当前位置:网站首页>中间表是如何被消灭的?
中间表是如何被消灭的?
2022-07-05 15:47:00 【CSDN云计算】

作者 | 不吃西红柿
来源 | CSDN博客

中间表的产生
中间表是数据库中专门存放中间计算结果的数据表,往往是为了前端查询统计更快或更方便而在数据库中建立的汇总表,由于是由原始数据加工而成的中间结果,因此被称为中间表。
在某些大型机构中,多年积累出来中间表的数量居然高达数万张,给系统和使用造成了很多麻烦。
中间表会占用大量的数据库存储空间导致数据库容量不足,面临扩容压力。数据库的空间往往很贵,扩容成本非常高,并且数据库扩容还常常存在限制,耗费高昂成本来存储中间表并不是个好办法。同时,中间表过多还会引发数据库性能问题,中间表并不是孤立存在,从原始数据到中间表要经过一系列运算这就要耗费数据库计算资源,而且加工中间表的频率有时很高,数据库的大量资源消耗在中间表生成上,严重时会导致数据库查询慢、交易迟钝等问题。
为什么会产生这么多中间表呢?主要原因有以下几条。
1、一步算不出来
数据库中的原始数据表要经过复杂计算,才能在报表上展现出来。一个 SQL 很难实现这样的复杂计算。要连续多个 SQL 实现,前面的生成中间表给后边的 SQL 使用。
2、实时计算等待时间过长
因为数据量大或者计算复杂,报表用户等待时间太长。所以要每天晚上跑批量任务,把数据计算好之后存入中间表。报表用户基于中间表查询就会快很多。
3、多样性数据源参加计算
来自于文件、NOSQL、Web service 等的外部数据,本身没有多少计算能力,需要利用数据库的计算能力,特别是要与数据库内数据进行混合计算时,传统办法只能导入数据库形成中间表。
4、中间表难以删除
由于数据库通常采用缺乏层次的扁平结构,中间表一旦创建就可能被多个查询使用,删除就可能影响其他查询。甚至一个中间表被哪些程序使用都很难搞清楚,更不用提删除了,不是不想删,而是不敢删。日积月累,上万张中间表也就不奇怪了。
那么,为什么要把中间数据存到数据库中形成中间表呢?仔细观察中间表产生的直接原因可以看出来,存到数据库主要是为了继续借助数据库的计算能力。中间数据在使用时还会做进一步计算,有时计算还比较复杂,而目前只有数据库(SQL)具备较为便利的计算能力。文件等数据存储形式虽然也有优点(如IO性能高、可压缩、易并行),但文件没有计算能力,如果基于文件还要在应用中硬编码实施计算,远没有 SQL 方便。为了进一步利用数据库的计算能力是中间表产生的根本原因。
中间数据从某种意义上讲是有必要的,但仅仅为了获得进一步的计算能力就要占用大量数据库资源,显然不是个理想的解决方案。如果让文件也拥有与数据库等同的能力,那将中间表存储在数据库外的文件系统中就可以解决数据库中间表的各种问题,数据库也可以因此解脱(减负)。
开源SPL可以实现这个目标。
SPL是一款开源的结构化数据计算引擎,可以直接基于文件进行数据处理,使得文件也拥有计算能力。SPL不依赖数据库,提供了专业的结构化数据对象及其上的丰富运算类库,拥有完备的计算能力,同时支持过程控制,实现复杂计算也很方便,可以完全替代数据库完成中间表生成和后续的数据处理任务。
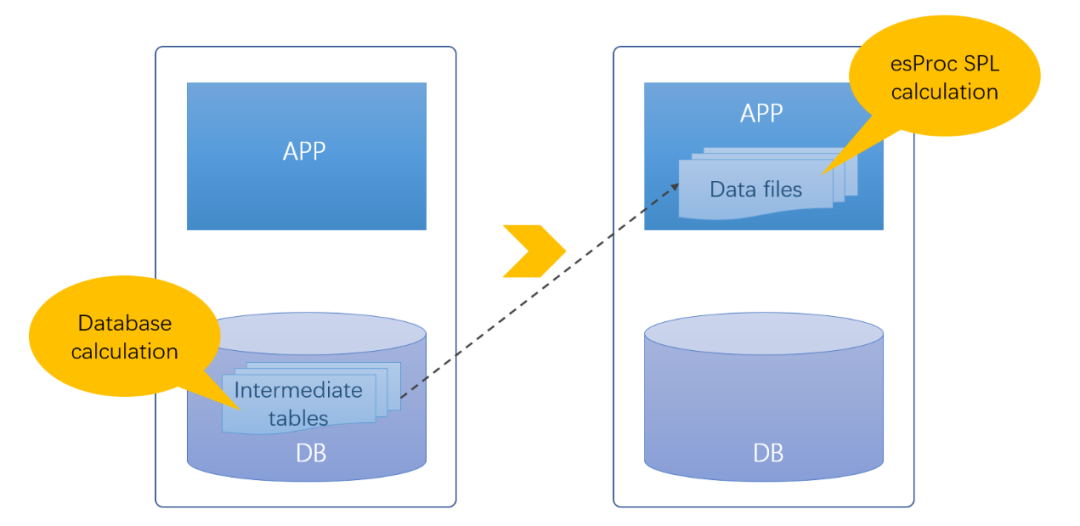

