当前位置:网站首页>Pspnet | semantic segmentation and scene analysis
Pspnet | semantic segmentation and scene analysis
2022-07-05 16:25:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery This time , By the Chinese University of Hong Kong (CUHK) And Technology Shang Dynasty (SenseTime) Proposed pyramid scene parsing network (Pyramid Scene Parsing Network, PSPNet) Has been reviewed .
The goal of semantic segmentation is only to know the category label of each pixel of the known object .
Scene parsing is based on semantic segmentation , Its goal is to know the category labels of all pixels in the image .

Scene analysis
By using pyramid pooling modules (Pyramid Pooling Module), After integrating the context based on different regions ,PSPNet In effect, it exceeds FCN、DeepLab and DilatedNet The best way to wait .PSPNet Final :
get 2016 year ImageNet Champion of scene analysis challenge
stay PASCAL VOC 2012 and Cityscapes Get the best results at that time on the data set
The work has been published in 2017 year CVPR, More than 600 Time .(SH Tsang @ Medium )
Outline of this article
1. The need for global information
2. Pyramid pool module
3. Some details
4. Model simplification research
5. Comparison with the best method nowadays
1. The need for global information
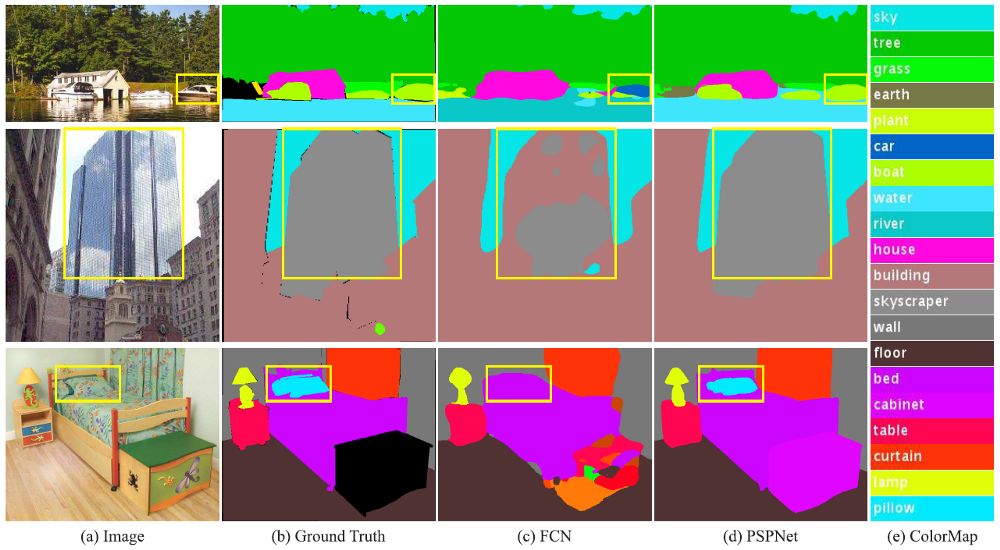
(c) Original without context integration FCN,(d) Context integrated PSPNet
Relationship mismatch :FCN Predict the ship in the yellow box as “ automobile ”. But according to common sense , Cars rarely appear on the river .
Category confusion :FCN Predict a part of the objects in the box as “ skyscraper ”, Part of the prediction is “ building ”. These results should be excluded , In this way, the object as a whole will be divided into “ skyscraper ” or “ building ” In one category , It will not fall into two categories .
Categories of small objects : The appearance of pillows and sheets is similar . Ignoring the global scene category may cause parsing “ Pillow ” A kind of failure .
therefore , We need some global features of the image .
2. Pyramid pool module
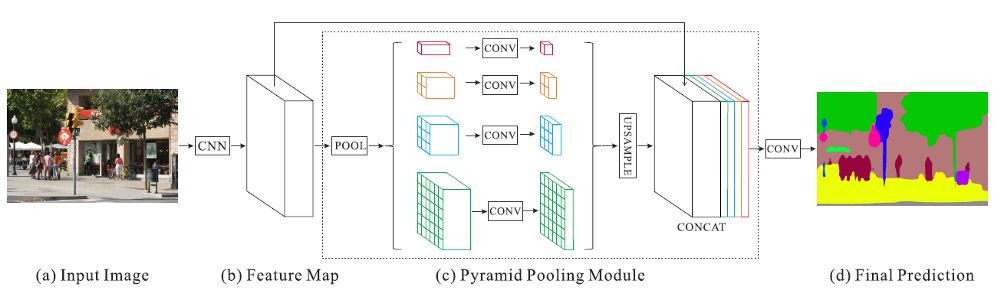
Pyramid pool module after feature extraction ( Color is very important in this picture !)
(a) and (b)
(a) Input image for one of our .(b) Adopt extended network strategy (DeepLab / DilatedNet) The extracted features . stay DeepLab Then add extended convolution . features map The size of is the size of the image input here 1/8.
(C).1
stay (c) It's about , For each feature map Perform sub area average pooling .
