当前位置:网站首页>记录Pytorch中的eval()和no_grad()
记录Pytorch中的eval()和no_grad()
2022-07-05 17:56:00 【我是一个对称矩阵】
起源是我训练好了一个模型,新建一个推理脚本加载好checkpoint和预处理输入后推理,发现无论输入是哪一类甚至是随机数,其输出概率总是第一类的值最大,且总是在0.5附近,排查许久,发现是没有加上model.eval()函数。
因为我使用了model.no_grad(),下意识认为不需要加model.eval(),导致发生了本次事故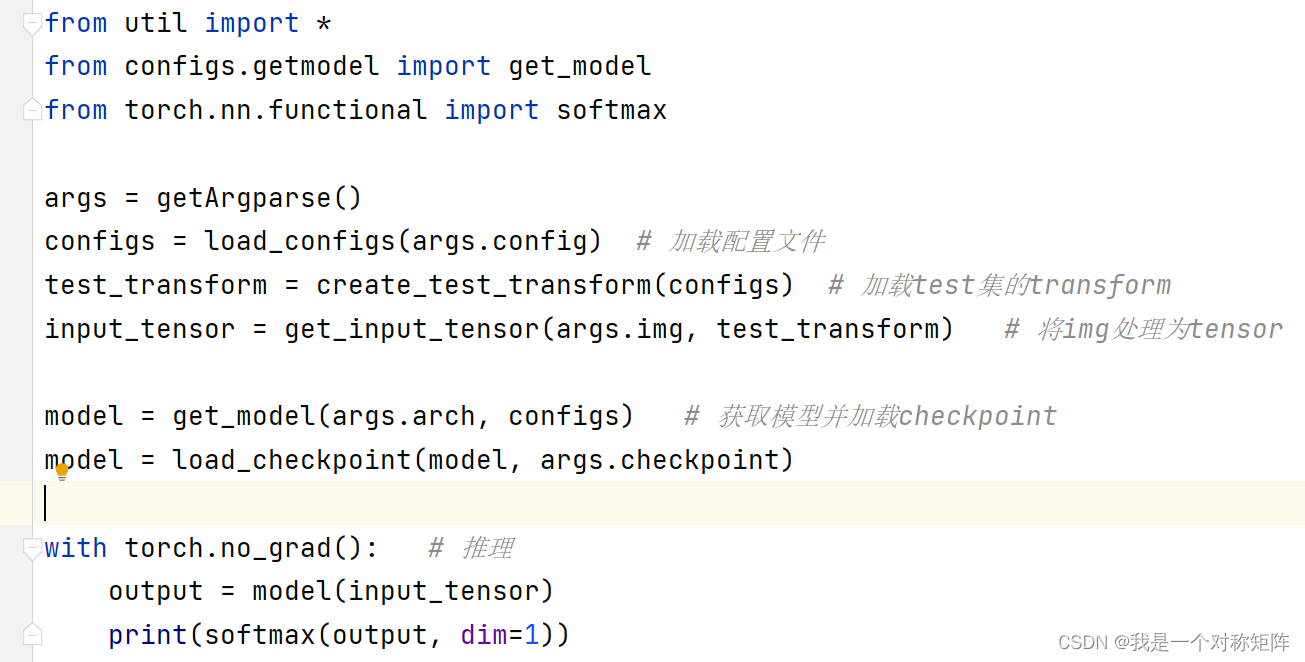
1、三剑客:train()、eval()、no_grad()
这三个函数实际上很常见,先来简单看下使用方法
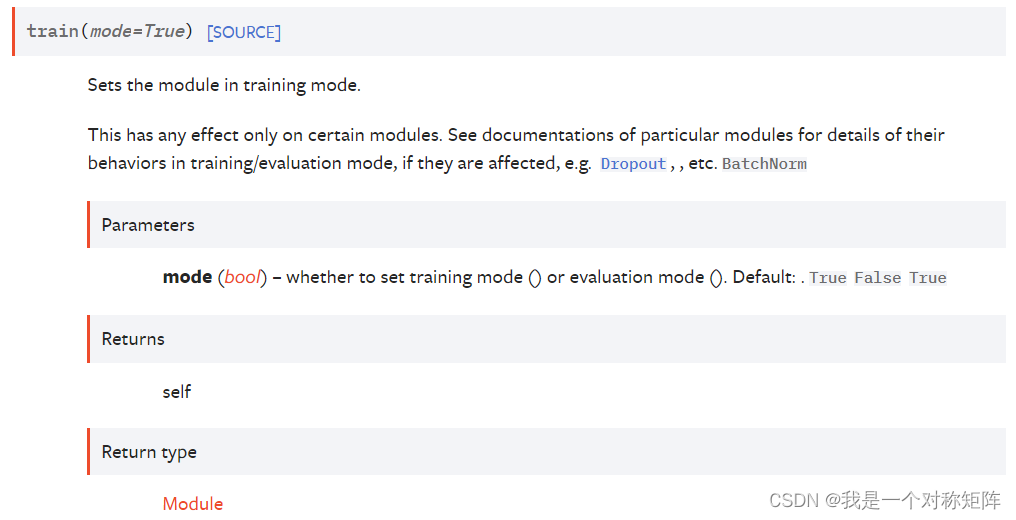
1.1 train()
train()是nn.Module的方法,也就是你定义了一个网络model,那么mdoel.train()表示将该model设置为训练模式,一般在开始新epoch训练时,我们会首先执行该命令:
...
model.train() # 将模型设置为训练模式
for i, data in enumerate(train_loader): # 开始新epoch的训练
images, labels = data
images, labels = images.to(device), labels.to(device)
...
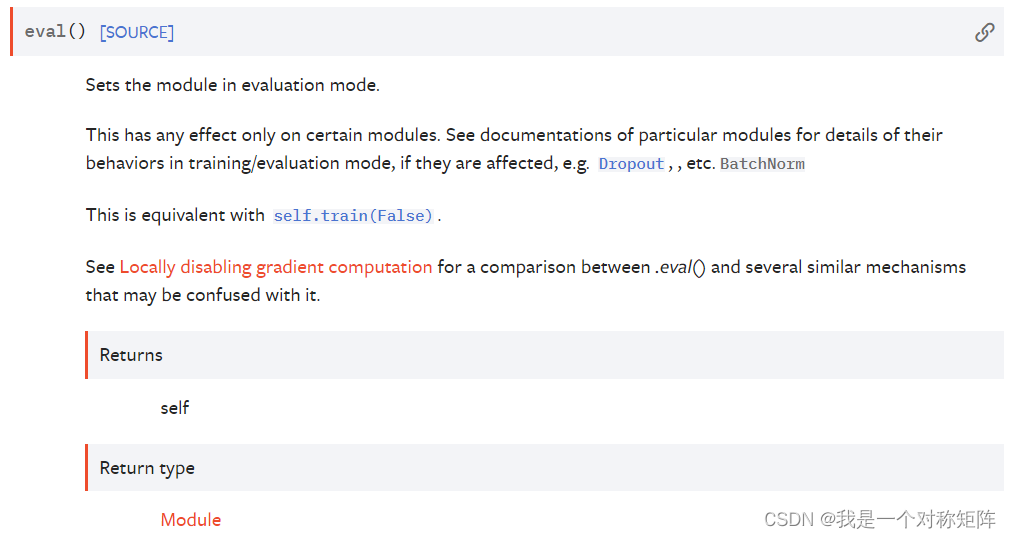
1.2 eval()
同train()一样,其用法和含义也一样,eval()是nn.Module的方法,也就是你定义了一个网络model,那么mdoel.eval()表示将该model设置为验证模式,一般在开始验证当前model效果时,我们会首先执行该命令:
...
model.eval() # 将模型设置为验证模式
for i, data in enumerate(eval_loader): # 在验证集上验证
images, labels = data
images, labels = images.to(device), labels.to(device)
...
1.3 no_grad()
no_grad()是torch库的方法,和上下文管理器with来搭配使用。
其作用是禁用梯度计算,当你确定不会调用tensor.backward()时。它将减少计算的内存消耗,否则这些计算将requires_grad=True。
如果设定了no_grad(),即使输入张量属性requires_grad为True,也不会计算梯度
一般我们进行模型验证或者模型推理时,就不需要梯度以及反向传播,所以我们可以在torch.no_grad()上下文管理器中执行我们的验证或推理任务,可以显著降低显存的使用。
with torch.no_grad():
output=model(input_tensor) # 模型推理
print(output) # model推理才涉及梯度等,print都不涉及了,所以在不在with之中已经无所谓了