文件计算
SPL可以基于Csv、Excel等文件进行计算,也可以计算JSON/XML等多层数据,读取和使用很方便。这样,就可以中间表数据存储成这类文件,再使用SPL进行加工处理。下面是一些常规运算:
| A | B | |
1 | =T("/data/scores.txt") | |
| 2 | =A1.select(CLASS==10) | 过滤 |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | 分组汇总 |
| 4 | =A1.sort(CLASS:-1) | 排序 |
| 5 | =T("/data/students.txt").keys(SID) | |
| 6 | =A1.join(STUID,A5,SNAME) | 关联 |
| 7 | =A6.derive(English+ Chinese+ Math:TOTLE) | 追加列 |
除了原生SPL语法,SPL还提供了相当SQL92标准的SQL支持,对于熟悉使用SQL的人员可以直接使用SQL查询文件。
$select * from d:/Orders.csv where Client in ('TAS','KBRO','PNS')复杂些的with都支持:
$select t.Client, t.s, ct.Name, ct.address from
(select Client ,sum(amount) s from d:/Orders.csv group by Client) t
left join ClientTable ct on t.Client=ct.ClientSPL在处理JSON/XML等多层数据(文件)方面也很有优势,如:根据员工订单信息(json)完成计算。
| A | ||
| 1 | =json(file("/data/EO.json").read()) | |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 && Amount<=3000 && [email protected](Client,"*s*")) | 条件过滤 |
| 4 | =A2.groups(year(OrderDate);sum(Amount)) | 分组汇总 |
| 5 | =A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) | 关联计算 |
可以看到,相对其他JSON库(如JsonPath)SPL的实现更简洁。
同样,使用SQL也可以查询JSON数据:
$select * from {json(file("/data/EO.json").read())}
where Amount>=100 and Client like 'bro' or OrderDate is nullSPL的敏捷语法和过程计算还非常适合完成复杂计算,比如基于股票记录(txt)计算某只股票最长连涨天数 可以这样写:
| A | |
| 1 | =T("/data/stock.txt") |
| 2 | [email protected](price<price[-1]).max(~.len())-1 |
再比如,根据用户登录记录(csv)列出每个用户最近一次登录间隔:
| A | ||
| 1 | =T(“/data/ulogin.csv”) | |
| 2 | =A1.groups(uid;top(2,-logtime)) | 最后2个登录记录 |
| 3 | =A2.new(uid,#2(1).logtime-#2(2).logtime:interval) | 计算间隔 |
这类计算即使基于数据库使用SQL也很难写,SPL实现却很方便。
有了SPL的库外计算支持,原本数据库中间表带来的各种问题就能得到有效解决。文件存储不再占用数据库存储空间,数据库扩容压力降低,数据库更方便管理;库外计算不再占用数据库计算资源,数据库减负可以更好服务其他业务。

高性能文件格式
虽然文本是很常见的数据存储形式,具备通用性易读性等优点,但是,文本的性能却非常差!基于文本做计算很难获得高性能。
文本字符不能直接运算,需要转换成整数、实数、日期、字符串等内存数据类型才可以进一步处理,而文本的解析是个非常复杂的任务,CPU 耗时很严重。一般来讲,外存数据访问的主要时间是在硬盘本身的读取上,而文本文件的性能瓶颈却经常发生在 CPU 环节。因为解析的复杂性,CPU 耗时很可能超过硬盘耗时(特别是采用高性能固态硬盘时)。需要高性能处理较大数据量时通常不会使用文本。
SPL提供了两种高性能数据存储格式,集文件和组表。集文件是SPL提供的二进制数据格式,采用了压缩技术(占用空间更小读取更快),存储了数据类型(无需解析数据类型读取更快),还支持可追加数据的倍增分段机制,利用分段策略很容易实现并行计算,进一步提升计算性能。
组表是SPL提供列存、索引机制的文件存储格式,在参与计算的列数(字段)较少时列存会有巨大优势。组表除了支持列存,实现了minmax索引外,还支持倍增分段机制,这样不仅能享受到列存的优势,也更容易并行提升计算性能。
SPL存储的使用很方便,与文本使用基本一致,比如读取集文件并计算:
| A | B | |
| 1 | =T("/data/scores.btx") | 读入集文件 |
| 2 | =A1.select(CLASS==10) | 过滤 |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | 分组汇总 |
如果数据量较大,还支持游标分批读取以及多CPU并行计算:
=file("/data/scores.btx")[email protected]()在使用文件作为数据存储方式时,无论原始数据是何种格式,最后都至少要转存成二进制(如集文件)格式,这样无论在空间占用还是计算性能上都会更有优势。

