当前位置:网站首页>U-Net: Convolutional Networks for Biomedical Images Segmentation
U-Net: Convolutional Networks for Biomedical Images Segmentation
2022-07-05 18:23:00 【00000cj】
paper: U-Net: Convolutional Networks for Biomedical Image Segmentation
Innovation points
- Put forward U type encoder-decoder Network structure , adopt skip-connection Operate to better integrate shallow location information and deep semantic information .U-Net reference FCN Structure with full convolution , Compared with FCN An important change is that there are also a large number of feature channels in the upper sampling part , This allows the network to propagate context information to higher resolution layers .
- The task of medical image segmentation , Very little training data , The author has done a lot of data enhancement by using elastic deformation .
- Propose to use weighted loss .
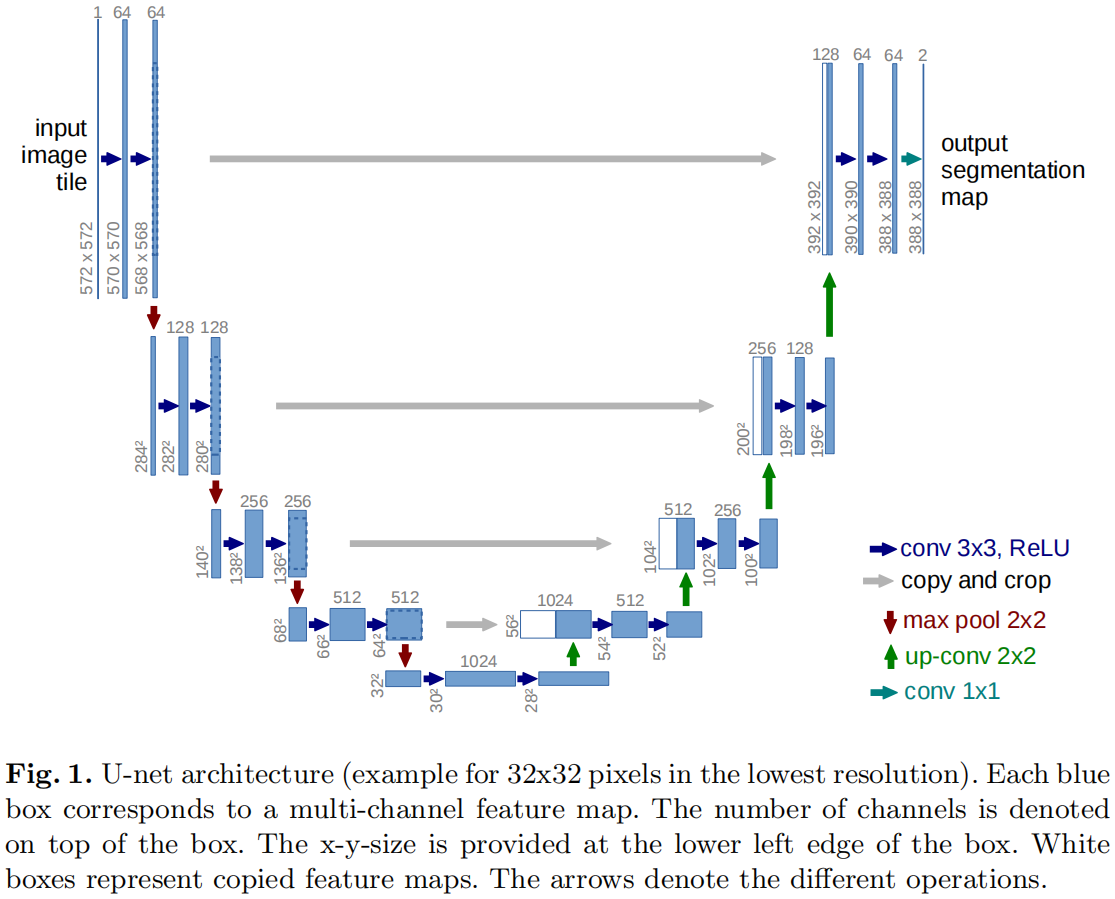
Some implementation details that need attention
- The original paper does not use padding, So output feature map The resolution of gradually decreases , What is introduced below mmsegmentation In the implementation of padding, So when stride=1 The resolution of the output characteristic image remains unchanged .
