When the business scale reaches a certain scale , For example, the daily order volume of Taobao is in 5000 More than ten thousand , Meituan 3000 More than ten thousand . The database faces massive data pressure , Sub database and sub table is the operation that must be carried out . After the database and table are divided, some regular queries may have problems , The most common problem is paging query . Generally, we call the fields of sub table as shardingkey, For example, the order table is based on the user ID As shardingkey, Then, if there is no user in the query condition ID Query how to paginate ? For example, there are no more multi-dimensional queries shardingkey How to query ?
Unique primary key
Generally, the primary key of our database is self increasing , So the problem of primary key conflict after table splitting is an unavoidable problem , The simplest way is to use a unique business field as the only primary key , For example, the order number in the order table must be globally unique .
Common distributed generation is unique ID There are many ways , The most common snowflake algorithm Snowflake、 sound of dripping water Tinyid、 Meituan Leaf. Take the snowflake algorithm, for example , One millisecond can generate 4194304 Multiple ID.
first place Don't use , The default is 0,41 A time stamp Accurate to milliseconds , It can hold 69 Years of time ,10 A working machine ID high 5 Bit is the data center ID, low 5 Bits are nodes ID,12 A serial number Each node adds up every millisecond , Cumulative can reach 2^12 4096 individual ID.

table
First step , How to ensure that the order number is unique after splitting the table , Now consider the following table . First, consider the size of the sub table according to its own business volume and increment .
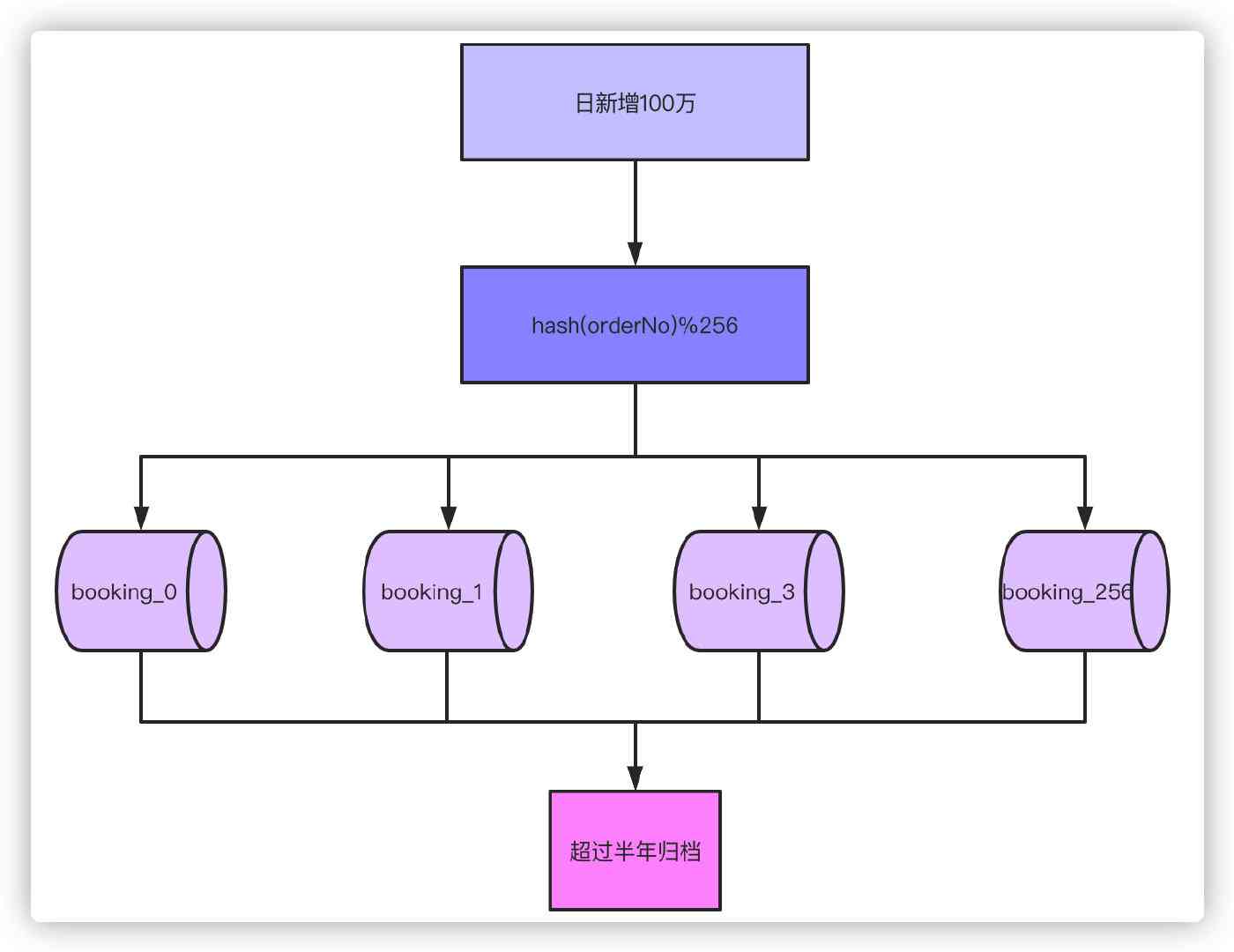
for instance , Now our daily order is 10 Thousands of single , It is estimated that it will reach the date in one year 100 Thousands of single , According to business attributes , Generally, we support the inquiry of orders within half a year , Orders over half a year need to be filed .
