecture.
• Pre-training optimization:
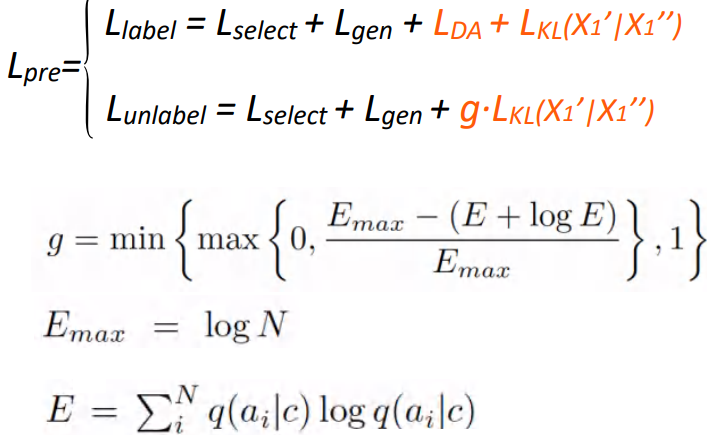
Whether it is marked or not, it will add a consistent regular loss, Add a gate mechanism to unsupervised data . By constraining the preset non-conforming distribution on the non-standard data , We can detect the entropy of the classification results of the model on the non-standard data . If entropy is greater than a certain threshold , We will restrict its score to be as small as possible , Avoid that there may be some dialog data on a large amount of unsupervised data that is not quite in line with our assumptions , In this way, some noise data can be eliminated .
The above is the optimization process of pre training , Downstream missions fine-tuning During the process, we will keep the generated dialog reply loss, At the same time, if the downstream task includes DA label , We'll add LDA To learn and make good use of the characteristics of data sets ; And if the downstream task does not include DA label , We won't add LDA, Only reply generated loss To achieve .
Experiment and analysis
Experiment preparation : Downstream tasks
• Task dialog dataset MultiWOZ
• EMNLP2018 best resource paper, 35+ team
• Rich fields : The restaurant 、 The hotel 、⽕⻋ etc. 7 Fields
• Data volume ⼤:10k sessions ⼈⼈ Crowdsourcing dialogue
• Diverse tasks :
• understand : Dialog State Tracking(DST)
• Strategy :Policy optimization • End to end : End-to-end modelling
• indicators :
• Inform: Provide Entity Whether it is right , Measure the effect of dialogue understanding
• Success: Whether the final task is completed , Measure the effectiveness of dialogue strategies
• BLUE: The relevance score of each round of reply , Measure dialogue ⽣ Result
• Combine score: (Inform+Success)/2+BLU
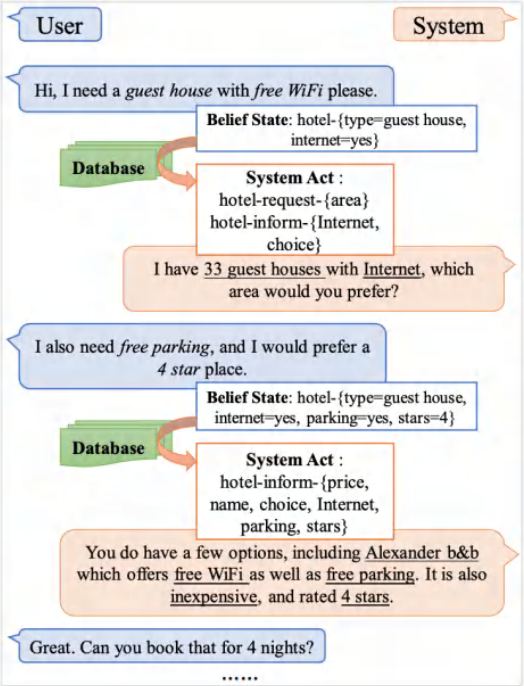
Experiment preparation : Downstream input and output
• reference UBAR Ideas

In the whole downstream task , After inputting user statements, we will use the model to predict an intermediate tag . Then we will put the prediction tag again as input after the user's sentence , Continuous iteration 、 Add 、 forecast ... We can use the completed dialog history including the middle tag as input again , So as to maintain the consistency of the dialogue .
Semi supervised pre training dialogue model SPACE
On the task of end-to-end dialog modeling , We are 4 Data sets were obtained SOTA Result .
• Overall Results: New SOTA on End-to-End Dialog Modeling

