当前位置:网站首页>机器学习1一回归模型(二)
机器学习1一回归模型(二)
2022-07-30 23:30:00 【存在~~】
逻辑回归(Logistic Regression)
前言
在前面讲述的回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量的期望与自变量之间的线性关系或多项式曲线关系。比如常见的线性回归模型:
而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个两点(0或1)分布变量,它就不能用h函数连续的值来预测因变量Y(Y只能取0或1)。此时就不适合用线性回归或者多项式回归模型,而采用逻辑模型来解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
在逻辑回归算法中,使用了 sigmoid 函数来拟合数据。可以看出 sigmoid 函数有点像是被掰弯的线性
函数直线,这样函数的取值范围被限定在了 0 和 1 之间,很明显,使用这个函数去拟合上面的二分类结
果要比线性直线好得多。
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如图上图所示,采用的Sigmoid函数实现。这里我们将该函数定义如下:
函数的定义域为全体实数,值域在[0,1]之间,x轴在0点对应的结果为0.5。当x取值足够大的时候y无限趋近0和1,所以看成0或1两类问题,大于0.5可以认为是1类问题,反之是0类问题,而刚好是0.5,则可以划分至0类或1类。
对于0-1型变量,y=1的概率分布公式定义为:
y=0公式为: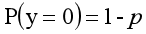
其离散型随机变量期望值为:
对其进行线性模型分析,其公式变换如下: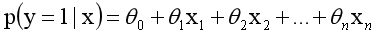
而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit与自变量之间存在线性相关的关系,逻辑回归模型定义如下:
概率p(以0.5为界限,预测p大于0.5时,我们判断此时y更可能为1,否则y为0。)为:
- 绘制Sigmoid曲线
import matplotlib.pyplot as plt
import numpy as np
def Sigmoid(x):
return 1.0 / (1.0 + np.exp(-x)) # 返回函数
x= np.arange(-10, 10, 0.1) # x的范围-10到10,单位为0.1
h = Sigmoid(x) # Sigmoid函数
plt.plot(x, h)
plt.axvline(0.0, color='k') # 坐标轴上加一条竖直的线(0位置)
# plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
plt.axhline(y=0.5, ls='dotted', color='r') # 在y=0.5画一条点线
plt.yticks([0.0, 0.5, 1.0]) # y轴标度
plt.ylim(-0.1, 1.1) # y轴范围
plt.show()
输出为: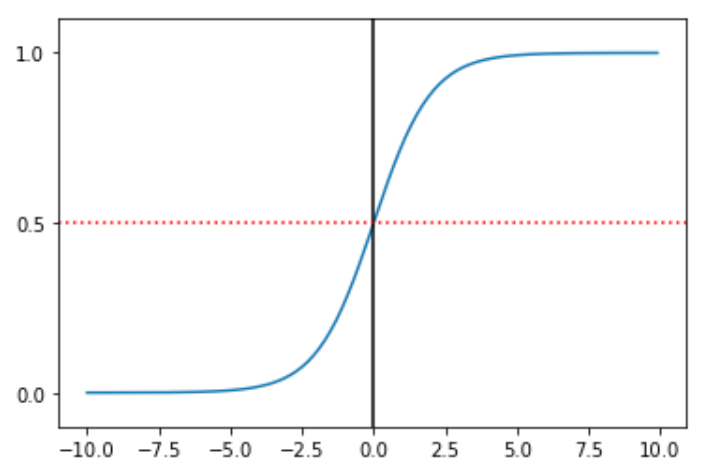
一、LogisticRegression的使用
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
- 导入模型。调用逻辑回归LogisticRegression()函数。
- fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
- predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
# 没有导入任何数据所以输出会报错,只是对上述步骤的简单描述
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
clf = LogisticRegression() # 创建逻辑回归模型
# clf
clf.fit(train_feature,label) # fit()训练模型
predict['label'] = clf.predict(predict_feature) # 预测label的predict_feature结果
输出函数的构造方法:
LogisticRegression(C=1.0,penalty=‘l2’,…)
只对C和penalty参数分析:
- 参数penalty表示惩罚项,包括两个可选值L1和L2。L1表示向量中各元素绝对值的和,常用于特征选择;L2表示向量中各个元素平方之和再开根号,当需要选择较多的特征时,使用L2参数,使他们都趋近于0。
- C值的目标函数约束条件为:s.t.||w||1<C,默认值是0,C值越小,则正则化强度越大。
二、Sklearn机器学习包导入鸢尾花数据集实现回归分析实例
1.鸢尾花卉(iris)数据集
下面将结合Scikit-learn官网的逻辑回归模型分析鸢尾花数据集。由于该数据分类标签划分为3类(0类、1类、2类),属于三分类问题,所以能利用逻辑回归模型对其进行分析。
