当前位置:网站首页>【PaddlePaddle】 PaddleDetection 人脸识别 自定义数据集
【PaddlePaddle】 PaddleDetection 人脸识别 自定义数据集
2022-07-05 17:50:00 【mtl1994】
【PaddlePaddle】 PaddleDetection 人脸识别 自定义数据集
使用paddleDetection实现人脸识别
文章目录
# 前言
使用paddleDetection人脸识别
简介
PaddleDetection飞桨目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的组建、训练、优化及部署等全开发流程。
PaddleDetection模块化地实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力。
经过长时间产业实践打磨,PaddleDetection已拥有顺畅、卓越的使用体验,被工业质检、遥感图像检测、无人巡检、新零售、互联网、科研等十多个行业的开发者广泛应用。
特性
- 模型丰富: 包含目标检测、实例分割、人脸检测等100+个预训练模型,涵盖多种全球竞赛冠军方案
- 使用简洁:模块化设计,解耦各个网络组件,开发者轻松搭建、试用各种检测模型及优化策略,快速得到高性能、定制化的算法。
- 端到端打通: 从数据增强、组网、训练、压缩、部署端到端打通,并完备支持云端/边缘端多架构、多设备部署。
- 高性能: 基于飞桨的高性能内核,模型训练速度及显存占用优势明显。支持FP16训练, 支持多机训练。
一、数据集制作
1.收集数据
从本地摄像头收集运行以下代码,也可以从其他地方获取
# -*- coding: utf-8 -*-
####### 本地运行!!!!!!!!!
import cv2
import os
path = "./pictures/" # 图片保存路径
if not os.path.exists(path):
os.makedirs(path)
cap = cv2.VideoCapture(0)
i = 0
while (1):
ret, frame = cap.read()
k = cv2.waitKey(1)
if k == 27:
break
elif k == ord('s'):
cv2.imwrite(path + str(i) + '.jpg', frame)
print("save" + str(i) + ".jpg")
i += 1
cv2.imshow("capture", frame)
cap.release()
cv2.destroyAllWindows()
2.标注
打开labelimg
1.打开图片文件夹
2.点击change_save_dir 选择 xml保存路径
3.标注
二、下载
#下载飞桨
https://www.paddlepaddle.org.cn/
#下载paddleDetection
# pip安装paddledet
pip install paddledet==2.1.0 -i https://mirror.baidu.com/pypi/simple
# 下载使用源码中的配置文件和代码示例
git clone https://github.com/PaddlePaddle/PaddleDetection.git
cd PaddleDetection
# 安装其他依赖
pip install -r requirements.txt
三、训练
1.修改配置文件
#使用 ssd_mobilenet
#vim configs/ssd/ssd_mobilenet_v1_voc.yml
#主要修改数据集位置
TrainReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class']
dataset:
!VOCDataSet
anno_path: trainval.txt
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
EvalReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class', 'im_shape', 'im_id', 'is_difficult']
dataset:
!VOCDataSet
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: val.txt
TestReader:
inputs_def:
image_shape: [3,300,300]
fields: ['image', 'im_id', 'im_shape']
dataset:
!ImageFolder
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: label_list.txt
完整配置文件
architecture: SSD
pretrain_weights: https://paddlemodels.bj.bcebos.com/object_detection/ssd_mobilenet_v1_coco_pretrained.tar
use_gpu: true
max_iters: 2800
snapshot_iter: 2000
log_iter: 1
metric: VOC
map_type: 11point
save_dir: output
weights: output/ssd_mobilenet_v1_voc/model_final
# 20(label_class) + 1(background)
num_classes: 25
SSD:
backbone: MobileNet
multi_box_head: MultiBoxHead
output_decoder:
background_label: 0
keep_top_k: 200
nms_eta: 1.0
nms_threshold: 0.45
nms_top_k: 400
score_threshold: 0.01
MobileNet:
norm_decay: 0.
conv_group_scale: 1
conv_learning_rate: 0.1
extra_block_filters: [[256, 512], [128, 256], [128, 256], [64, 128]]
with_extra_blocks: true
MultiBoxHead:
aspect_ratios: [[2.], [2., 3.], [2., 3.], [2., 3.], [2., 3.], [2., 3.]]