• Overall Results: New SOTA on End-to-End Dialog Modeling
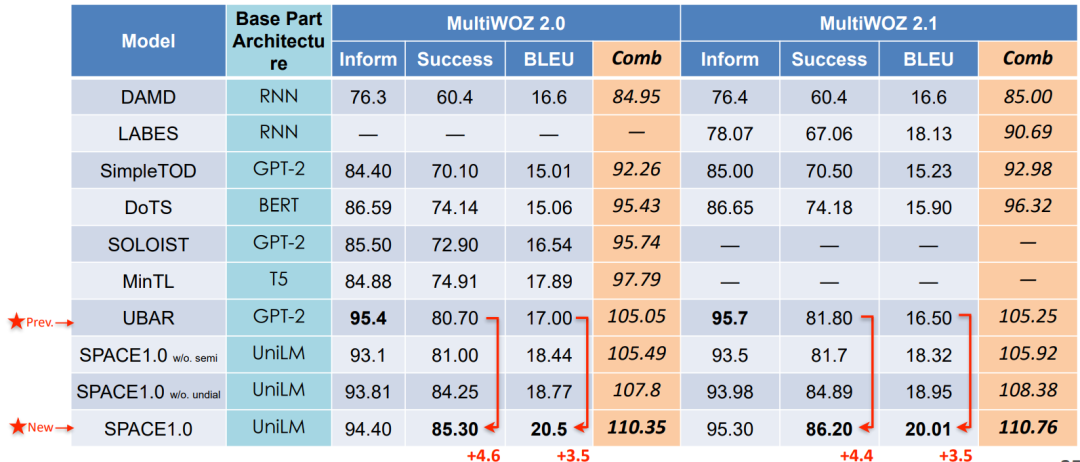
You can see from the above picture that , Our model is relative to the previous SOTA The improvement of the overall indicators of the model mainly comes from the generation of dialogue strategies Success and BLEU On .
It can be understood in this way , Because our model effectively models dialogue strategies , Therefore, in measuring the effectiveness of dialogue strategies Success Compared with the previous model, it has been significantly improved . And because the dialogue strategy is well chosen , So the subsequent dialogue generation is more reasonable . Our model also achieves the best effect in the overall mixing index .
• Low-Resource Results on MultiWOZ2.0
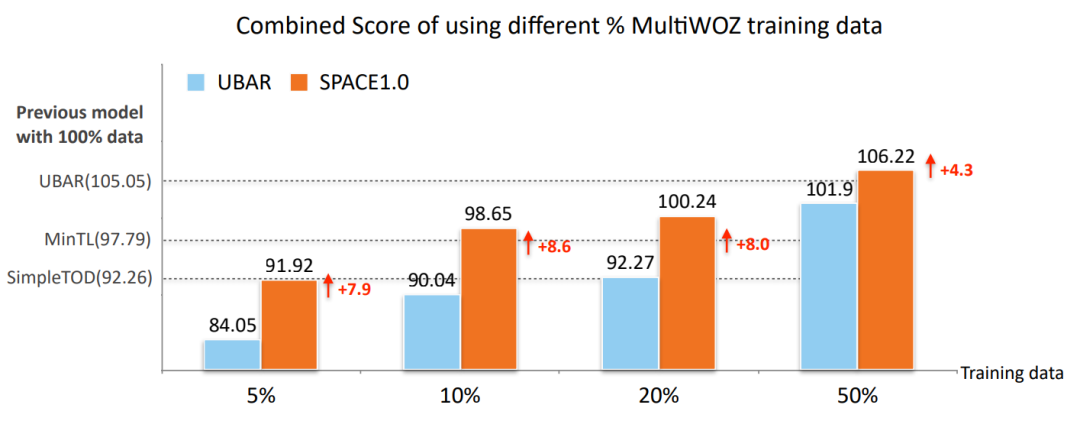
As can be seen from the picture above , Our model can get better dialog representation by pre training with less data , So as to adapt to the whole downstream task .
• Other Comparison
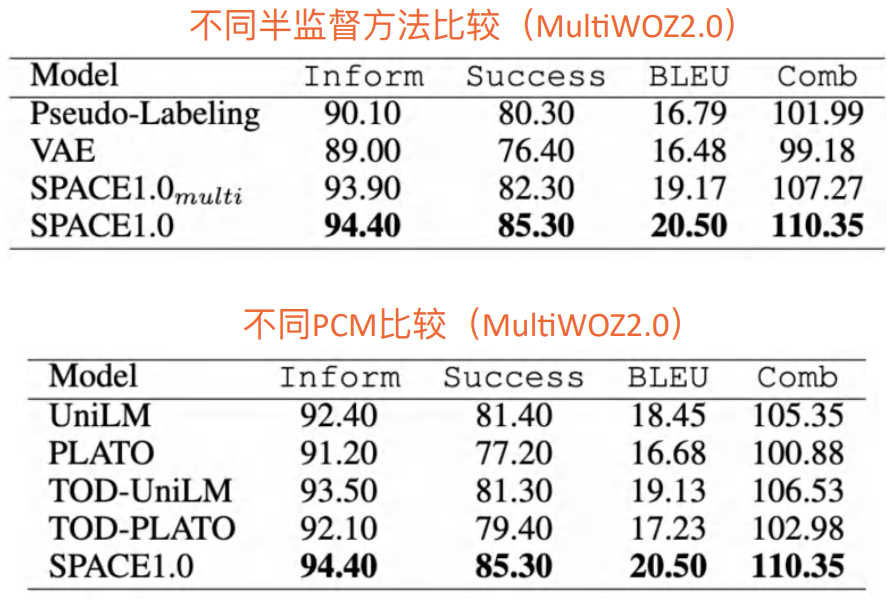
We found that , Our model can get the best effect no matter what kind of adaptation .
• Case Study