Sklearn机器学习包引用的是鸢尾花卉(iris)数据集,它也是一个很常用的数据集。该数据集一共包含4个特征变量,1个类别变量,共有150个样本。其中四个特征分别是萼片的长度和宽度、花瓣的长度和宽度,一个类别变量是标记鸢尾花所属的分类情况,该值包含三种情况,即山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。鸢尾花数据集详细介绍如表所示: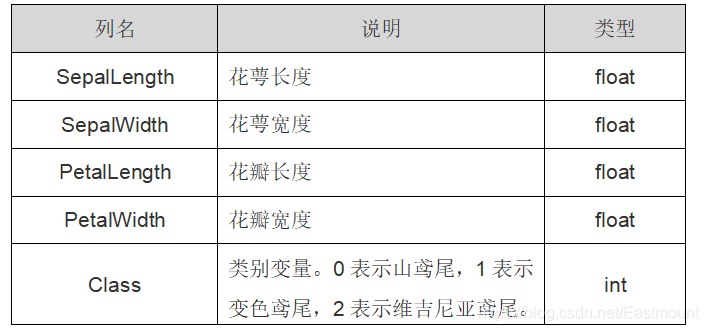
Class 类别变量中0表示山鸢尾,1表示变色鸢尾,2表示维吉尼亚鸢尾。 iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一行代表一个被测量的鸢尾植物,一共采样了150条记录,即150朵鸢尾花样本。target是输出 iris数据集中三种类变量0,1,2。
from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() # 载入数据集
# print(iris.data) # 输出iris数据(输出的是150行4列的数据列表)
print(iris.target) # 输出真实标签
print(len(iris.target)) # 150个样本 每个样本4个特征
print(iris.data.shape) # 输出iris数据集形状,150行4列的矩阵
# 输出为
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150, 4)
- 从输出结果可以看到,类标共分为三类,前面50个类标位0,中间50个类标位1,后面为2。
2.散点图绘制
在载入了鸢尾花数据集(数据data和标签target)之后,我们需要获取其中两列数据(两个特征),再调用scatter()函数绘制散点图。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris #导入数据集iris
# 载入iris数据集
iris = load_iris()
# print(iris.data) # 输出数据集
# print(iris.target) # 输出真实标签
# 获取花卉两列数据集(重点代码地方)
X = [x[0] for x in iris.data ] # 获取第一列数据
# print(X)
Y = [x[1] for x in iris.data ] # 获取第二列数据
# print(Y)
#plt.scatter(X, Y, c=iris.target, marker='x')
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa') # 山鸢尾(setosa)0为前50个样本(两列数据集X,Y的前50个数据)
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor') # 变色鸢尾(versicolor)1为中间50个
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica') # 维吉尼亚鸢尾(virginica)2为后50个样本
plt.legend(loc=2) # 把图标放置在左上角
plt.show()
输出为:

3.逻辑回归分析鸢尾花
- 掌握代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
# 载入iris数据集
iris = load_iris()
X = X = iris.data[:, :2] # 获取花卉两列数据集和上述x=[x[1] for x in iris.data ]效果一样
Y = iris.target
# 逻辑回归模型
lris = LogisticRegression(C=1e5) # 初始化逻辑回归模型,C=1e5表示目标函数。
lris.fit(X,Y) # 调用逻辑回归模型进行训练,参数X为数据特征,参数Y为数据类标。
# meshgrid函数生成两个网格矩阵
h = .02 # 步长h(设置为0.02)
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 # 取X二维数组的第一列(长度)的最小值、最大值
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 # 取X二维数组的第二列(长度)的最小值、最大值
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 先取上面x和y变为数组,再由meshgrid函数生成两个网格矩阵xx和yy
# 将网格矩阵和对应的预测结果绘制在图片上
# 调用ravel()函数将xx和yy的两个矩阵转变成一维数组,由于两个矩阵大小相等,因此两个一维数组大小也相等。
Z = lris.predict(np.c_[xx.ravel(), yy.ravel()]) # np.c_[xx.ravel(), yy.ravel()]是获取并合并成矩阵,并且用predict()进行预测,预测结果赋值给Z