2、简单分析下
2.1 为什么要使用train()和eval()
我们知道nn.Module中的BN层可以加速收敛,但是该层需要计算输入BatchTensor的均值和方差,毕竟一个BatchSize为64、128甚至更大,计算他们的均值和方差也简单。
但问题是,当我们推理时,去对一张图像进行推理时,计算到BN层也需要该批次的均值和方差。但是现在就一个tensor,计算其均值和方差是没有意义的(一个样本的均值和方差统计量说明不了什么)。
实际上在推理时BN所需要的均值和方差是训练时的值(可以理解为训练时把训练样本的均值和方差记录下来了)。
问题来了,模型怎么知道我现在是训练状态还是推理状态?
当
model.train()时,模型处于训练状态,模型会计算Batch的均值和方差当
model.eval()时,模型处于验证状态,模型会使用训练集的均值和方差作为验证数据的均值和方差
同样的还有Dropout层,Dropout层在训练时会随机失活某些神经元,提高模型泛化能力,但是在验证推理时,Dropout层不需要再失活了,也就是所有的神经元都要“干活”了。
总之train()和eval()最主要就是影响了BN层和Dropout层
2.2 为什么可以把训练集的统计量用作测试集?
为什么可以把训练集的统计量用作测试集,因为无论是训练集、验证集还是测试机,甚至是没有收集到的同类图像,他们都是独立同分布的。
换句话说,世界上所有的猫的图片组成一个集合,那么这个集合就存在一个分布,这个分布就像高斯分布、泊松分布等,只不过这个猫的集合分布可能更加复杂,暂叫它猫分布吧。
这个猫分布中每一个样本都肯定是服从这个猫分布的,但同时这些样本互不相关联,我们把其中一部分拿来做训练集,再拿一小部分做测试集。
我们设计了一个模型在训练集上训练,因为训练集也服从猫分布,所以模型在训练集上“锻炼”出来的能力,就是从小块训练集去拟合整个猫分布。
即从少量猫图上去推理所有猫图,从而具有泛化能力,去推理没有见过的但同类的图像也有非常好的效果。但是这也容易造成管中窥豹,只看到事物的一部分,见不全面,所以模型又无法识别出所有的猫图。
3、我的坑
我下意识以为使用了no_grad()就不需要再设置了eval(),导致训练效果很好,自己以测试,其输出的概率毫无逻辑。
eval()是影响BN层和Dropout层
而no_grad()是不计算梯度
两个是风马牛不相及,当然搭配使用效果即好还剩内存!
边栏推荐
- GFS分布式文件系统
- 苹果手机炒股安全吗?打新债是骗局吗?
- Introduction to VC programming on "suggestions collection"
- Data access - entityframework integration
- 数值计算方法 Chapter8. 常微分方程的数值解
- EPM相关
- Zabbix
- Action avant ou après l'enregistrement du message teamcenter
- Find the first k small element select_ k
- Neural network self cognition model
猜你喜欢
Zabbix