Our model can improve its ability to predict the next round during pre training , therefore SPACE The model can predict the best DA label . Because the dialogue strategy is selected correctly , therefore SPACE The model can achieve a good effect in predicting the generation of dialogue .
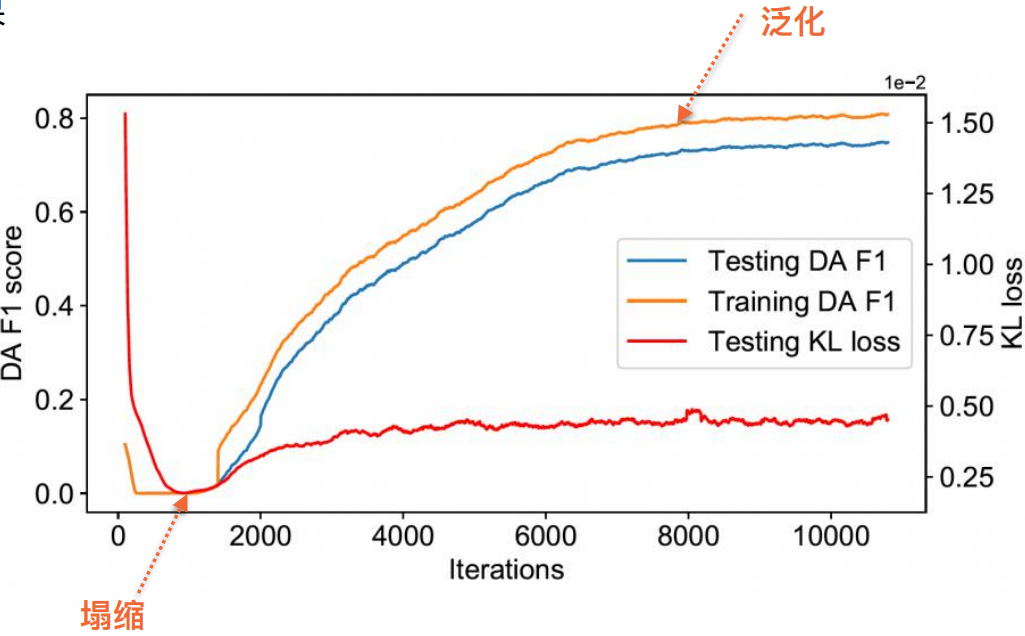
Why is the consistent regularization method effective ?