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(8,6))
# 调用pcolormesh()函数将xx、yy两个网格矩阵和对应的预测结果Z绘制在图片上,可以发现输出为三个颜色区块,分布表示分类的三类区域。
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) # cmap=plt.cm.Paired表示绘图样式选择Paired主题
#绘制散点图
plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa')
# 第一个参数为第一列数据(长度),第二个参数为第二列数据(宽度),第三、四个参数为设置点的颜色为红色,款式o为圆圈,最后标记为setosa。
plt.scatter(X[50:100,0], X[50:100,1], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:,0], X[100:,1], color='green', marker='s', label='Virginica')
plt.xlabel('Sepal length') # x的标题
plt.ylabel('Sepal width') # y的标题
plt.xlim(xx.min(), xx.max()) # x轴的范围
plt.ylim(yy.min(), yy.max()) # y轴的范围
plt.xticks(()) # x轴的标度为空
plt.yticks(()) # y轴的标度为空
plt.legend(loc=2)
plt.show()
输出为:逻辑回归后划分为三个区域,左上角部分为红色的圆点,对应为山鸢setosa;右上角部分为绿色方块,对应为维吉尼亚鸢尾virginica;中间下部分为蓝色星形,对应为变色鸢尾versicolor。散点图为各数据点真实的花类型,划分的三个区域为数据点预测的花类型,预测的分类结果与训练数据的真实结果结果基本一致,部分鸢尾花出现交叉。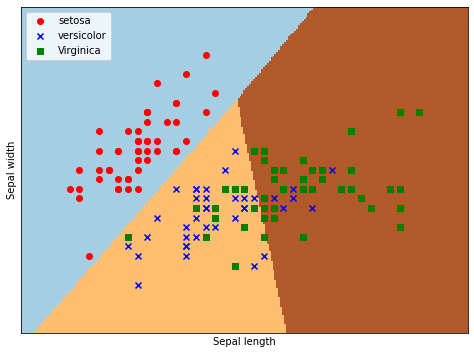
总结
逻辑回归(Logistic Regression)与线性回归(Linear Regression)都是一种广义线性模型(generalized linear model)。逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从高斯分布。 因此与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
边栏推荐
- 软件测试三阶段,你在哪一步?
- 阿里云视频点播+项目实战
- BFS题单总结
- In MySQL, the stored procedure cannot realize the problem of migrating and copying the data in the table
- Golang go-redis cluster模式下不断创建新连接,效率下降问题解决
- HCIP Day 15 Notes
- 如何在 AWS 中应用 DevOps 方法?
- “蔚来杯“2022牛客暑期多校训练营4 N.Particle Arts 规律 方差
- leetcode 406. Queue Reconstruction by Height 根据身高重建队列(中等)
- image里的mode属性
猜你喜欢
![[MySQL] Mysql transaction and authority management](/img/a5/c92e0404c6a970a62595bc7a3b68cd.gif)







随机推荐
Flex布局使用
【2022-05-31】JS逆向之易企秀
实验7(MPLS实验)
leetcode 406. Queue Reconstruction by Height 根据身高重建队列(中等)
Go的Gin框架学习
JS中? ?和??=和?.和 ||的区别
Apache Doris series: In-depth understanding of real-time analytical database Apache Doris
A detailed explanation: SRv6 Policy model, calculation and drainage
[MySQL] Related operations on databases and tables in MySQL
Reverse linked list - head insertion inversion method
ZZULIOJ:1120: 最值交换
抽象类和接口(学习笔记)
Soft Exam Study Plan
Manually set transaction commit in mysql
flex-direction容器属性
grub learning
Go1.18升级功能 - 模糊测试Fuzz 从零开始Go语言
会员生日提前了一天
matplotlib图表多曲线多纵轴绘制工具方法
Summary of BFS questions