- FCN in skip-connection The fusion of shallow information and deep information is through add The way , and U-Net China is through concatenate The way .
Implementation details analysis
With MMSegmentation in unet For example , hypothesis batch_size=4, Input shape by (4, 3, 480, 480).
Backbone
- encode Stage total 5 individual stage, Every stage There is one of them. ConvBlock,ConvBlock from 2 individual Conv-BN-Relu form . Except for 1 individual stage, after 4 individual stage stay ConvBlock There's always been 1 individual 2x2-s2 Of maxpool. Every stage Of the 1 individual conv The output channel of x2. therefore encode Each stage stage Output shape Respectively (4, 64, 480, 480)、(4, 128, 240, 240)、(4, 256, 120, 120)、(4, 512, 60, 60)、(4, 1024, 30, 30).
- decode Stage total 4 individual stage, and encode after 4 Down sampled stage Corresponding . Every stage It is divided into upsample、concatenate、conv Three steps .upsample By a scale_factor=2 Of bilinear Interpolation and 1 individual Conv-BN-Relu form , Among them conv yes 1x1-s1 Convolution of halving the number of channels . The second step concatenate take upsample The output of encode Outputs with the same stage resolution are spliced together along the channel direction . The third step is a ConvBlock, and encode The stage is the same , there ConvBlock There are also two Conv-BN-Relu form , because upsample Halve the number of rear channels , But and encode After the corresponding output is spliced, the number of channels is restored , there ConvBlock The first of conv Then halve the number of output channels . therefore decode Each stage stage Output shape Respectively (4, 1024, 30, 30)、(4, 512, 60, 60)、(4, 256, 120, 120)、(4, 128 , 240, 240)、(4, 64, 480, 480). Be careful decode common 4 individual stage, So the actual output is post 4 individual , The first output is encode the last one stage Output .
FCN Head
- backbone in decode The last stage stage Output (4, 64, 480, 480) As head The input of . First pass through a 3x3-s1 Of conv-bn-relu, The number of channels remains unchanged . And then pass by ratio=0.1 Of dropout. At the end of the day 1x1 Of conv Get the final output of the model , The number of output channels is the number of categories ( Include background ).
Loss
- loss use cross-entropy loss
Auxiliary Head
- backbone in decode The penultimate stage stage Output (4, 128, 240, 240) As auxiliary head The input of . Through a 3x3-s1 Of conv-bn-relu, The number of output channels is halved to 64. after ratio=0.1 Of dropout. At the end of the day 1x1 Of conv Get the final output of the model , The number of output channels is the number of categories ( Include background ).
- Auxiliary branch Loss It's also cross-entropy loss, Note that the final output resolution of this branch is raw gt Half of , So it's calculating loss You need to sample up through bilinear interpolation first .