Red : This is in every feature map The coarsest level of the global average pool on , Used to generate a single bin Output .
Orange : This is the second floor , Will feature map Divided into 2×2 Subarea , Then average pool each sub area .
Blue : This is the third level , Will feature map Divided into 3×3 Subarea , Then average pool each sub area .
green : This will feature map Divided into 6×6 The smallest level of the sub region , Then pool each sub region .
(c).2. 1×1 Convolution is used for dimensionality reduction
Then for each feature obtained map Conduct 1×1 Convolution , If the pyramid's hierarchical size is N, Reduce the context representation to the original 1/N( black ).
In this case ,N=4, Because there are 4 A level ( Red 、 Orange 、 Blue and green ).
If you enter a feature map The quantity of is 2048, Then output features map by (1/4)×2048 = 512, That is, output characteristics map The quantity of is 512.
(c).3. Bilinear interpolation is used for up sampling
Bilinear interpolation is used for each low dimensional feature map Sample up , Make it with original characteristics map The same size ( black ).
(c).4. Connection context aggregation features
All upsampling features at different levels map All with original features map( black ) come together . These feature maps are fused into a global a priori . This is the pyramid pool module (c) Termination of .
(d)
Last , The final predicted segmentation map is generated through the convolution layer (d).
The concept of sub area average pool is actually similar to SPPNet The spatial pyramid pooling in is very similar . First use 1×1 Convolution and then concatenation , And Xception or MobileNetV1 The depth convolution in the depth separable convolution used is very similar , Except that only bilinear interpolation is used to make all features map They are the same size .
3. Some training details
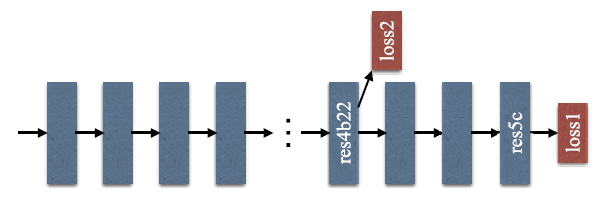
Auxiliary loss items in the middle
· Auxiliary loss items are used in the training process . Auxiliary loss items include 0.4 The weight of , To balance the final loss and auxiliary loss . At testing time , Will give up the auxiliary loss . This is a deep supervision training strategy for deep network training . The idea is similar to GoogLeNet / Inception-v1 Auxiliary classifier in (https://medium.com/coinmonks/paper-review-of-googlenet-inception-v1-winner-of-ilsvlc-2014-image-classification-c2b3565a64e7).
· “ multivariate ” Learning has replaced “ unit ” Study .
4. Model reduction test