Sophon autocv: help AI industrial production and realize visual intelligent perception

Find the first k small element select_ k
记一次使用Windbg分析内存“泄漏”的案例

华夏基金:基金行业数字化转型实践成果分享

Why is all (()) true and any (()) false?
Configure pytorch environment in Anaconda - win10 system (small white packet meeting)
寻找第k小元素 前k小元素 select_k

职场进阶指南:大厂人必看书籍推荐
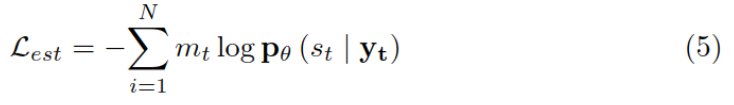
Thesis reading_ Medical NLP model_ EMBERT
随机推荐
Star Ring Technology launched transwarp Navier, a data element circulation platform, to help enterprises achieve secure data circulation and collaboration under privacy protection
matlab内建函数怎么不同颜色,matlab分段函数不同颜色绘图
小林coding的内存管理章节
tkinter窗口预加载
rsync
Teamcenter 消息注册前操作或后操作
2022新版PMP考试有哪些变化?
Size_ T is unsigned
删除数组中的某几个元素
第十一届中国云计算标准和应用大会 | 华云数据成为全国信标委云计算标准工作组云迁移专题组副组长单位副组长单位
开户复杂吗?网上开户安全么?
How to solve the error "press any to exit" when deploying multiple easycvr on one server?
Data access - entityframework integration
在一台服务器上部署多个EasyCVR出现报错“Press any to exit”,如何解决?
ISPRS2020/云检测:Transferring deep learning models for cloud detection between Landsat-8 and Proba-V
mybash
Please tell me why some tables can find data by writing SQL, but they can't be found in the data map, and the table structure can't be found
吳恩達團隊2022機器學習課程,來啦
Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
Sophon autocv: help AI industrial production and realize visual intelligent perception