当前位置:网站首页>Kalman filter -- Derivation from Gaussian fusion
Kalman filter -- Derivation from Gaussian fusion
2022-06-30 19:14:00 【Ancient road】
Kalman filter -- Derived from Gaussian fusion
0. introduction
“ If the ancient Greeks knew the normal distribution , There must be a normal goddess in the temple of Olympus , She is in charge of the chaos of the world !”
1. Bayes' rule
- Another way to deduce , Derivation from the angle of error ? Refer to the previous derivation . The previous derivation is too cumbersome , It feels more like mathematical derivation , From the perspective of Bayesian rule and Gaussian fusion , The physical meaning is very clear , More easy to understand .
- In one sentence Bayes' rule + Gaussian fusion : According to Bayes' law, there are , A posteriori estimate ∝ \propto ∝ likelihood * transcendental , Reference link ; Then according to the assumption ( The error follows Gaussian distribution ), Through the properties of Gaussian distribution , take Likelihood Gaussian distribution and A priori Gaussian distribution Multiply to get the distribution of a posteriori estimate .
It is enough for this article to read here .
The solution of state estimation problem :
Suppose the system k k k The observation quantity at the time is z k z_k zk , The state quantity is x k x_k xk , These two variables are random variables that conform to a certain distribution , And they are not independent of each other . We hope to find out :
P ( x k ∣ x 0 , z 1 : k ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k}\right) P(xk∣x0,z1:k)
According to the Bayes rule ,( Reference to the probability formula in estimation ) The probability solution of the system state is split as follows :
P ( x k ∣ x 0 , z 1 : k ) ∝ P ( z k ∣ x k ) P ( x k ∣ x 0 , z 1 : k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k}\right) \propto P\left(\mathbf{z}_{k} \mid \boldsymbol{x}_{k}\right) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k-1}\right) P(xk∣x0,z1:k)∝P(zk∣xk)P(xk∣x0,z1:k−1)
Suppose the system Satisfy Markov properties , namely x k x_k xk Only with x K − 1 x_{K-1} xK−1 relevant , Not related to earlier states ( Here's the picture ), It can be further simplified to :

P ( x k ∣ x 0 , z 1 : k ) ∝ P ( z k ∣ x k ) P ( x k ∣ x k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k}\right) \propto P\left(\mathbf{z}_{k} \mid \boldsymbol{x}_{k}\right) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{k-1}\right) P(xk∣x0,z1:k)∝P(zk∣xk)P(xk∣xk−1)
among :
- P ( z k ∣ x k ) P\left(\mathbf{z}_{k} \mid \boldsymbol{x}_{k}\right) P(zk∣xk) Is the likelihood term , Can be given by the observation equation
- P ( x k ∣ x k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{k-1}\right) P(xk∣xk−1) Is a priori term , It can be derived from the state transition equation
This problem can be solved by filter correlation algorithm , Such as Kalman Filter or Extented Kalman Filter.
In state estimation :
p ( x ∣ y ) = p ( y ∣ x ) p ( x ) p ( y ) p(\boldsymbol{x} \mid \boldsymbol{y})=\frac{p(\boldsymbol{y} \mid \boldsymbol{x}) p(\boldsymbol{x})}{p(\boldsymbol{y})} p(x∣y)=p(y)p(y∣x)p(x)
Give the formula physical meaning :
- x x x : state , It can be deduced from the state transition equation , Also known as a priori
- y y y : Sensor readings
- p ( y ∣ x ) p(y|x) p(y∣x) : Sensor model , Can be given by the observation equation , Also known as likelihood
- p ( x ∣ y ) p(x|y) p(x∣y) : State estimation , Also known as a posteriori
So Bayesian estimation : A posteriori estimate ∝ \propto ∝ likelihood * transcendental . Reference link .
2.kalman deduction
Start with an example , Definition k k k The status of the system at the moment is x k x_k xk , Suppose there are two parts: position and speed :
x k = [ p k v k ] x_{k}=\left[\begin{array}{l} p_{k} \\ v_{k} \end{array}\right] xk=[pkvk]
To further express x k x_k xk The uncertainty of each member and the relationship between each dimension , Introduce covariance matrix :
P k = [ Σ p p Σ p v Σ v p Σ v v ] \boldsymbol{P}_{k}=\left[\begin{array}{cc} \Sigma_{p p} & \Sigma_{p v} \\ \Sigma_{v p} & \Sigma_{v v} \end{array}\right] Pk=[ΣppΣvpΣpvΣvv]
among :
- Σ p p \Sigma_{p p} Σpp and Σ v v \Sigma_{v v} Σvv Is the variance of the state component
- Σ v p \Sigma_{v p} Σvp and Σ p v \Sigma_{p v} Σpv describe p p p and v v v Covariance between