ADE2K The dataset is ImageNet Scene analysis challenge 2016 Data set in . It is a more challenging data set , Contains up to 150 Class and 1,038 Image level labels . Yes 20K/2K/3K Images are used for training / verification / test .
Validation sets are used for model simplification testing .
4.1. Maximum pooling vs The average pooling , And dimensionality reduction (DR)
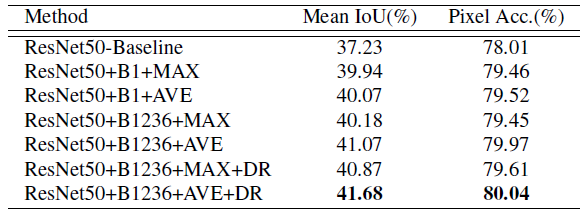
Different algorithms in ADE2K Verify the results on the set
ResNet50-Baseline: be based on ResNet50 Expansion FCN.
‘B1’ and ‘B1236’: bin The sizes are {1×1} and {1×1,2×2,3×3,6×6} Pooling characteristics of map.
‘MAX’ and ‘AVE’: Maximum pool operation and average pool operation
‘DR’: Dimension reduction .
The average pool always has better results . Using dimension reduction is better than not using dimension reduction .
4.2 Ancillary loss
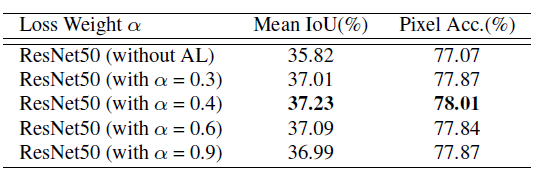
The different weights of auxiliary loss items are ADE2K Verify the results on the set
α= 0.4 Get the best performance . therefore , Use weights α= 0.4.
4.3. Different network layers and different scales (MS) Test of
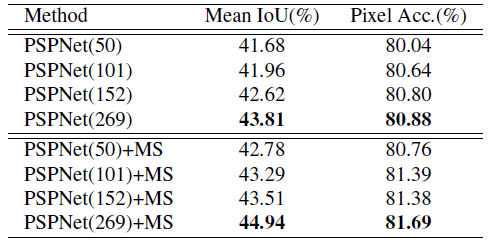
Networks of different layers and scales are ADE2K Verify the results on the set
As we know , Deeper models have better results . Multiscale testing helps to improve test results .
4.4. Data to enhance (DA) And the comparison with other algorithms
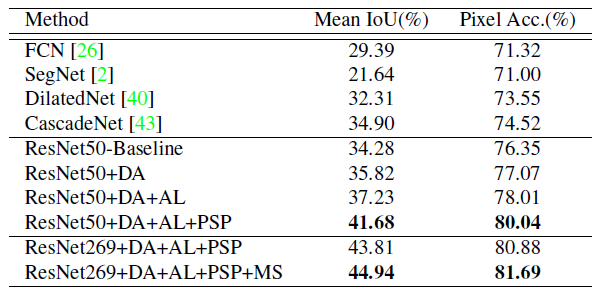
stay ADE2K Comparison results with the latest methods on the validation set ( Except for the last line , All methods are single scale ).
ResNet269+DA+AL+PSP: For a single scale test , If all the skills are combined , This algorithm has great advantages over the most advanced methods .
ResNet269+DA+AL+PSP+MS: At the same time, multi-scale tests were carried out , Good results have been achieved .
Here are some examples :
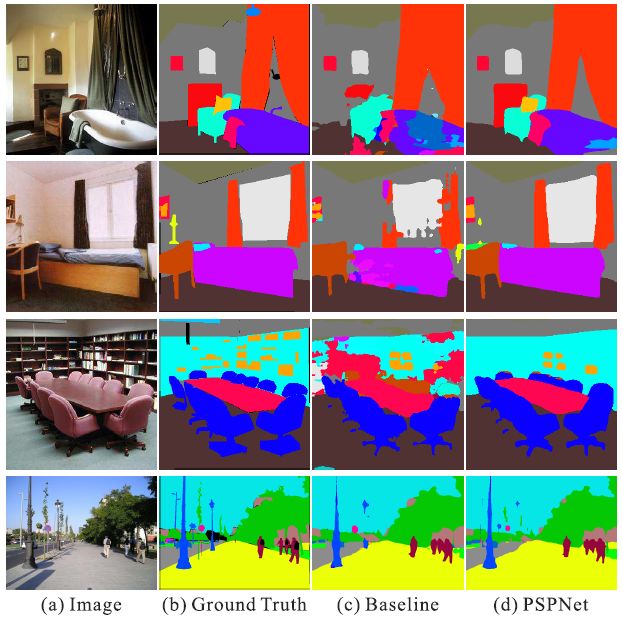
ADE2K Examples in
5. Comparison with the most advanced methods
5.1. ADE2K - ImageNet Scene analysis challenge 2016
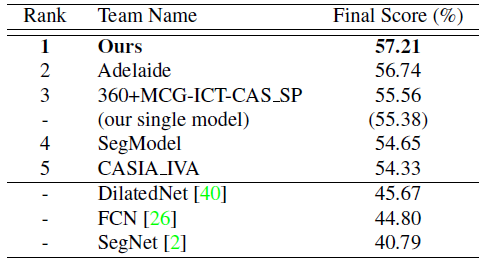
ADE2K Test set results
PSPNet Won 2016 year ImageNet Champion of scene analysis challenge .
5.2. PASCAL VOC 2012
In the case of using data enhancement , Yes 10582/1449/1456 Images for training / verification / test .
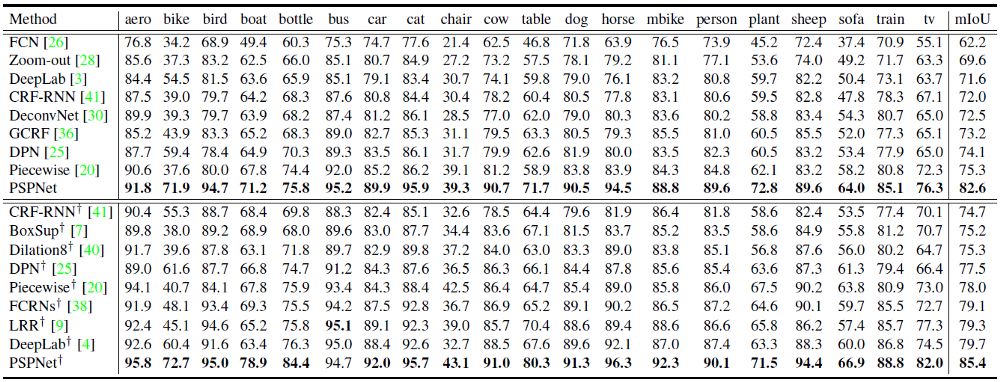
PASCAL VOC 2012 Test set results
“+” Indicates that the model passes MS COCO Data pre training .
Again ,PSPNet Superior to all the most advanced methods , Such as FCN、DeconvNet、DeepLab and Dilation8.
Here are some examples :