The complete structure of the model
EncoderDecoder(
(backbone): UNet(
(encoder): ModuleList(
(0): Sequential(
(0): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(1): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(2): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(3): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(4): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
)
(decoder): ModuleList(
(0): UpConvBlock(
(conv_block): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(upsample): InterpConv(
(interp_upsample): Sequential(
(0): Upsample()
(1): ConvModule(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(1): UpConvBlock(
(conv_block): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(upsample): InterpConv(
(interp_upsample): Sequential(
(0): Upsample()
(1): ConvModule(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(2): UpConvBlock(
(conv_block): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(upsample): InterpConv(
(interp_upsample): Sequential(
(0): Upsample()
(1): ConvModule(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
(3): UpConvBlock(
(conv_block): BasicConvBlock(
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
(1): ConvModule(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
(upsample): InterpConv(
(interp_upsample): Sequential(
(0): Upsample()
(1): ConvModule(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): _BatchNormXd(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
)
)
)
init_cfg=[{'type': 'Kaiming', 'layer': 'Conv2d'}, {'type': 'Constant', 'val': 1, 'layer': ['_BatchNorm', 'GroupNorm']}]
(decode_head): FCNHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss(avg_non_ignore=False)
(conv_seg): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Normal', 'std': 0.01, 'override': {'name': 'conv_seg'}}
(auxiliary_head): FCNHead(
input_transform=None, ignore_index=255, align_corners=False
(loss_decode): CrossEntropyLoss(avg_non_ignore=False)
(conv_seg): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
(dropout): Dropout2d(p=0.1, inplace=False)
(convs): Sequential(
(0): ConvModule(
(conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): _BatchNormXd(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activate): ReLU(inplace=True)
)
)
)
init_cfg={'type': 'Normal', 'std': 0.01, 'override': {'name': 'conv_seg'}}
)
边栏推荐
- [paddleclas] common commands
- ClickHouse(03)ClickHouse怎么安装和部署
- Star Ring Technology launched transwarp Navier, a data element circulation platform, to help enterprises achieve secure data circulation and collaboration under privacy protection
- buuctf-pwn write-ups (9)
- [PM2 details]
- 隐私计算助力数据的安全流通与共享
- 星环科技重磅推出数据要素流通平台Transwarp Navier,助力企业实现隐私保护下的数据安全流通与协作
- About Estimation with Cross-Validation
- 使用Jmeter虚拟化table失败
- 热通孔的有效放置如何改善PCB设计中的热管理?
猜你喜欢
About Statistical Power(统计功效)

破解湖+仓混合架构顽疾,星环科技推出自主可控云原生湖仓一体平台
Can communication of nano

Image classification, just look at me!
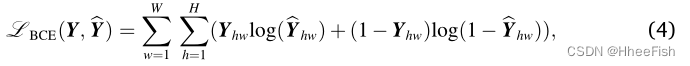
Isprs2022 / Cloud Detection: Cloud Detection with Boundary nets Boundary Networks Based Cloud Detection
Sophon CE Community Edition is online, and free get is a lightweight, easy-to-use, efficient and intelligent data analysis tool
图像分类,看我就够啦!
ConvMAE(2022-05)
pytorch yolov5 训练自定义数据

Simulate the hundred prisoner problem
随机推荐
Introduction to Resampling
Numerical calculation method chapter8 Numerical solutions of ordinary differential equations
图扑软件数字孪生 | 基于 BIM 技术的可视化管理系统
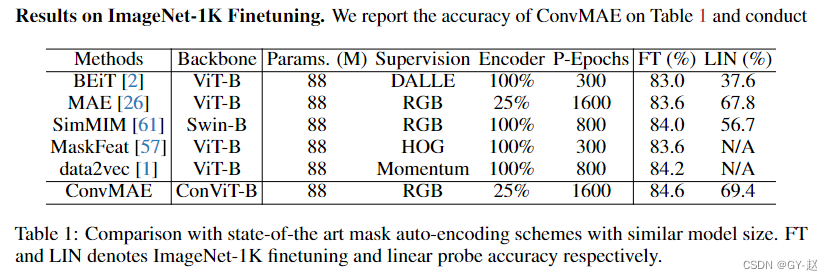
ConvMAE(2022-05)
多线程(一) 进程与线程
写作写作写作写作
图像分类,看我就够啦!
OpenShift常用管理命令杂记
JVM第三话 -- JVM性能调优实战和高频面试题记录
【PaddlePaddle】 PaddleDetection 人脸识别 自定义数据集
How to improve the thermal management in PCB design with the effective placement of thermal through holes?
[JMeter] advanced writing method of JMeter script: all variables, parameters (parameters can be configured by Jenkins), functions, etc. in the interface automation script realize the complete business
How to solve the error "press any to exit" when deploying multiple easycvr on one server?
Let more young people from Hong Kong and Macao know about Nansha's characteristic cultural and creative products! "Nansha kylin" officially appeared
兄弟组件进行传值(显示有先后顺序)
How can cluster deployment solve the needs of massive video access and large concurrency?
Electron installation problems
Le cours d'apprentissage de la machine 2022 de l'équipe Wunda arrive.
ViewPager + RecyclerView的内存泄漏
英语句式参考