On the marked data , We have 2 individual loss, One is DA loss, One is KL Consistent regularity of loss; On unmarked data , Also have 1 individual KL Consistent regularity of loss. Due to the existence of KL loss Can achieve a certain degree of regularization loss, It is likely that the whole DA The distribution will be over fitted to the standard data .
However , If you only use non-standard data KL loss, It is likely to learn a frequent solution , That is, no matter what data will learn the same distribution —— Predict the same kind . This will lead to non-standard data KL loss Directly reduce to 0, So our whole training loss It includes both marked and unmarked , Marked data LDA loss It can prevent collapse .
Summary and prospect
• For the first time, we inject the dialogue strategy into the pre training dialogue model through a semi supervised way , And get on multiple data sets SOTA result .
• We also propose to use semi supervision as a means of pre training , So as to train a better pre training model . In fact, our method can not only use dialogue strategy , You can also use a lot of dialogue 、NLP Related fields
carry
Wake up
Thesis title :
SPACE 1.0 - A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Thesis link :
https://arxiv.org/abs/2111.14592
Click on “ Read the original ”, You can watch this playback
Arrangement : Lin be
author : Dai yinpei
Activity recommendation

Remember to pay attention to us ! There is new knowledge every day !
About AI TIME
AI TIME From 2019 year , It aims to carry forward the spirit of scientific speculation , Invite people from all walks of life to the theory of artificial intelligence 、 Explore the essence of algorithm and scenario application , Strengthen the collision of ideas , Link the world AI scholars 、 Industry experts and enthusiasts , I hope in the form of debate , Explore the contradiction between artificial intelligence and human future , Explore the future of artificial intelligence .
so far ,AI TIME Has invited 700 Many speakers at home and abroad , Held more than 300 An event , super 260 10000 people watch .

I know you.
Looking at
Oh
~

Click on Read the original View playback !
边栏推荐
- 中间表是如何被消灭的?
- HiEngine:可媲美本地的云原生内存数据库引擎
- Google Earth engine (GEE) -- a brief introduction to kernel kernel functions and gray level co-occurrence matrix
- 【729. 我的日程安排表 I】
- 怎样在电脑上设置路由器的WiFi密码
- npm安装
- 国内首家 EMQ 加入亚马逊云科技「初创加速-全球合作伙伴网络计划」
- 树莓派4b安装Pytorch1.11
- Scratch colorful candied haws Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
- 网站页面禁止复制内容 JS代码
猜你喜欢
![[61dctf]fm](/img/22/3e4e3f1679a27d8b905684bb709905.png)
[61dctf]fm
Win11提示无法安全下载软件怎么办?Win11无法安全下载软件
【剑指 Offer】63. 股票的最大利润
Fleet tutorial 09 basic introduction to navigationrail (tutorial includes source code)
Oneforall installation and use
How to set the WiFi password of the router on the computer
Deep learning plus

【 brosser le titre 】 chemise culturelle de l'usine d'oies

【刷题篇】有效的数独
[brush questions] effective Sudoku
随机推荐
[729. My Schedule i]
composer安装报错:No composer.lock file present.
普洛斯数据中心发布DC Brain系统,科技赋能智慧化运营管理
HiEngine:可媲美本地的云原生内存数据库引擎
How to set the WiFi password of the router on the computer
怎样在电脑上设置路由器的WiFi密码
Android 隐私沙盒开发者预览版 3: 隐私安全和个性化体验全都要
JSON转MAP前后数据校验 -- 自定义UDF
如何将mysql卸载干净
[deep learning] how does deep learning affect operations research?
【剑指 Offer】66. 构建乘积数组
Summary of methods for finding intersection of ordered linked list sets
深潜Kotlin协程(二十一):Flow 生命周期函数
tf. sequence_ Mask function explanation case
Do sqlserver have any requirements for database performance when doing CDC
How to uninstall MySQL cleanly
[team PK competition] the task of this week has been opened | question answering challenge to consolidate the knowledge of commodity details
The difference between searching forward index and inverted index
Pspnet | semantic segmentation and scene analysis
[61dctf]fm