PASCAL VOC 2012 Examples
5.3. Cityscapes
This dataset contains data from 50 Cities in different seasons 5000 A high-quality pixel level fine annotation image . There were 2975/500/1525 Images for training / verification / test . It defines the 19 Categories . Besides , We also provide 20000 Compare the roughly annotated image , namely , Use only fine data and both fine and coarse annotation data for training . Both training uses “++” Mark .
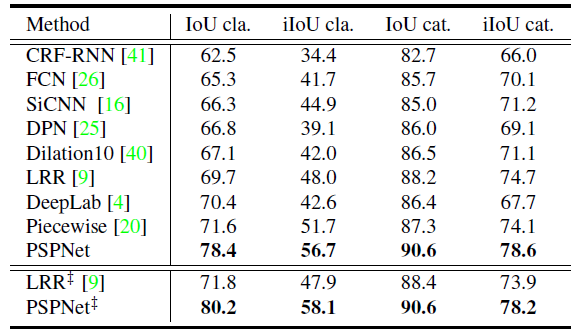
Cityscapes Test set results
Training with fine labeled data , Or use fine data and rough labeled data to train at the same time ,PSPNet Have achieved good results .
Here are some examples :

Cityscapes Examples

The author also uploaded Cityscapes Video of dataset , Very impressive :
Two other video examples :
https://www.youtube.com/watch?v=gdAVqJn_J2M
https://www.youtube.com/watch?v=HYghTzmbv6Q
Pyramid pool module is adopted , Get the global information of the image , Improved results .
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- APICloud云调试解决方案
- ES6 drill down - Async functions and symbol types
- 自己要有自己的坚持
- Six common transaction solutions, you sing, I come on stage (no best, only better)
- Example project: simple hexapod Walker
- One click installation script enables rapid deployment of graylog server 4.2.10 stand-alone version
- Obj resolves to a set
- You should have your own persistence
- 英特尔第13代Raptor Lake处理器信息曝光:更多核心 更大缓存
- Migrate /home partition
猜你喜欢

vulnhub-FirstBlood
Explain in detail the functions and underlying implementation logic of the groups sets statement in SQL

The new version of effect editor is online! 3D rendering, labeling, and animation, this time an editor is enough

ES6深入—ES6 Generator 函数
详解SQL中Groupings Sets 语句的功能和底层实现逻辑
公司自用的国产API管理神器
Single merchant v4.4 has the same original intention and strength!
Today's sleep quality record 79 points
vant tabbar遮挡内容的解决方式
CISP-PTE之PHP伪协议总结
随机推荐
Record the pits encountered in the raspberry pie construction environment...
践行自主可控3.0,真正开创中国人自己的开源事业
视觉体验全面升级,豪威集团与英特尔Evo 3.0共同加速PC产业变革
Quick completion guide for manipulator (IX): forward kinematics analysis
Research and practice of super-resolution technology in the field of real-time audio and video
ES6 deep - ES6 class class
Cheer yourself up
Flet教程之 09 NavigationRail 基础入门(教程含源码)
新春限定丨“牛年忘烦”礼包等你来领~
Some cognitive thinking
Li Kou today's question -729 My schedule I
Research and development efficiency measurement index composition and efficiency measurement methodology
Use of set tag in SQL
[graduation season] as a sophomore majoring in planning, I have something to say
Obj resolves to a set
Flet教程之 11 Row组件在水平数组中显示其子项的控件 基础入门(教程含源码)
The difference between abstract classes and interfaces
Six common transaction solutions, you sing, I come on stage (no best, only better)
One click installation script enables rapid deployment of graylog server 4.2.10 stand-alone version
List de duplication and count the number