Well, with a daily order 100 In the order of magnitude of ten thousand six months , Without dividing the tables, our order will reach 100 ten thousand X180=1.8 Billion , At this data level, some tables will not be able to handle a single table , Even if you can carry RT You can't accept it at all . According to experience, the number of millions of tables in a single table has no pressure on the database , So just divide 256 A watch is enough ,1.8 Billion /256≈70 ten thousand , If you want to be on the safe side , You can also get 512 A watch . So think about , If business grows again 10 Double to 1000 Ten thousand orders a day , table 1024 It's a better choice .
Through the sub table and more than half a year of data archiving , Single table 70 Ten thousand is enough for most scenarios . Next, for the order number hash, Then on 256 Take the mold can fall into the specific table .
that , Because the only primary key is based on the order number , What you wrote before was based on the primary key ID You can't use the query , This involves the modification of some query functions in history . But it's not about it, is it , Change it to the order number . That's not a problem , The problem is at the point of our title .
C End query
Said along while , It's time to get to the point , Then how to solve the problem of query and paging query after table splitting ?
First of all, bring shardingkey Query for , For example, through the order number query , No matter how you paginate or how, you can directly locate the specific table to query , Obviously, there will be no problem with queries .
If not shardingkey Words , Take the order number as an example shardingkey Words , image APP、 This kind of small program is generally through the user ID Inquire about , At that time, we made it through the order number sharding What do I do ? Many company order forms are directly used by users ID do shardingkey, So it's very simple , Just look it up . What about the order number , A very simple way is to take the user on the order number ID Properties of . Take a very simple example , Original 41 You don't think you'll run out of time stamps , user ID yes 10 Bit , The generation rule of order number takes the user ID, According to the order number when making a detailed list 10 Users ID hash modulus , In this way, no matter according to the order number or the user ID The query results are the same .
Of course , This is just an example , Specific order number generation rules , How many , Which factors are included depends on your own business and implementation mechanism .

good , So whether you're an order number or a user ID As shardingkey, You can solve the problem in both ways . Then there's another problem if it's not an order number or a user ID What to do with the inquiry ? The most intuitive example is from the merchant side or background query , The merchant end is to the merchant or the seller ID As a query condition , Background query conditions may be more complex , Like some background query conditions I encountered, there are dozens of them , How to find out ??? Don't worry. , Next, separate them B End and background complex queries .
In reality, most of the real traffic comes from users C End , So it essentially solves the problem of the client , This problem is solved for the most part , The rest comes from merchants and sellers B End 、 The query traffic of backstage support operation business is not very big , This problem is easy to solve .
Other end queries
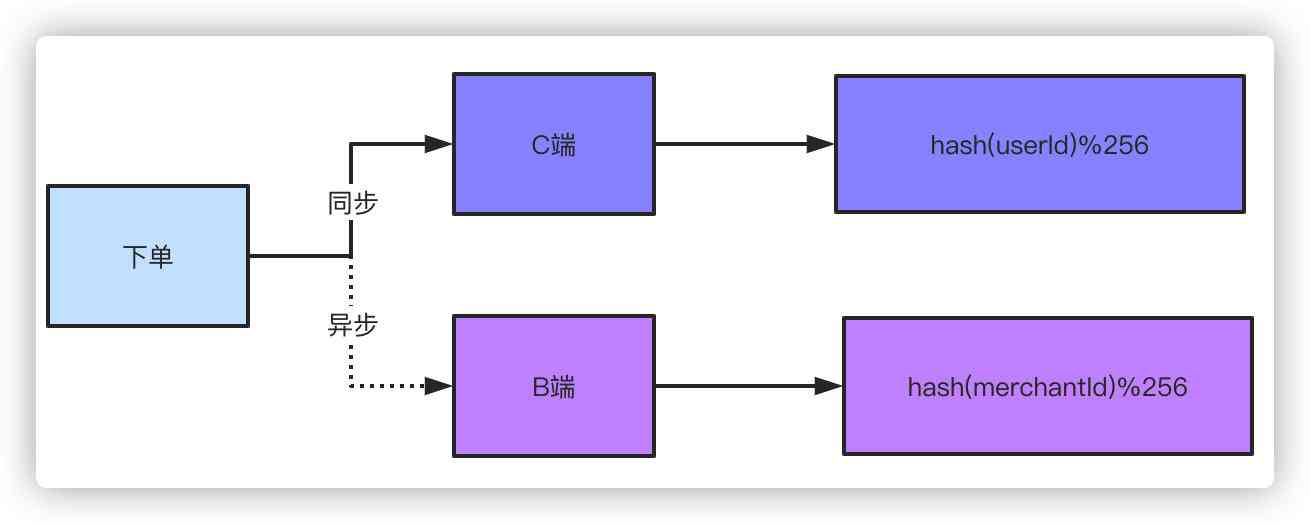
in the light of B Non of end shardingkey There are two ways to solve this problem .