base_size: 300
flip: true
max_ratio: 90
max_sizes: [[], 150.0, 195.0, 240.0, 285.0, 300.0]
min_ratio: 20
min_sizes: [60.0, 105.0, 150.0, 195.0, 240.0, 285.0]
offset: 0.5
LearningRate:
schedulers:
- !PiecewiseDecay
milestones: [10000, 15000, 20000, 25000]
values: [0.001, 0.0005, 0.00025, 0.0001, 0.00001]
OptimizerBuilder:
optimizer:
momentum: 0.0
type: RMSPropOptimizer
regularizer:
factor: 0.00005
type: L2
TrainReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class']
dataset:
!VOCDataSet
anno_path: trainval.txt
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !RandomDistort
brightness_lower: 0.875
brightness_upper: 1.125
is_order: true
- !RandomExpand
fill_value: [127.5, 127.5, 127.5]
- !RandomCrop
allow_no_crop: false
- !NormalizeBox {}
- !ResizeImage
interp: 1
target_size: 300
use_cv2: false
- !RandomFlipImage
is_normalized: true
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 4
shuffle: true
drop_last: true
worker_num: 8
bufsize: 16
use_process: true
EvalReader:
inputs_def:
image_shape: [3, 300, 300]
fields: ['image', 'gt_bbox', 'gt_class', 'im_shape', 'im_id', 'is_difficult']
dataset:
!VOCDataSet
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: val.txt
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !NormalizeBox {}
- !ResizeImage
interp: 1
target_size: 300
use_cv2: false
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 4
worker_num: 8
bufsize: 16
use_process: false
TestReader:
inputs_def:
image_shape: [3,300,300]
fields: ['image', 'im_id', 'im_shape']
dataset:
!ImageFolder
dataset_dir: /home/aiuser/mtl/data/face_demo/VOCdevkit
anno_path: label_list.txt
use_default_label: false
sample_transforms:
- !DecodeImage
to_rgb: true
- !ResizeImage
interp: 1
max_size: 0
target_size: 300
use_cv2: true
- !Permute {}
- !NormalizeImage
is_scale: false
mean: [127.5, 127.5, 127.5]
std: [127.502231, 127.502231, 127.502231]
batch_size: 1
2.开始训练
python -u tools/train.py -c configs/ssd/ssd_mobilenet_v1_voc.yml -o --eval
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qhhnrgL3-1656931184790)(C:\Users\e9\AppData\Roaming\Typora\typora-user-images\image-20210712141658919.png)]
3.导出模型
python tools/export_model.py -c configs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model
四、使用
python -u deploy/python/infer.py --model_dir D:/Paddle/PaddleDetection/PaddleDetection/output/ssd_mobilenet_v1_voc/ssd_mobilenet_v1_voc
nfigs/ssd/ssd_mobilenet_v1_voc.yml --output_dir=./inference_model ```
四、使用
python -u deploy/python/infer.py --model_dir D:/Paddle/PaddleDetection/PaddleDetection/output/ssd_mobilenet_v1_voc/ssd_mobilenet_v1_voc
# 总结
边栏推荐
- 热通孔的有效放置如何改善PCB设计中的热管理?
- OpenShift常用管理命令杂记
- 提高应用程序性能的7个DevOps实践
- Cmake tutorial Step2 (add Library)
- 怎么选择外盘期货平台最正规安全?
- 毫无章法系列
- How to save the trained neural network model (pytorch version)
- Cmake tutorial step5 (add system self-test)
- Sophon AutoCV:助力AI工业化生产,实现视觉智能感知
- Ant financial's sudden wealth has not yet begun, but the myth of zoom continues!
猜你喜欢
nacos -分布式事务-Seata** linux安装jdk ,mysql5.7启动nacos配置ideal 调用接口配合 (保姆级细节教程)
ISPRS2022/云检测:Cloud detection with boundary nets基于边界网的云检测

Why is all (()) true and any (()) false?