Pictured above ( Left ), The relationship between speed and position is independent , Because their variances are not affected by each other ; Diagram ( Right ) On the contrary .
further , It is known that k − 1 k − 1 k−1 The state of the moment x k − 1 x_{k-1} xk−1 , We can first predict its motion relationship k k k The state of the moment x k x_k xk .
situation 1: Suppose that the condition of uniform motion is satisfied in a short time :
x ‾ k = [ 1 Δ t 0 1 ] x ^ k − 1 = F k x ^ k − 1 \overline{\boldsymbol{x}}_{k}=\left[\begin{array}{cc} 1 & \Delta t \\ 0 & 1 \end{array}\right] \widehat{\boldsymbol{x}}_{k-1}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1} xk=[10Δt1]xk−1=Fkxk−1
among :
- x ‾ k \overline{\boldsymbol{x}}_{k} xk by k k k A priori distribution of time
- x ^ k − 1 \widehat{\boldsymbol{x}}_{k-1} xk−1 by k − 1 k − 1 k−1 A posteriori distribution of time
- F k \boldsymbol{F}_{k} Fk Is the state transition matrix

situation 2: The above state transition process , It means that the system moves at a constant speed without any external intervention , But imagine what would happen if there were external influences during the exercise ? such as , An artificial push .
x ‾ k = F k x ^ k − 1 + B k u k \overline{\boldsymbol{x}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k} xk=Fkxk−1+Bkuk
among :
- u k \boldsymbol{u}_{k} uk Represents external input
- B k \boldsymbol{B}_{k} Bk The transformation relation matrix representing external input and system state change
situation 3: In the above system state modeling , Are idealized models , System noise is not considered . To better model the system state transition relationship , We introduce Gaussian noise term to simulate system noise . After considering the noise x ‾ k \overline{\boldsymbol{x}}_{k} xk as follows :
x ‾ k = F k x ^ k − 1 + B k u k + w k (1) \textcolor{blue}{\overline{\boldsymbol{x}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}+\boldsymbol{w}_{k}}\tag{1} xk=Fkxk−1+Bkuk+wk(1)
among :
- w k ∼ N ( 0 , Q k ) \boldsymbol{w}_{k} \sim N\left(0, \boldsymbol{Q}_{k}\right) wk∼N(0,Qk) Gaussian noise
C o v ( x ) = Σ Cov(x) = \boldsymbol{Σ} Cov(x)=Σ , According to the properties of covariance matrix :
Cov ( A x ) = A Σ A T \operatorname{Cov}(\boldsymbol{A} \boldsymbol{x})=\boldsymbol{A} \boldsymbol{\Sigma} \boldsymbol{A}^{T} Cov(Ax)=AΣAT Bayesian rule and Gaussian fusion
For the predicted state , Can be described as :
Cov ( x ^ k − 1 ) = P ^ k − 1 x ‾ k = F k x ^ k − 1 } ⇒ Cov ( x ‾ k ) = Cov ( F k x ^ k − 1 ) = F k P ^ k − 1 F k T \left.\begin{array}{c} \operatorname{Cov}\left(\widehat{\boldsymbol{x}}_{k-1}\right)=\widehat{\boldsymbol{P}}_{k-1} \\ \overline{\boldsymbol{x}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1} \end{array}\right\} \Rightarrow \operatorname{Cov}\left(\overline{\boldsymbol{x}}_{k}\right)=\operatorname{Cov}\left(\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}\right)=\boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T} Cov(xk−1)=Pk−1xk=Fkxk−1}⇒Cov(xk)=Cov(Fkxk−1)=FkPk−1FkT
That is :
P ‾ k = F k P ^ k − 1 F k T \overline{\boldsymbol{P}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T} Pk=FkPk−1FkT