Double write , Double writing is to place an order in two copies ,C End sum B Keep a copy of each ,C You can use the order number 、 user ID do shardingkey Will do ,B The end uses the merchant seller's ID As shardingkey Just fine . Some students will say , Don't you double write ? Because for B At the end of the day, a slight delay is acceptable , So you can take an asynchronous way to drop B End order . Think about it. You went to Taobao to buy an order , Does it matter if the seller is delayed a second or two to receive this order ? If you order a takeaway merchant and receive this order a second or two later, does it have any big impact ?
This is a solution , Another plan is to go Offline data warehouse or ES Inquire about , After the order data is placed in the database , No matter you pass binlog still MQ All forms of news , Synchronize data to a data warehouse or ES, The order of magnitude they support is very simple for this query condition . Again, there must be a slight delay in this way , But this controllable delay is acceptable .
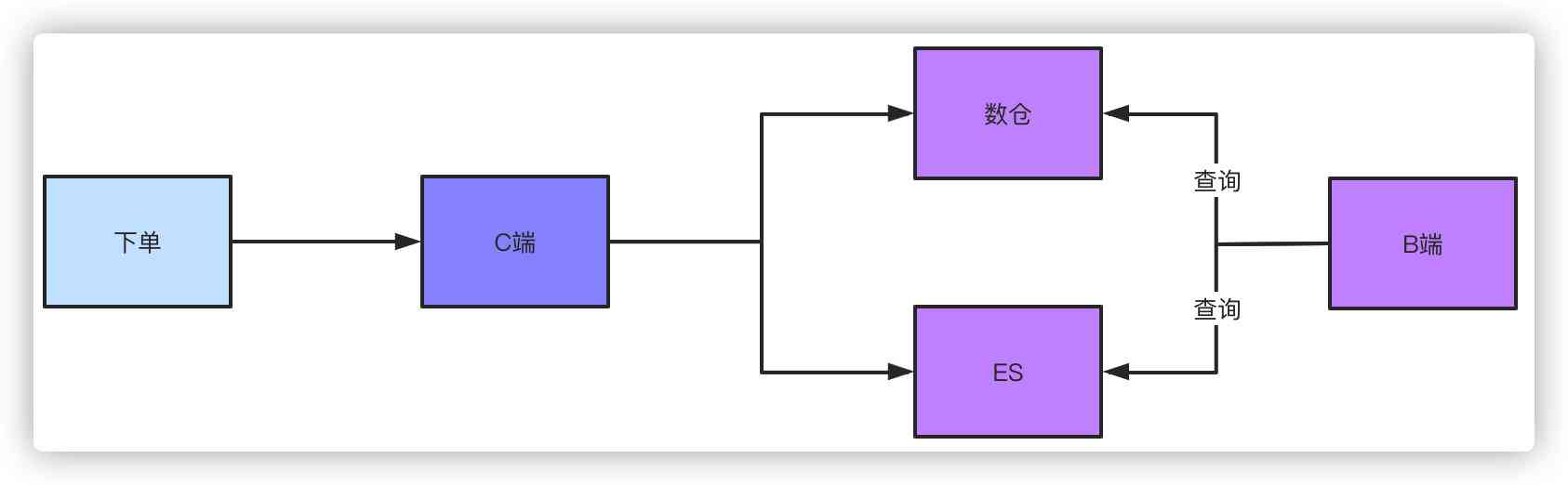
And for the query of the management background , Like operations 、 Business 、 Products need to look at the data , They naturally need complex query conditions , Go the same way ES Or a storehouse can do it . If you don't use this program , And without shardingkey Pagination query of , brother , This can only scan the whole table to query the aggregate data , Then I did pagination manually , But the results are limited .
Like you 256 A movie , When querying, scan all the tiles in a loop , Take from each piece 20 Data , Finally, aggregate data is manually paginated , It must be impossible to find the full amount of data .
summary
Query after sub database and sub table , For experienced students, in fact, this problem is known to all , But I believe that most of the students' business may not come to this order of magnitude , Sub database and sub table may stay in the concept stage , I was at a loss when I was asked about the interview , Because I have no experience, I don't know what to do .
First of all, sub database and sub table are based on the existing business volume and future increment , For example, the daily quantity of pinduoduo 5000 Ten thousand , Half a year's data has to be 10 billion levels , That's all scored 4096 It's a watch, right , But the actual operation is the same , For your business 4096 Then there's no need to , Make reasonable choices based on the business .
Based on shardingkey We can easily solve the problem , For non shardingkey The query can be done by double data and data warehouse 、ES Solution , Of course , If there is a small amount of data after sub table , Build the index , Scanning the whole table is not a problem .
- END -