提高應用程序性能的7個DevOps實踐
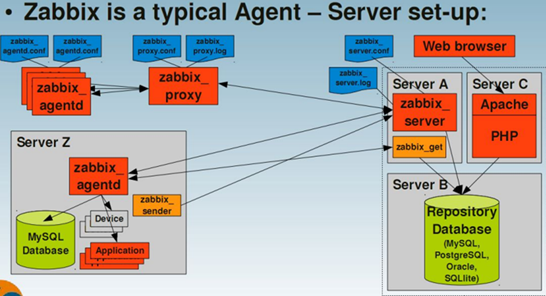
Zabbix
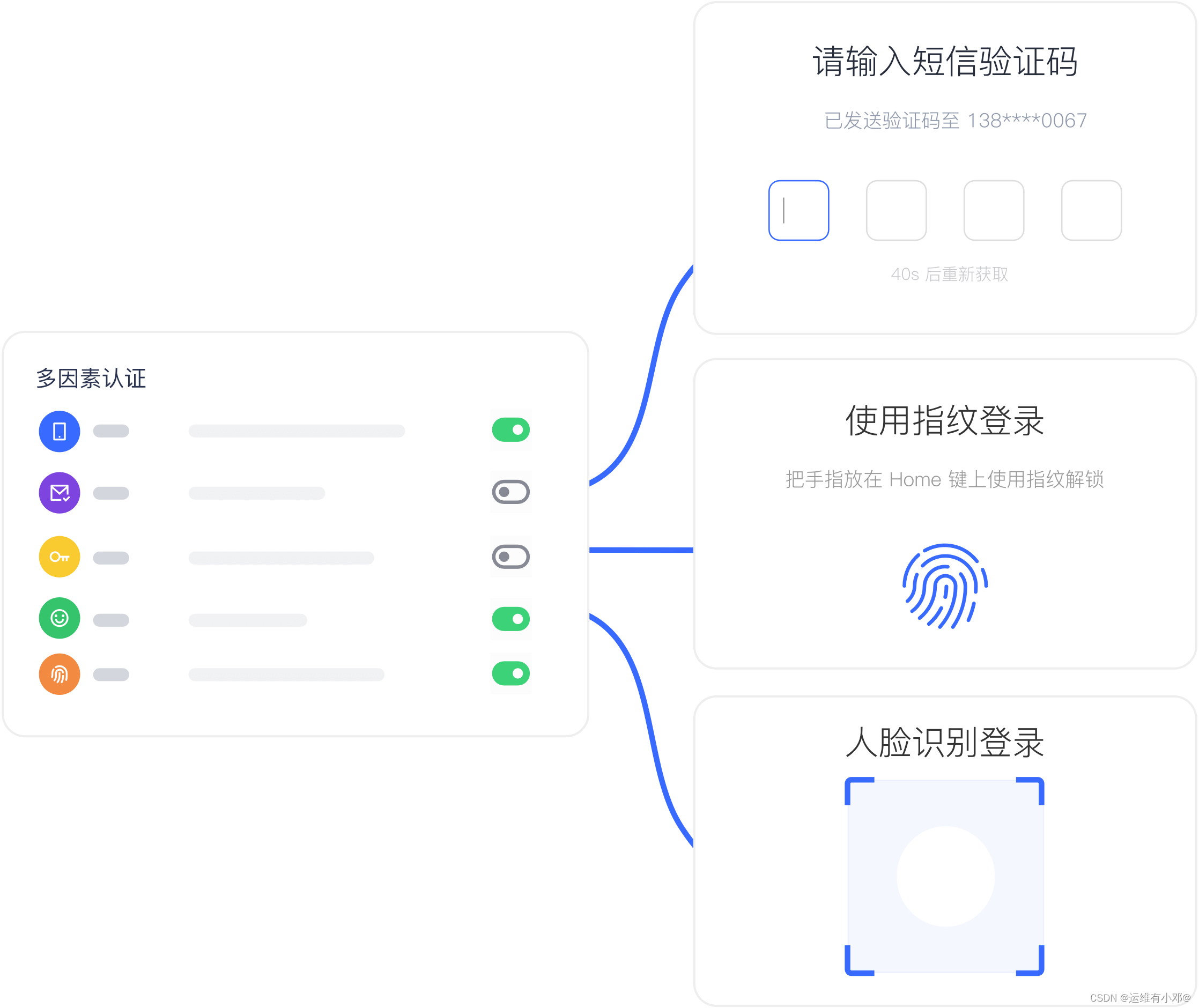
「运维有小邓」用于云应用程序的单点登录解决方案

Abnormal recovery of virtual machine Oracle -- Xi Fenfei

模拟百囚徒问题
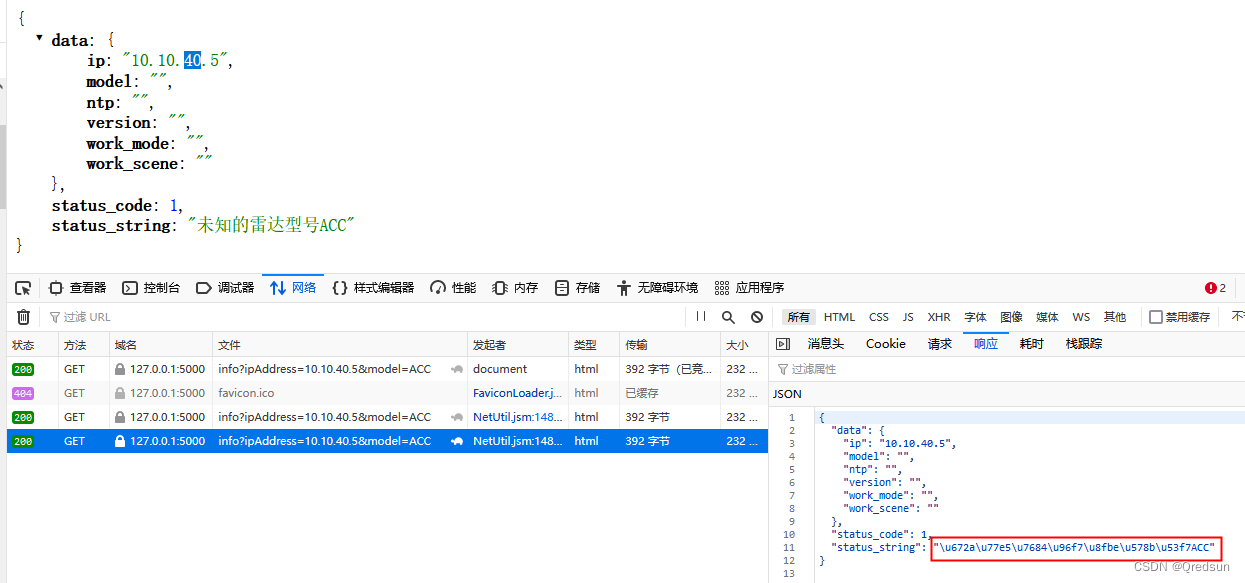
Unicode processing in response of flash interface
"Xiaodeng in operation and maintenance" is a single sign on solution for cloud applications
随机推荐
记一次使用Windbg分析内存“泄漏”的案例
VBA drives SAP GUI to realize office automation (II): judge whether elements exist
EasyCVR接入设备开启音频后,视频无法正常播放是什么原因?
What are the requirements for PMP certification? How much is it?
Is it safe to open an account online? What is the general interest rate of securities financing?
ISPRS2020/云检测:Transferring deep learning models for cloud detection between Landsat-8 and Proba-V
Leetcode daily question: the first unique character in the string
Tencent music launched its new product "quyimai", which provides music commercial copyright authorization
Abnormal recovery of virtual machine Oracle -- Xi Fenfei
使用Jmeter虚拟化table失败
网络威胁分析师应该具备的十种能力
GIMP 2.10教程「建议收藏」
Delete some elements in the array
「运维有小邓」用于云应用程序的单点登录解决方案
Size_t 是无符号的
To solve the stubborn problem of Lake + warehouse hybrid architecture, xinghuan Technology launched an independent and controllable cloud native Lake warehouse integrated platform
最大人工岛[如何让一个连通分量的所有节点都记录总节点数?+给连通分量编号]
Sophon CE社区版上线,免费Get轻量易用、高效智能的数据分析工具
Sophon kg upgrade 3.1: break down barriers between data and liberate enterprise productivity
LeetCode 练习——206. 反转链表