Consider noise x ‾ k \overline{\boldsymbol{x}}_{k} xk, Its covariance can be recorded as :
P ‾ k = F k P ^ k − 1 F k T + Q k (2) \textcolor{blue}{\overline{\boldsymbol{P}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T}+\boldsymbol{Q}_{k}}\tag{2} Pk=FkPk−1FkT+Qk(2)
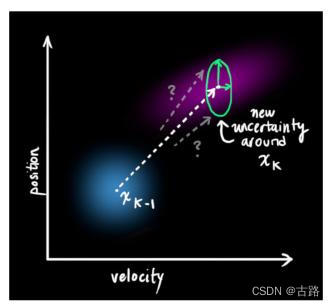
according to k − 1 k − 1 k−1 The posterior state of time x ^ k − 1 \widehat{\boldsymbol{x}}_{k-1} xk−1, We can predict k k k A priori state of time x ‾ k \overline{\boldsymbol{x}}_{k} xk And its covariance matrix p ‾ k \overline{\boldsymbol{p}}_{k} pk :
x ‾ k = F k x ^ k − 1 + B k u k + w k (1) \overline{\boldsymbol{x}}_{k}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}+\boldsymbol{w}_{k}\tag{1} xk=Fkxk−1+Bkuk+wk(1)
x ‾ k \overline{\boldsymbol{x}}_{k} xk Satisfy the following distribution :
N ( x ‾ k , P ‾ k ) = N ( F k x ^ k − 1 + B k u k , F k P ^ k − 1 F k T + Q k ) (2) \textcolor{blue}{N\left(\overline{\boldsymbol{x}}_{k}, \overline{\boldsymbol{P}}_{k}\right)=N\left(\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}, \boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T}+\boldsymbol{Q}_{k}\right)}\tag{2} N(xk,Pk)=N(Fkxk−1+Bkuk,FkPk−1FkT+Qk)(2)
When you get k k k Systematic measurement of time z k \boldsymbol{z}_k zk when , You can try to pass z k \boldsymbol{z}_k zk Revise k k k The posterior state of time x ^ k \widehat{\boldsymbol{x}}_{k} xk And its covariance matrix p ^ k \widehat{\boldsymbol{p}}_{k} pk.
Suppose it is measured by some sensors z k = ( p o s i t i o n , v e l o c i t y ) \boldsymbol{z}_k = (position, velocity) zk=(position,velocity) , In this way, we can get the following results :
z k = x ‾ k \boldsymbol{z}_k = \overline{\boldsymbol{x}}_{k} zk=xk
In order to further generalize the observation and measurement z k \boldsymbol{z}_k zk And state quantity x ‾ k \overline{\boldsymbol{x}}_{k} xk The relationship between , Define observation matrix H k {\boldsymbol{H}}_{k} Hk:
z k = H k x ‾ k (3) \boldsymbol{z}_k = {\boldsymbol{H}}_{k}\overline{\boldsymbol{x}}_{k}\tag{3} zk=Hkxk(3)
According to the properties of covariance matrix , It can be deduced that the variance of the observation is :
Σ = H k P ‾ k H k T (4) \boldsymbol{\Sigma}=\boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}\tag{4} Σ=HkPkHkT(4)
further , Considering the observed Gaussian noise v k \boldsymbol{v}_k vk Satisfy N ( 0 , R k ) N(0,\boldsymbol{R}_k) N(0,Rk) Distribution , The following formula can be obtained :
z k = H k x ‾ k + v k (5) \boldsymbol{z}_k={\boldsymbol{H}}_{k}\overline{\boldsymbol{x}}_{k} + \boldsymbol{v}_k \tag{5} zk=Hkxk+vk(5)
z k \boldsymbol{z}_k zk Satisfy the following distribution :
N ( z k , Σ ) = N ( H k x ‾ k , H k P ‾ k H k T + R k ) (6) N\left(\boldsymbol{z}_{k}, \boldsymbol{\Sigma}\right)=N\left(\boldsymbol{H}_{k} \overline{\boldsymbol{x}}_{\boldsymbol{k}}, \boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}+\boldsymbol{R}_{k}\right)\tag{6} N(zk,Σ)=N(Hkxk,HkPkHkT+Rk)(6)
among , The formula (2) It describes x ‾ k \overline{\boldsymbol{x}}_{k} xk The distribution of , The formula (6) It describes z k \boldsymbol{z}_k zk The distribution of .
Review of Gaussian distribution knowledge :