易管理性
中间表转移到库外通过文件存储以后,除了可以帮数据库减负,库外中间表自身还具备极强的易管理性。文件可以通过系统的树状目录进行存储,使用和管理都很方便。将不同系统、不同模块使用的中间表存放在不同的目录中非常清晰,不会出现交叉引用的情况,这样就不会出现以往数据库中间表使用混乱造成各个系统或各个模块之前的紧耦合问题。如果对应功能模块下线也可以放心删除对应的中间表数据不用担心对其他程序产生影响。

多数据源支持
除了文件数据源,SPL还支持其他几十种数据源,不仅可以连接取数,还可以完成混合计算。

中间表改用文件存储后要与数据库中的实时数据进行全量查询就涉及跨源计算,使用SPL完成这类T+0查询就很方便。
| A | ||
| 1 | =cold=file(“/data/orders.ctx”).open().cursor(area,customer,amount) | /冷数据从文件系统(SPL高性能存储)中取,昨天及以前的数据 |
| 2 | =hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) | |
| 3 | =[cold,hot].conjx() | /热数据从生产库中取,今天的数据 |
| 4 | =A3.groups(area,customer;sum(amout):amout) | /混合计算实现T+0 |

集成性
SPL提供了标准JDBC和ODBC接口供应用调用。特别地,对于Java应用可以将SPL作为嵌入引擎集成到应用中,使得应用本身就具备中间(数据)表的处理能力。
JDBC调用SPL 代码示例:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…SPL是解释执行的,天然支持热切换。基于SPL的数据计算逻辑编写、修改和运维都不需要重启,实时生效,开发运维也更加便捷。
有了具备库外计算能力的SPL,将中间表转移到文件系统中,就可以帮助数据库消灭数以万计的中间表,为数据库减负的同时,获得更高的灵活性、更快的性能以及更强的扩展能力。

往期推荐

点分享

点收藏

点点赞

点在看
边栏推荐
- ES6深入—ES6 Generator 函数
- 【学术相关】多位博士毕业去了三四流高校,目前惨不忍睹……
- Apple 已弃用 NavigationView,使用 NavigationStack 和 NavigationSplitView 实现 SwiftUI 导航
- Exception com alibaba. fastjson. JSONException: not match : - =
- Some cognitive thinking
- 国泰君安网上开户安全吗
- The memory of a Zhang
- Why should we learn mathematical modeling?
- Intel 13th generation Raptor Lake processor information exposure: more cores, larger cache
- Record the pits encountered in the raspberry pie construction environment...
猜你喜欢

项目中批量update

数据湖(十四):Spark与Iceberg整合查询操作
RLock锁的使用

Arduino controls a tiny hexapod 3D printing robot
Clock switching with multiple relationship

Reduce the cost by 40%! Container practice of redis multi tenant cluster
![21.[STM32]I2C协议弄不懂,深挖时序图带你编写底层驱动](/img/f4/2c935dd9933f5cd4324c29c41ab221.png)
21.[STM32]I2C协议弄不懂,深挖时序图带你编写底层驱动

Li Kou today's question -729 My schedule I

Why should we learn mathematical modeling?
Today's sleep quality record 79 points
随机推荐
10分钟帮你搞定Zabbix监控平台告警推送到钉钉群
记一次'非常诡异'的云安全组规则问题排查过程
You should have your own persistence
Clock switching with multiple relationship
EDI许可证和ICP经营性证有什么区别
《MongoDB入门教程》第04篇 MongoDB客户端
Dataarts studio data architecture - Introduction to data standards
超分辨率技术在实时音视频领域的研究与实践
21. [STM32] I don't understand the I2C protocol. Dig deep into the sequence diagram to help you write the underlying driver
Mongodb getting started Tutorial Part 04 mongodb client
Enterprise backup software Veritas NetBackup (NBU) 8.1.1 installation and deployment of server
不敢买的思考
list集合根据对象某属性求和,最大值等
视觉体验全面升级,豪威集团与英特尔Evo 3.0共同加速PC产业变革
【深度学习】深度学习如何影响运筹学?
定义严苛标准,英特尔Evo 3.0正在加速PC产业升级
10 minutes to help you get ZABBIX monitoring platform alarm pushed to nail group
具有倍数关系的时钟切换
Six common transaction solutions, you sing, I come on stage (no best, only better)
Cheer yourself up