The product of two Gaussian distributions is still a Gaussian distribution , And in order to get the distribution function of the overlapping part of two Gaussian distributions , We usually multiply two Gaussian distributions .
N ( x , μ ′ , σ ′ ) = N ( x , μ 0 , σ 0 ) ⋅ N ( x , μ 1 , σ 1 ) N\left(x, \mu^{\prime}, \sigma^{\prime}\right)=N\left(x, \mu_{0}, \sigma_{0}\right) \cdot N\left(x, \mu_{1}, \sigma_{1}\right) N(x,μ′,σ′)=N(x,μ0,σ0)⋅N(x,μ1,σ1)
from N ( x , μ , σ ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 N(x, \mu, \sigma)=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}} N(x,μ,σ)=σ2π1e−2σ2(x−μ)2 It can be deduced that :
μ ′ = μ 0 + σ 0 2 ( μ 1 − μ 0 ) σ 0 2 + σ 1 2 σ ′ 2 = σ 0 2 − σ 0 4 σ 0 2 + σ 1 2 \begin{aligned} &\mu^{\prime}=\mu_{0}+\frac{\sigma_{0}^{2}\left(\mu_{1}-\mu_{0}\right)}{\sigma_{0}^{2}+\sigma_{1}^{2}} \\ &\sigma^{\prime 2}=\sigma_{0}^{2}-\frac{\sigma_{0}^{4}}{\sigma_{0}^{2}+\sigma_{1}^{2}} \end{aligned} μ′=μ0+σ02+σ12σ02(μ1−μ0)σ′2=σ02−σ02+σ12σ04
hypothesis k = σ 0 2 σ 0 2 + σ 1 2 k = \frac{\sigma_{0}^{2}}{\sigma_{0}^{2}+\sigma_{1}^{2}} k=σ02+σ12σ02, The above formula can be reduced to :
μ ′ = μ 0 + K ( μ 1 − μ 0 ) σ ′ 2 = σ 0 2 − K σ 0 2 \begin{aligned} &\mu^{\prime}=\mu_{0}+K\left(\mu_{1}-\mu_{0}\right) \\ &\sigma^{\prime 2}=\sigma_{0}^{2}-K \sigma_{0}^{2} \end{aligned} μ′=μ0+K(μ1−μ0)σ′2=σ02−Kσ02
Extend the above formula to multidimensional space :
K = Σ 0 ( Σ 0 + Σ 1 ) − 1 μ ′ = μ 0 + K ( μ 1 − μ 0 ) Σ ′ = Σ 0 + K Σ 0 \begin{gathered} \boldsymbol{K}=\boldsymbol{\Sigma}_{0}\left(\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1}\right)^{-1} \\ \boldsymbol{\mu}^{\prime}=\boldsymbol{\mu}_{\mathbf{0}}+\boldsymbol{K}\left(\boldsymbol{\mu}_{\mathbf{1}}-\boldsymbol{\mu}_{\mathbf{0}}\right) \\ \boldsymbol{\Sigma}^{\prime}=\boldsymbol{\Sigma}_{0}+\boldsymbol{K} \boldsymbol{\Sigma}_{0} \end{gathered} K=Σ0(Σ0+Σ1)−1μ′=μ0+K(μ1−μ0)Σ′=Σ0+KΣ0
go back to kalman deduction
x ˉ k \bar{\boldsymbol{x}}_{k} xˉk Satisfy the following distribution :
N ( x ‾ k , P ‾ k ) = N ( F k x ^ k − 1 + B k u k , F k P ^ k − 1 F k T + Q k ) (2) N\left(\textcolor{blue}{\overline{\boldsymbol{x}}_{k}, \overline{\boldsymbol{P}}_{k}}\right)=N\left(\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}, \boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T}+\boldsymbol{Q}_{k}\right)\tag{2} N(xk,Pk)=N(Fkxk−1+Bkuk,FkPk−1FkT+Qk)(2)
z k \mathbf{z}_{k} zk Satisfy the following distribution :
N ( z k , Σ ) = N ( H k x ‾ k , H k P ‾ k H k T + R k ) (6) N\left(\textcolor{blue}{\mathbf{z}_{k}, \Sigma}\right)=N\left(\boldsymbol{H}_{\boldsymbol{k}} \overline{\boldsymbol{x}}_{\boldsymbol{k}}, \boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}+\boldsymbol{R}_{k}\right)\tag{6} N(zk,Σ)=N(Hkxk,HkPkHkT+Rk)(6)
take x ‾ k \overline{\boldsymbol{x}}_{k} xk and z k \boldsymbol{z}_{k} zk The distribution of is substituted into the above formula ( Gaussian distribution knowledge review inside the multi-dimensional space Gaussian distribution fusion formula ):
x ^ k = x ‾ k + K ( z k − x ‾ k ) P ^ k = P ‾ k + K P ‾ k \textcolor{blue}{\begin{gathered} \widehat{\boldsymbol{x}}_{k}=\overline{\boldsymbol{x}}_{k}+\boldsymbol{K}\left(\mathbf{z}_{k}-\overline{\boldsymbol{x}}_{k}\right) \\ \widehat{\boldsymbol{P}}_{k}=\overline{\boldsymbol{P}}_{k}+\boldsymbol{K} \overline{\boldsymbol{P}}_{k} \end{gathered}} xk=xk+K(zk−xk)Pk=Pk+KPk
among , K = P ‾ k ( P ‾ k + Σ ) − 1 \boldsymbol{K}=\overline{\boldsymbol{P}}_{k}\left(\overline{\boldsymbol{P}}_{k}+\boldsymbol{\Sigma}\right)^{-1} K=Pk(Pk+Σ)−1 Is the Kalman gain .
The above is based on historical status and observation , The process of estimating the current position and speed state .
When the system is a linear Markov system , Can pass Kalman Filter To solve the fusion problem .
{ x ‾ k = F k x ^ k − 1 + B k u k + w k z k = H k x ‾ k + v k k = 1 , 2 , ⋯ , N (7) \left\{\begin{array}{c} \overline{\boldsymbol{x}}_{\boldsymbol{k}}=\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}+\boldsymbol{w}_{k} \\ \boldsymbol{z}_{k}=\boldsymbol{H}_{k} \overline{\boldsymbol{x}}_{\boldsymbol{k}}+\boldsymbol{v}_{k} \end{array} \quad k=1,2, \cdots, N\right.\tag{7} { xk=Fkxk−1+Bkuk+wkzk=Hkxk+vkk=1,2,⋯,N(7)
From the state transition equation : P ( x ‾ k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = N ( F k x ^ k − 1 + B k u k , F k P ^ k − 1 F k T + Q k ) P\left(\overline{\boldsymbol{x}}_{\boldsymbol{k}} \mid \boldsymbol{x}_{0}, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k-1}\right)=N\left(\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}, \boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T}+\boldsymbol{Q}_{k}\right) P(xk∣x0,u1:k,z1:k−1)=N(Fkxk−1+Bkuk,FkPk−1FkT+Qk)
From the observation equation : P ( z k ∣ x ‾ k ) = N ( H k x ‾ k , H k P ‾ k H k T + R k ) P\left(\boldsymbol{z}_{k} \mid \overline{\boldsymbol{x}}_{\boldsymbol{k}}\right)=N\left(\boldsymbol{H}_{k} \overline{\boldsymbol{x}}_{\boldsymbol{k}}, \boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}+\boldsymbol{R}_{k}\right) P(zk∣xk)=N(Hkxk,HkPkHkT+Rk)
notes :
- x ^ k − 1 \widehat{\boldsymbol{x}}_{k-1} xk−1 Express k − 1 k-1 k−1 A posteriori state of the system state at any time ;
- P ^ k − 1 \widehat{\boldsymbol{P}}_{k-1} Pk−1 Represents the posterior variance of the corresponding state ;
- Q \boldsymbol{Q} Q and R \boldsymbol{R} R , respectively, Indicates state and observation noise .
According to the Bayes rule P ( x k ∣ x 0 , z 1 : k ) ∝ P ( z k ∣ x k ) P ( x k ∣ x 0 , z 1 : k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k}\right) \propto P\left(\boldsymbol{z}_{k} \mid \boldsymbol{x}_{k}\right) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k-1}\right) P(xk∣x0,z1:k)∝P(zk∣xk)P(xk∣x0,z1:k−1), take P ( x ‾ k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P\left(\overline{\boldsymbol{x}}_{\boldsymbol{k}} \mid \boldsymbol{x}_{0}, \boldsymbol{u}_{1: k}, \boldsymbol{z}_{1: k-1}\right) P(xk∣x0,u1:k,z1:k−1) and P ( z k ∣ x ‾ k ) P\left(\mathbf{z}_{k} \mid \overline{\boldsymbol{x}}_{\boldsymbol{k}}\right) P(zk∣xk) Multiply , have to :
N ( x ^ k , P ^ k ) = N ( H k x ‾ k , H k P ‾ k H k T + Q k ) N ( F k x ^ k − 1 + B k u k , F k P ^ k − 1 F k T + R k ) N\left(\widehat{\boldsymbol{x}}_{k}, \widehat{\boldsymbol{P}}_{k}\right)=N\left(\boldsymbol{H}_{k} \overline{\boldsymbol{x}}_{\boldsymbol{k}}, \boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}+\boldsymbol{Q}_{k}\right) N\left(\boldsymbol{F}_{k} \widehat{\boldsymbol{x}}_{k-1}+\boldsymbol{B}_{k} \boldsymbol{u}_{k}, \boldsymbol{F}_{k} \widehat{\boldsymbol{P}}_{k-1} \boldsymbol{F}_{k}^{T}+\boldsymbol{R}_{k}\right) N(xk,Pk)=N(Hkxk,HkPkHkT+Qk)N(Fkxk−1+Bkuk,FkPk−1FkT+Rk)
It can be obtained. , Posterior distribution N ( x ^ k , P ^ k ) N\left(\widehat{\boldsymbol{x}}_{k}, \widehat{\boldsymbol{P}}_{k}\right) N(xk,Pk) Mean and covariance matrix of :
x ^ k = x ‾ k + K ( z k − H k x ‾ k ) P ^ k = ( I − K H k ) P ‾ k \textcolor{blue}{\begin{gathered} \widehat{\boldsymbol{x}}_{k}=\overline{\boldsymbol{x}}_{k}+\boldsymbol{K}\left(\mathbf{z}_{k}-\boldsymbol{H}_{k} \overline{\boldsymbol{x}}_{k}\right) \\ \widehat{\boldsymbol{P}}_{k}=\left(I-\boldsymbol{K} \boldsymbol{H}_{k}\right) \overline{\boldsymbol{P}}_{k} \end{gathered}} xk=xk+K(zk−Hkxk)Pk=(I−KHk)Pk
among , K = P ‾ k H k T ( H k P ‾ k H k T + Q k ) − 1 \boldsymbol{K}=\overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}\left(\boldsymbol{H}_{k} \overline{\boldsymbol{P}}_{k} \boldsymbol{H}_{k}^{T}+\boldsymbol{Q}_{k}\right)^{-1} K=PkHkT(HkPkHkT+Qk)−1 Is the Kalman gain .
3. summary
The state estimation problem is modeled as :
P ( x k ∣ x 0 , z 1 : k ) ∝ P ( z k ∣ x k ) P ( x k ∣ x k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{0}, \boldsymbol{z}_{1: k}\right) \propto P\left(\mathbf{z}_{k} \mid \boldsymbol{x}_{k}\right) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{k-1}\right) P(xk∣x0,z1:k)∝P(zk∣xk)P(xk∣xk−1)
among :
- P ( z k ∣ x k ) P\left(\mathbf{z}_{k} \mid \boldsymbol{x}_{k}\right) P(zk∣xk) Is the likelihood term , Can be given by the observation equation
- P ( x k ∣ x k − 1 ) P\left(\boldsymbol{x}_{k} \mid \boldsymbol{x}_{k-1}\right) P(xk∣xk−1) Is a priori term , It can be derived from the state transition equation
In one sentence Bayes' rule + Gaussian fusion : According to Bayes' law, there are , A posteriori estimate ∝ \propto ∝ likelihood * transcendental , Reference link ; Then according to the assumption ( The error follows Gaussian distribution ), Through the properties of Gaussian distribution , take Likelihood Gaussian distribution and A priori Gaussian distribution Multiply to get the distribution of a posteriori estimate .
边栏推荐
- Pytorch learning (III)
- ONEFLOW source code parsing: automatic inference of operator signature
- 20220528【聊聊假芯片】贪便宜往往吃大亏,盘点下那些假的内存卡和固态硬盘
- Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 1)
- Infineon - GTM architecture -generic timer module
- NBI可视化平台快速入门教程(五)编辑器功能操作介绍
- Cloud Native Landing Practice Using rainbond for extension dimension information
- Swin-Transformer(2021-08)
- Nodejs 安装与介绍
- 3.10 haas506 2.0开发教程-example-TFT
猜你喜欢
Practice and Thinking on the architecture of a set of 100000 TPS im integrated message system

一点比较有意思的模块

【TiDB】TiCDC canal_ Practical application of JSON

Dlib library for face key point detection (openCV Implementation)

Swin-transformer --relative positional Bias

System integration project management engineer certification high frequency examination site: prepare project scope management plan

Infineon - GTM architecture -generic timer module

PyTorch学习(三)

Redis入门到精通01

France a+ France VOC label highest environmental protection level
随机推荐
拓維信息使用 Rainbond 的雲原生落地實踐
Influence and requirements of different manufacturing processes on the pad on PCB
Detailed single case mode
Cloud Native Landing Practice Using rainbond for extension dimension information
「干货」数据分析常用的10种统计学方法,附上重点应用场景
Memory Limit Exceeded
基于STM32F1的环境光与微距离检测系统
Dlib library for face key point detection (openCV Implementation)
nats集群部署
删除排序链表中的重复元素 II[链表节点统一操作--dummyHead]
Develop those things: how to add text watermarks to videos?
Evolution of screen display technology
Nodejs installation and introduction
MySQL事务并发问题和MVCC机制
Entry node of link in linked list - linked list topic
Swin-Transformer(2021-08)
rust配置国内源
一套十万级TPS的IM综合消息系统的架构实践与思考
CTF流量分析常见题型(二)-USB流量
「经验」爬虫在工作中的实战应用『实现篇』